在阿里达摩院 ICLR2022 发表的论文《GiraffeDet: A Heavy-Neck Paradigm for Object Detection》中,他们提出了GiraffeDet,它具有极轻量级计算量的backbone和大计算量的neck,使得网络更关注于高分辨率特征图中空间信息和低分辨率特征图中语义信息的信息交互。同时在2022年11月底他们开源的DAMO YOLO中,再一次用到了GFPN的思想,他们基于queen-fusion的GFPN,加入了高效聚合网络(ELAN)和重参数化的思想,构成了一个新的Neck网络RepGFPN,乘着火热,本篇将在YOLOv6 Pro框架中,在YOLOV6的neck结构中改入RepGFPN,同样改进也可以在YOLOv5中实现。
惯例,介绍下YOLOv6 Pro框架!
· YOLOv6 Pro 基于官方
YOLOv6的整体架构,使用YOLOv5的网络构建方式构建一个YOLOv6网络,包括backbone,neck,effidehead结构。
· 可以在yaml文件中任意修改或添加模块,并且每个修改的文件都是独立可运行的,目的是为了助力科研。
· 后续会基于yolov5和yoloair中的模块加入更多的网络结构改进。
· 预训练权重已经从官方权重转换,确保可以匹配。· 预先发布了p6模型(非官方)
· 已经加入了一些其他改进模块,如RepGFPN,FocalTransformer,RepGhost,CoAtNet等
我们使用的 yoloair 和 YOLOv6 pro 框架在 IEEE UV 2022 "Vision Meets Alage" 目标检测竞赛中取得第一名!
项目链接:GitHub – yang-0201/YOLOv6_pro: Make it easier for yolov6 to change the network structure
感兴趣的小伙伴们可以点点Star和Fork,有问题可以及时反馈,项目初期,会对一些功能意见会进行采纳和开发,也欢迎志同道合的朋友来提PR,共同维护和开发项目,项目后续会持续更新和完善,敬请关注!
进入正题!
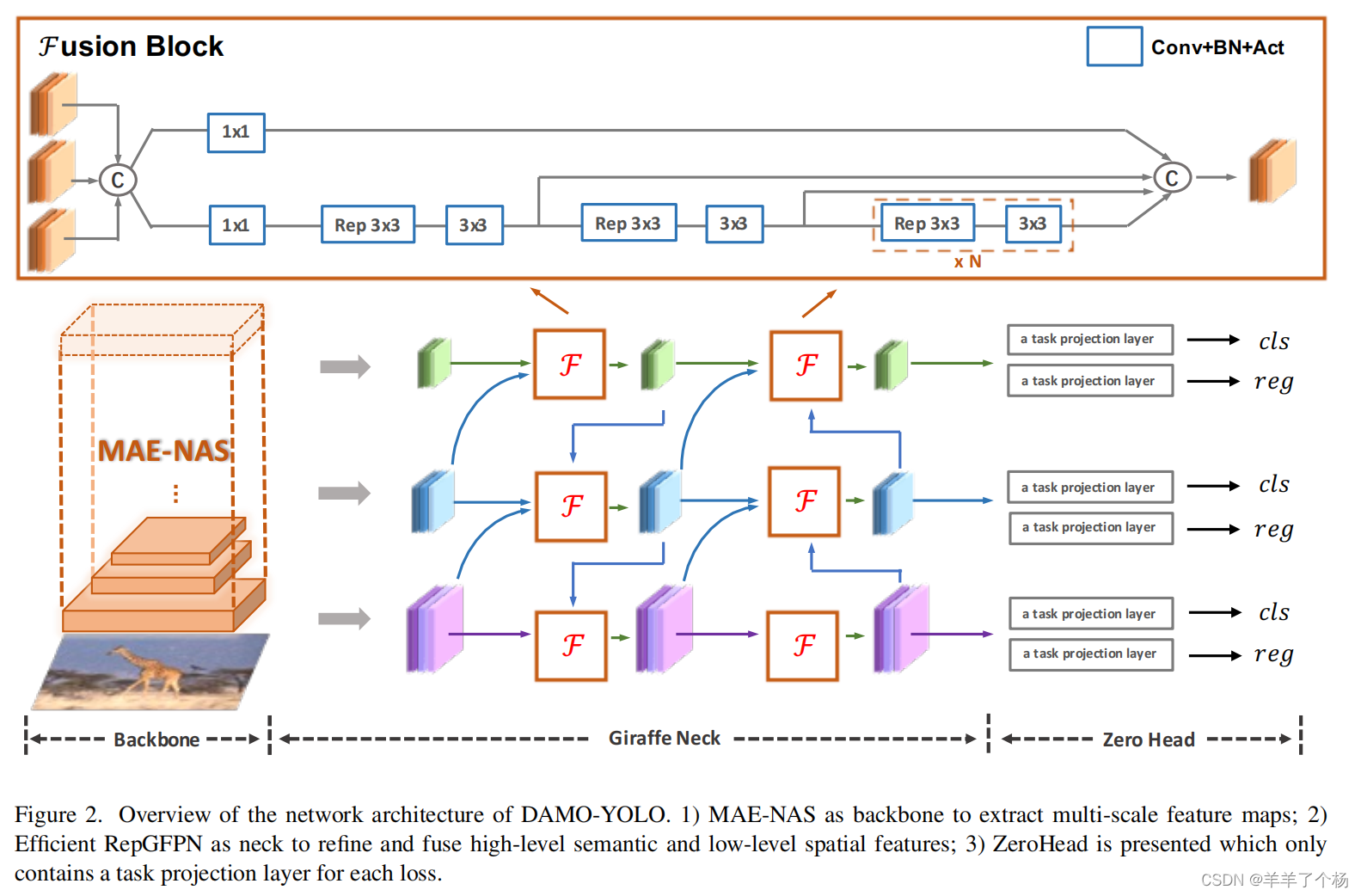
DAMO YOLO:论文地址 https://arxiv.org/pdf/2211.15444.pdf
这是整个DAMO YOLO的网络结构图,包括基于神经结构搜索NAS技术得到的MAE-NAS主干网络,RepGFPN和一个ZeroHead结构,我们今天主要关注的是RepGFPN结构,可以发现主要的模块是Fusion Block结构。
作者认为GFPN有效的主要原因之一是因为它可以充分交换高级语义信息和低级空间信息。在GFPN中,多尺度特征在前一层和当前层的层次特征中都被融合。更重要的是,log2(n)跳过层连接提供了更有效的信息传输,可以扩展到更深层次的网络。
同样,当他们在现代yolo系列模型上用GFPN直接替换原先的Neck结构后,可以获得了更高的精度。(后续可以尝试GFPN的替换)但是他们发现的问题在于基于GFPN的模型的延迟远远高于基于改进的panet的模型,所以精度的提升或许有些得不偿失。总结以下几个原因:
1. 不同尺度的特征图具有相同的通道维度;
2. queen-fusion的不能满足实时检测模型的要求;
3. 基于卷积的跨尺度特征融合效率低下;
基于GFPN,我们提出了一种新颖的高效——RepGFPN满足实时目标检测的设计,综合考虑这些原因,作者的思想有以下几点:
1. 由于不同尺度特征图的flop差异较大,在计算成本有限的约束下,很难控制每个尺度特征图共享的相同的通道数。
因此,在作者的的neck特征融合中,采用了不同通道维度的不同尺度特征图的设置。作者比较了相同和不同通道的性能以及neck深度和宽度的权衡,如下表
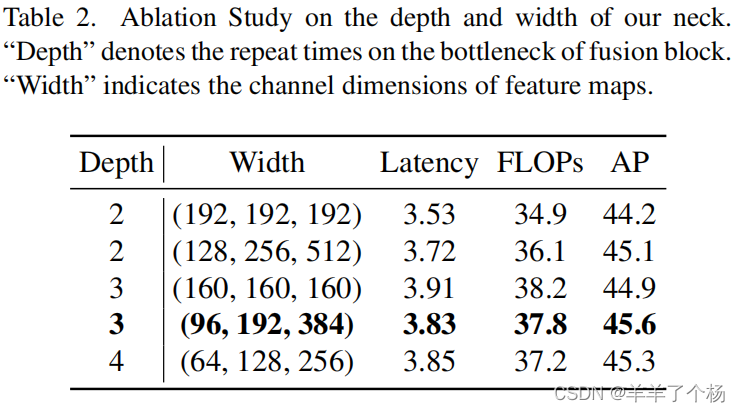
我们可以看到,通过灵活地控制不同尺度上的信道数量,我们可以获得比在所有尺度上共享相同通道数更高的精度。当深度等于3,宽度等于(96、192、384)时,可以获得最佳的性能。
2) GFPN通过queen-fusion增强了特征交互,但它也带来了大量额外的上采样和降采样操作。
作者比较了这些上采样和下采样操作的性能,结果如表所示
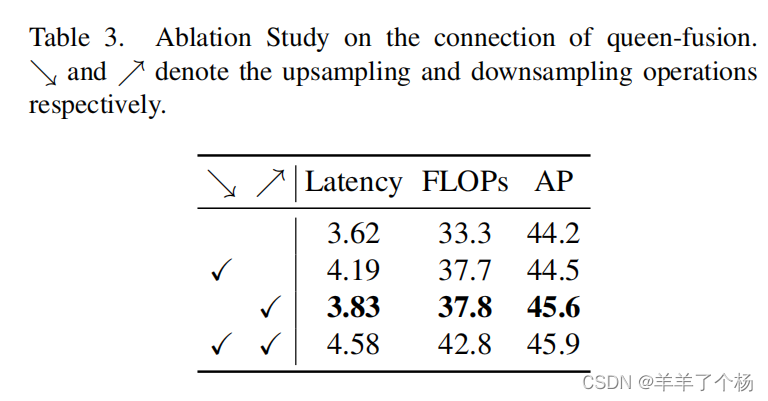
我们可以看到,额外的上采样操作导致延迟增加了0.6 ms,而精度的提高只有0.3mAP,远低于额外的下采样操作带来的性能提升。因此,在实时检测的约束下,我们去掉了queen-fusion中额外的上采样操作。
3. 在特征融合块中,我们首先用CSPNet替换原始的基于3×3卷积的特征融合,获得4.2 mAP增益。之后,我们通过结合重参数化机制和高效层聚合网络(ELAN)的连接来升级CSPNet。由于不带来额外巨大的计算负担,我们实现了更高的精度。比较的结果列于表中
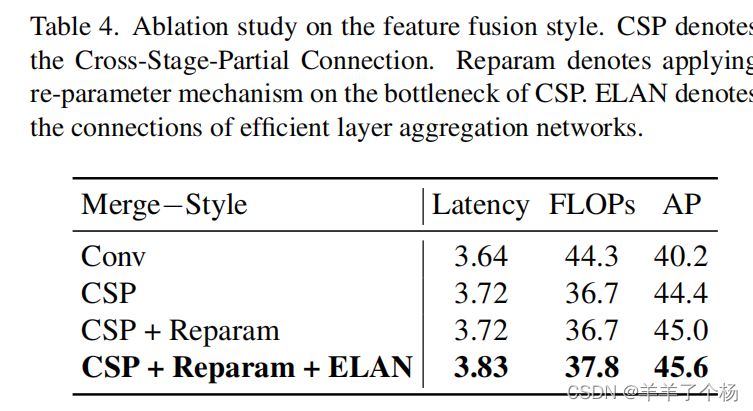
经过论文中的介绍,相信大家已经对 RepGFPN的思想有所了解,下面来看看代码!
我参考DAMO YOLO 的源码在YOLOv6 Pro的框架中加入了RepGFPN结构,包括RepGFPN-T,RepGFPN-M,RepGFPN-S,分别加在了YOLOv6l和YOLOv6t中作为示例
先看yolov6l+RepGFPN-M结构的yaml文件:
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
backbone:
# [from, number, module, args]
[[-1, 1, ConvWrapper, [64, 3, 2]], # 0-P1/2
[-1, 1, ConvWrapper, [128, 3, 2]], # 1-P2/4
[-1, 1, BepC3, [128, 6, "ConvWrapper"]],
[-1, 1, ConvWrapper, [256, 3, 2]], # 3-P3/8
[-1, 1, BepC3, [256, 12, "ConvWrapper"]],
[-1, 1, ConvWrapper, [512, 3, 2]], # 5-P4/16
[-1, 1, BepC3, [512, 18, "ConvWrapper"]],
[-1, 1, ConvWrapper, [1024, 3, 2]], # 7-P5/32
[-1, 1, BepC3, [1024, 6, "ConvWrapper"]],
[-1, 1, SPPF, [1024, 5]]] # 9
neck:
[
[ 6, 1,ConvBNAct,[ 256, 3, 2, silu ] ],
[ [ -1, 9 ], 1, Concat, [ 1 ] ], # 768
[ -1, 1, RepGFPN, [ 512, 1.5, 1.0, silu ] ], # 8
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ 4, 1,ConvBNAct,[ 128, 3, 2, silu ] ],
[ [ -1, 6, 13 ], 1, Concat, [ 1 ] ], # 896
[ -1, 1, RepGFPN, [ 256, 1.5, 1.0, silu ] ], # merge_4 12
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 4 ], 1, Concat, [ 1 ] ], # 384
[ -1, 1, RepGFPN, [ 128, 1.5, 1.0, silu ] ], # 512+256 merge_5 15 out
[ -1, 1,ConvBNAct,[ 128, 3, 2, silu ] ],
[ [ -1, 16 ], 1, Concat, [ 1 ] ], # 384
[ -1, 1, RepGFPN, [ 256, 1.5, 1.0, silu ] ], # 512+256 merge_7 18 out
[ 16, 1,ConvBNAct,[ 256, 3, 2, silu ] ],
[ -2, 1,ConvBNAct,[ 256, 3, 2, silu ] ],
[ [ -1, 12, -2 ], 1, Concat, [ 1 ] ], # 1024
[ -1, 1, RepGFPN, [ 512, 1.5, 1.0, silu ] ], # 512+512+1024 merge_6 22 out
]
effidehead:
[[19, 1,Head_out , [128, 16]],
[22, 1, Head_out, [256, 16]],
[26, 1, Head_out, [512, 16]],
[[27, 28, 29], 1, Out, []]]
对比下原图
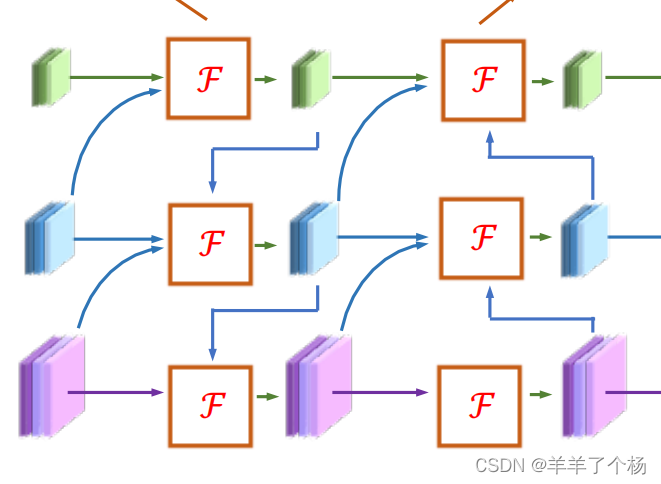
其中各种颜色的模块就是ConvBNAct,是一个简单的卷积加标准化加relu/silu激活函数的模块。
Fusion Block就是主要的融合模块,对应yaml文件中的RepGFPN
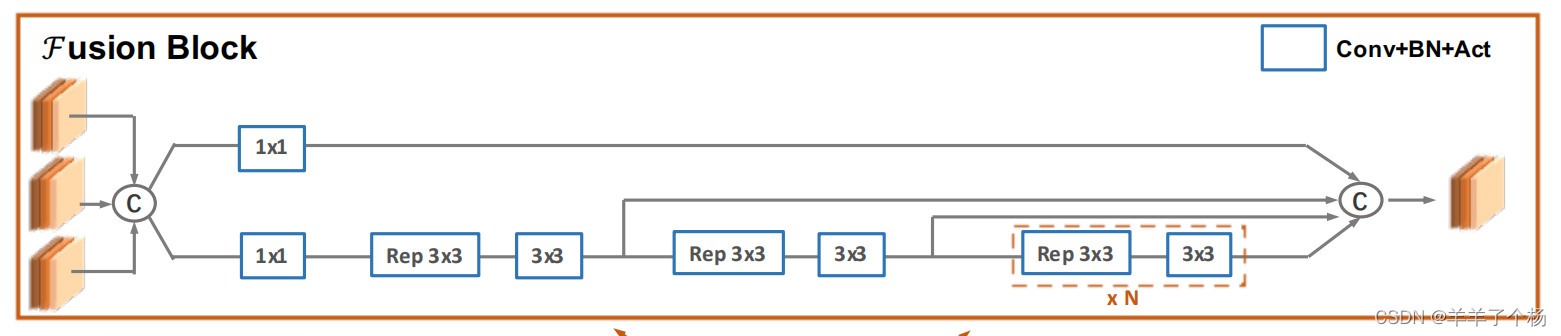
输入为两个或者三个层,经过concat之后,分别用1×1卷积降通道,下方就是模仿ELAN的特征聚合模块,由N个Rep 3×3卷积和3×3卷积组成,不同层同时输出,再通过concat得到最终的输出。
输入RepGFPN的参数含义为[输出通道,深度系数,中间层通道的缩放因子,使用的激活函数类型],为了保持重Neck,轻Head的思想,我去掉了6的解耦头,换为了Head_out 做一个简单输出
yolov6t+RepGFPN-T结构的yaml文件:
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.375 # layer channel multiple
backbone:
# [from, number, module, args]
[[-1, 1, RepVGGBlock, [64, 3, 2]], # 0-P1/2
[-1, 1, RepVGGBlock, [128, 3, 2]], # 1-P2/4
[-1, 6, RepBlock, [128]],
[-1, 1, RepVGGBlock, [256, 3, 2]], # 3-P3/8
[-1, 12, RepBlock, [256]],
[-1, 1, RepVGGBlock, [512, 3, 2]], # 5-P4/16
[-1, 18, RepBlock, [512]],
[-1, 1, RepVGGBlock, [1024, 3, 2]], # 7-P5/32
[-1, 6, RepBlock, [1024]],
[-1, 1, SimSPPF, [1024, 5]]] # 9
neck:
[
[ 6, 1,ConvBNAct,[ 192, 3, 2 ] ],
[ [ -1, 9 ], 1, Concat, [ 1 ] ], # 576
[ -1, 1, RepGFPN, [ 384, 1.0, 1.0 ] ], # 8
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ 4, 1,ConvBNAct,[ 96, 3, 2 ] ],
[ [ -1, 6, 13 ], 1, Concat, [ 1 ] ], # 672
[ -1, 1, RepGFPN, [ 192, 1.0, 1.0 ] ], # merge_4 12
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 4 ], 1, Concat, [ 1 ] ], # 288
[ -1, 1, RepGFPN, [ 64, 1.0, 1.0 ] ], # merge_5 15 out
[ -1, 1,ConvBNAct,[ 64, 3, 2 ] ],
[ [ -1, 16 ], 1, Concat, [ 1 ] ], # 256
[ -1, 1, RepGFPN, [ 128, 1.0, 1.0 ] ], # merge_7 18 out
[ 16, 1,ConvBNAct,[ 192, 3, 2 ] ],
[ -2, 1,ConvBNAct,[ 128, 3, 2 ] ],
[ [ -1, 12, -2 ], 1, Concat, [ 1 ] ], # 704
[ -1, 1, RepGFPN, [ 256, 1.0, 1.0 ] ], # merge_6 22 out
]
effidehead:
[[19, 1,Head_out , [170, 0]], ##170 * 0.375 = 64
[22, 1, Head_out, [341, 0]], ##341 * 0.375 = 128
[26, 1, Head_out, [682, 0]], ##682 * 0.375 = 256
[[27, 28, 29], 1, Out, []]]
需要加入的代码为,在common.py中加入,或者自己新建一个RepGFPN.py文件,再在common.py中导入模块名称,
from yolov6.layers.damo_yolo import ConvBNAct,RepGFPNimport numpy as np
import torch
import torch.nn as nn
class RepGFPN(nn.Module):
def __init__(self,in_channels,out_channels,depth=1.0,hidden_ratio = 1.0,act = 'relu',block_name='BasicBlock_3x3_Reverse',spp = False):
super(RepGFPN, self).__init__()
self.merge_3 = CSPStage(block_name,
in_channels,
hidden_ratio,
out_channels,
round(3 * depth),
act=act)
def forward(self,x):
x = self.merge_3(x)
return x
class CSPStage(nn.Module):
def __init__(self,
block_fn,
ch_in,
ch_hidden_ratio,
ch_out,
n,
act='swish',
spp=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = ConvBNAct(ch_in, ch_first, 1, act=act)
self.conv2 = ConvBNAct(ch_in, ch_mid, 1, act=act)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
act=act,
shortcut=True))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module(
'spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13], act=act))
next_ch_in = ch_mid
self.conv3 = ConvBNAct(ch_mid * n + ch_first, ch_out, 1, act=act)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y
class ConvBNAct(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self,
in_channels,
out_channels,
ksize,
stride=1,
act='relu',
groups=1,
bias=False,
norm='bn',
reparam=False,
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
if norm is not None:
self.bn = get_norm(norm, out_channels, inplace=True)
if act is not None:
self.act = get_activation(act, inplace=True)
self.with_norm = norm is not None
self.with_act = act is not None
def forward(self, x):
x = self.conv(x)
if self.with_norm:
x = self.bn(x)
if self.with_act:
x = self.act(x)
return x
def fuseforward(self, x):
return self.act(self.conv(x))
class BasicBlock_3x3_Reverse(nn.Module):
def __init__(self,
ch_in,
ch_hidden_ratio,
ch_out,
act='relu',
shortcut=True):
super(BasicBlock_3x3_Reverse, self).__init__()
assert ch_in == ch_out
ch_hidden = int(ch_in * ch_hidden_ratio)
self.conv1 = ConvBNAct(ch_hidden, ch_out, 3, stride=1, act=act)
self.conv2 = RepConv(ch_in, ch_hidden, 3, stride=1, act=act)
self.shortcut = shortcut
def forward(self, x):
y = self.conv2(x)
y = self.conv1(y)
if self.shortcut:
return x + y
else:
return y
def get_norm(name, out_channels, inplace=True):
if name == 'bn':
module = nn.BatchNorm2d(out_channels)
else:
raise NotImplementedError
return module
class SPP(nn.Module):
def __init__(
self,
ch_in,
ch_out,
k,
pool_size,
act='swish',
):
super(SPP, self).__init__()
self.pool = []
for i, size in enumerate(pool_size):
pool = nn.MaxPool2d(kernel_size=size,
stride=1,
padding=size // 2,
ceil_mode=False)
self.add_module('pool{}'.format(i), pool)
self.pool.append(pool)
self.conv = ConvBNAct(ch_in, ch_out, k, act=act)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
y = torch.cat(outs, axis=1)
y = self.conv(y)
return y
import torch.nn.functional as F
class Swish(nn.Module):
def __init__(self, inplace=True):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
if self.inplace:
x.mul_(F.sigmoid(x))
return x
else:
return x * F.sigmoid(x)
class RepConv(nn.Module):
'''RepConv is a basic rep-style block, including training and deploy status
Code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
dilation=1,
groups=1,
padding_mode='zeros',
deploy=False,
act='relu',
norm=None):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
if isinstance(act, str):
self.nonlinearity = get_activation(act)
else:
self.nonlinearity = act
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = None
self.rbr_dense = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=padding_11,
groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(
self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(
kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3),
dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(
branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(
in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size,
stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding,
dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
def get_activation(name='silu', inplace=True):
if name is None:
return nn.Identity()
if isinstance(name, str):
if name == 'silu':
module = nn.SiLU(inplace=inplace)
elif name == 'relu':
module = nn.ReLU(inplace=inplace)
elif name == 'lrelu':
module = nn.LeakyReLU(0.1, inplace=inplace)
elif name == 'swish':
module = Swish(inplace=inplace)
elif name == 'hardsigmoid':
module = nn.Hardsigmoid(inplace=inplace)
elif name == 'identity':
module = nn.Identity()
else:
raise AttributeError('Unsupported act type: {}'.format(name))
return module
elif isinstance(name, nn.Module):
return name
else:
raise AttributeError('Unsupported act type: {}'.format(name))
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
'''Basic cell for rep-style block, including conv and bn'''
result = nn.Sequential()
result.add_module(
'conv',
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result在yolo.py 中加入
elif m in [RepGFPN, ConvBnAct]:
c1 = ch[f]
c2 = args[0]
args = [c1, c2, *args[1:]]大功告成!
文章出处登录后可见!