【NLP相关】PyTorch多GPU并行训练(DataParallel和DistributedDataParallel介绍、单机多卡和多机多卡案例展示)
当下深度学习应用越来越广泛,训练规模也越来越大,需要更快速的训练速度来满足需求。而多GPU并行训练是实现训练加速的一种常见方式,本文将介绍如何使用PyTorch进行多GPU并行训练。
1. 原理
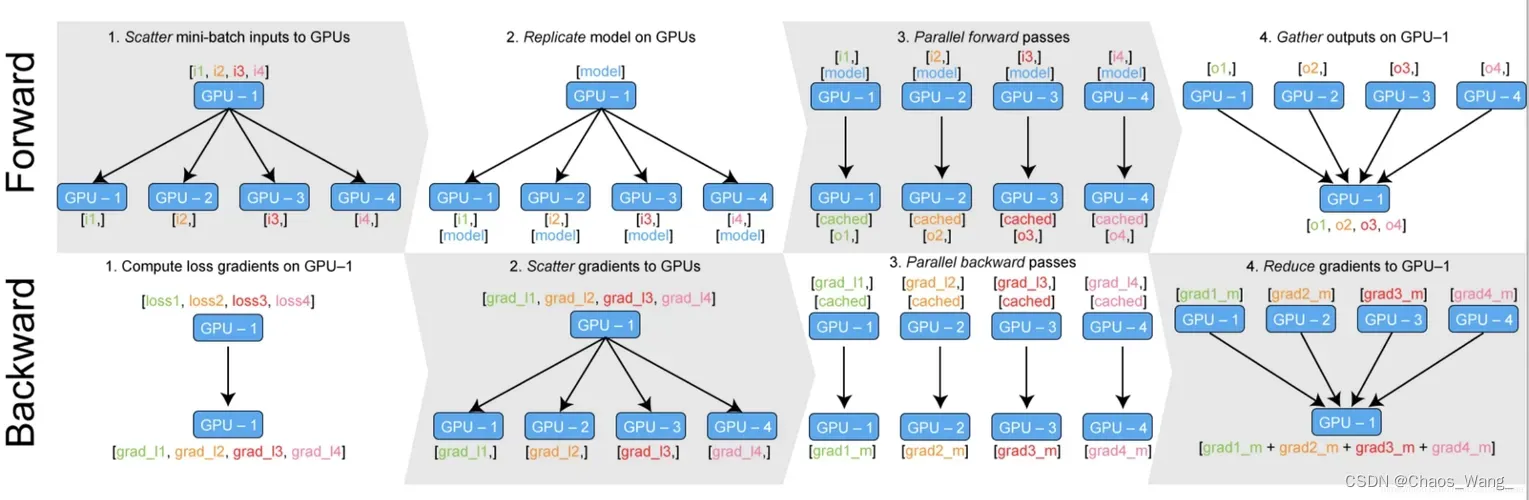
多GPU并行训练的原理就是将模型参数和数据分布到多个GPU上,同时利用多个GPU计算加速训练过程。具体实现需要考虑以下两个问题:
数据如何划分?因为模型需要处理的数据通常很大,将所有数据放入单个GPU内存中可能会导致内存不足,因此我们需要将数据划分到多个GPU上。一般有两种划分方式:
- 数据并行:将数据分割成多个小批次,每个GPU处理其中的一个小批次,然后将梯度汇总后更新模型参数。
- 模型并行:将模型分解成多个部分,每个GPU处理其中一个部分,并将处理结果传递给其他GPU以获得最终结果。
计算如何协同?因为每个GPU都需要计算模型参数的梯度并将其发送给其他GPU,因此需要使用同步机制来保证计算正确性。一般有两种同步方式:
- 数据同步:在每个GPU上计算模型参数的梯度,然后将梯度发送到其他GPU上进行汇总,最终更新模型参数。
- 模型同步:在每个GPU上计算模型参数的梯度,然后将模型参数广播到其他GPU上进行汇总,最终更新模型参数。
2. 不同方法的优劣势
目前主要有两种PyTorch的多GPU并行训练方式:nn.DataParallel和DistributedDataParallel,它们各有优劣势。
2.1 nn.DataParallel
nn.DataParallel是PyTorch提供的一种数据并行方式,适用于单机多GPU的情况,使用非常方便,只需要在模型前加上nn.DataParallel即可。nn.DataParallel的优点是使用简单、易于理解,而且能够充分利用多个GPU进行训练。但是nn.DataParallel也有缺点,主要体现在以下两个方面:
- 内存占用:nn.DataParallel会将整个模型复制到每个GPU上,因此需要占用大量的GPU内存。当模型非常大时,可能会导致内存不足。
- 数据通信:nn.DataParallel使用的是数据并行方式,需要将每个GPU上的梯度进行汇总,因此需要进行大量的数据通信,可能会导致训练速度的下降。
2.2 DistributedDataParallel
DistributedDataParallel是PyTorch提供的一种更加高级的多GPU并行训练方式,适用于多机多GPU的情况。DistributedDataParallel使用了数据并行和模型并行两种方式,通过将模型参数和梯度分布到不同的GPU上来充分利用多个GPU进行训练。DistributedDataParallel的优点是在内存占用和数据通信方面优于nn.DataParallel,能够更加高效地利用多个GPU进行训练。但是使用DistributedDataParallel需要一定的分布式编程经验,使用也相对比较复杂。
3. 代码展示
下面展示如何使用nn.DataParallel和DistributedDataParallel进行多GPU并行训练。
3.1 nn.DataParallel
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(5, 2)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.softmax(x)
return x
model = MyModel()
# 定义数据和优化器
train_data = torch.randn(100, 10)
train_labels = torch.randint(0, 2, (100,))
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 将模型放入DataParallel中
model = nn.DataParallel(model)
# 训练模型
for epoch in range(10):
for i, (data, labels) in enumerate(DataLoader(zip(train_data, train_labels), batch_size=10)):
optimizer.zero_grad()
outputs = model(data)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()
if i % 10 == 0:
print(f"Epoch {epoch}, Iteration {i}, Loss {loss.item():.4f}")
3.2 DistributedDataParallel
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.utils.data import DataLoader
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(5, 2)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.softmax(x)
return x
def train(model, rank, world_size):
# 初始化进程组
dist.init
# 获取数据
train_data = torch.randn(100, 10)
train_labels = torch.randint(0, 2, (100,))
train_sampler = torch.utils.data.distributed.DistributedSampler(
dataset=torch.utils.data.TensorDataset(train_data, train_labels),
num_replicas=world_size,
rank=rank,
shuffle=True,
)
train_loader = torch.utils.data.DataLoader(
dataset=torch.utils.data.TensorDataset(train_data, train_labels),
batch_size=10,
sampler=train_sampler,
)
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 将模型放入DistributedDataParallel中
model = nn.parallel.DistributedDataParallel(model, device_ids=[rank])
# 训练模型
for epoch in range(10):
for i, (data, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(data)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()
if i % 10 == 0 and rank == 0:
print(f"Epoch {epoch}, Iteration {i}, Loss {loss.item():.4f}")
def main():
# 初始化多进程
mp.spawn(
train,
args=(world_size,),
nprocs=world_size,
join=True,
)
if __name__ == "__main__":
world_size = 2
mp.set_start_method("spawn")
main()
4. 案例解析
4.1 NLP领域-单机多卡
接下来我们将介绍如何使用PyTorch进行单机多卡训练。这里我们以Transformer模型为例,来说明如何进行单机多卡训练。
在单机多卡训练中,我们需要使用PyTorch的nn.DataParallel模块来实现模型的多卡并行。这个模块会自动将模型的输入数据分发到多个GPU上进行并行计算,然后将结果合并到单个GPU上进行梯度计算和参数更新。
(1)环境准备
首先,我们需要导入必要的包:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
from torch.utils.data import DataLoader, RandomSampler
from transformers import BertTokenizer, BertForSequenceClassification
from transformers.optimization import AdamW, get_linear_schedule_with_warmup
import os
import random
import numpy as np
这里我们使用了transformers库来加载预训练的BERT模型。
接下来,我们需要设置训练环境。这里我们假设我们有4个GPU可用,并使用nn.DataParallel模块进行多卡并行训练。我们可以通过以下代码来初始化训练环境:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model.to(device)
这里torch.device()会自动检测当前环境是否支持GPU,并返回一个GPU设备或CPU设备。如果有多个GPU可用,则使用nn.DataParallel模块将模型进行多卡并行。最后,我们将模型移动到指定的设备上。
(2)数据准备
接下来,我们需要加载数据集。这里我们使用的是IMDB电影评论分类数据集,包含50,000条电影评论,每条评论都被标记为正面或负面。我们将使用BERT模型来对这些评论进行分类。
class IMDBDataset(data.Dataset):
def __init__(self, tokenizer, data_path):
self.tokenizer = tokenizer
self.sentences = []
self.labels = []
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
sentence, label = line.strip().split("\t")
self.sentences.append(sentence)
self.labels.append(int(label))
def __getitem__(self, index):
sentence = self.sentences[index]
label = self.labels[index]
inputs = self.tokenizer.encode_plus(sentence,
add_special_tokens=True,
padding="max_length",
max_length=512,
return_tensors="pt")
input_ids = inputs["input_ids"][0]
attention_mask = inputs["attention_mask"][0]
return input_ids, attention_mask, label
def __len__(self):
return len(self.labels)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
train_dataset = IMDBDataset(tokenizer, "data/train.tsv")
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=16)
这里我们使用了transformers库提供的BertTokenizer来对文本进行编码。接下来,我们将训练数据集封装为一个IMDBDataset类,其中__getitem__方法会返回每个样本的输入ID、注意力掩码和标签。然后,我们使用DataLoader将数据集分成多个小批量进行训练。
(3)模型训练
现在我们可以开始训练我们的模型了。这里我们使用了BERT的预训练模型BertForSequenceClassification,它已经包含了一个全连接层用于分类任务。我们只需要在顶部添加一个全连接层来进行微调。
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=100, num_training_steps=1000)
criterion = nn.CrossEntropyLoss()
接下来,我们可以开始训练模型了。这里我们使用了nn.DataParallel模块将模型并行化,同时使用了学习率调度器来动态调整学习率。
for epoch in range(10):
model.train()
for step, batch in enumerate(train_dataloader):
input_ids, attention_mask, labels = batch
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
if step % 100 == 0:
print("Epoch: {}, Step: {}, Loss: {}".format(epoch, step, loss.item()))
这里我们迭代了10个epoch,在每个epoch中,我们将训练数据集分成多个小批量,然后将每个小批量放到多个GPU上进行并行计算。在每个小批量计算完成后,我们将梯度合并到单个GPU上进行梯度更新。
4.2 NLP领域-多机多卡
下面给出一个NLP领域的多机多卡训练的例子,以BERT为例,使用PyTorch和Horovod库实现多机多卡训练。
Horovod是一个开源的分布式训练框架,可以实现多机多卡训练。它支持TensorFlow、PyTorch、MXNet等多个框架。在本例中,我们使用Horovod和PyTorch实现多机多卡训练。
import torch
import torch.nn as nn
from transformers import BertModel
from torch.utils.data import DataLoader, RandomSampler
from transformers import BertTokenizer
import horovod.torch as hvd
# 初始化Horovod
hvd.init()
# 获取本机的GPU数量和rank
local_rank = hvd.local_rank()
local_size = hvd.local_size()
# 设定GPU
torch.cuda.set_device(local_rank)
# 加载BERT模型
model = BertModel.from_pretrained('bert-base-uncased')
# 数据预处理
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
inputs = inputs.to(local_rank)
labels = torch.tensor([1]).unsqueeze(0)
labels = labels.to(local_rank)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
# Horovod准备
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
# 加载数据
dataset = []
for i in range(100):
dataset.append((inputs, labels))
sampler = RandomSampler(dataset)
batch_size = 4
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size // local_size)
# 训练模型
model.train()
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(dataloader, 0):
inputs, labels = data
inputs, labels = inputs.to(local_rank), labels.to(local_rank)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs[0], labels.squeeze())
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 10 == 9:
avg_loss = running_loss / 10
print(f"Rank {hvd.rank()} Epoch {epoch + 1} Step {i + 1} loss: {avg_loss:.4f}")
running_loss = 0.0
在代码中,我们首先使用hvd.init()初始化Horovod。然后使用hvd.local_rank()获取本机的GPU数量和rank,并使用torch.cuda.set_device(local_rank)指定当前进程使用的GPU。
接着加载BERT模型,并使用`BertTokenizer类对输入进行数据预处理。然后定义损失函数和优化器。
在Horovod的准备阶段,我们使用hvd.DistributedOptimizer()对优化器进行包装,以支持多机多卡训练。同时,我们使用hvd.broadcast_parameters()和hvd.broadcast_optimizer_state()将模型和优化器的状态广播给所有进程。
在加载数据时,我们使用RandomSampler和DataLoader对数据进行采样和分批。注意,我们将batch_size除以local_size,以确保每个进程处理的样本数量相同。
最后,在训练循环中,我们使用model.train()将模型设置为训练模式,并使用enumerate()遍历数据集。在每个循环中,我们将数据移到当前GPU上,并对模型进行前向传播、计算损失、反向传播和优化。注意,我们使用hvd.rank()打印每个进程的训练进度。
4.3 CV领域-单机多卡
下面我们来介绍一下CV领域的单机多卡训练的例子。
(1)数据准备
我们将使用CIFAR-10数据集来训练我们的模型。首先,我们需要使用torchvision库中的transforms模块来对图像进行预处理。
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],
std=[0.2023, 0.1994, 0.2010])
])
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128,
sampler=train_sampler,
num_workers=4, pin_memory=True)
这里我们定义了一个名为transform_train的预处理函数,它将图像随机裁剪为32×32大小,随机水平翻转,转换为张量,然后进行归一化处理。然后,我们使用torchvision中的CIFAR10类来加载训练数据集,并使用torch.utils.data.distributed.DistributedSampler来对数据集进行分布式采样。最后,我们使用torch.utils.data.DataLoader将数据集分成多个小批量进行训练。
(2)模型训练
我们将使用ResNet-18模型来训练我们的模型。首先,我们需要定义模型、优化器和学习率调度器。
model = models.resnet18(num_classes=10)
model.cuda()
model = nn.parallel.DataParallel(model)
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[150, 250], gamma=0.1)
这里我们使用了nn.parallel.DataParallel模块将模型并行化,并将模型移动到GPU上进行训练。我们使用交叉熵损失作为损失函数,随机梯度下降(SGD)作为优化器,并使用多步调度器来动态调整学习率。为了使模型更加稳定,我们还可以添加数据增强、批标准化等技术。这里我们使用torchvision中的transforms模块来添加数据增强和归一化操作,使用nn.BatchNorm2d模块来添加批标准化。
接下来,我们可以开始训练我们的模型了。
for epoch in range(350):
train_sampler.set_epoch(epoch)
train_loss = 0.0
correct = 0.0
total = 0.0
model.train()
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.cuda(), targets.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
train_acc = 100.0 * correct / total
train_loss = train_loss / len(train_loader)
if epoch % 10 == 0:
print("Epoch [{}/{}], Loss: {:.4f}, Train Acc: {:.2f}%".format(epoch+1, 350, train_loss, train_acc))
scheduler.step()
在训练过程中,我们使用DataParallel将模型在多个GPU上进行并行化,使得训练速度得到大幅提升。同时,我们使用DistributedSampler对数据集进行分布式采样,保证了多GPU之间的训练数据是不重复且均衡的。除此之外,我们还使用了多步调度器动态调整学习率,帮助模型更好地收敛。
4.4 CV领域-多机多卡
下面以训练图像分类模型为例,演示如何使用DistributedDataParallel进行多机多GPU并行训练。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
def train(model, rank, world_size):
# 初始化进程组
dist.init_process_group(
backend="nccl",
init_method="tcp://localhost:12345",
world_size=world_size,
rank=rank,
)
# 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform)
# 使用分布式sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset, num_replicas=world_size, rank=rank)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=False, num_workers=2, sampler=train_sampler)
# 定义优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(2):
train_sampler.set_epoch(epoch)
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取数据
inputs, labels = data
inputs, labels = inputs.to(rank), labels.to(rank)
# 梯度清零
optimizer.zero_grad()
# 正向传播和反向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 统计损失
running_loss += loss.item()
if i % 2000 == 1999:
print(f"[{rank}, {epoch + 1}, {i + 1}] loss: {running_loss / 2000:.3f}")
running_loss = 0.0
# 释放进程组
dist.destroy_process_group()
def main():
# 初始化多进程
world_size = 2
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()
这里使用了torchvision.datasets.CIFAR10数据集,加载数据时使用DistributedSampler进行分布式采样。模型训练时每个进程都需要独立的模型和优化器,并且需要将数据放入对应的GPU上。在训练过程中,使用dist.reduce()函数对所有进程的损失进行求和,然后再除以进程数,得到平均损失,最后输出平均损失即可。
这个例子中,我们使用了两台机器,每台机器上有一个GPU。在每台机器上运行一个进程,共运行两个进程。如果需要使用更多的机器和GPU,只需要将world_size设置为对应的值即可。
文章出处登录后可见!