异常检测模型赢得信任的 3 大方式
将异常检测模型结果连接回原始信号

在之前的一篇文章中,我介绍了一些通过对原始结果进行后处理从异常检测模型中提取更丰富见解的方法:
阅读本文并将其付诸实践后,您可能会收到有关这些见解的可信度的反馈:
“我不知道我是否可以相信这些见解。为什么这个模型会这样说?给我看看数据!”
在某些情况下,证明将在布丁中:您必须在实时数据上部署模型并调查标记的异常几周。这将使您能够定期进行现实检查,并将模型标记的事件与现场用户的知识进行比较。这种合作将逐渐建立和加强对您模型的信任。
前段时间,我在 LinkedIn 上发布了一个简短的演示文稿(如果你想了解这篇文章的入门,请查看这篇文章),在那里我解释了我在尝试将我的异常检测模型结果与输入时间序列联系起来时遵循的过程。[0]
我鼓励您通过浏览 GitHub 来关注这篇博文,以获取这一系列配套的 Jupyter 笔记本。您可以使用常用的 Jupyter 环境,也可以使用 Amazon SageMaker 启动一个。克隆 repo 并运行前四个笔记本(从数据生成部分到模型评估部分)后,您可以打开最后一个 (synthetic_4_results_deep_dive.ipynb) 并按照本文进行操作。[0][1][2]
Dataset overview
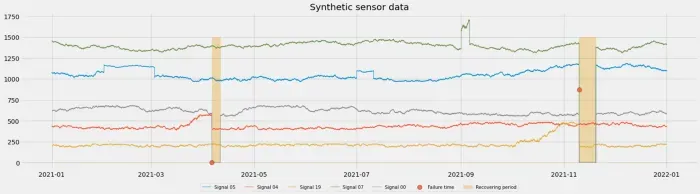
在本文中,我仍然使用我生成的人工数据集,其中包含一些合成异常。如果您想了解有关此数据集的更多信息,请转到我上一篇文章的数据集概述部分。简而言之,这是一个长达 1 年的数据集,包含 20 个时间序列信号和 10 分钟的常规采样率。在可视化这些数据时,您将识别一些故障时间(下面的红点)和一些恢复期(下面的黄色):[0]
在上一篇文章中,我们还使用 Amazon Lookout for Equipment(在 AWS 云中运行的托管服务)训练和异常检测模型。如果您想更深入地研究这项服务(即使您不是开发人员),我将我的时间序列 on AWS 书中的 6 章专门用于这项服务:[0]
回到时间序列
我将假设你已经运行了前 4 个笔记本,并且你有一个训练有素的模型和你的第一个可视化来理解它的结果。为了更好地了解正在发生的事情,您可能需要返回原始时间序列。即使在已经部署了此类模型的生产环境中,执行定期错误分析也可能是您需要与您最喜欢的主题专家一起进行的活动。毕竟,这些 AI 模型并没有取代您的专家和操作员:它们只是通过提供更快的洞察力来增强它们。
Time series visualization
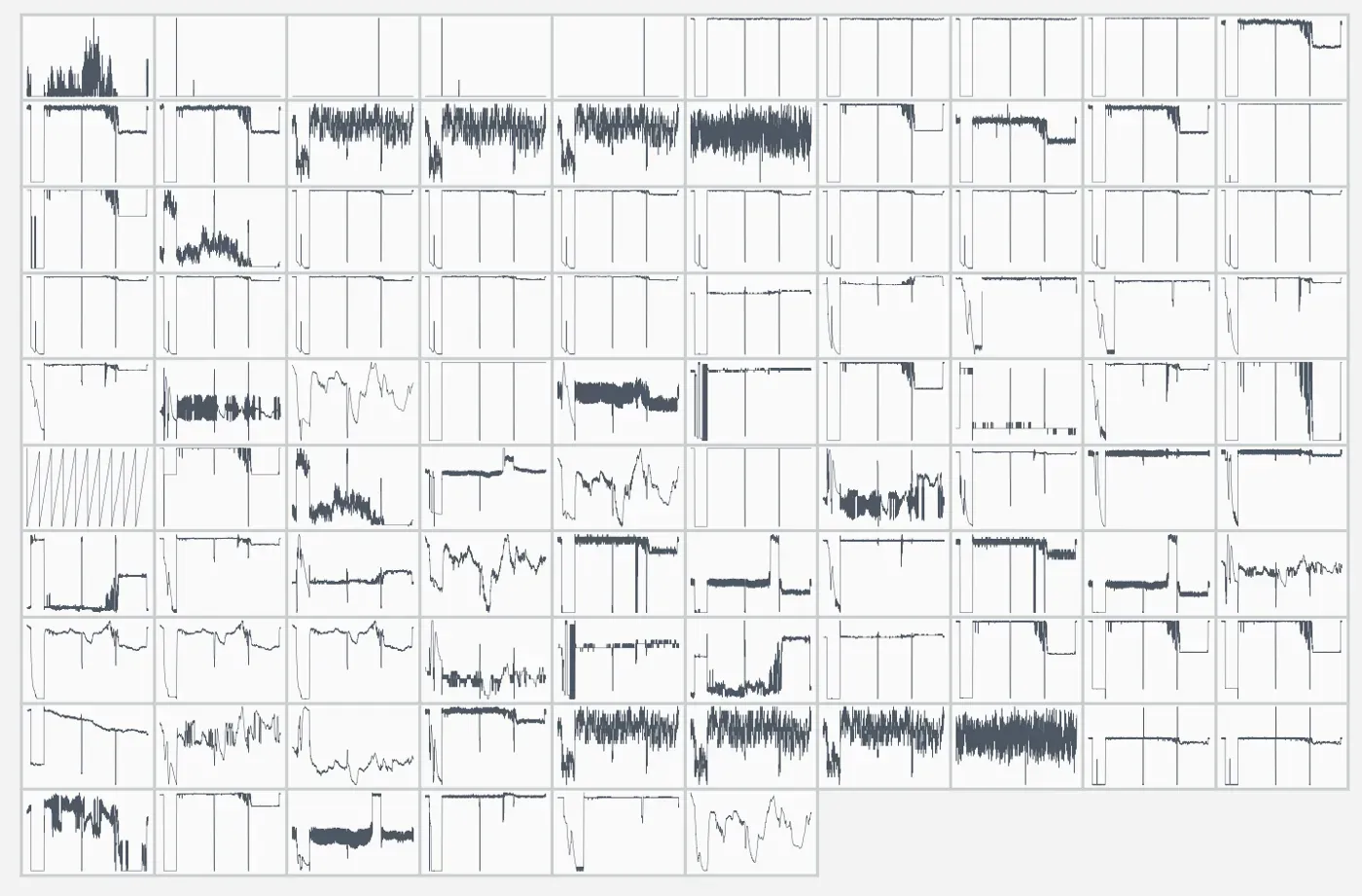
可视化所有时间序列(即使只有 20 个)可能已经具有挑战性。这是我最近遇到的一个数据集示例,您可以在其中看到近 100 个时间序列:
干草堆不是吗?如果我们为我们的 20 传感器更简单的合成数据集组装相同的图,则更容易看到正在发生的事情:
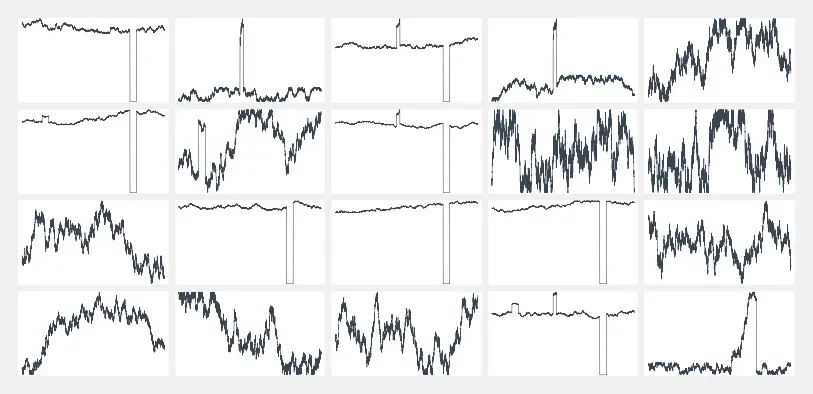
然而,仅仅依靠现实生活中的这种简单性可能还不够……您可以做的第一件事是突出显示模型检测到某些事件的时间范围:
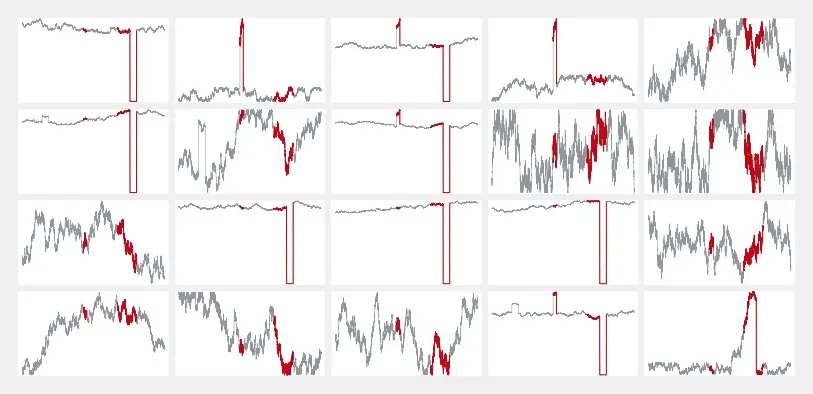
这稍微好一些,特别是如果您的时间序列很少并且异常很容易发现。但是,如果您阅读了我之前的文章,您会记得我们的异常检测模型实际上挑出了几个传感器。让我们绘制第一个,而不是在单个窗格中显示所有这些:
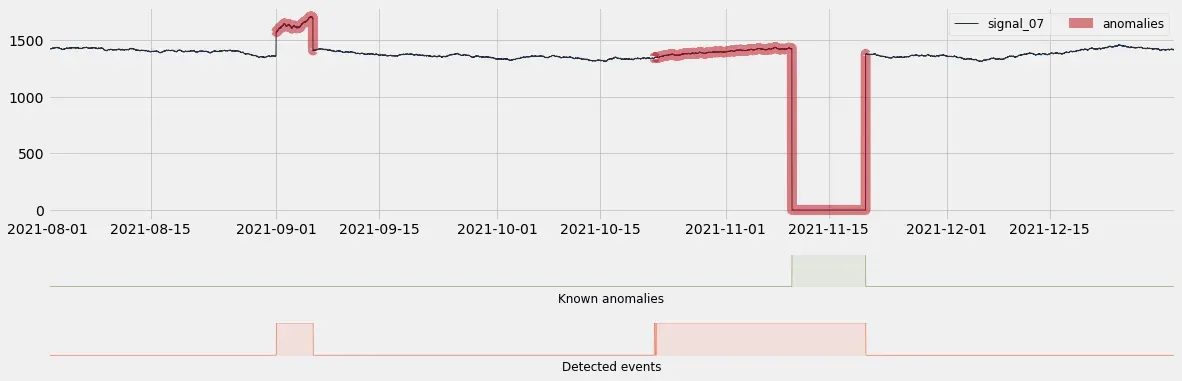
signal_07 输入是我们的异常检测模型挑选出来的时间序列之一,作为这些检测到的事件的关键贡献者。在上图中,我用红色突出显示了异常时间范围:现在更清楚为什么检测到第一个事件。第二个事件更有趣:实际的故障清晰可见,但模型实际上在这发生前将近 2 周检测到了错误。
“当它不那么明显并且我没有看到我的信号有任何问题时会发生什么?”
这是您可能担心的问题之一,尤其是在查看上图中突出显示的失败前的两周时。看起来信号在故障前略有增加,但不是很明显。这是使用直方图可视化时间序列信号所取值的分布的地方可能会派上用场。让我们来看看这个……
可视化时间序列值分布
让我们关注上面检测到的第一个事件。我在笔记本中添加了一些实用函数来绘制两个叠加的直方图:
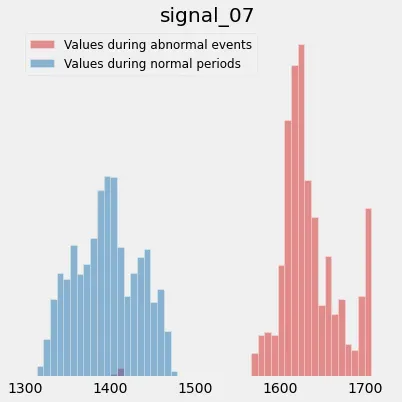
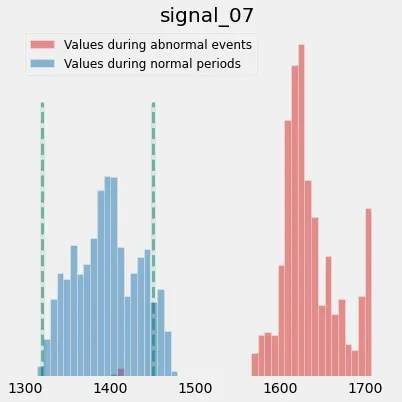
蓝色直方图是 signal_07 在训练范围内取值的分布,而红色直方图突出显示同一信号在异常期间取值。行为的变化更加明显,您甚至可以利用您的领域专业知识来丰富这些直方图。例如,您可能知道在正常操作条件下,signal_07 介于 1320 和 1450 之间。在这种情况下,您可能希望通过在直方图上添加以下信息来帮助您的用户:
让我们看一下第二个异常的直方图:
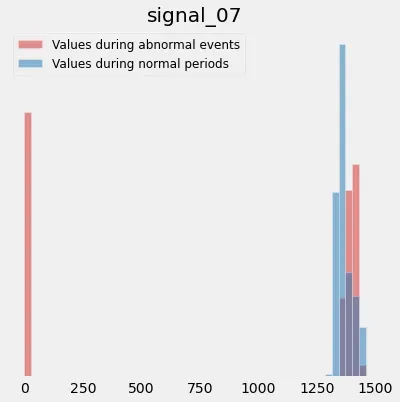
您可以在此处看到发生故障的部分(0 附近的条形图)。让我们放大第二部分,看看失败之前发生了什么:
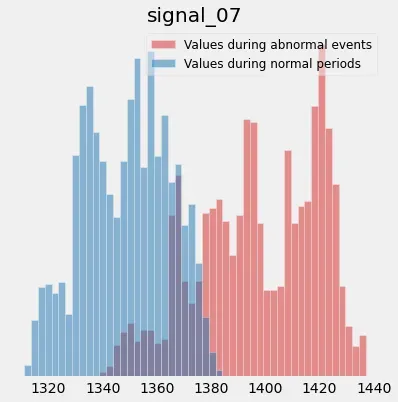
在这里,尽管时间序列上的差异非常小,但分布变化在这里变得更加明显。
Conclusion
在本文中,您学习了如何将异常检测模型结果与原始时间序列联系起来。这对于在您的机器学习系统中建立信任非常有价值,并且是与领域专家协作并进一步改进您的异常管理流程的好工具。基本上,异常检测模型输出可以帮助您集中调查,而适当的可视化或原始数据可以帮助您查明原因!
在以后的文章中,我将深入探讨如何计算直方图之间的距离,并将其用作衡量异常检测模型特征重要性的代理。
我希望您发现这篇文章很有见地:如果您不想错过我即将发布的帖子,请随时在此处给我留言,并随时订阅我的 Medium 电子邮件提要!想支持我和未来的工作吗?使用我的推荐链接加入 Medium:[0]
文章出处登录后可见!