政策梯度如何让您登上月球
强化学习实践课程——第 7 部分

策略梯度是一系列强大的强化学习算法,可以解决复杂的控制任务。在今天的课程中,我们将从头开始实施原版策略梯度并登陆月球🌗。
如果您不熟悉强化学习,请查看课程介绍以了解基础知识和术语。[0]
同样,您可以在此存储库中找到今天课程的所有代码👇🏽[0]

Contents
- 如何通过政策梯度登月? 🚀🌙
- The LunarLanderenvironment
- Baseline agent
- Welcome policy gradients 🤗
- Policy gradients agent
- Key take-aways
- Homework 📚
- What’s next?
1、如何通过政策梯度登月? 🚀🌙
为了登陆月球,我们使用宇宙飞船,这是一个巨大的模块化工程,结合了令人难以置信的力量和温和的精度。
在我们旅程的开始,我们使用强大的火箭(如下图所示)帮助宇宙飞船摆脱地球的引力。

一旦火箭被消耗,宇宙飞船就会将它们安全地释放到地球的海洋中,并开始其 385,000 公里(239,000 英里)的月球之旅。
3 天后,我们的宇宙飞船接近月球并开始绕月球运行。这场高超的戏剧的最后一幕是着陆。
宇宙飞船释放了一个装置,即月球着陆器,月球的引力场将其拉向其表面。我们整个任务的成功取决于这个装置的轻柔着陆。

在今天的讲座中,我们将使用强化学习来训练一个代理(又名控制器)以将该设备降落在月球上。
此外,我们将使用 OpenAI 的 LunarLander 环境作为着陆问题的方便(和简化)抽象。
最后,这就是您今天将实施的代理如何登陆月球。
2. The LunarLander environment
在进入建模部分之前,让我们快速熟悉一下 LunarLander 环境。
State
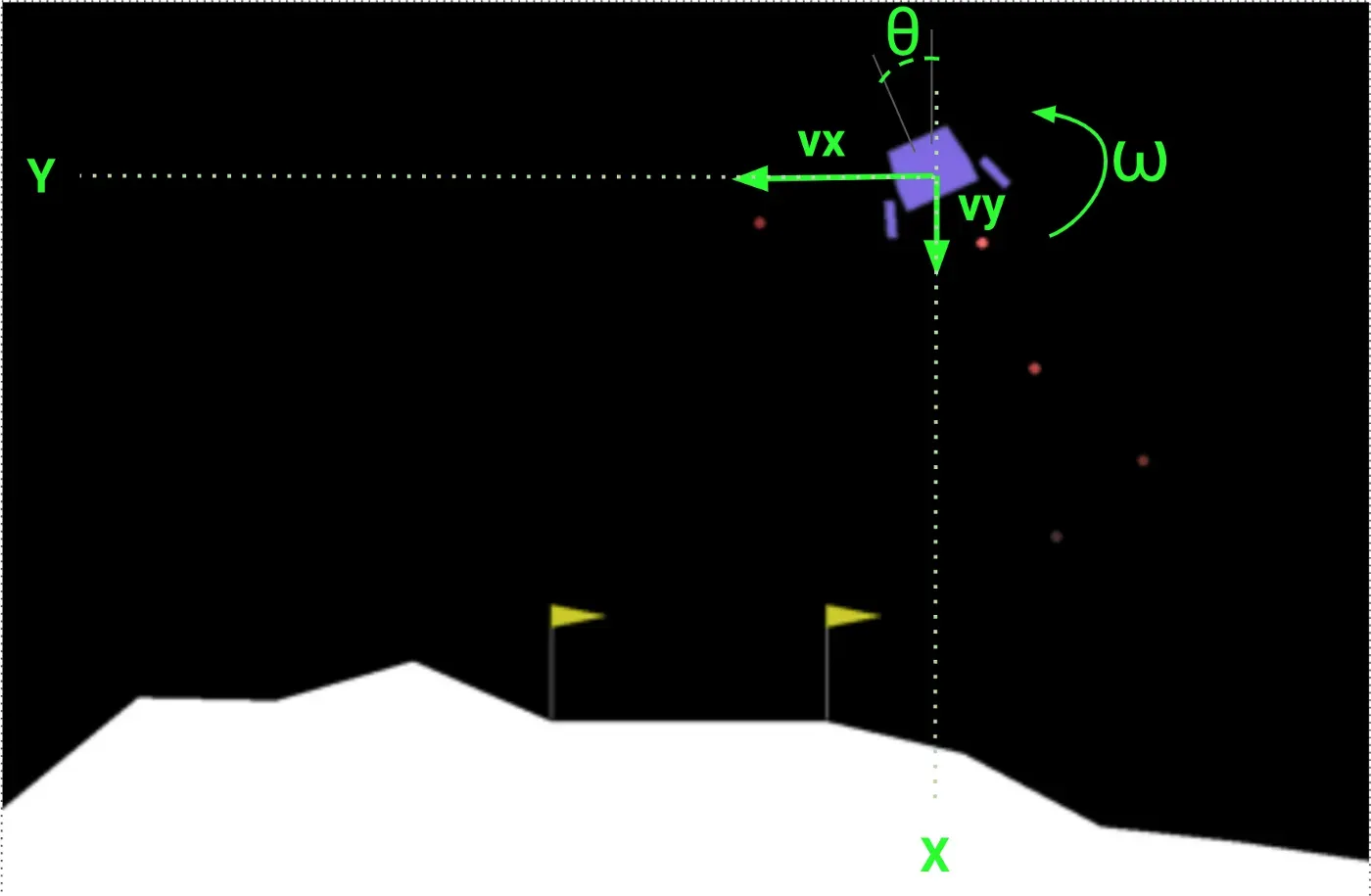
代理得到一个包含 8 个分量的状态向量:
- 2D 世界中的当前位置:x 和 y
- 沿这两个轴的速度:vx 和 vy
- 相对于垂直方向的角位置 θ:
- 角速度 ω,捕捉设备围绕其自身轴的旋转。
- 两个二进制信号(s1 和 s2),用于指示设备的 2 条腿中的哪条腿(如果有)与地板接触。
Actions
有 4 种可能的操作:
- 0 Do nothing.
- 1 点燃左侧发动机。
- 2 点燃主机(中央)。
- 3 Fire right engine.
Rewards
在这种环境下,奖励功能旨在为代理提供足够的信号。这使训练更容易。
这是着陆器在每个时间步获得的奖励:
- 如果着陆器离开着陆台,它会得到负奖励。
- 如果发生崩溃,它会获得额外的 -100 分。
- 如果涉及到休息,它会获得额外的 +100 分。
- 每条与地面接触的腿+10分。
- 启动主引擎是每帧 -0.3 点。
- 启动侧引擎是每帧 -0.03 点。
- 最后,解决的是200分。
奖励工程的优缺点
奖励工程是一种建模技巧,通过向代理提供频繁的反馈来帮助 RL 代理学习。奖励不频繁(又名稀疏)的环境更难解决。
但是,它有两个缺点:
👉🏽 奖励功能很难设计,就像你看到 LunarLander-v2 奖励后可能想象的那样。在找到鼓励智能体学习正确行为的奖励函数之前,通常需要进行大量的反复试验。
👉🏽 奖励塑造是特定于环境的,这限制了受过训练的代理对稍微不同的环境的泛化。此外,这限制了经过模拟训练的 RL 代理在现实世界环境中的可迁移性。
3. Baseline agent
👉🏽 notebooks/01_random_agent_baseline.ipynb[0]
像往常一样,我们使用随机代理获得问题的快速基线。
# create environment
import gym
env = gym.make('LunarLander-v2')
# create random agent
class RandomAgent:
def __init__(self, env):
self.env = env
def act(self, state) -> int:
"""
No input arguments to this function.
The agent does not consider the state of the environment when deciding
what to do next.
"""
return self.env.action_space.sample()
agent = RandomAgent(env)接下来,我们使用 100 集来评估这个代理,以获得总奖励和着陆器的成功率:
from tqdm import tqdm
n_episodes = 100
reward_per_episode = []
success_per_episode = []
for i in tqdm(range(0, n_episodes)):
state = env.reset()
total_reward = 0
done = False
reward = None
while not done:
action = agent.act(state)
next_state, reward, done, info = env.step(action)
total_reward += reward
state = next_state
reward_per_episode.append(total_reward)
success_per_episode.append(1 if reward > 0 else 0)然后我们绘制结果
import numpy as np
reward_avg = np.array(rewards).mean()
reward_std = np.array(rewards).std()
print(f'Reward average {reward_avg:.2f}, std {reward_std:.2f}')
success_rate = np.array(success_per_episode).mean()
print(f'Succes rate = {success_rate:.2%}')终于意识到我们的代理是一场彻头彻尾的灾难
Reward average -198.35, std 103.93
Succes rate = 0.00%*由于代理的固有随机性,当您在笔记本电脑上运行笔记本时,这些数字不会完全相同。无论如何,成功率几乎肯定是0%。
此外,您可以观看此随机代理的视频,以说服自己我们远未解决问题。
# Workaround for pygame error: "error: No available video device"
# See https://stackoverflow.com/questions/15933493/pygame-error-no-available-video-device?rq=1
# This is probably needed only for Linux
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from src.viz import show_video
show_video(agent, env, sleep_sec=0.01, seed=12345)事实证明,登陆月球并不是小菜一碟(真是惊喜)
让我们看看政策梯度如何帮助我们登上月球。
4. Welcome policy gradients 🤗
任何强化学习问题的目标都是找到最大化累积奖励的最优策略。
到目前为止,在课程中,我们使用了基于价值的方法,例如 Q-learning 或 SARSA。这些方法以间接的方式找到最优策略,首先找到最优 Q 函数,然后使用这个 Q 函数按照 epsilon-greedy 策略选择次优动作。通过这种方式,他们提出了最优策略。[0][1]
另一方面,基于策略的方法直接找到最优策略,而不必估计最优 Q 函数。
基于策略的方法中的两个基本步骤如下:
Step 1. Policy parameterization
我们使用神经网络模型来参数化最优策略。该策略被建模为随机策略,而不是确定性策略。我们称其为策略网络,我们将其表示为
随机政策和探索与开发的权衡
随机策略将给定的观察(输入)映射到概率列表,每个概率对应一个可能的动作。
为了选择下一步要采取的行动,代理会根据其概率对行动进行抽样。因此,随机策略自然地处理了探索与利用的权衡,没有像 epsilon 这样的超参数技巧(如 Q 学习中使用的 epsilon-greedy 技巧)。
在 LunarLander-v2 环境中,我们的随机策略将有 8 个输入和 4 个输出。 4 个输出中的每一个代表采取 4 个动作中的每一个的概率。
策略网络的架构是您需要试验的超参数。我们今天将使用的那个有一个包含 64 个单元的隐藏层。
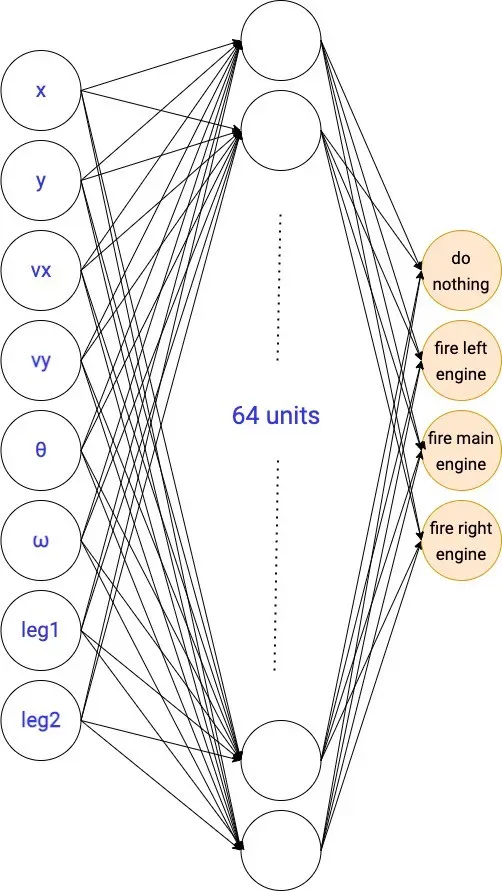
解决我们的 RL 问题相当于找到这个神经网络的最优参数。
但是我们究竟如何找到这个网络的最佳参数呢?
步骤 2. 找到最优参数的策略梯度
评估策略的好坏很容易:
- 首先,我们对 N 个随机剧集遵循此策略并收集每集的总奖励
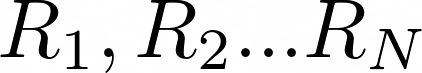
- 其次,我们对这 N 个总奖励进行平均,并获得一个整体绩效衡量标准。这个表达式是总奖励的经验平均值。
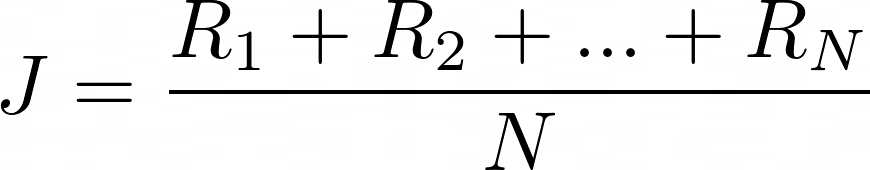
此外,总奖励和 J 取决于策略参数 θ,我们的目标是找到使 J 最大化的参数 θ。
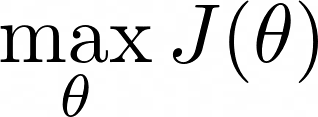
同样,有不同的算法可以解决这个最大化问题(例如遗传优化),但在深度学习中,基于梯度的方法才是王道👑。
基于梯度的方法如何工作?
我们从策略参数 θ₀ 的初始猜测开始,我们希望找到一组更好的参数 θ₁
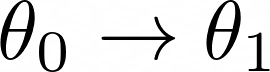
θ₁ 和 θ₀ 之间的差异是我们在参数空间中行进的方向。
问题是,增加 J 的最佳方向是什么?
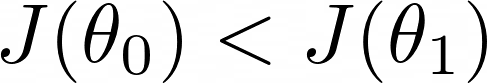
答案是……梯度。
What is it?
函数 J 相对于参数向量 θ 的梯度是我们需要从 θ 采取的方向,以产生 J 的最大增加。
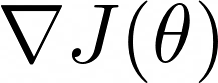
但是,我们应该在梯度方向移动的距离呢?
这是另一个(非常流行的)超参数:学习率 α
配备梯度和适当调整的学习率,我们执行梯度上升的一步以得出更好的参数向量 θ₁
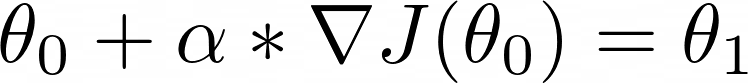
如果我们迭代地重复这个公式,我们将获得更好的策略参数,并有望解决环境问题。
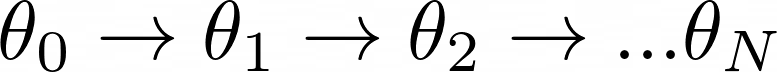
这就是梯度上升如何帮助我们找到最优策略网络参数。
剩下的问题是,我们如何计算这些梯度?
估计策略性能的梯度
为了实现这个算法,我们需要一个可以数值计算的策略性能梯度表达式。
可以通过一点微积分和统计在数学上证明,可以使用使用当前策略收集的轨迹样本来近似策略参数,如下所示:
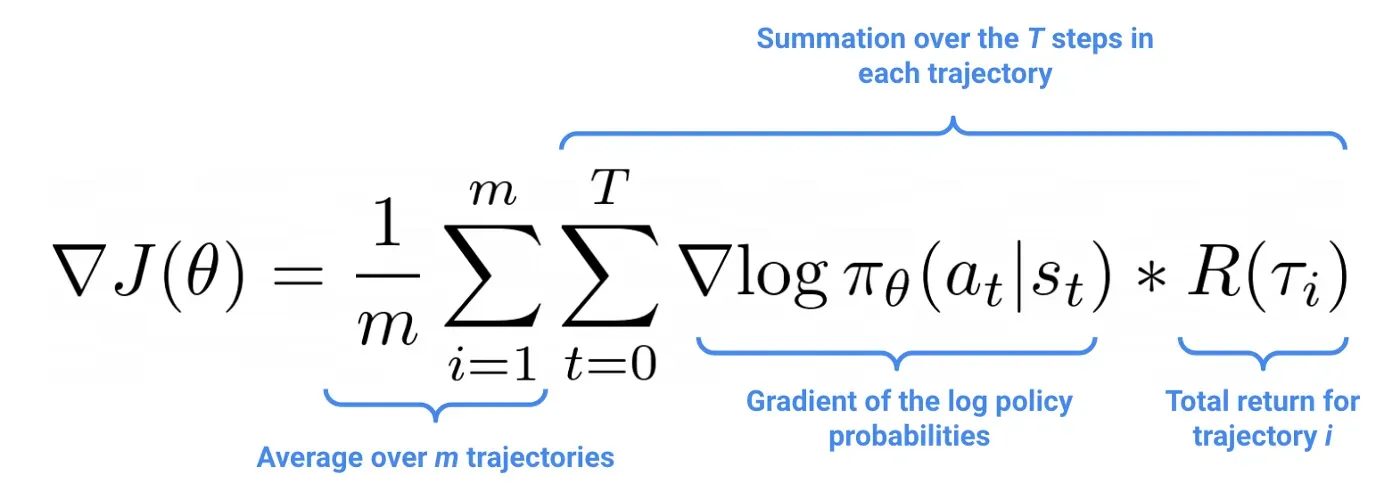
其中轨迹 𝛕 是观察到的状态序列和直到剧集结束所采取的行动
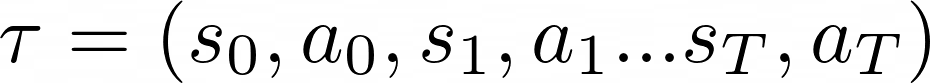
重要的是要强调一个事实,这些轨迹必须使用当前的政策参数来收集。
On-policy 与 off-policy 算法
策略梯度方法是策略上的算法,意味着我们只能使用在当前策略下收集的经验来改进当前策略。
另一方面,使用诸如 Q-learning 之类的离策略算法,我们可以保留轨迹的回放记忆,收集旧版本的策略,并使用它们来改进当前策略。
此外,上面的公式对应于最简单的策略梯度方法。然而,这个公式有一些变化,它取代了每条轨迹的总回报 R(τᵢ)
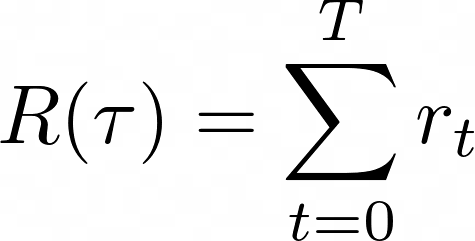
与其他成功指标。
特别是,我们将在本课程中看到 2 个版本,一个今天,另一个在下一课:
- 给定动作后的累积奖励,即奖励执行
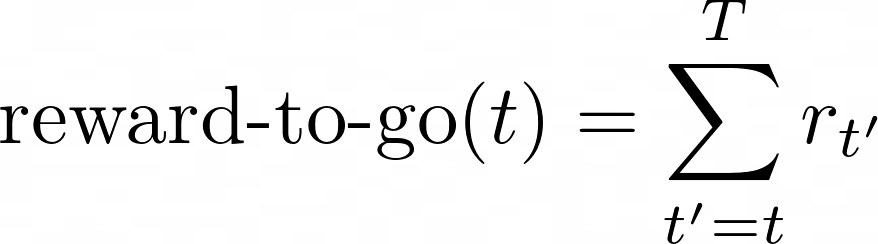
- 优势函数,即当前策略的 Q 函数和 V 函数之间的差异。

如果我们已经有一个,为什么我们需要替代公式来估计梯度?
策略梯度公式的所有 3 个变体都具有相同的期望值,因此如果您使用非常大的轨迹样本,这 3 个数字将非常相似。然而,对于计算性能,我们只能提供一小组轨迹,因此这些估计的可变性很重要。
In particular
- 奖励执行版本的方差低于原始公式
- 并且优势函数版本的方差甚至小于reward-to-go版本。
较低的方差导致更快和更稳定的策略学习。
今天,我们将实现reward-to-go 版本,因为它几乎和原始的带有累积奖励的普通策略梯度公式一样复杂。在下一节课中,我们将看到如何估计优势函数并获得更好的结果。
想了解详情吗?
由于本课程的目的是为您提供对该主题的实践方法,因此我将数学技术保持在最低限度。
如果您想了解从上面推导策略梯度公式的所有步骤,我建议您阅读 Wouter van Heeswijk 的这篇出色的博客文章📝。[0]
5. Policy gradients agent
👉🏽 notebooks/03_vanilla_policy_gradient_with_rewards_to_go.ipynb[0]
让我们实现最简单的策略梯度代理,其中策略梯度公式中的权重是情节奖励。
超参数只有3个:
- learning_rate 是策略梯度更新的大小。
- hidden_layers 定义策略网络架构。
- gradient_weights 是每个时间步的奖励:即从当前时间步到剧集结束的奖励总和。
ENV_NAME = 'LunarLander-v2'
from src.vpg_agent import VPGAgent
agent = VPGAgent(
env_name=ENV_NAME,
learning_rate=3e-3,
hidden_layers=[64],
gradient_weights='rewards',
)我们使用 Tensorboard 设置基本日志记录并开始训练我们的 VPGAgent:
# unique agent_id to identify this run in tensorboard
from src.utils import get_agent_id
agent_id = get_agent_id(ENV_NAME)
# tensorboard logger to see training curves
from src.utils import get_logger, get_model_path
logger = get_logger(env_name=ENV_NAME, agent_id=agent_id)
# path to save policy network weights and hyperparameters
model_path = get_model_path(env_name=ENV_NAME, agent_id=agent_id)
# let's train!
agent.train(
n_policy_updates=5000,
batch_size=256,
logger=logger,
model_path=model_path,
)训练逻辑封装在您可以在 src/vgp_agent.py 中找到的 agent.train() 函数中。这个函数本质上是一个带有 n_policy_updates 迭代的循环,在每次迭代中我们:[0]
- 收集 batch_sizetrajectories 的样本
- 使用随机梯度上升更新策略参数。
- 将指标记录到 Tensorboard
- 可能评估当前代理,如果它是我们迄今为止找到的最佳代理,则将其保存到磁盘。
for i in range(n_policy_updates):
# use current policy to collect trajectories
states, actions, weights, rewards = self._collect_trajectories(n_samples=batch_size)
# one step of gradient ascent to update policy parameters
loss = self._update_parameters(states, actions, weights)
# log epoch metrics
print('epoch: %3d \t loss: %.3f \t reward: %.3f' % (i, loss, np.mean(rewards)))
if logger is not None:
# we use total_steps instead of epoch to render all plots in Tensorboard comparable
# Agents wit different batch_size (aka steps_per_epoch) are fairly compared this way.
total_steps += batch_size
logger.add_scalar('train/loss', loss, total_steps)
logger.add_scalar('train/episode_reward', np.mean(rewards), total_steps)
# evaluate the agent on a fixed set of 100 episodes
if (i + 1) % freq_eval_in_epochs == 0:
rewards, success = self.evaluate(n_episodes=100)
avg_reward = np.mean(rewards)
avg_success_rate = np.mean(success)
if save_model and (avg_reward > best_avg_reward):
self.save_to_disk(model_path)
print(f'Best model! Average reward = {avg_reward:.2f}, Success rate = {avg_success_rate:.2%}')
best_avg_reward = avg_reward什么是正确的 batch_size 使用?
每个策略更新的轨迹数(又名 batch_size)是您需要调整的超参数,以确保您的训练在合理的时间内收敛到最佳解决方案。
👉🏽 如果 batch_size 太低,你会得到非常嘈杂的梯度估计,并且训练不会收敛到最优策略。
👉🏽 相反,如果batch_size 太大,训练循环会不必要地变慢,你会坐等🥱
Plotting training results
在模型训练时,我们转到终端并启动 Tensorboard 服务器,如下所示:
$ tensorboard --logdir tensorboard_logs如果您访问打印在控制台上的 URL,您将看到与此类似的图表,其中横轴是代理到目前为止收集的轨迹总数,纵轴是每集的总奖励。
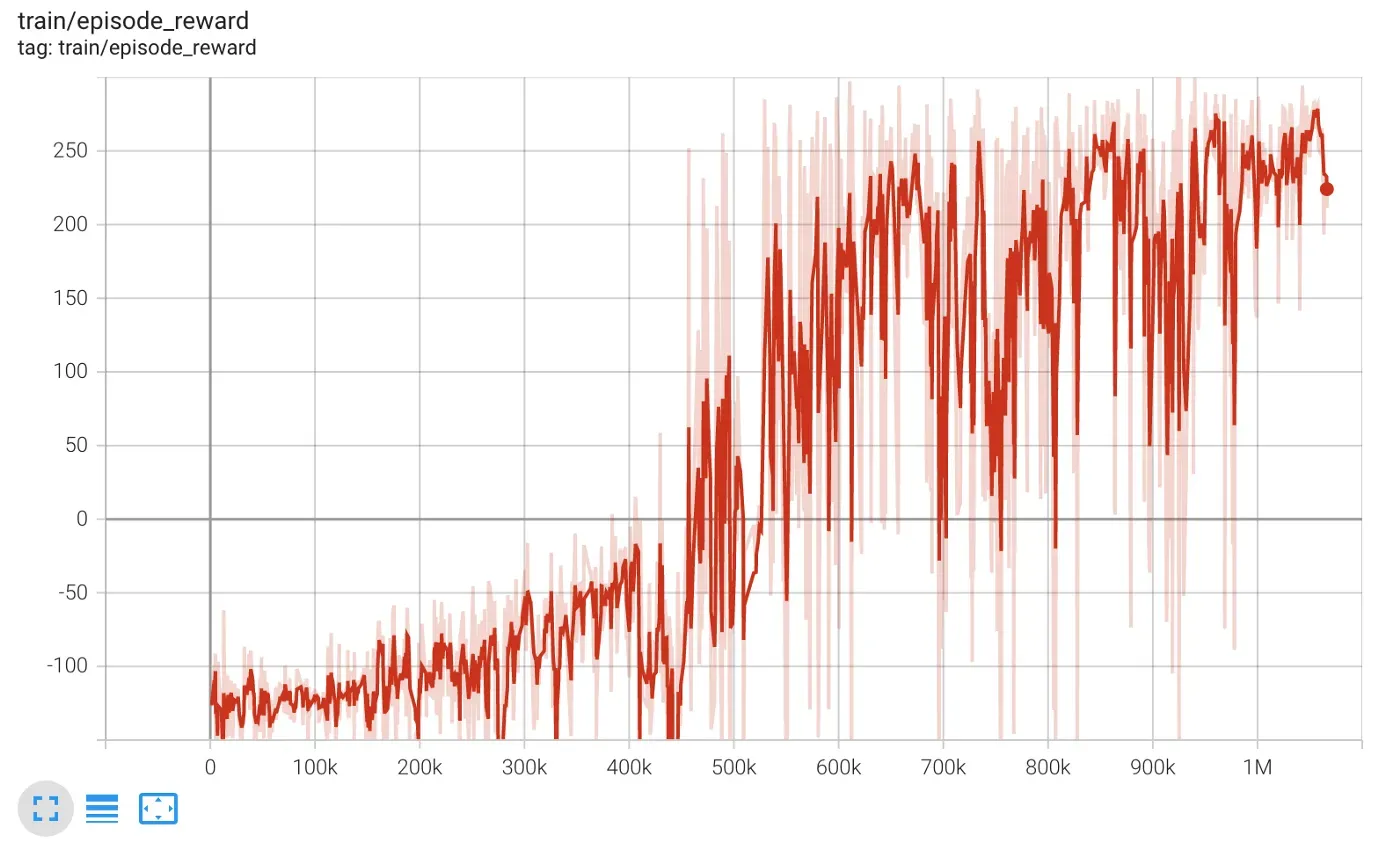
我们清楚地看到代理正在学习,并且在 100 万步后获得了大约 250 的平均总奖励。
由于总奖励不是一个非常直观的衡量标准,我们在 100 个新集的训练结束时直接评估代理,并检查着陆成功率:
# evalute on 100 episodes
rewards, success = agent.evaluate(n_episodes=100)
# print results
import numpy as np
reward_avg = np.array(rewards).mean()
reward_std = np.array(rewards).std()
print(f'Reward average {reward_avg:.2f}, std {reward_std:.2f}')
success_rate = np.array(success).mean()
print(f'Succes rate = {success_rate:.2%}')Reward average 245.86, std 30.18
Succes rate = 99.00%哇! 99% 的准确率相当不错,不是吗?
让我们休息一下,回顾一下,然后展示作业。我们可以?

6. Key takeaways
这些是我今天想让你睡觉的三件事:
- 首先,策略梯度(PG)算法直接参数化最优策略并使用梯度上升算法调整其参数。
- 其次,与深度 Q 学习相比,PG 算法更稳定(即对超参数不太敏感),这很好。
- 最后,PG 算法的数据效率较低,因为它们不能重用旧轨迹来更新当前策略参数(即它们是策略上的方法)。这是我们需要改进的地方
7. Homework
👉🏽 notebooks/04_homework.ipynb[0]
- 你能找到一个更小的网络来解决这个环境吗?我使用了一个有 64 个单位的隐藏层,但我觉得这有点过头了。
- 您可以通过正确调整 batch_size 来加快收敛速度吗?
8. What’s next
在下一课中,我们将介绍一个新的技巧来提高策略梯度方法的数据效率。
Stay tuned.
Love,
Live.
Learn.
Wanna support me?
你喜欢阅读和学习机器学习、人工智能和数据科学吗?
无限制地访问我在 Medium 上发布的所有内容并支持我的写作。
👉🏽 立即使用我的推荐链接成为会员。[0]
👉🏽 订阅数据机器通讯。[0]
👉🏽 在 Medium 上关注我。[0]
有一个美好的一天🤗
Pau
文章出处登录后可见!