自己近期跑了FCN和maskR-CNN网络模型,原作者都是在coco或者是VOC数据集上训练的权重,然后进行识别。其中FCN是用来做语义分割任务的,maskR-CNN采用来双分支结构,同时用来做语义分割和目标检测。
COCO数据集有80个类别,VOC数据集有20个类别。当这些数据集类别中没有自己需要的时候,就需要自己动手做自己的数据集了。
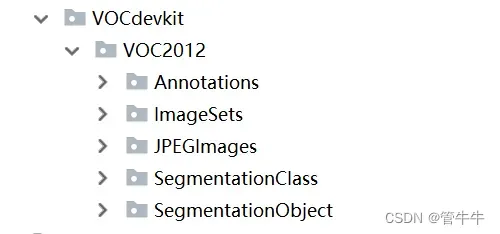
我自己在做数据集的时候主要使用到了labelme和labelImg两个工具。labelme主要是制作语义分割数据集(ImageSets,JPEGImages,SegmentationClass,SegmentationObject几个文件夹),labelImg主要是制作目标检测数据集(主要是Annoations中的xml文件),最后把两个何在一起就可以使用maskR-CNN来训练了。文件结构如下图所示
建议在annoconda中安装。在conda环境中创建和安装labelme的命令如下:
conda create -n labelme python=3.7
activate labelme
pip install pyqt
pip install labelme然后再环境中直接使用labelme命令打开工具:
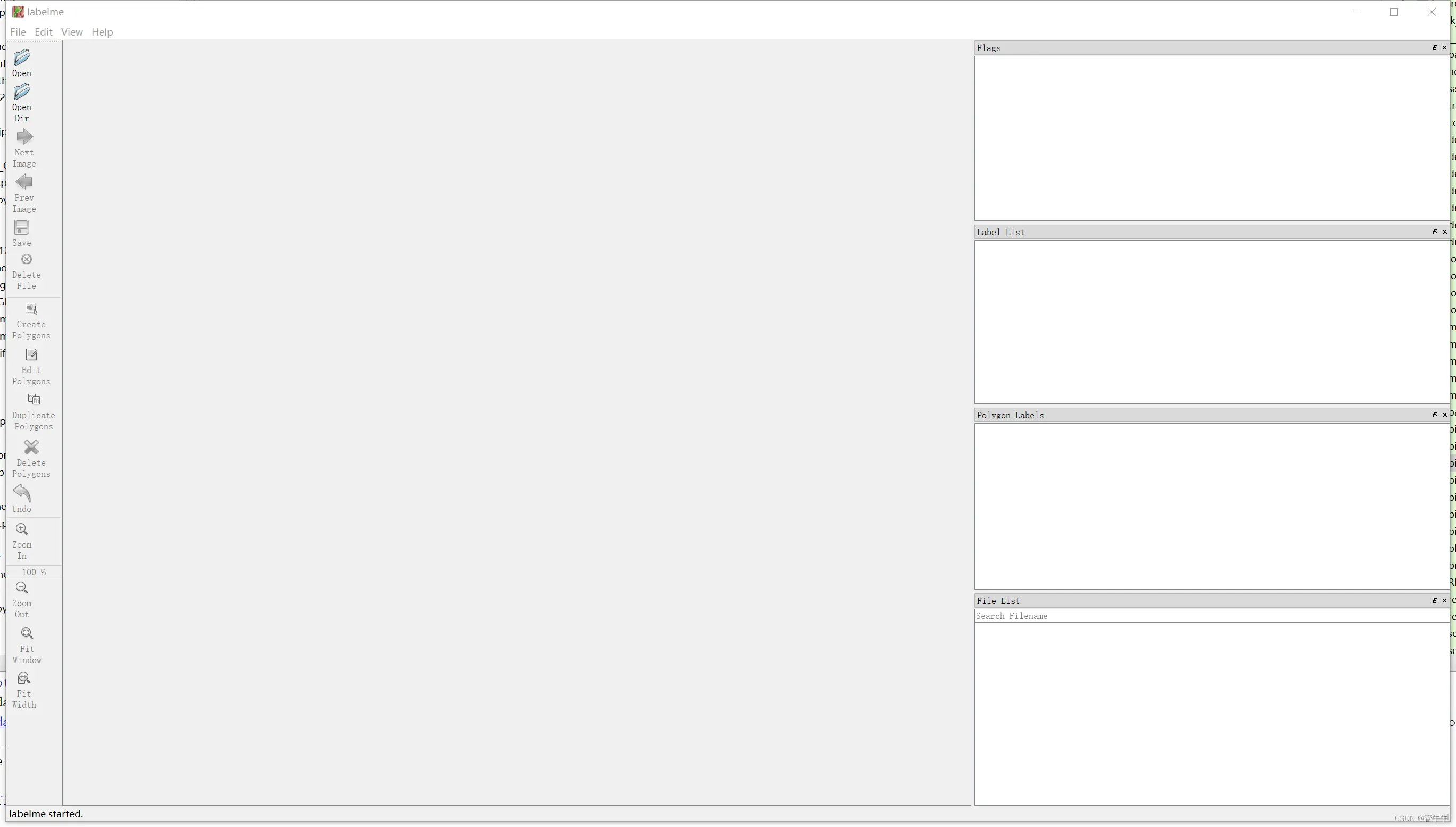
点击OpenDir打开要制作数据集图片的文件夹。点击CreatePolygons标记图片就可以了,最后每张图片标记好之后,别忘记点击save保存。此时的会保存问json格式的文件,如图所示:
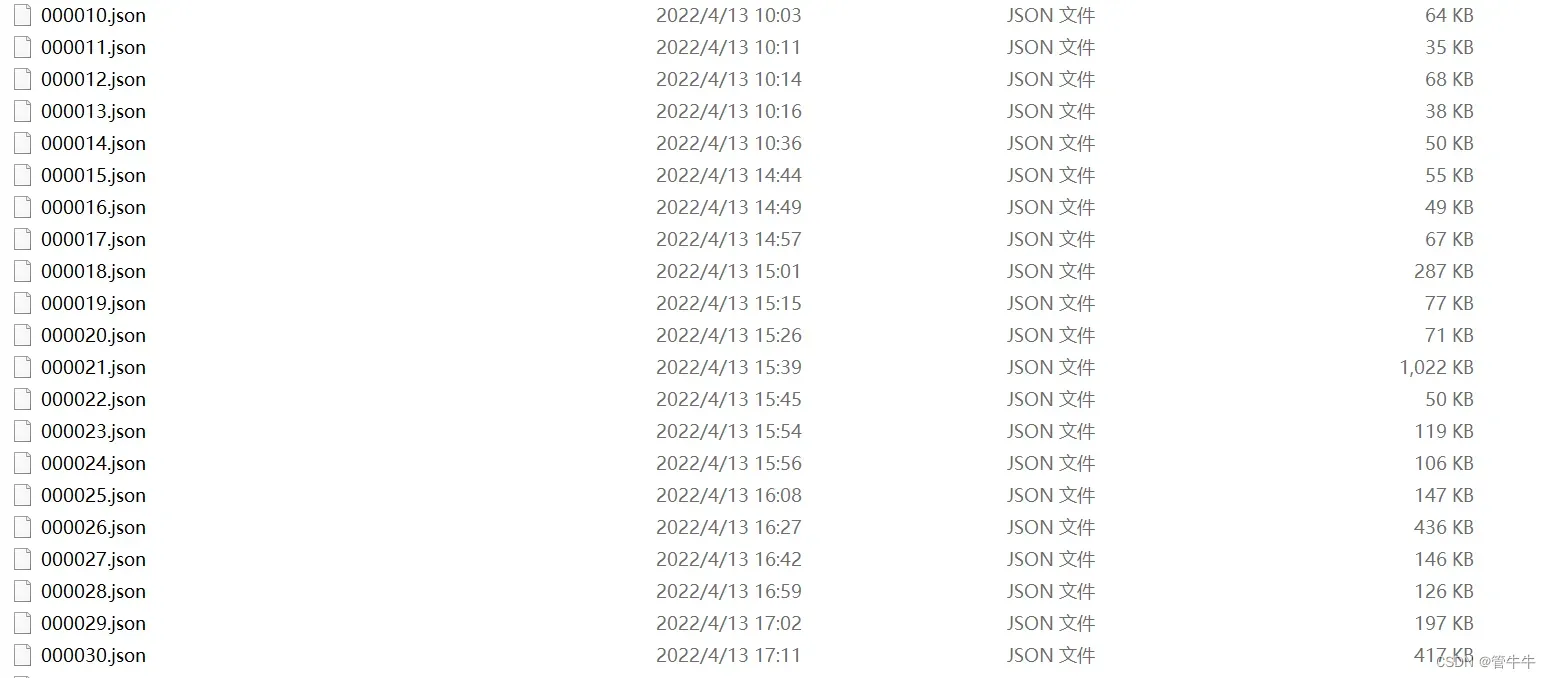
接下来就要转换这些json格式为轮廓图片。
在json文件的目录下启动cmd,命令conda activate labelme切换至labelme环境下。
输入命令
labelme_json_to_dataset K:\\MyDataset\\json_data 注:K:\\MyDataset\\json_data为自己存放json文件的文件夹,运行后在此文件中就会出现转换好的文件夹了。打开其中的某一个:

其中的label.png就是标记好的轮廓图片。最后讲原始图片和轮廓图片按照相对应的名字分别存放在 JPEGImages和SegmentationClass中(我这里Object中放的是和Class文件夹中同样的图片)。
使用如下代码生成ImageSets文件夹中Segmentation文件中的test.txt,train.txt和val.txt文件(分别是测试、训练和验证文件)
import os
import shutil
from sklearn.model_selection import train_test_split
# 从json中挑出mask文件
inputdir = r'K:\MyDataset\label' # 存放json文件的文件夹
outputdir = r'K:\MyDataset\MyVOC2022\SegmentationClass'
c = 1
for dir in os.listdir(inputdir):
# 设置旧文件名(就是路径+文件名)
oldname = inputdir + os.sep + dir + os.sep + 'label.png' # os.sep添加系统分隔符
# 设置新文件名
# c = outputdir + os.sep + dir.split('_')[1]
a = "0" * (6 - len(str(c)))
newname = outputdir + os.sep + a + str(c) + '.png'
shutil.copyfile(oldname, newname) # 用os模块中的rename方法对文件改名
print(oldname, '======>', newname)
c += 1
#原始数据转换
inputdir = r'K:\MyDataset\pig_image' #存放初始数据的文件夹
outputdir = r'K:\MyDataset\MyVOC2022\JPEGImages'
c = 1
for dir in os.listdir(inputdir):
# 设置旧文件名(就是路径+文件名)
oldname = inputdir + os.sep + dir # os.sep添加系统分隔符
# 设置新文件名
#c = outputdir + os.sep + dir.split('_')[1]
a = "0" * (6 - len(str(c)))
newname =outputdir + os.sep +a + str(c) + '.jpg'
shutil.copyfile(oldname, newname) # 用os模块中的rename方法对文件改名
print(oldname, '======>', newname)
c += 1
#生成txt文件
imagedir = 'K:\MyDataset\MyVOC2022\JPEGImages'
outdir = r'K:\MyDataset\MyVOC2022\ImageSets\Segmentation'
images = []
for file in os.listdir(imagedir):
filename = file.split('.')[0]
images.append(filename)
# 训练集测试集验证集比例为:4:2:2
train, test = train_test_split(images, train_size=0.5, random_state=0)
val, test = train_test_split(test, train_size=0.5, random_state=0)
with open(outdir + os.sep +"train.txt", 'w') as f:
f.write('\n'.join(train))
with open(outdir + os.sep +"val.txt", 'w') as f:
f.write('\n'.join(val))
with open(outdir + os.sep +"test.txt", 'w') as f:
f.write('\n'.join(test))
按照以上操作,FCN语义分割数据集就制作好了。接下来制作目标检测的部分:
在conda环境中安装labelImg工具非常简单:
使用命令:pip install labelimg
labelimg打开工具:
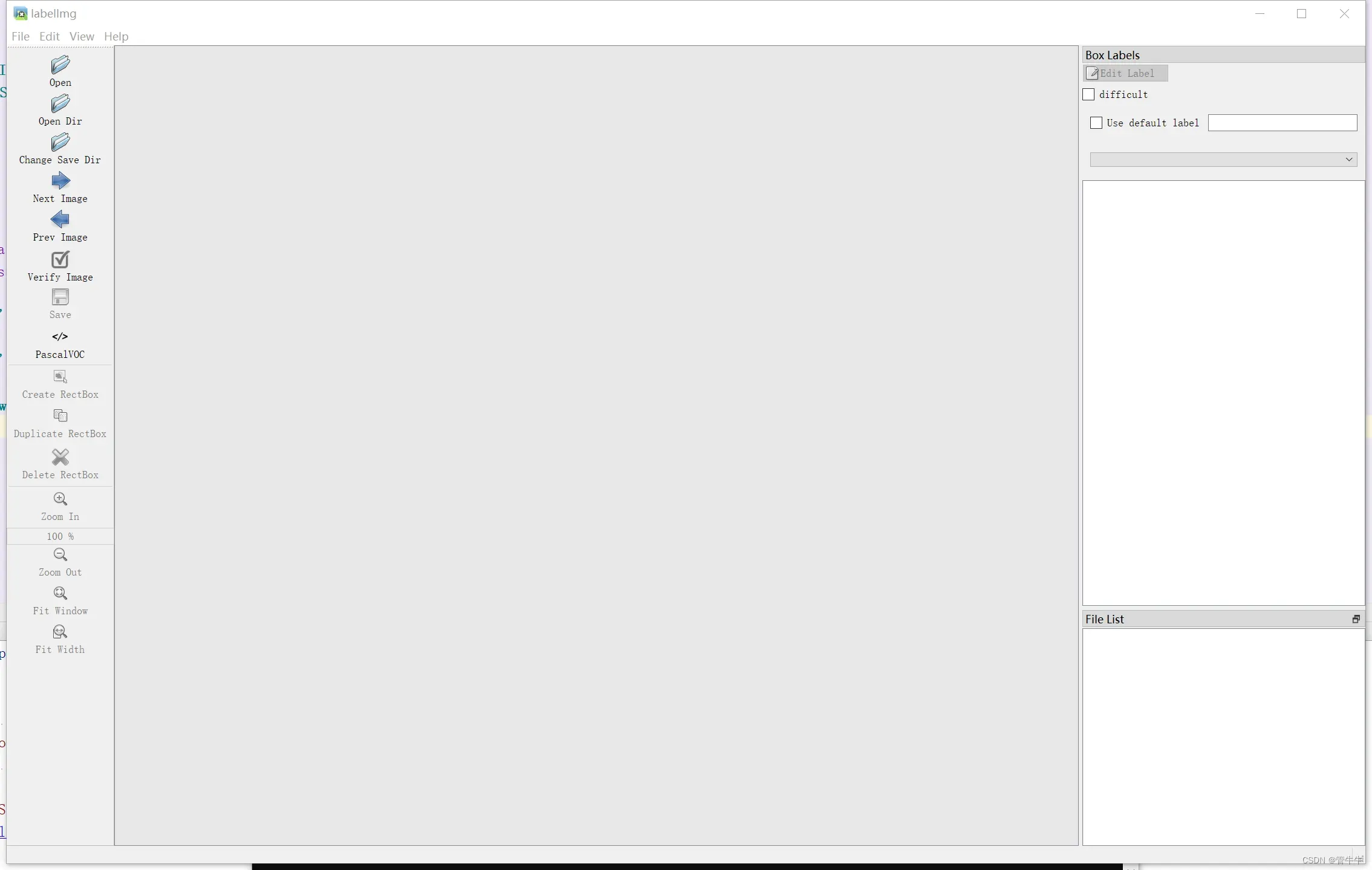
点击Create RectBox就可以标记图片了,图片标记号后会生成xml文件:
这里的文件名要和之前的文件名一一对应。xml文件中存放的是图片中框起来的目标的信息:

把这些xml文件复制到Annotations文件夹下就可以了。随后就可以使用maskR-CNN来训练这些图片了,训练好之后就可以进行识别预测了。

文章出处登录后可见!