2020-CVPR-《Mnemonics Training Multi-Class Incremental Learning Without Forgetting》
论文地址:CVPR 2020 Open Access Repository
代码地址:https://github.com/yaoyao-liu/mnemonics
0 摘要
多类增量学习(Multi-Class Incremental Learning,MCIL)旨在通过【逐步更新以前概念训练的模型】来【学习新概念】。然而,要有效地学习新概念,同时不会灾难性遗忘以前的概念,这是一种固有的权衡。为了缓解这个问题,有人建议保留一些先前概念的样本(exemples),但这种方法的有效性在很大程度上取决于这些样本(exemples)的代表性。
本文提出了一种新颖的自动化框架,我们称之为助记符(mnemonics),我们在其中参数化示例(parameterize exemplars),并使其能够以端到端的方式进行优化。我们通过双级优化(bilevel optimizations),即模型级和示例级(model-level and exemplar-level),来训练框架。
我们在3个MCIL的benchmark(CIFAR-100,ImageNet-Subset,ImageNet)上进行了广泛的实验,实验表明使用助记符示例(mnemonics exemplars)可以大大超过最先进的技术。有趣且非常有趣的是,助记符示例往往位于不同类之间的边界上。
1 Introduction
1)人类可以不忘记,但机器却不行。
- 自然学习系统,例如人类,可以自然而然地以一种增量的方式学习新概念,同时不忘记以前的概念。
- In contrast,然而机器却不行,当前的机器学习系统在使用新的传入数据不断更新时,会遭受灾难性的遗忘(因为更新可以覆盖从先前数据里学习到的知识)。
- 对于多类增量学习(MCIL,multi-class incremental learning)尤其如此,无法重放所有先前的输入。
- 因此,灾难性遗忘成为了多类增量学习(MCIL)系统的一个主要的问题。
2)分析了现有工作的研究现状分析,缺点在哪。基于herding来选择示例不是那么高效。
- Motivated by this,出现了许多作品[2, 9, 16, 17, 25, 36]。
- Rebuffi等人[25](2017-CVPR-iCaRL)首先定义了一种用于评估MCIL方法的协议,即,处理图像分类任务,其中不同类别的训练数据在训练阶段不断地顺序到来。由于保留来自先前概念的所有数据及不可取也不可扩展,因此,在此协议中,他们限制了每个类别可以保留的示例的数量,例如,每个类别只能存储20个示例,并传递到后续的训练阶段。这20个示例是让MCIL模型想起来先前知识的关键资源。(对于以前的数据,限制每类保存20个示例。这20个示例是让MCIL模型想起来先前知识的关键资源。)
- 现有的提取示例的方法是基于启发式设计的规则,例如,每个类中平均样本周围的最近邻(命名为herding[35])[2,9,25,36],但是结果并不是特别有效。
- 比如,与使用全部样本(exemples)的上限性能相比,使用herding的iCaRL,在CIFAR-100上预测最后阶段的50个先前类别的准确率下降了约25%(当类别数增加到100个时)。
- 图1给出了羊群示例(herding exemplars)的t-SNE可视化,并显示类之间的分离在以后的训练阶段变得很弱。

3)我们提出了一个示例提取框架。
- In this work, 我们提出(develop)了一个自动化示例提取框架,名为mnemonics,在该框架中,我们使用图像大小的参数来参数化示例,然后在端到端方案中优化它们。
- 使用助记符(mnemonics),每个阶段的MCIL模型不仅可以从新的类别数据中学习最佳示例,还可以调整先前阶段的示例以适应当前数据分布。
- 如图1所示,助记符示例在类之间产生了从开始到最后阶段的一致清晰分离。在检查各个类时(例如,用图1中“蓝色”类的黑色虚线框表示),我们观察到助记符示例(深蓝点)大多位于类数据分布的边界(浅蓝色点),这对于推导高质量的分类器至关重要。
4)此框架是如何运作的。
- 从技术上讲,助记符(mnemonics)有两个模型需要优化,即常规模型(conventional model)和参数化助记符示例(parameterized mnemonics exemplars)。这两者不是独立的,不能共同优化,因为在当前阶段学习的示例将作为后期模型的输入数据。
- 我们使用双层优化程序(BOP)[19,29]来解决这个问题,该程序交替学习两个级别的模型。
- 我们通过整个增量训练阶段迭代此优化。特别是,对于每个阶段,我们执行本地BOP,旨在将新类数据的知识蒸馏到示例中。
- 首先,使用示例作为输入来训练一个临时模型。
- 然后,计算新类数据的验证loss,并反向传播梯度以优化输入层,即助记符示例的参数(the parameters of the mnemonics exemplars)。
- 迭代这两个步骤,使得为以后的训练阶段派生出具有代表性的示例。
- 为了评估所提出的助记符方法,我们在四个不同的baseline架构、3种MCIL的bechmarks(CIFAR-100,ImageNet-Subset和ImageNet)上进行了广泛的实验。
- 我们的研究结果表明,与baselines相比,助记符始终达到最佳性能。例如,在ImageNet的25阶段的设置中,助记符分别比基于羊群的iCaRL [25]和LUCER [9]高出20%和6.5%。
5)贡献点
- 一个新的助记符训练框架:交替进行助记符和模型的学习,在模型层和示例层的双级优化程序下(model-level、exemplar-level)。
- 一个新的本地双级优化程序(meta-level、base-laevel),以一种端到端的方式,为新类训练示例、调整旧类的示例。
- 深入的实验,在特征空间中可视化和解释助记符示例。
2 Related Work
2.1 Incremental Learning
增量学习在机器学习中有着很长的历史。统一的setting是不同类别的数据逐渐出现。最近的工作要么在多任务(multi-task)设置中(类别来自不同的数据集)[4,10,17,26,28],要么在多类(multi-clas)设置中(类别来自相同的数据集)[2,9,25,36]。我们的工作是在后一种称为多类增量学习的benchmarks上进行的。
- 多任务增量(multi-task)
- 多类别增量(multi-class)
一种经典的baseline方法被称为使用transfer set的知识蒸馏,首先由Li等人[17]应用于增量学习[8]。Rebuffi等人[25]将这一想法与表征学习相结合,存储了一些herding示例以重放旧知识。………举了很多例子,我们的方法与这些工作密切相关。我们的工作和其他工作的不同之处是:示例的产生方式。在提出的助记符训练框架中,示例是可优化的,并且可以以端到端的方式进行更新,因此也比以前的更有效。
2.2 Bilevel optimization program(BOP)
双层优化程序(BOP)旨在解决一个框架中的两个层次的问题,其中A级问题是解决B级问题的约束。元学习[5,15,32,33,37,38]是另一个BOP,其中元学习者根据基础学习者的最优性进行优化。最近,MacKay等人[19]将超参数优化公式化为BOP,其中特定时间阶段的最优模型参数取决于超参数,反之亦然。在这项工作中,我们引入了一个全局BOP,该BOP可以优化所有阶段的MCIL模型的参数和助记符示例。在每个阶段中,我们利用本地 BOP 来学习(或调整)特定于新类(或以前的类)的助记符示例。
3 Preliminaries
Multi-Class Incremental Learning(MCIL)多类增量学习
Denotations 符号说明
Distillation and Classification Loss 蒸馏和分类损失
4 Mnemonics Training
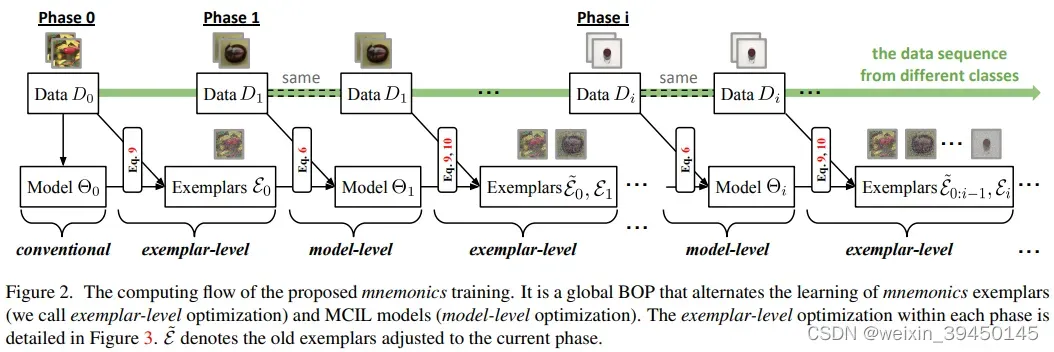
如图2所示,所提出的助记符训练在所有阶段交替学习分类模型和助记符示例,其中助记符示例不仅仅是数据样本,还可以在线优化和调整。我们使用由模型级和示例级问题(第 4.1 节)组成的全局双层优化程序(BOP)来制定这种替代学习,并分别在第 4.2 节和第 4.3 节中提供解决方案。
4.1 Global BOP
在 MCIL 中,分类模型在每个阶段都对新类数据和旧类助记符示例的合并进行增量训练。反过来,基于该模型,在省略新的类数据之前训练新的类助记符示例(即示例的参数)。通过这种方式,模型的最优性派生了对优化示例的约束,反之亦然。我们建议与全局BOP建立这种关系,其中每个阶段都使用最优模型来优化示例,反之亦然。
BOP双级优化:1)model-level;2)exemplar-level。
- 1)每个阶段的model:新数据+旧类的助记符示例,增量训练得到。
- 2)反过来,基于该模型,在省略新类数据之前,训练新类助记符示例(即,示例的参数)
4.2 Model-level problem
模型层(如图2所示):
- 1)在第i个阶段:
- 示例
作为部分输入
- 模型
用作模型初始化
- 示例
- 2)得到模型
- 3)将模型
用于接下来的exemplar示例层
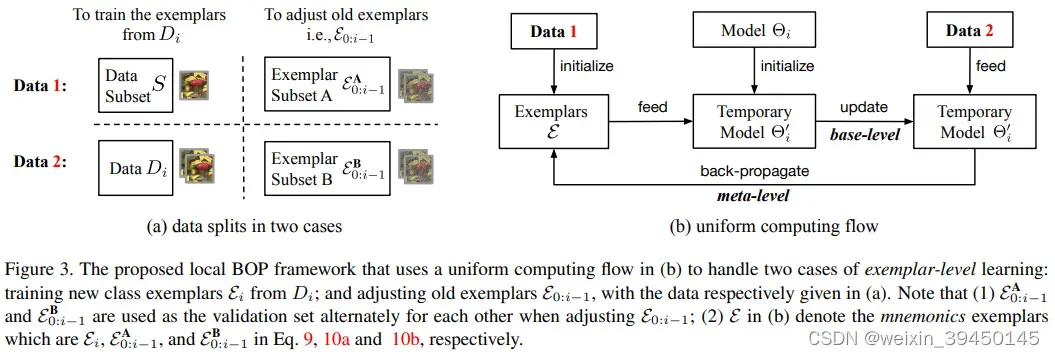
4.3 Exemplar-level problem
示例层(如图3所示):
的训练:
- 1)
上随机采样进行初始化
- 2)用
,在
- 3)计算
- 1)
- 1)以前类别的助记符示例在这个类出现时被训练
- 把
5 总结
这篇论文和以前论文方法的不同之处在于:挑选示例exemplars的方法不同,通过参数化示例来对exemplars进行更新。整篇论文的思路,模型级的优化和示例级的优化,在论文里的那两张图片(图2和图3)解释地很清楚。
文章出处登录后可见!