
我们知道Openai的聊天机器人可以回答用户提出的绝大多数问题,它几乎无所不知,无所不能,但是由于有机器人所学习到的是截止到2021年9月以前的知识,所以当用户询问机器人关于2021年9月以后发送的事情时,它无法给出正确的答案,另外用户向机器人提问的字符串(prompt)长度被限制在4096个token(token可以看作是一种词语单位)。如果用户的prompt的长度超过4096个token时,机器人通常会抛出一个“异常”提示信息:

我们想要做的是让像openai聊天机器人这样的大型语言模型(LLMs)学习特定领域内的知识,这些特定的领域的知识可能是几本电子书,几十个文本文件,或者是关系型数据库,我们想要LLMs模型学习用户给定的数据,并且只回答给定数据范围内的相关问题,如果问题超出范围,一律告知用户问题超出范围无法回答,也就是我们要限制LLMs模型自由发挥,不能让它随便乱说。能否执行这样的功能呢?
LangChain
LangChain 是一种LLMs接口框架,它允许用户围绕大型语言模型快速构建应用程序和管道。 它直接与 OpenAI 的 GPT-3 和 GPT-3.5 模型以及 Hugging Face 的开源替代品(如 Google 的 flan-t5 模型)集成。
LangChain可用于聊天机器人、生成式问答(GQA)、本文摘要等。
LangChain的核心思想是我们可以将不同的组件“链接”在一起,以围绕 LLM 创建更高级的用例。 链(chain)可能由来自多个模块的多个组件组成。
今天我们要实现的功能是,让LLMs模型(如openai的聊天机器人)学习我提供的3个文本文件中的内容,并根据这些文件中的内容来回答相关问题,当问题超出范围时一律给出提示,并且机器人不会有任何自由发挥的空间。而我们提供的3个文本文件都是百度百科中拷贝下来的2022年发生的国内外时事新闻:
- 2022年卡塔尔世界杯。
- 日本请首相安倍晋三遇刺案。
- 埃隆·马斯克收购推特案。
为此我们从百度百科中将上述三个2022年的时事新闻网页中的内容拷贝出来,分别存储为三个文本文件:
- 2022世界杯.txt
- 埃隆·马斯克收购推特案.txt
- 安倍晋三遇刺案.txt
由于我们从百度百科上下载的这3篇时事新闻均发生在2022年,而ChatGPT只学习到了截止2021年9月之前的知识,因此它将无法准确回答关于这3个时事新闻的以外的其他问题。并且这些时事新闻都有较大的篇幅,且长度均超过了4096个token的长度,这正好被用来测试ChatGPT对特定数据的学习能力以及回答相关问题的能力。
这里我们会用到一种称为文本嵌入(Embeddings)的技术:

安装依赖包
我们需要安装如下依赖包:
pip install langchain
pip install openai
pip install chromadb
pip install jieba
pip install unstructured 导入依赖包
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import TokenTextSplitter
from langchain.llms import OpenAI
from langchain.chains import ChatVectorDBChain
from langchain.document_loaders import DirectoryLoader
import jieba as jb文档预处理
由于中文的语法的特殊性,对于中文的文档必须要做一些预处理工作:词语的拆分,也就是要把中文的语句拆分成一个个基本的词语单位,这里我们会用的一个分词工具:jieba,它会帮助我们对资料库中的所有文本文件进行分词处理。不过我们首先将这3个时事新闻的文本文件放置到Data文件夹下面,然后在data文件夹下面再建一个子文件夹:cut, 用来存放被分词过的文档:
files=['2022世界杯.txt','埃隆·马斯克收购推特案.txt','安倍晋三遇刺案.txt']
for file in files:
#读取data文件夹中的中文文档
my_file=f"./data/{file}"
with open(my_file,"r",encoding='utf-8') as f:
data = f.read()
#对中文文档进行分词处理
cut_data = " ".join([w for w in list(jb.cut(data))])
#分词处理后的文档保存到data文件夹中的cut子文件夹中
cut_file=f"./data/cut/cut_{file}"
with open(cut_file, 'w') as f:
f.write(cut_data)
f.close()文本嵌入(Embeddings)
接下来我们要按照LangChain的流程来处理这些经过中文分词处理的数据,首先是加载文档,然后要对文档进行切块处理,切块处理完成以后需要调用openai的Embeddings方法进行文本嵌入操作和向量化操作,最后我们需要创建一个聊天机器人的chain, 这个chain可以加载openai的各种语言模型,这里我们加载gpt-3.5-turbo模型。
#加载文档
loader = DirectoryLoader('./data/cut',glob='**/*.txt')
docs = loader.load()
#文档切块
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
doc_texts = text_splitter.split_documents(docs)
#调用openai Embeddings
os.environ["OPENAI_API_KEY"] = "your-openai_api_key"
embeddings = OpenAIEmbeddings(openai_api_key=os.environ["OPENAI_API_KEY"])
#向量化
vectordb = Chroma.from_documents(doc_texts, embeddings, persist_directory="./data/cut")
vectordb.persist()
#创建聊天机器人对象chain
chain = ChatVectorDBChain.from_llm(OpenAI(temperature=0, model_name="gpt-3.5-turbo"), vectordb, return_source_documents=True)创建聊天函数
接下来我们要创建一个聊天函数,用来让机器人回答用户提出的问题,这里我们让机器人每次只针对当前问题进行回答,并没有将历史聊天记录保存起来一起喂给机器人。
def get_answer(question):
chat_history = []
result = chain({"question": question, "chat_history": chat_history});
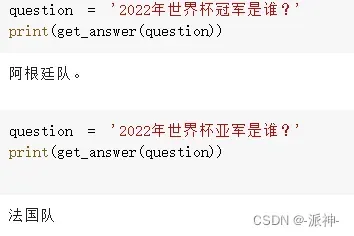
return result["answer"]下面是我和机器人之间就2022年3个时事新闻进行针对性聊天的内容:






总结
今天我们用LangChain对接了大型语言模型(LLMs), 并让LMMs可以针对性的学习用户给定的特定数据,这些数据可以是文本文件,数据库,知识库等结构化或者非结构化的数据。当用户询问的问题超出范围时,机器人不会给出任何答案,只会给出相关的提示信息显示用户的问题超出了范围,这样可以有效限制机器人自由发挥,使机器人不能让它随便乱说。
文章出处登录后可见!