什么是随机森林
随机森林是多个决策树集成算法,树多了也就成了森林,随机森林包含多个决策树来降低过拟合,
那随机2字又该怎么解释呢??
随机体现在:
-
每次迭代时,对原始数据进行二次抽样来获得不同的训练数据。
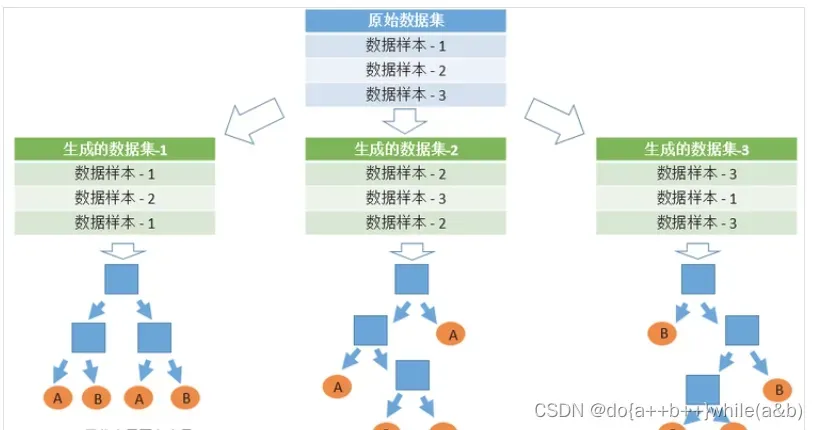
-
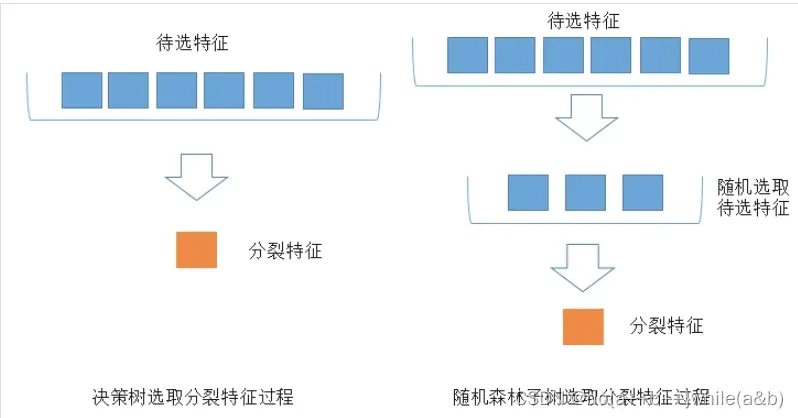
对于每个树节点,考虑不同的随机特征子集来进行分裂。
spark代码实现
spark.ml支持二分类、多分类以及回归的随机森林算法
数据采用https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
spark和scala版本如下

接下来就开始写代码了
减少日志输出和构建SparkSession环境
Logger.getLogger("org").setLevel(Level.ERROR)
val session: SparkSession = SparkSession.builder().master("local[*]")
.appName("RandomForest")
.getOrCreate()
读取数据集转换格式
val source: DataFrame = session.read.text("iris\\iris.data")
val data: DataFrame = source
.map((_: Row).toString().split(","))
.map(
(row: Array[String]) => (Vectors.dense(row(2).toDouble, row(3).toDouble),row(4).replace("]","")))
.toDF("features", "label")
使用索引器对数据进行转换
val indexedLabel: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
.fit(data)
val indexedFeatures: VectorIndexerModel = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures")
.fit(data)
数据随机切分(分的数量有些许偏差)
// 7分训练 3分测试
val Array(training, test) = data.randomSplit(Array(0.7, 0.3))
构建随机森林分类器
// 随机森林分类器
val classifier: RandomForestClassifier = new RandomForestClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setMaxDepth(5)
.setNumTrees(20)
.setMaxBins(32)
对预测的结果转换成标签
val labelConverter: IndexToString = new IndexToString().
setInputCol("prediction").
setOutputCol("predictedLabel").
setLabels(indexedLabel.labels)
使用pipline构建模型,对7分数据进行训练,三分数据进行测试
val pipeline: Pipeline = new Pipeline()
.setStages(Array(indexedLabel, indexedFeatures, classifier, labelConverter))
val model: PipelineModel = pipeline.fit(training)
val predictions: DataFrame = model.transform(test)
输出观察一下预测结果
predictions.select("indexedLabel","prediction").show(150)
我们可以使用多分类评估器对我们的模型进行评估
val evaluator: MulticlassClassificationEvaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val d: Double = evaluator.evaluate(predictions)
println(s"正确率:${d}--错误:${1 - d}")
正确率:0.9333333333333333--错误:0.06666666666666665
可以看出,我们的模型预测正确率已经非常高了
到此,随机森林的简单使用已经完成
文章出处登录后可见!
已经登录?立即刷新