目录
一、Nacos 安装和配置
在 浏览器地址栏中输入 nacos.io 就可以访问到 nacos 官网,然后点击前往 github ,如下图:
下滑就可以看到 nacos 的一个发行历代版本,如下:
 这里大家可以根据需求,自由下载~
这里大家可以根据需求,自由下载~
我使用的是 1.4.1 版本的 nacos,下载好 zip 后,解压到一个非中文目录路径下即可,成功后文件内容如下:

conf 目录下 有一个文件名为 application.properties ,这个文件使用来对 nacos 进行配置的,有什么用呢? nacos 默认配置端口为 8848,如果你电脑上的 8848 端口被占用,那么就可以对 nacos 端口信息进行配置~
bin 目录下就是我们需要的 nacos 的可执行文件啦,我们要使用的就是 startup.cmd ,如下:

最简单的启动方式就是双击这个文件即可,但是这样打开会缺少一些详细的信息~
因此,我们还有一种打开办法就是通过如下命令启动 nacos 服务(该文件目录下打开终端):
./startup.cmd -m standalone也可以通过如下命令,在云服务器通过 docker 启动:
docker run --env MODE=standalone --name nacos --restart=always -d -p 8848:8848 nacos/nacos-server:1.2.0
- MODE=standalone 单机版
- –restart=always 开机启动
- -p 8848:8848 映射端口
- -d 创建一个守护式容器在后台运行
Ps:需要先通过 docker pull nacos/nacos-server:1.2.0 拉取镜像.
以下为执行成功的效果:
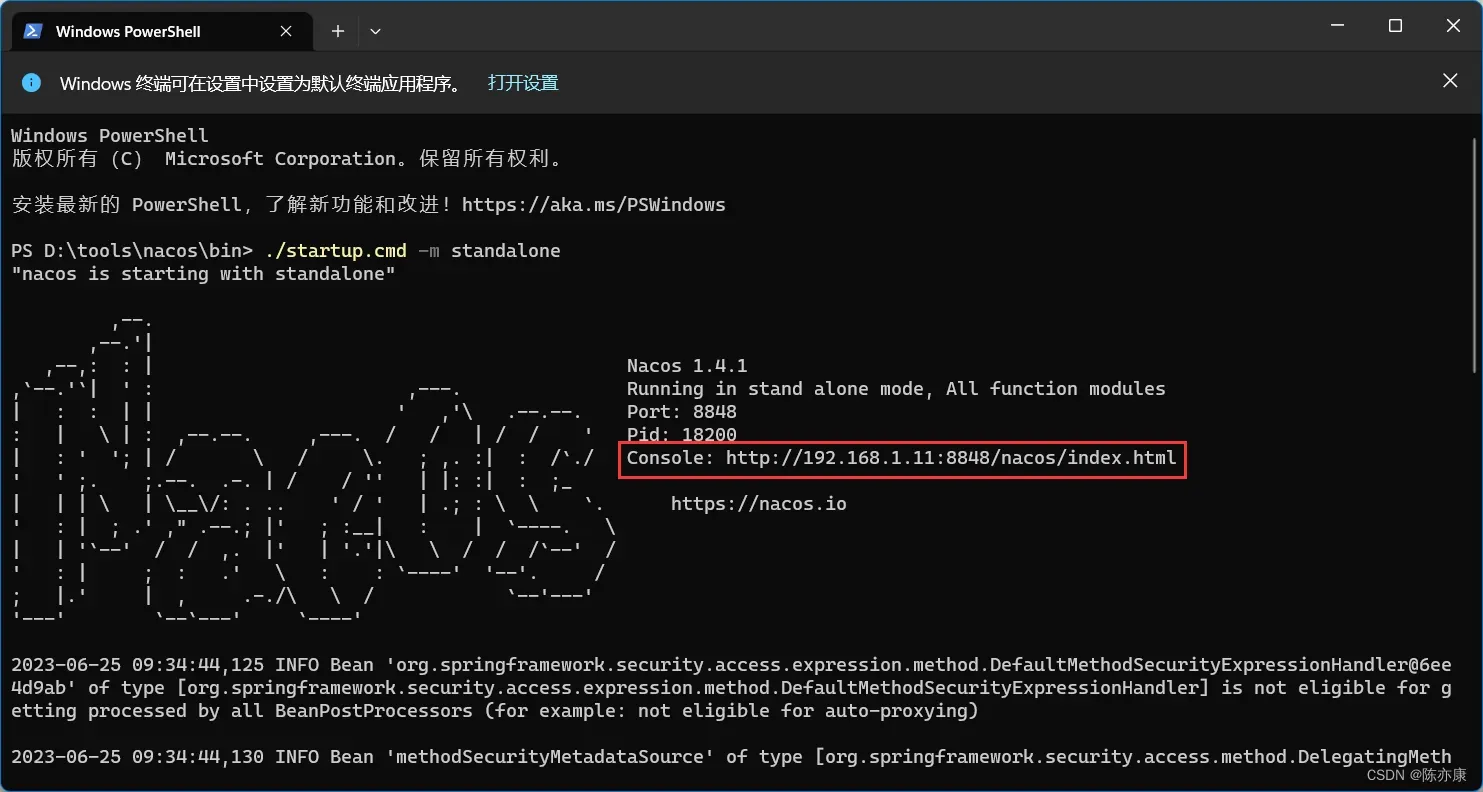
上图中圈起来的就是 Nacos 服务的地址,可以通过 Ctrl + 点击 的方式打开(或者直接在浏览器中输入 localhost:8848/nacos 也可以访问),就可以看到如下界面:
默认账号和密码都是输入 nacos 即可,后面讲到 Nacos 服务注册时会用到~
二、Nacos 服务注册发现
2.1、将服务注册到 nacos 中
ps:案例是上一章所讲的 “根据订单id查询订单的同时,把订单所属的用户信息一起返回” 。
a)在你项目的父工程中加入 spring-cloud-alibaba 依赖,如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Ps:注意:版本 2.1.x.RELEASE 对应的是 Spring Boot 2.1.x 版本。版本 2.0.x.RELEASE 对应的是 Spring Boot 2.0.x 版本,版本 1.5.x.RELEASE 对应的是 Spring Boot 1.5.x 版本
b)如果项目项目中之前使用过 eureka 服务注册,一定记得要将其依赖注释掉
c)对你项目需要进行注册的微服务添加 nacos 依赖(对于本章所讲案例,需要在 user-service 和 order-service 的 pom 文件添加依赖)如下:
<!-- nacos客户端依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
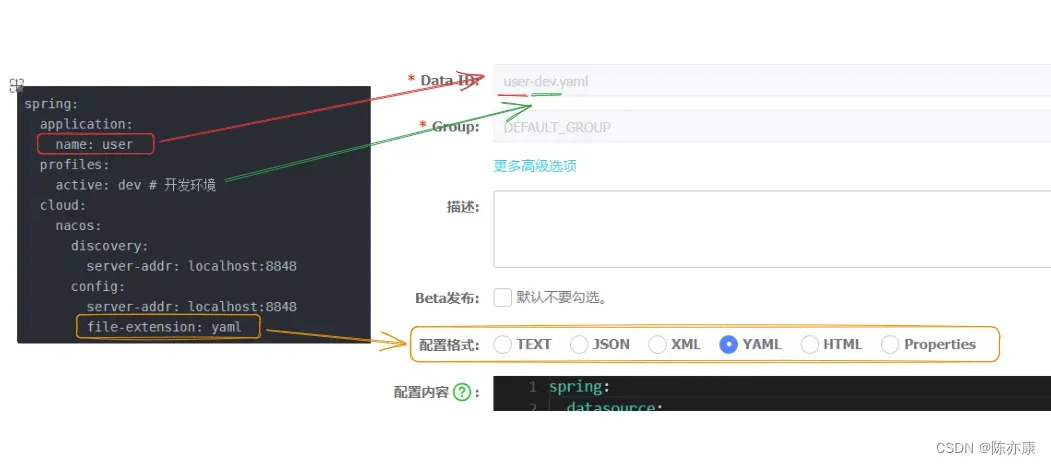
</dependency>d)修改 user-service,order-service 中的 application.yml 文件,注释 eureka 地址(如果以前使用过),添加 nacos 地址 和 服务名称:
spring:
application:
name: user
profiles:
active: dev # 开发环境
cloud:
nacos:
discovery:
server-addr: localhost:8848
config:
server-addr: localhost:8848
file-extension: yaml
2.2、执行效果
a)接下来启动如下项目:

b)打开nacos 注册中心页面,输入账号和密码(默认是 nacos),接着进入主页,打开服务列表就可以观察到刚刚的服务,如下:
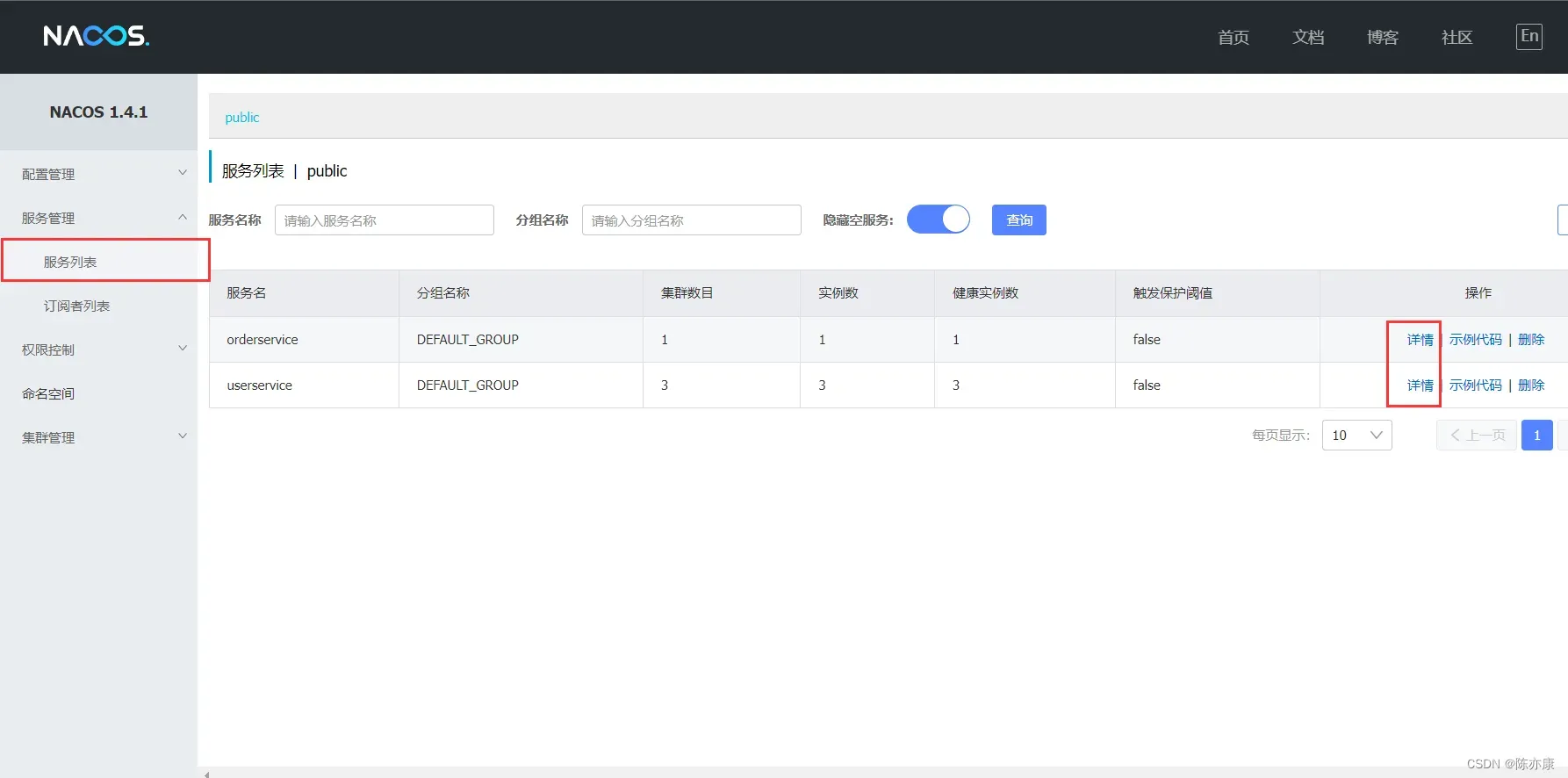
同时你也可以观察他们的详细信息,如下:

2.3、Nacos 服务注册发现原理过程(考点:与 Eureka 的区别)
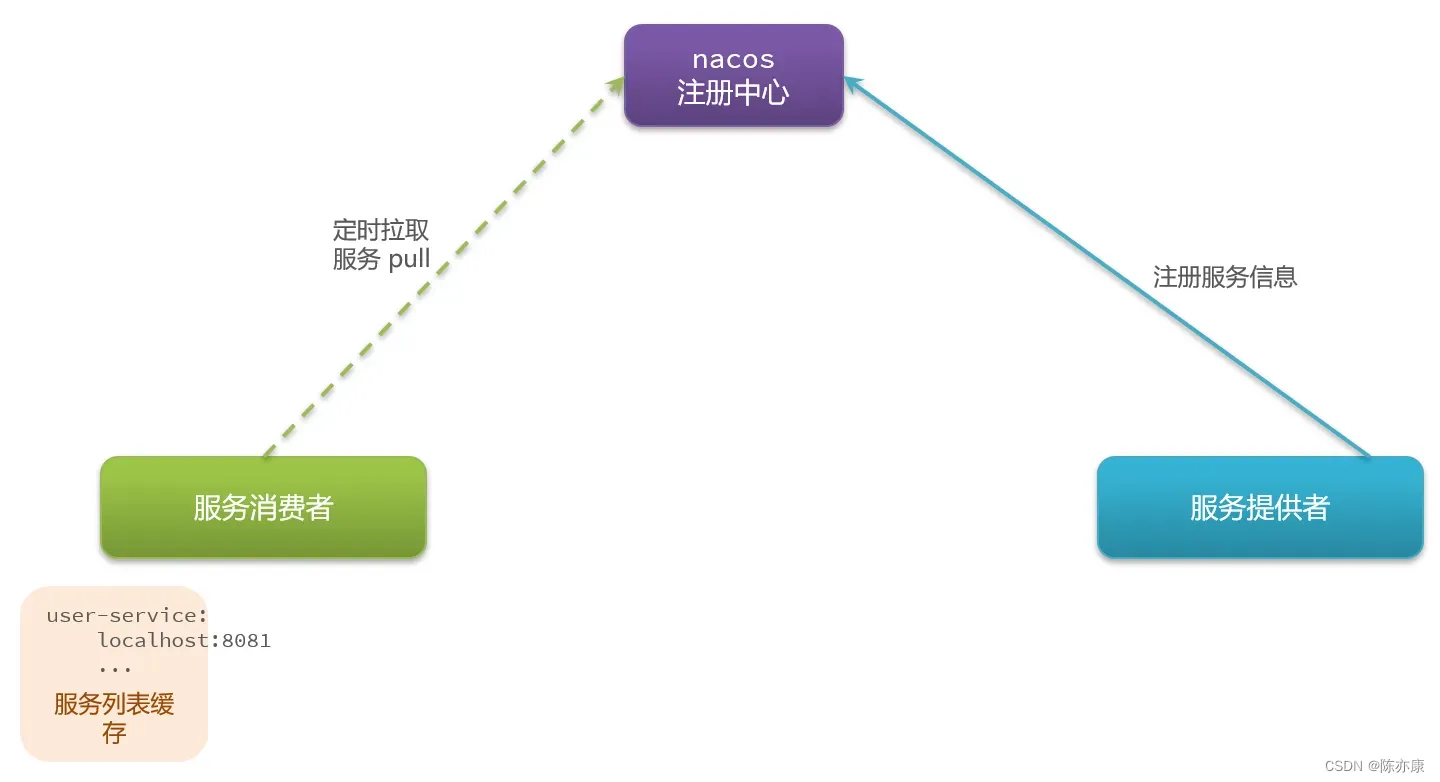
a)首先,我们的服务启动时。都会把自己的信息提交给注册中心(自己的 Ip 、端口号、集群信息….),然后注册中心就会把信息保存下来.
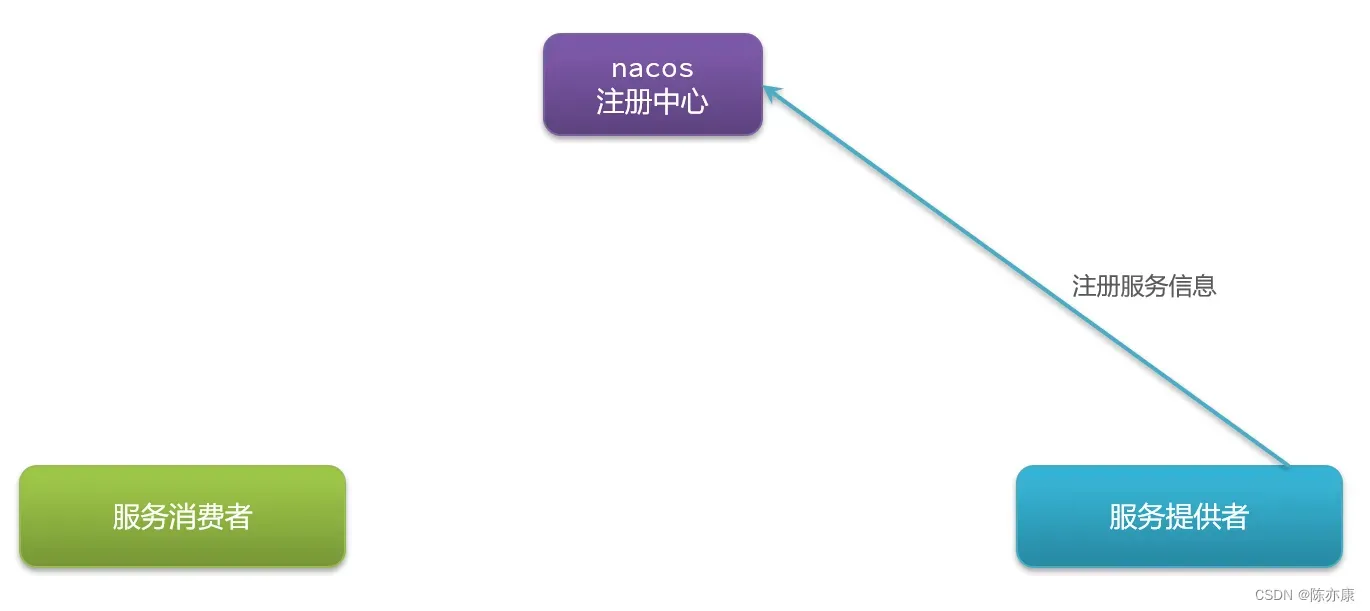
b)那么当服务消费者要去消费时,就可以从注册中心拉取服务信息. 这个过程也被称为“服务发现”. 但是他这个拉去动作不是每次都要做的(压力太大),而是将拉取到的服务信息缓存到一个列表中,这样接下来的一段时间里,就不用去拉去了,而是直接从缓存列表中拿.
当然这个缓存一直不更新也不行,因此会每隔 30 秒取重新拉取一次(多长时间不用记,都是可以配置的),进行更新.
c)消费者拿到服务列表后,就可以通过 负载均衡(LoadBalancer)从列表中挑选一个发起远程调用就可以了.
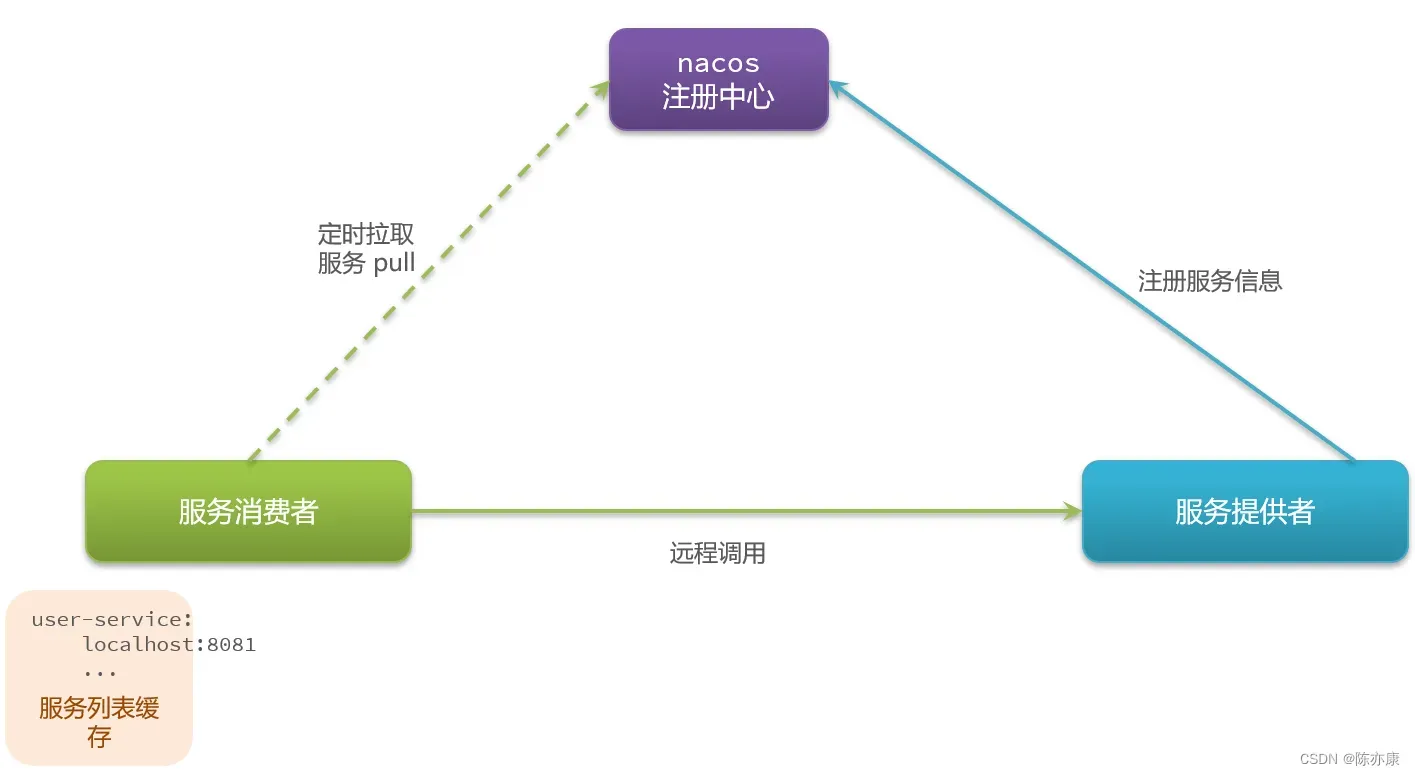
d)截至目前为止,Nacos 和 Eureka 还没什么差别,那差别在哪呢?差别就在于服务提供者的健康检测机制.
e)在 nacos 中,将服务分成了临时实例和非临时实例:
- 临时实例:当临时实例进行心跳检测的时候,如果心跳不跳了,nacos 就会把它从服务中直接剔除. (这里的心跳检测机制和 Eureka 是一样的,但非临时实例就不一样了)
- 非临时实例:nacos 就不会要求你给我发心跳了,而是通过 nacos 主动发请求询问:“你还活着吗?”,即使真的挂了,nacos 也仅仅只是把它标记为 不健康,不会剔除,而是等待它恢复健康.
这差别就像是亲生儿子和非亲生儿子,亲生儿子我还会去主动关怀一下,诶,你还活着么?而非临时实例,就是你不心跳了,就把你扔了~
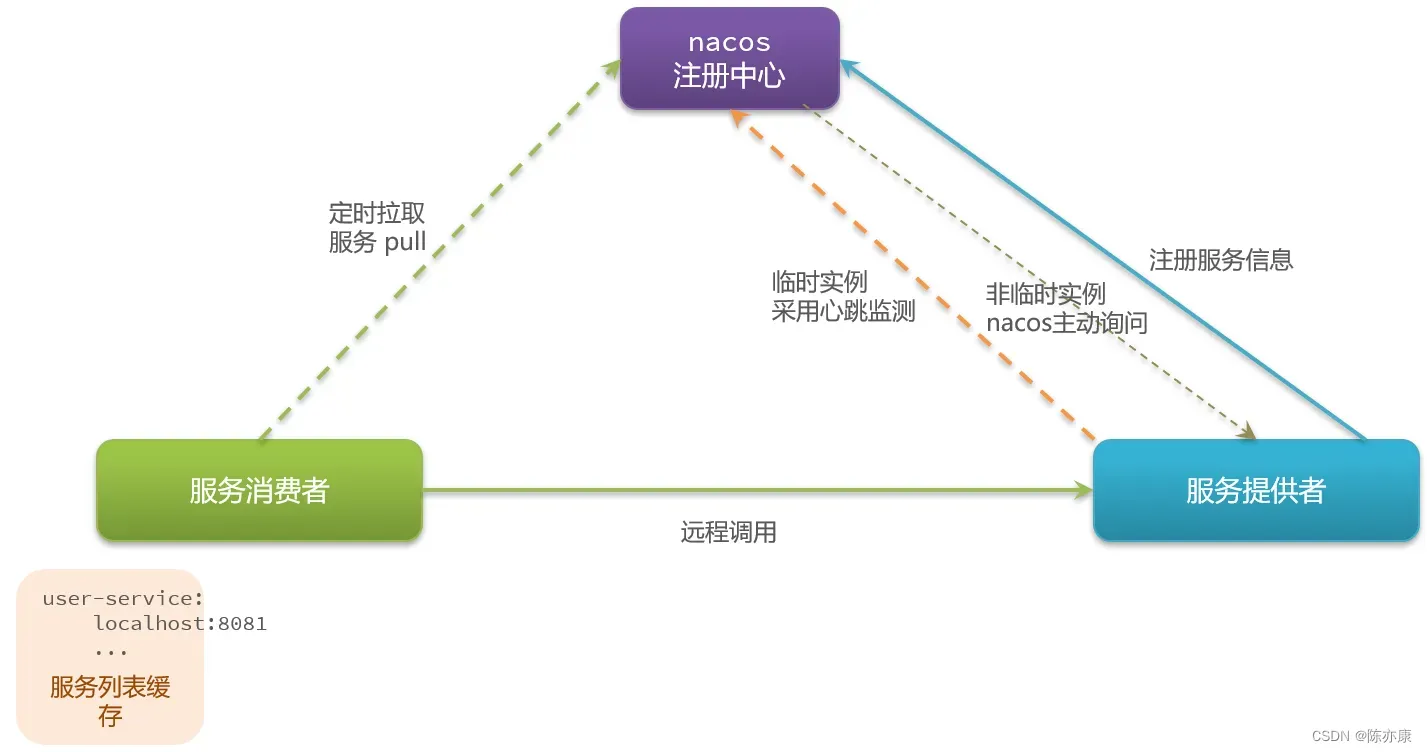
f)还有一个差别在于服务消费者,Eureka 采用的是定时拉去(每 30 秒一次),那如果在 30 秒内服务提供者挂了,消费肯定是不知道的,因此 Eureka 这里更新的时效性也比较差.
而 nacos 这里的消费者不光进行服务的定时拉取,nacos 还会主动进行消息的推送,一旦发现有服务挂了,就立刻推送一条消息给服务消费者,告诉你服务要更新了.

三、Nacos 的服务分级模型及配置
3.1、分级模型

为什么 nacos 要引入这样的服务分级模型呢?
实际上也就是说,为什么要加上地域划分这个概念~
- 容灾能力:假设如果把所有的实例都部署在一个集群,这就像把鸡蛋都放在一个篮子里,哪天你一不小心把篮子打翻了,那所有的蛋不是都破了?那都部署在一个集群中,万一这一个集群出了问题,整个服务就完蛋了,因此为了解决整个问题,我们需要将一个服务的多个实例部署到多个集群(机房),这样就大大增加了他的容灾能力。
- 调用效率:nacos 引入服务分级还有重要的一点就是,防止跨集群调用(提高调用效率),服务调用尽可能选择本地集群的服务,跨集群调用延迟较高,当本地集群不可访问时,再去访问其它集群。
3.2、配置集群
a)修改 user-service 的 application.yml 文件,如下配置:
spring:
cloud:
nacos:
server-addr: localhost:8848 # nacos 服务端地址
discovery:
cluster-name: BJ # 配置集群名称,也就是机房位置,例如:BJ,北京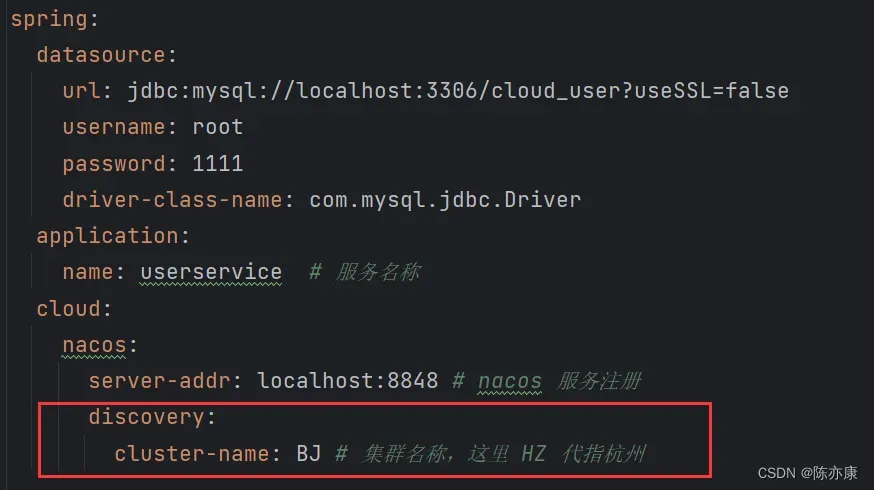
b)接着打开以下两个服务:
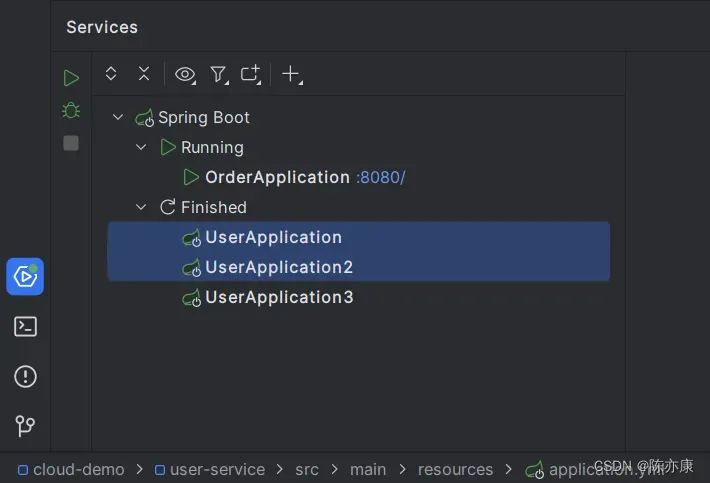
c)继续在配置文件中修改 cluster-name: SH ,这里的 SH 表示代指上海,接着再启动 UserApplication3 服务,如下:
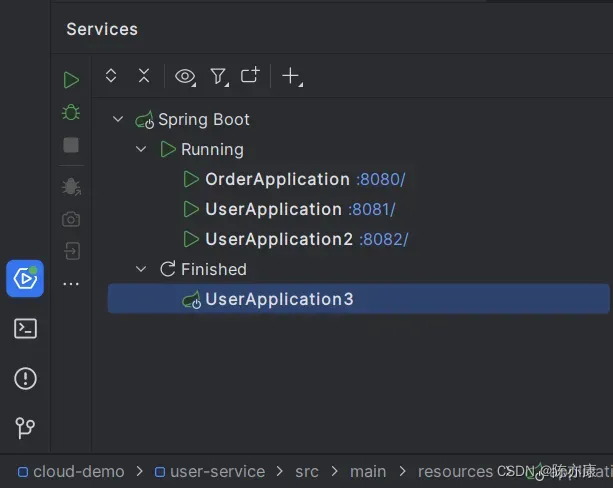
d)登录 nacos,查看服务详情信息,可以观察到如下结果:
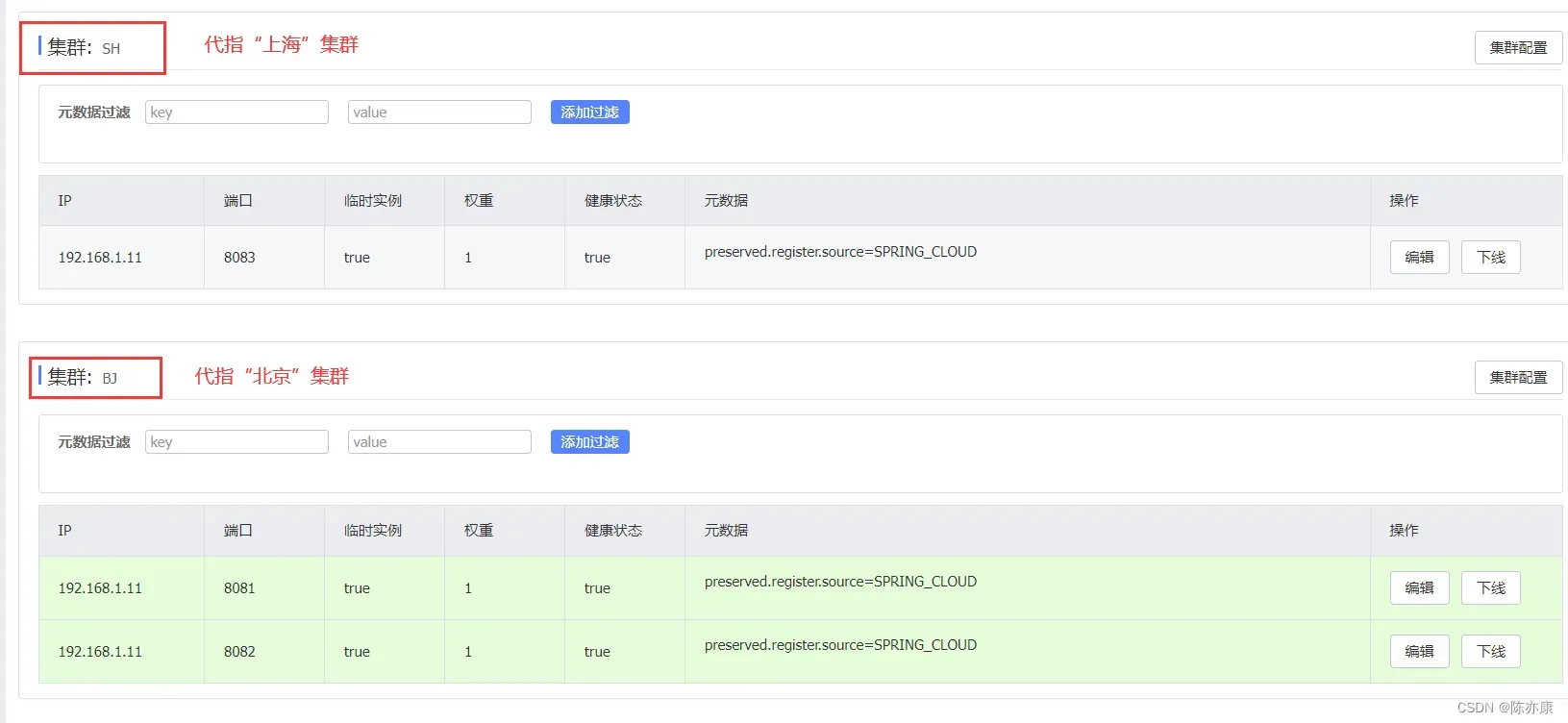
这样就完成了集群的配置~
3.3、配置 Nacos 负载均衡策略
前面我们提到 Nacos 的服务分级模型,他会优先访问本地集群,实际上这也是需要进行配置的~
Ps:配置前我们应当注意,如果之前有重写 IRule 修改负载均衡算法,一定要注释掉!
a)首先,我们需要给 order-service 的 application.yml 添加配置集群信息,如下:
spring:
cloud:
nacos:
server-addr: localhost:8848 # nacos 服务端地址
discovery:
cluster-name: BJ # 配置集群名称,也就是机房位置b)接着,我们只需要在 order-service 的 application.yml 文件中添加以下信息即可(这个就是在配置负载均衡的原则为“优先访问本地集群”):
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 这样就可以实现优先访问本地集群啦~
Ps:在本地集群中选择实例的时候,还是以随机方式进行选择的~
值得注意的一点是,当本地集群挂掉,那么就不得不跨集群访问了,并且在项目中会打印以下日志信息:

通过这个信息,运维人员就可以快速找到挂掉的集群,进行修复~
3.4、Nacos 服务实例的权重设置
Nacos 的权重使用来干什么的呢?往下看~
使用场景(作用):
- 在实际的部署环境中,服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求,那么这时候就可以通过 Nacos 配置权重来控制频率,权重越高的,访问频率越大。
- 当我们某一个服务需要进行优化的的时候,需要先下线该服务,那么可以先将该服务的权重改到很低,最后改到零,这样用它的用户越来越少,最后就感知不到他的存在,同样,当服务优化完后,进行上线的时候,可以先将其权重修改为一个很小的数字,这样使用的用户也很少,可以让这些用户来进行一个服务的测试,如果用户反馈的效果不错,再将权重改为合适的数字即可,这样就做到了平滑上下线服务的效果。
Nacos 权重的特点如下:
- Nacos控制台可以设置实例的权重值,0~1之间
- 同集群内的多个实例,权重越高被访问的频率越高
- 权重设置为0则完全不会被访问
Nacos 权重的配置步骤如下:
a)在 Nacos 的服务列表的服务详情信息中可以观察到权重信息,以及编辑按钮,如下:
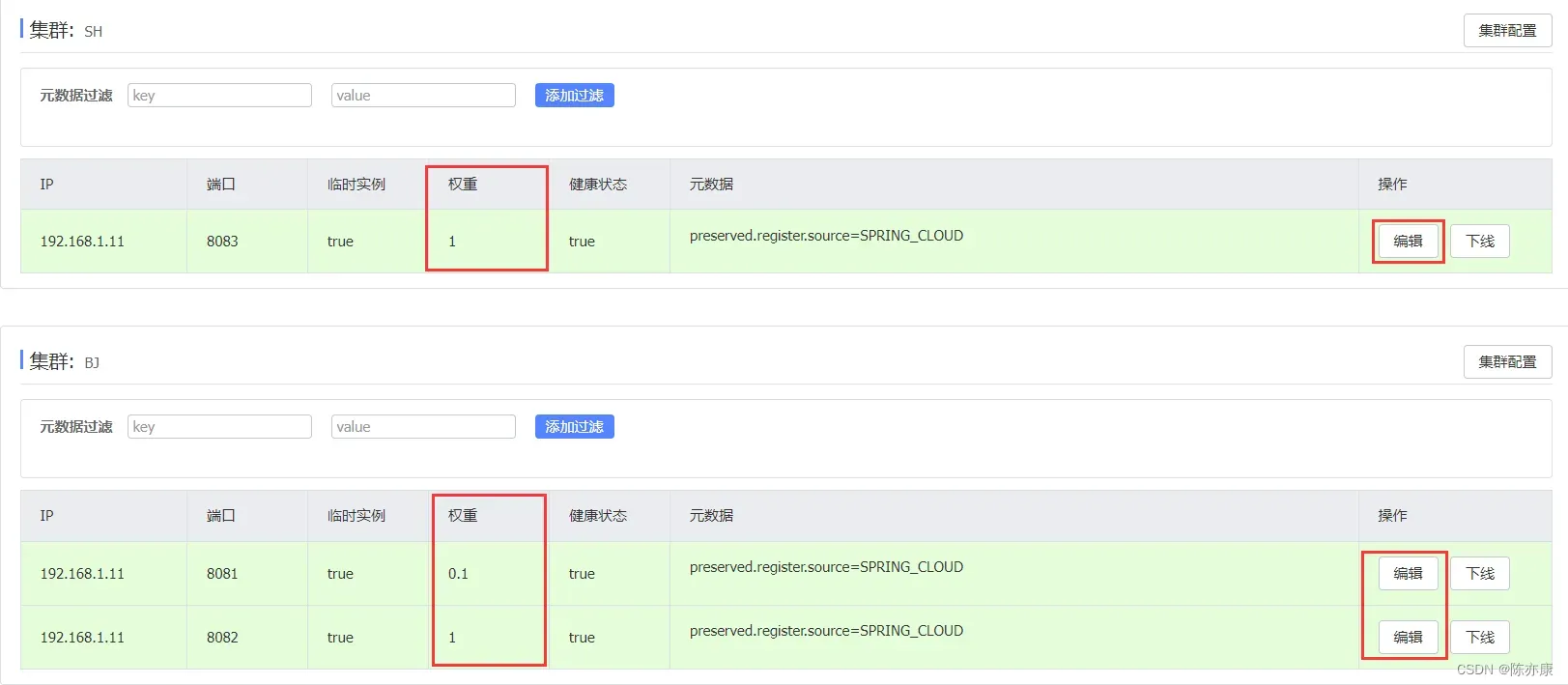
b)通过编辑按钮即可对一些信息进行修改,例如我们修改权重为0.1,如下:

c)修改完后点击确定,就完成啦,可以达到这样一个效果——使得端口为 8081 的服务访问频率是端口号为 8082 的服务访问频率的十分之一!
3.5、环境隔离——namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离,在实际的工作中,需要有开发环境、测试环境等,彼此直接的隔离就是通过 namespace 实现的,他们的关系如下图:
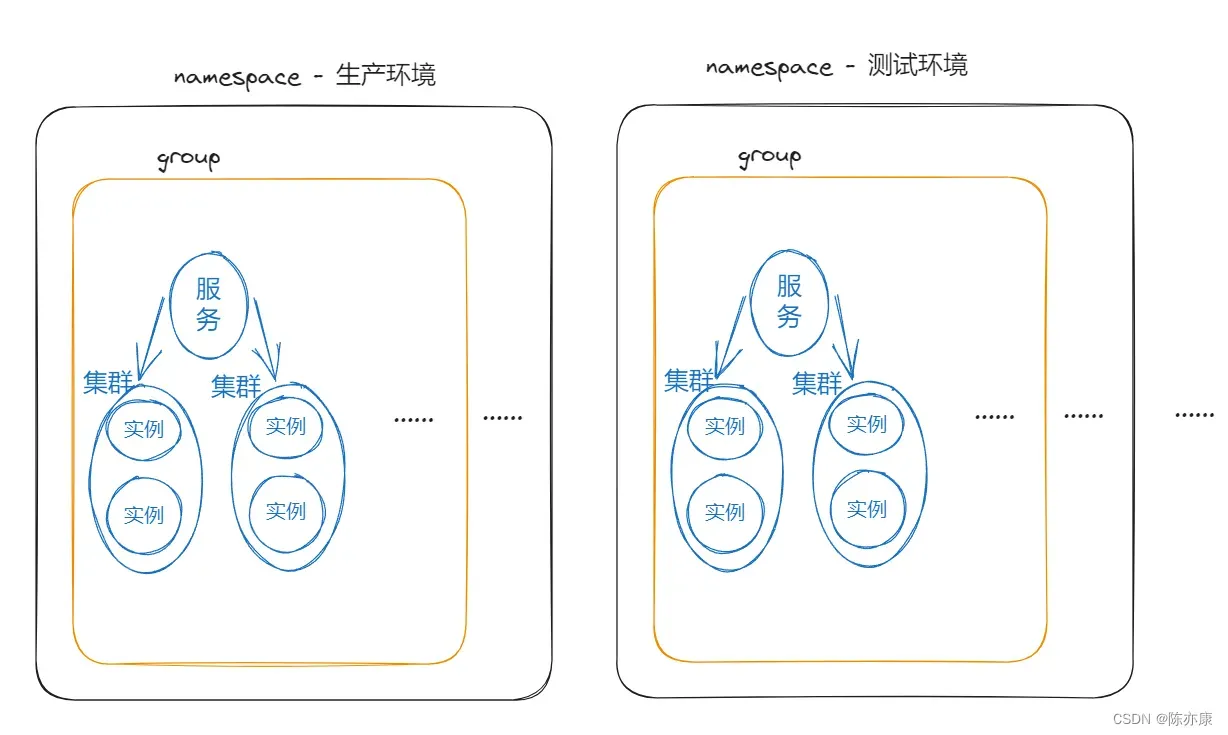
特点有如下三点:
- 每个namespace都有唯一id
- 服务设置namespace时要写id而不是名称
- 不同namespace下的服务互相不可见
配置环境隔离步骤如下:
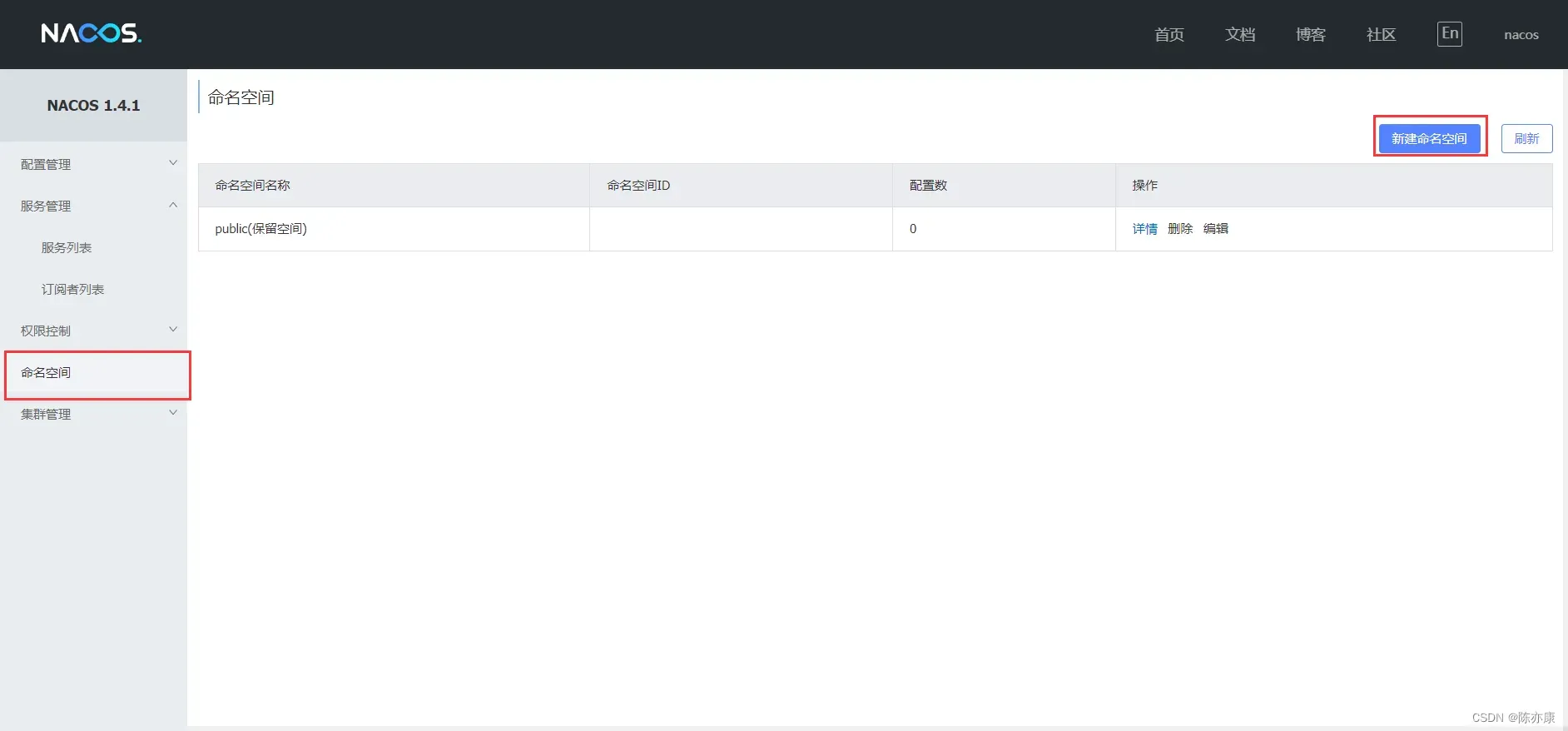
a)在 Nacos 主页中点击命名空间,再新建命名空间,如下:
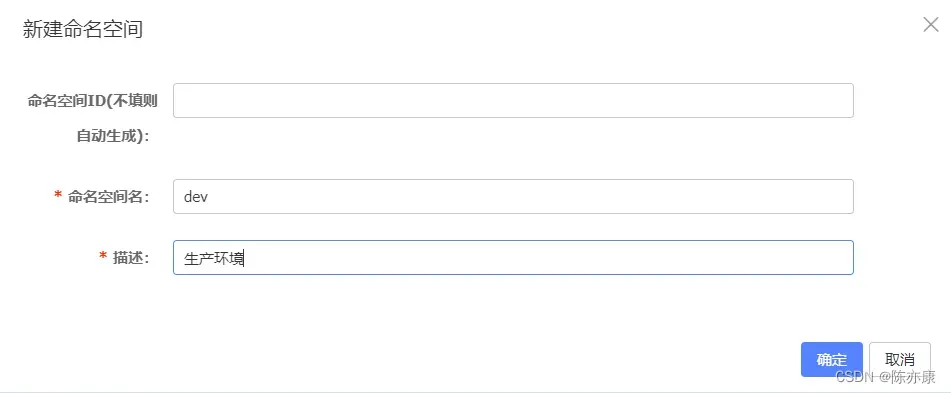
b)我们也可以根据需求取创建命名空间,例如创建生产环境,如下图:
c)确定后,就可以看到通过 UUID 随机生成的命名空间ID,如下:

d)修改 order-service 的 application.yml ,添加 namespace 和 命名空间 ID,如下:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false
username: root
password: 1111
driver-class-name: com.mysql.jdbc.Driver
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: BJ # 北京
namespace: 12c8df32-0dbf-48a0-9889-098a6d15c31d # dev
e)重启 order-service ,观察 Nacos 服务列表,可以看到 dev 命名空间下,出现了 order-service 的信息,如下:

f)由于不同的命名空间下的服务是相互不可见的,因此输入 url 再次请求的时候就会报错,如下:
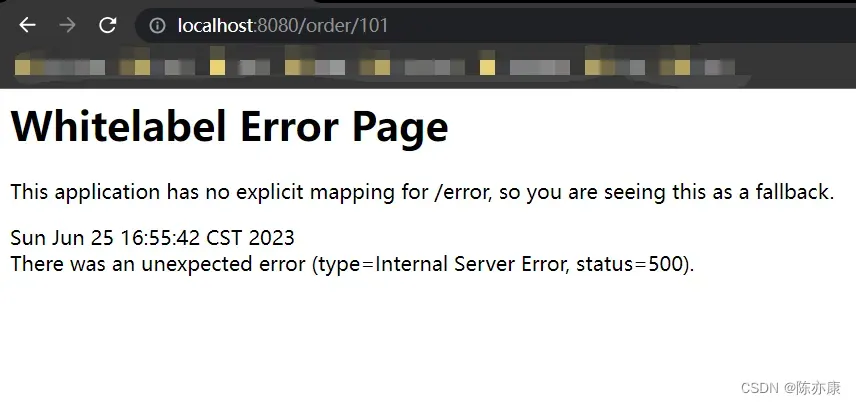
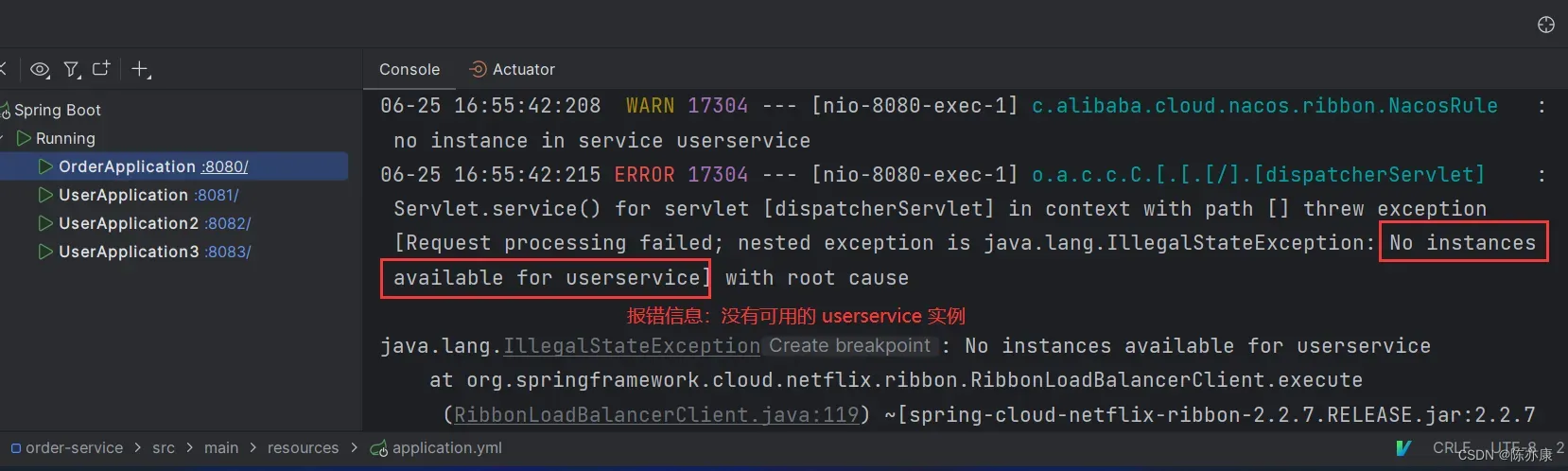
这样就是实现了环境隔离~
四、Nacos注册原理
4.1、工作原理
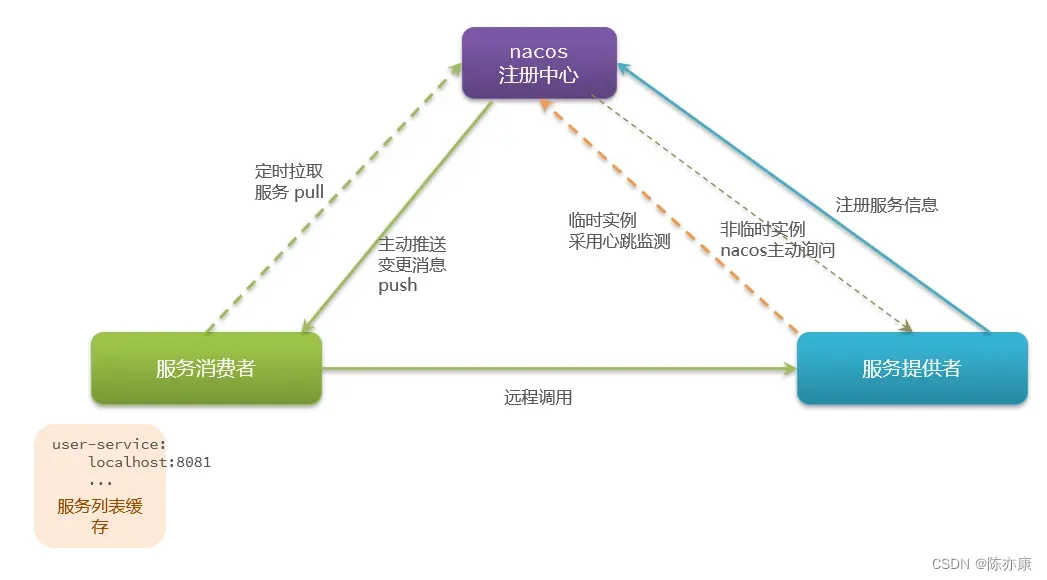
工作过程如下:
- 首先由服务提供者向 nacos 注册服务信息.
- 接着,服务消费者定时向 nacos 拉取服务(每隔30秒一次),并将拉取到的服务缓存到起来,下一次就可以不用去拉取,而是直接从缓存中拿,当然也不是每次都从缓存中拿,他会每隔30秒取拉取一次服务,并更新缓存.
- 另外,一旦 nacos 注册中心有新的变更,nacos 也会及时的通过消息推送机制,将更新信息推送给服务消费者.
- 消费者拿到服务列表之后,就可以通过负载均衡,向服务提供者发起远程调用.
- nacos 会把服务提供者划分成临时实例(可以直接人为停掉服务)和非临时实例(只能标记为下线),临时实例采用心跳检测(比 Eureka 快一些,每隔一段时间发一个请求),当有一天心跳检测发现不在了,nacos 就会把他从服务列表中直接删除,而非临时实例则不是使用心跳包,是由 nacos 主动向服务提供者发起询问,如果发现非临时实例挂了,不会从列表中删除,而是标记为“不健康”,等待这个实例恢复健康.
4.2、临时实例与非临时实例的配置
在 application.yml 中加入以下配置信息,即可修改为非临时实例,如下:
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例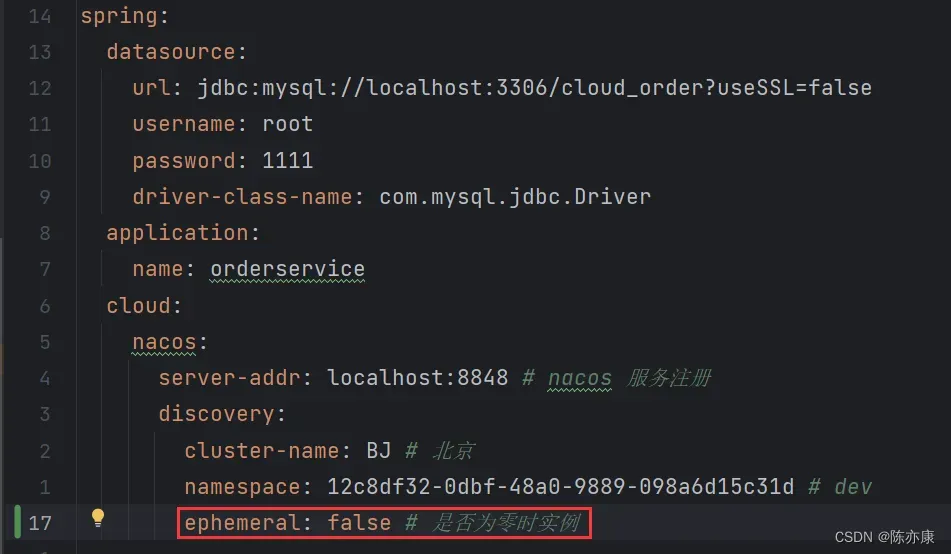
Ps:临时实例宕机时,会从nacos的服务列表中剔除,而非临时实例则不会
4.3、Nacos 和 Eureka 的区别
共同点:
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
不同点:
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,心跳不正常会被剔除,非临时实例采用主动检测模式,若不正常不会被剔除,只是作标记
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式

版权声明:本文为博主作者:陈亦康原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/CYK_byte/article/details/131372727