目录
😆😆😆感谢大家的阅读😆😆😆
集成学习概念
💎集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(基学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
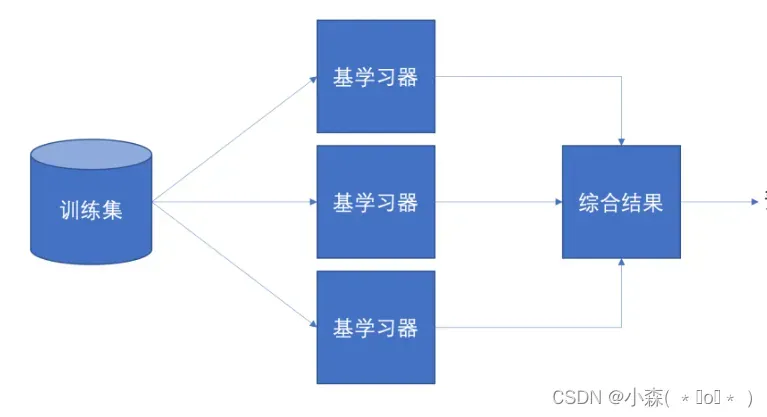
- 集成学习通过构建多个模型来解决单一预测问题
- 生成多基学习器,各自独立地学习和预测
- 通过平权或者加权的方式,整合多个基学习器的预测输出
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
集成算法可以分为:Bagging,Boosting和Stacking等类型。
基学习器是可使用不同的学习模型,比如:支持向量机、神经网络、决策树整合到一起作为一个集成学习系统也可使用相同的学习模型,一般情况下,更使用相同的学习模型 。
集成学习器性能评估
如果把好坏不等的东西掺到一起,通常结果会比最坏的好一些,比最好的坏一些。集成学习把多个学习器结合起来,要获得好的集成,个体学习器应有一定的准确性 ,学习器不能太坏,并且学习器之间具有差异 。
常用的度量标准包括准确率、精确率、召回率、F1分数、ROC曲线下的面积(AUC)等。并且可以使用交叉验证等技术来选择最优的模型,根据性能评估的结果,可以调整集成学习器的参数,如基学习器的数量、投票策略等,以优化其性能。这是一个迭代的过程,可能需要多次重复以上步骤,直到达到满意的性能。
根据集成分类策略
- Bagging(随机森林)
- Boosting (Adaboost、XGBoost)
Baggging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
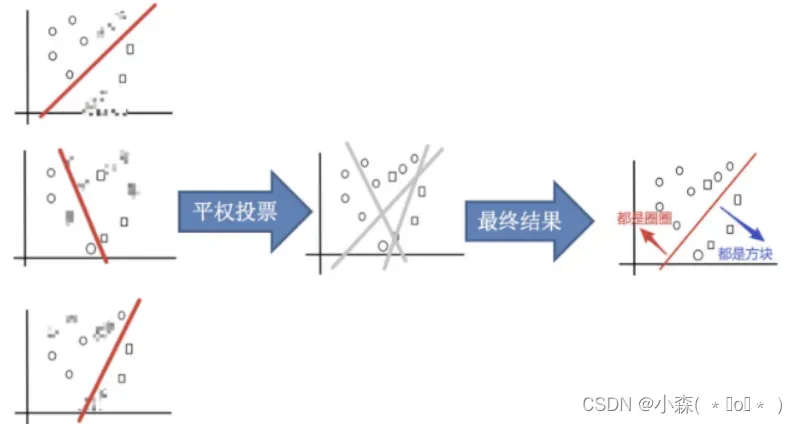
Bagging算法首先采用M轮自助采样法,获得M个包含N个训练样本的采样集。然后,基于这些采样集训练出一个基学习器。最后将这M个基学习器进行组合。
-
分类任务采用简单投票法:即每个基学习器一票
-
回归问题使用简单平均法:即每个基学习器的预测值取平均值
随机森林
💎随机森林是基于 Bagging 思想实现的一种集成学习算法,它采用决策树模型作为每一个基学习器。
- 有放回的产生训练样本
- 随机挑选 n 个特征(n 小于总特征数量)
- 预测:平权投票,多数表决输出预测结果
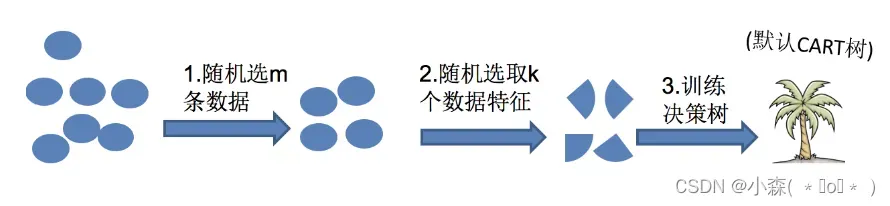
单个决策树在产生样本集和确定特征后,使用CART算法计算,不剪枝。得到所需数目的决策树后,随机森林方法对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
随机森林的随机性体现在每棵树的训练样本是随机的,树中每个节点的分裂属性也是随机选择的。即使每棵决策树没有进行剪枝,随机森林也不会产生过拟合的现象。
sklearn.ensemble.RandomForestClassifier()
- n_estimators:决策树数量
- Criterion:entropy、gini
- max_depth:指定树的最大深度
- max_features=”auto”, 决策树构建时使用的最大特征数量
- bootstrap:是否采用有放回抽样,如果为 False 将会使用全部训练样本
- min_impurity_split: 节点划分最小不纯度,如果某节点的不纯度小于这个阈值,则该节点不再生成子节点
Sklearn实战💎
import pandas as pd
titanic=pd.read_csv("泰坦尼克号.csv")
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=26)
#使用单一的决策树
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)
#随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)
#性能
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))超参数选择
rf = RandomForestClassifier()
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# GridSearchCV网格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))Boosting
Boosting的核心思想在于逐步改进预测结果,每个新的基模型都在前一个模型的基础上进一步提升性能。这种方法是递进的,意味着后续的学习器依赖于前面学习器的表现。Boosting方法通常会对所有基模型的预测结果进行线性组合,以产生最终的预测结果。这种组合方式有助于减少整体的偏差,从而提高模型的预测性能。
💎Bagging 和 Boosting
- 样本选择:Bagging 使用均匀取样,每个样本的权重相等,而 Boosting 根据错误率不断调整样本的权值,错误率越大的样本权重越大。
- 预测函数:在 Bagging 中,所有预测函数的权重相等,而 Boosting 中每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
- 计算效率:Bagging 算法更加简单高效,因为每次迭代可以独立进行,而 Boosting 需要根据前一轮的结果来调整样本的权重和训练模型。
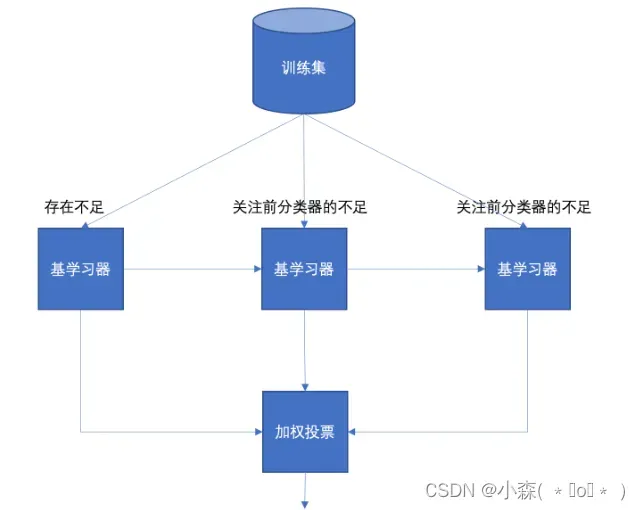
- 先从初始训练集训练出一个基学习器
- 在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续得到最大的关注。
- 然后基于调整后的样本分布来训练下一个基学习器;
- 如此重复进行,直至基学习器数目达到实现指定的值T为止。
- 再将这T个基学习器进行加权结合得到集成学习器。
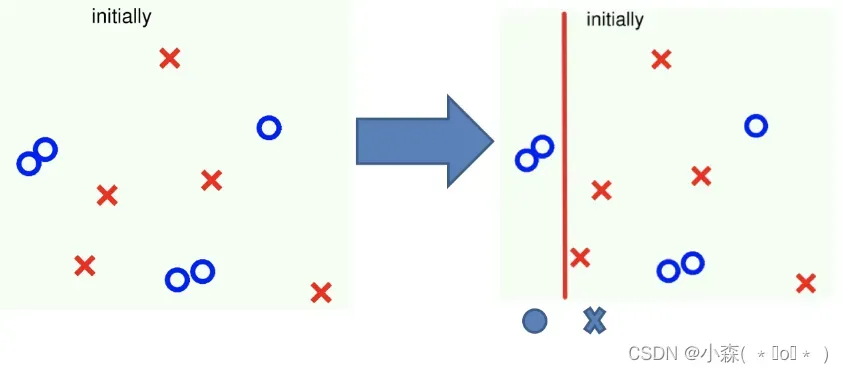
然后进行第二轮训练时预测错误的样品放大,正确的缩小。
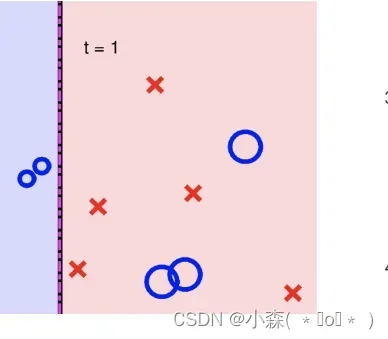
直到循环几轮之后:
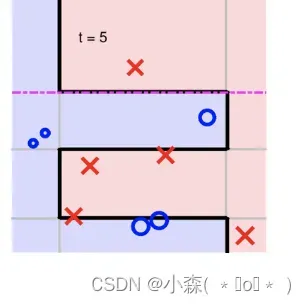
AdaBoost
AdaBoost是Boosting算法的一种实现,是一种用于分类问题的算法,它用弱分类器的线性组合来构造强分类器。在训练开始时,每个样本都被赋予相同的权值,例如 ( w_1 = \frac{1}{N} ),其中 ( N ) 是训练样本的数量。
- 接着,算法会训练一系列的弱分类器 ( h_i )。对于每一轮训练,如果某个样本被正确分类,则它的权值会降低;反之,如果被错误分类,则权值会增加。这样做的目的是让后续的弱分类器更加关注那些难以正确分类的样本。
- 在每一轮迭代中,根据上一轮的分类结果调整样本权值,并基于新的权值分布训练下一个弱分类器。
- 最终,所有的弱分类器会被组合起来形成一个强分类器。每个弱分类器的贡献由其在训练过程中的表现决定,分类效果好的弱分类器会有更大的权重。
AdaBoost自提出以来,因其出色的性能在多个领域得到了广泛应用,如文本分类、图像识别和生物信息学等。它的优势在于能够自适应地调整样本权重,并通过弱分类器的线性组合达到强化模型性能的目的。
import pandas as pd
df_wine = pd.read_csv('wine.data')
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
df_wine = df_wine[df_wine['Class label'] != 1]
# 获取特征值和目标值
X = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label'].values
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# (2,3)=>(0,1)
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy',max_depth=1,random_state=0)
ada=AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=0)
from sklearn.metrics import accuracy_score
# 决策树和AdaBoost分类器评估
# 决策树性能评估
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# Decision tree train/test accuracies 0.845/0.854
# AdaBoost性能评估
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# Adaboost train/test accuracies 1/0.875 版权声明:本文为博主作者:小森( ﹡ˆoˆ﹡ )原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_64685283/article/details/136828662