4. 我的解决

其实不难发现,我报错的位置基本都是从gpu往cpu转换的时候出现的问题。
- 因此考虑是不是cpu内存不太够了,所以内存访问发生错误了
- 由于我使用的是容器,因此在docker-compose或者dockerfile里将配置项改为:
shm_size: 64G → shm_size: 128G - shm_size,共享内存(shared memory)
- 之后就基本不报错了。。。
后续发现其实是某张卡有问题,
- 0~3一共4个GPU,只在使用0号GPU的时候会出问题
- 0号卡似乎是被某个进程锁了,还是怎么样,不用那个卡就没事了
1. 错误描述
例行吐槽,第一次遇到这个错误,我是非常无语的。以前是不报错的,和以前相比,不同的地方有
- 数据变多了,从80例变成了100例
- 换了个docker镜像,可能pytorch版本和cuda版本上有些问题
- 检查了代码,没有发生修改
2. 自我尝试
2.1 减小batch_size
感觉上可能会和显存有点关系吧
第一次报错
- 结合自己的代码,我这个是在第一个epoch训练完成,validation阶段报的错(line 243)
- 报错后调整
batch_size变小(10→8),继续报错

- 不过上一步validation的地方已经走过去了,line 258报错
- 说明把batch_size变小是有一定的效果的
按照这个思路继续把batch_size调小(8→5),又换了个位置报错。。

- line 305报错
2.2 换卡改代码
换思路
- 换了张卡,从0卡变到了1卡。。
- 删除了非必须的CPU和GPU交换数据部分的代码
- 依然报错

- 用两张卡,batch_size设置10,不使用预训练模型,还是报错
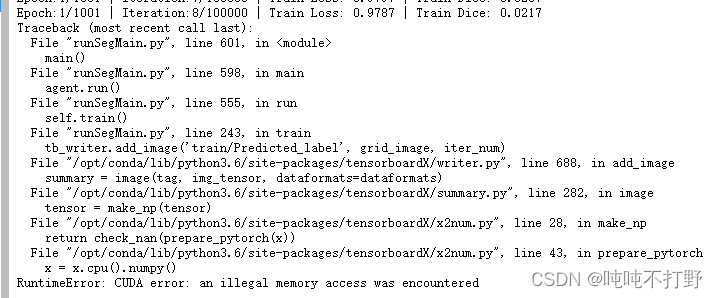
- 从头训练,单卡,batch_size=5
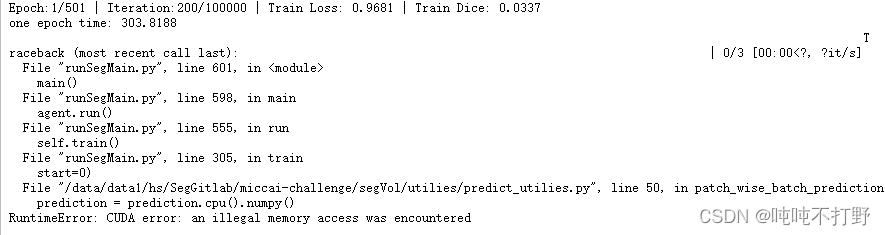
- 从头训练,单卡,batch_size=4

情况好了一点,都跑到第8个epoch了。但是还是断了
3. 调研情况
报错信息是CUDA丢出来的一个运行时错误,发生了非法内存访问。网上关于这个问题的讨论也很多,但是并没有发现有找到真正原因的。
很多都是靠感觉的
参考:
- pytorch的github issue:RuntimeError: CUDA error: an illegal memory access was encountered
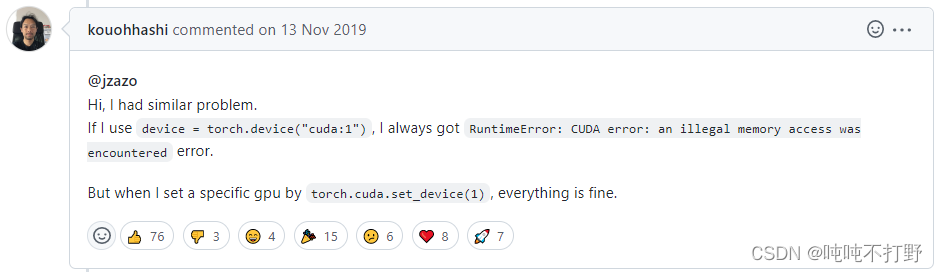
- 这个回答好像有效的人比较多,一次惨痛的debug的经历-RuntimeError: CUDA error: an illegal memory access was encountered,这个人就是这么解决的
- 另外还有一些是经验论的,
- yolo的GitHub issue:Cuda illegal memory access when running inference on *.engine #6311
文章出处登录后可见!
已经登录?立即刷新