深度学习和机器学习是有很大区别的,博主认为,其最大的区别在于:
- 机器学习每一个算法都有一个完整的理论体系,围绕这个完整的理论体系,衍生出一些能够完整使用的工具或包。只需要安装并使用这些工具,并对模型进行灵活的调参和优化就能达到一个很好的效果。
- 而深度学习对于一些工具(pytorch)的灵活使用或者代码理解要求是更高的,需要从算法架构本身入手来进行网络结构的调整和优化,才能让模型性能有一个比较好的表现。因此如果要对网络结构调整,则需要对工具有一个更深层次的理解,只有掌握tensor背后深层含义,才能灵活的解决各种编程问题,随心所欲的优化模型结构。
Tensor的创建
- 函数创建法:通过torch.tensor()方法创建张量对象。该方法的参数必须是一个序列,这个序列可以是一个列表,可以是一个元组,也可以是一个numpy.array。比如:
import torch t = torch.tensor([1, 2]) # 通过列表创建张量,返回:tensor([1, 2])返回的结果为tensor([1, 2]),tensor是标注符号,代表张量,该张量有两个分量,分别为1和2。下面是通过元组和通过numpy.array来创建张量:
t = torch.tensor((1, 2)) # 通过元组创建张量,返回:tensor([1, 2]) import numpy as np a = np.array((1, 2)) t = torch.tensor(a) # 通过numpy创建张量,返回:tensor([1, 2], dtype=torch.int32)需要注意的是,通过numpy.array创建张量会返回一个dtype,这代表该张量的类型和前者略有差别,特别注明了一下。因此,创建的规律如下:tensor的类型会根据numpy.array的类型发生改变,即:如果使用整数列表或元组创建的张量,会默认为torch.int64类型;如果使用浮点数列表或元组创建的张量,会默认为torch.float32类型;如果使用整数numpy.array创建的张量,会默认为torch.int32类型;如果使用浮点数numpy.array创建的张量,会默认为torch.float64类型。当然,我们也可以通过张量.dtype属性来查看该张量的类型。
t = torch.tensor((0.1, 2)) # 该tensor维度为torch.float32 import numpy as np a = np.array((0.1, 2)) t = torch.tensor(a) # 该tensor维度为torch.float64在pytorch中,由于我们需要在GPU上做大量运算,很多算子是不支持整形操作的,因此,一般情况下我们需要通过一下方法将整形转为浮点型,或者在创建tensor对象之初就创建浮点型。
t.float() t.double()
Tensor的形变
- 首先需要知道tensor的两个属性:
import torch t = torch.tensor([[1, 2],[3, 4]]) # 用list的list创建二维数组 print(t.ndim) # 返回张量维度 2 print(t.shape) # 返回张量形状 torch.Size([2, 2]) -
pytorch中还包括0维张量,只包含一个元素,但又不是单独的一个数(其是pytorch中的一个标量,而不是实际的一个数,该标量可以在GPU上运算),如:
t = torch.tensor(10) - pytorch中最常见的还是三维张量,我们完全可以将其理解为数个二维张量(矩阵)的集合。
import torch t = torch.tensor([[[1, 2, 2],[3, 4, 5]],[[5, 6, 7],[7, 8, 9]]]) # 用list的list创建二维数组 print(t)# tensor([[[1, 2, 2], # [3, 4, 5]], # [[5, 6, 7], # [7, 8, 9]]]) print(t.ndim) # 返回张量维度 3 print(t.shape) # 返回张量形状 torch.Size([2, 2, 3])上述代码中,torch.Size([2, 2, 3])至关重要,它和我们随后的切片,转换维度等操作直接相关。第一个2代表构成三维的张量由两个张量元素构成(第一个矩阵是第一个元素,第二个矩阵是第二个元素),后面的2和3代表每个元素是两行三列的矩阵(或者每个元素由更下一级的两个向量组成,每个向量有3个标量)。
-
张量作为数字的结构化的集合,其结构是可以根据实际需求灵活调整的。flatten方法可以将任意维度的张量转化为1维张量,reshape方法可以将任意维度的张量转化为指定维度的张量:
t.flatten() t.reshape(x,y) # 转化为x行,y列的张量 # 也可以理解转化为包含x个元素,每个元素包含y个标量的张量那么如果是t.reshape(x, y, z)该怎么解读呢?即生成一个包含x个矩阵,每个矩阵拥有y个向量,每个向量拥有z和标量的三维张量。
Tensor的符号索引
张量是一系列数的结构化的集合,因此就可以通过索引的方式将这一系列数按需求索引出来。
- 一维张量的索引是很基础的很重要的,高维张量的索引都是基于一维张量索引展开的。其遵循几个原则:
- 从左到右,从零开始(需要注意的是,组成一维张量的不是一个个的数,而是一个个的零维张量,因此返回的结果会有前缀tensor):
import torch t = torch.arange(1,11) # tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(t[1]) # 返回: tensor(2) -
冒号分隔,可以做切片操作,即对某一个区域范围进行索引(下面索引值1对应第二个元素,索引值8对应第九个元素,并且含左不含右,即不包含索引值为8的元素):
import torch t = torch.arange(1,11) # tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(t[1:8]) # 返回的是一维张量: tensor([2, 3, 4, 5, 6, 7, 8]) - 第二个冒号,表示索引间隔:
import torch t = torch.arange(1,11) # tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(t[1:8:2]) # 返回的是一维张量: tensor([2, 4, 6, 8]) - 冒号如果没有值,表示索引到底:
import torch t = torch.arange(1,11) # tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(t[1::2]) # 返回的是一维张量: tensor([ 2, 4, 6, 8, 10]) print(t[:8:2]) # 返回的是一维张量: tensor([1, 3, 5, 7])
- 从左到右,从零开始(需要注意的是,组成一维张量的不是一个个的数,而是一个个的零维张量,因此返回的结果会有前缀tensor):
- 二维张量的索引:
- 索引第x行,第y列的元素:
import torch t = torch.arange(1,10).reshape(3,3) # tensor([[1, 2, 3], # [4, 5, 6], # [7, 8, 9]]) print(t[0, 1]) # 返回的是0维张量: tensor(2) - pytorch规定:在上面例子的逗号前后,都可以把其看成是单独的一个索引,每个索引都可以是一维张量的索引表示方法,即两个冒号,三个分量的形式。在逗号前,可以对行进行索引,在逗号后,可以对列进行索引,如下:
print(t[0, ::2]) # tensor([1, 3]) print(t[::2, ::2]) # tensor([[1, 3], # [7, 9]]) - pytorch同样支持列表索引方式:逗号前依旧代表围绕第一行进行索引,逗号后代表索引列表,同时索引第一个元素和第三个元素:
print(t[0, [0, 2]]) # tensor([1, 3])
- 索引第x行,第y列的元素:
- 三维张量的索引:
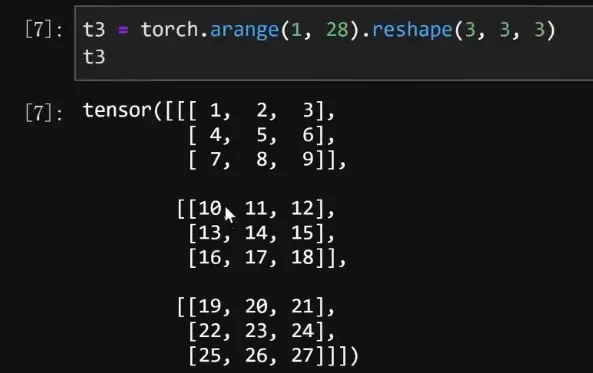
- 定点元素索引:第一个1代表三维张量中的第二个矩阵。(注:这个就和tensor.shape所对应的是一模一样的,shape的第一个元素代表的是长宽高还是batch,这里的第一个1就代表的是什么。)第二个1代表该矩阵中的第二行,第三个1代表第二行中的第二列。
t3[1, 1, 1] # tensor(14)也即:t3.shape的结果是torch.Size([3, 3, 3]),表示该张量由三个矩阵,每个矩阵由三个一维的向量组成,每个一维的向量由三个元素组成。其和上述代码的中括号中的数是一一对应的。
-
切片索引:我们的切片索引式中的每一个单元(如1,::2)都和shape所代表的维度相对应,并且每一个单元都可以按照一维张量的索引表示方法即两个冒号三个值。下式中,1代表索引第二个矩阵,第一个::2代表矩阵的行每隔两行取一次,第二个::2代表矩阵的列每隔两列取一次
t3[1, ::2, ::2] # tensor([[10, 12], # [16, 18]])
- 定点元素索引:第一个1代表三维张量中的第二个矩阵。(注:这个就和tensor.shape所对应的是一模一样的,shape的第一个元素代表的是长宽高还是batch,这里的第一个1就代表的是什么。)第二个1代表该矩阵中的第二行,第三个1代表第二行中的第二列。
- 理解:无论一维还是四维的tensor,索引过程都是围绕tensor的shape的不同方向来进行的,shape当前位置代表什么维度,索引过程中该位置的数就代表在该维度切片或取值。
- Tensor的函数索引:把需要索引的值先通过torch.tensor()创建,再通过index_select函数进行索引。如下所示,0代表按照对shape的第1个方向进行索引,同理如果是2则代表shape的第3个方向进行索引。
import torch t = torch.arange(1,11) indices = torch.tensor([1,2]) print(torch.index_select(t,0,indices)) # tensor([2, 3]) - index_select()由于可以在指定维度上进行索引,因此表意更加清晰,更被大家所使用。
import torch t = torch.arange(12).reshape(4,3) indices = torch.tensor([1,2]) print(torch.index_select(t,0,indices)) # tensor([[3, 4, 5], # [6, 7, 8]])
- Tensor的函数索引:把需要索引的值先通过torch.tensor()创建,再通过index_select函数进行索引。如下所示,0代表按照对shape的第1个方向进行索引,同理如果是2则代表shape的第3个方向进行索引。
Tensor.view()方法
- view象征着视图,代表着相同数据对象的不同形式展现。view有n个逗号,代表创建n+1维的张量。创建出来的张量的shape和view中的值保持一致。
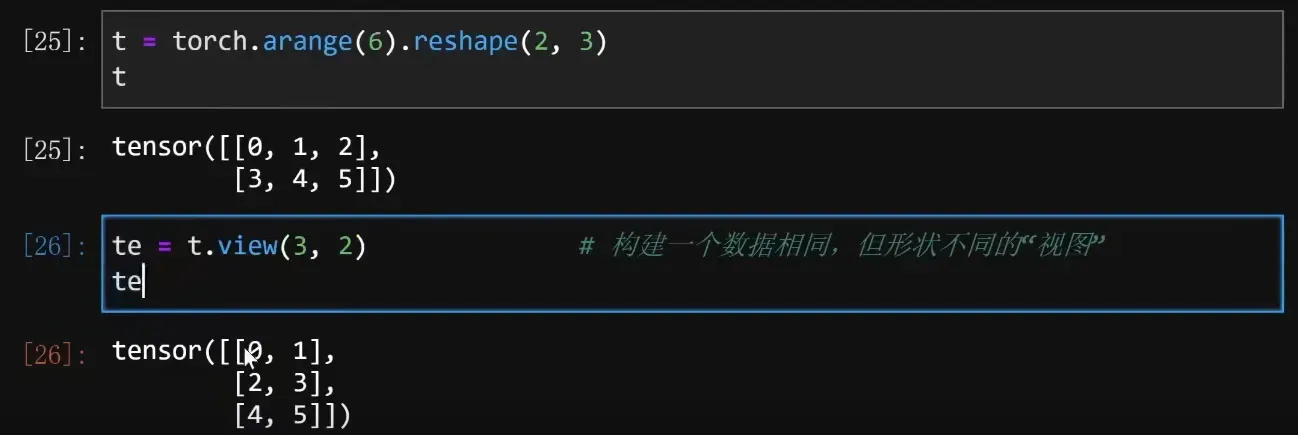
- 需要注意的是:view虽然会创建结构不一样的对象,但二者仍是共享同一块数据存储空间。修改其中一个,另外一个也会改变。
Tensor的分片与合并
- chunk()方法可以实现对张量均匀的切分,其本质上是返回原张量的一些特定视图。下述代码中的4代表均分为4块,dim=0代表沿着shape的第一个维度进行切分。
import torch t = torch.arange(12).reshape(4,3) print(torch.chunk(t, 4, dim=0)) # (tensor([[0, 1, 2]]), tensor([[3, 4, 5]]), tensor([[6, 7, 8]]), tensor([[ 9, 10, 11]])) - 当原张量不能切分时,chunk()方法也不会报错,但返回的结果可能就不尽人意了。
- split()方法则和chunk()方法不同,它可以实现均分,也可以实现自定义切分。代码中的dim=1代表沿着shape的第一个维度进行切分。[1, 3]代表t总共有4行,将4行分为1行和3行。
import torch t = torch.arange(12).reshape(4,3) print(torch.split(t, [1, 3], dim=0)) # (tensor([[0, 1, 2]]), tensor([[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])) - cat()方法可以实现tensor的拼接。第二个参数位为维度,如果不指定,则默认dim取0,即如果是二维张量,默认按行拼接。下面代码中的1代表按照shape的第二个维度进行拼接。
import torch a = torch.zeros(2,3) b = torch.ones(2,3) c = torch.zeros(3,3) print(torch.cat([a, b])) # tensor([[0., 0., 0.],[0., 0., 0.],[1., 1., 1.],[1., 1., 1.]]) print(torch.cat([a, b], 1)) # tensor([[0., 0., 0., 1., 1., 1.],[0., 0., 0., 1., 1., 1.]]) print(torch.cat([a, c], 1)) # 如果维度不一致会报错
文章出处登录后可见!