ex1data1数据集如下
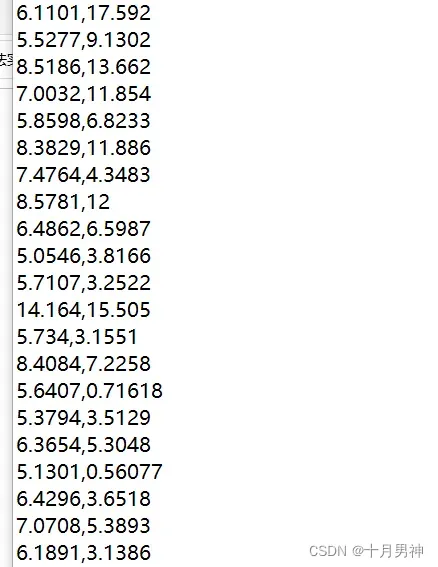
前一列代表人口,后一列代表利润,所以变量只有人口。现在我们需要对数据集进行线性拟合并以图形方式显示。
具体python代码展示如下:
1,首先是库函数的引用和原始数据的绘制
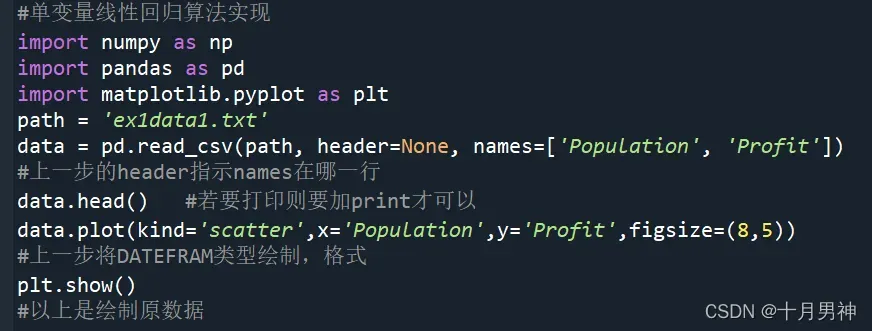
用到了numpy库,pandas库,matplotlib库中的pyplot模块(写在程序开头)
path指明文件名,文件名以字符串形式写(需注意若如此写则该py文件应和数据集txt文件在同一目录下)
pandas读取CSV文件方法:pd.read_csv(path,header=None,names=[‘population’,’profit’])
参数path上文已说明,参数header表示names=[‘population’,’profit’]所插入的位置(默认为行插入),header=None表示插入第一行,并命名第一列数据为population,第二列为profit,读入数据赋给变量data,可知data是dataframe类型
data.head()默认观察前五行数据,可在括号中指明数字(需加print进行打印)
data.plot(kind=’scatter’,x=’population’,y=’profit’,figsize=(8,5))#dataframe类型数据绘制,scatter表示绘制散点图,figsize表示画布大小
2,定义代价函数
def computecost(X,Y,theta):
inner=np.power(((X*theta.T)-Y),2)
return np.sum(inner)/(2*len(X))np.power()对数组的每个元素次方np.sum()对数组所有元素求和//len(X)表示X数据的行数即样本数
注意X与theta相乘的顺序
3,数据初始化
data.insert(0,'ones',1) #插入常数项1,并将一列名为ones
colums=data.shape[1] #统计数据的列数
X=data.iloc[:,-1] #对数据索引分别赋给X,y
y=data.iloc[:,colums-1:colums]
X=np.matrix(X.values) #由于后续要进行矩阵乘法,故对X,y的数字矩阵化
y=np.matrix(y.values)
theta=np.matrix(np.array([0,0])) #设置参数一个常数项一个变量项dataframe类型的插入:df.insert(0,’ones’,1) 默认插入列,在位置0前插入一列1且列名是ones
dataframe类型索引:df.iloc[,]逗号前表示行,逗号后表示列
注意变量y的赋值:data.iloc[:,colums-1:colums]若不这样写y的维度会从(97,1)变为(1,97),不利于数据处理
4,定义梯度下降函数
def gradientdescent(X,Y,theta,alpha,iters):
temp=np.matrix(np.zeros(theta.shape))
parameters=int(theta.ravel().shape[1]) #参数
cost=np.zeros(iters)
for i in range(iters):
error=(X*theta.T)-Y
for j in range(parameters):
term=np.multiply(error, X[:,j])#指各元素相乘
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta=temp
cost[i]=computecost(X, Y, theta)
return theta,costiters表示梯度迭代的次数,alpha是学习率,parameters统计参数的个数,cost数组记录每次迭代的代价函数值,观察算法是否正常工作
注意X与theta相乘的顺序
np.zeros() 生成一维元素为0的数组
np.ravel() 用于将数组降为一维即一维排列
np.multiply(a,b) a,b数组对应位置元素相乘
temp[0,j]表示temp矩阵中第0行第j列的位置
5,函数调用和预测
alpha=0.01 #设置学习率
iters=1500 #设置迭代次数
g,cost=gradientdescent(X, Y, theta, alpha, iters)
#以下是预测人数是35000,70000的利润
predict1 = [1,3.5]*g.T
print("predict1:",predict1)
predict2 = [1,7]*g.T
print("predict2:",predict2)6,拟合曲线的绘制
#第一种绘制拟合曲线方法
m=np.linspace(data.Population.min(),data.Population.max(),100) #添加数据
n=g[0,0]+g[0,1]*m #numpy数组的广播机制给所有元素都乘同一个数,都加一个数
#视频中的老方法绘图也可以
#绘制预测图
fig, ax = plt.subplots(figsize=(12,8)) #共同定义了一个坐标在同一张图绘图
ax.plot(m,n , 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2) #添加图例
ax.set_xlabel('Population') #x轴标签
ax.set_ylabel('Profit') #y轴标签
ax.set_title('Predicted Profit vs. Population Size') #表格标题
plt.show()#第二种绘制图形方法,先设置图片大小再分步绘图
fig=plt.figure(figsize=(12,8),dpi=80)
plt.plot(x,f,"r",label='prediction')
plt.scatter(data.Population,data.Profit,label='traing data')
plt.legend()#添加图例
plt.xlabel("population")
plt.ylabel('profit')
plt.show()g[0,0] 与g[0,1]表示常数项参数和变量参数
n=g[0,0] +g[0,1]*m运用numpy数组的广播机制,相乘和相加都是对每一个元素
np.linspace(start,stop,num)从start到stop中选取num个数字组成数组
总结:
1,主要是对numpy数组和dataframe类型理解不透彻,无法灵活运用
2,对于库函数中的方法不了解,使得编程困难
3,cost,gradient函数的定义编写
4,注意式中X与theta相乘的顺序
版权声明:本文为博主machine-learning进行中原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_56769994/article/details/123311804