1、定义
深度学习是机器学习的一个分支,包括使用人工神经网络。 特别是,深度学习算法允许计算机程序学习和发现大量数据中的模式。
人工神经网络是受生物体中生物神经网络工作原理启发的算法。 人工神经网络通常由相互连接的节点和权重组成。因此,输入信号首先通过称为神经元的节点传递。然后,这些神经元被一个函数激活并乘以权重以产生输出信号。
因此,当我们在特定数据集上采用深度学习算法时,我们会生成一个可以接收一些输入并产生输出的模型。为了评估这些模型的性能,我们使用一种称为损失的度量。具体来说,这种损失量化了模型产生的误差。
2、训练损失
训练损失是用于评估深度学习模型如何拟合训练数据的指标。也就是说,它评估模型在训练集上的误差。需要注意的是,训练集是用于初始训练模型的数据集的一部分。在计算上,训练损失是通过计算训练集中每个示例的误差总和来计算的。同样重要的是要注意训练损失是在每批之后测量的。这通常通过绘制训练损失曲线来可视化。
3、验证损失
相反,验证损失是用于评估深度学习模型在验证集上的性能和指标。验证集是数据集的一部分,用于验证模型的性能。验证损失类似于训练损失,是根据验证集中的每个示例的误差总和计算得出的。
此外,验证损失是在每个epoch之后测量的。这告诉我们模型是否需要进一步调整,我们通常绘制验证损失的学习曲线。
4、训练和验证损失的影响
在大多数深度学习项目中,训练和验证损失通常可在图标上一起可视化。这样做的目的是诊断模型的性能并确定哪些方面需要调整。
4.1 欠拟合
图像说明训练损失和验证损失都很高:
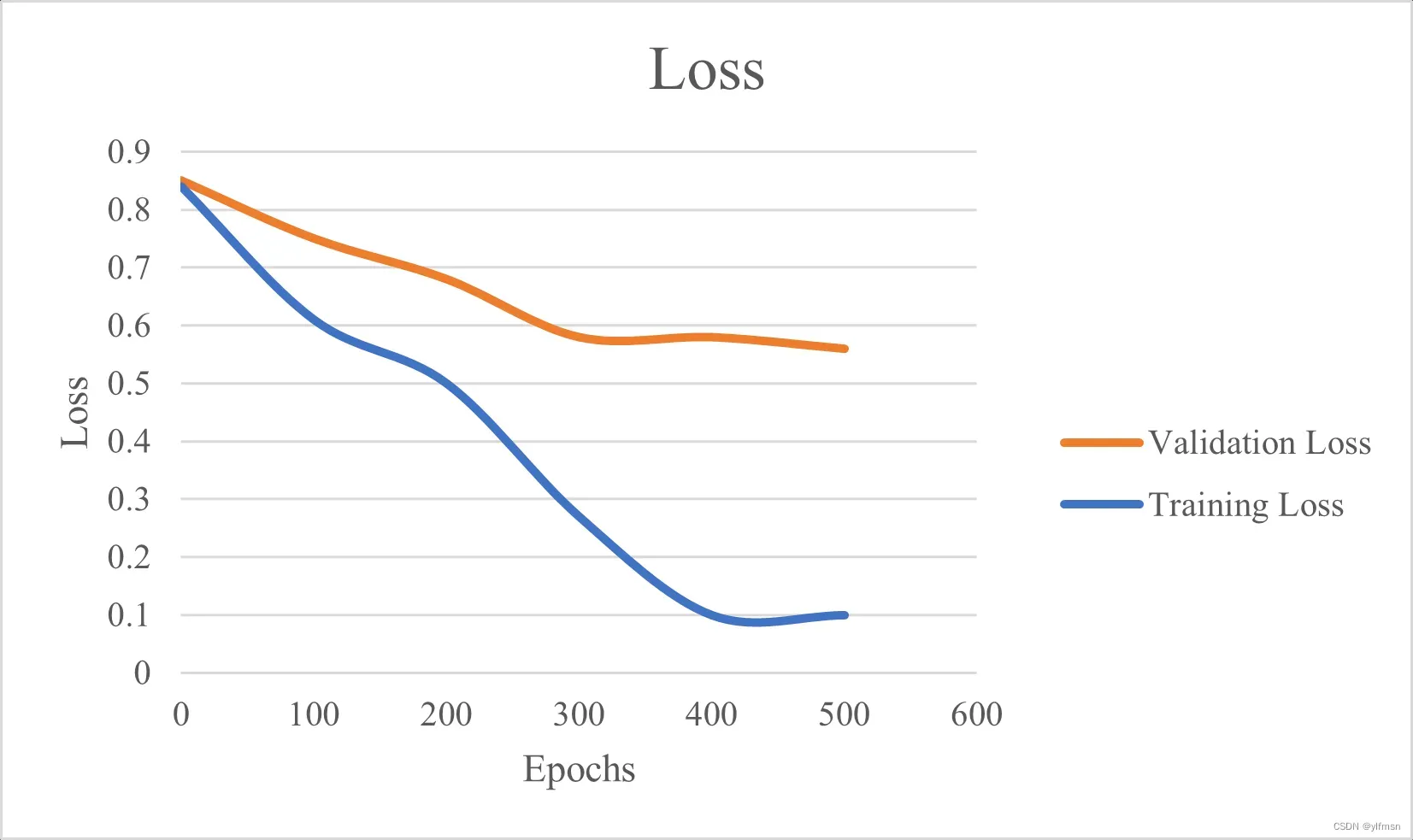
有时候,验证损失大于训练损失。这可能表明模型欠拟合。当模型无法准确地对训练数据建模时,就会发生欠拟合,从而产生较大地误差。
此外,欠拟合场景中的结果表明需要进一步训练以减少训练期间产生的损失。或者,也可以通过获取更多样本或扩充数据来增加训练数据。
4.2 过拟合
验证损失大于训练损失,如图所示:
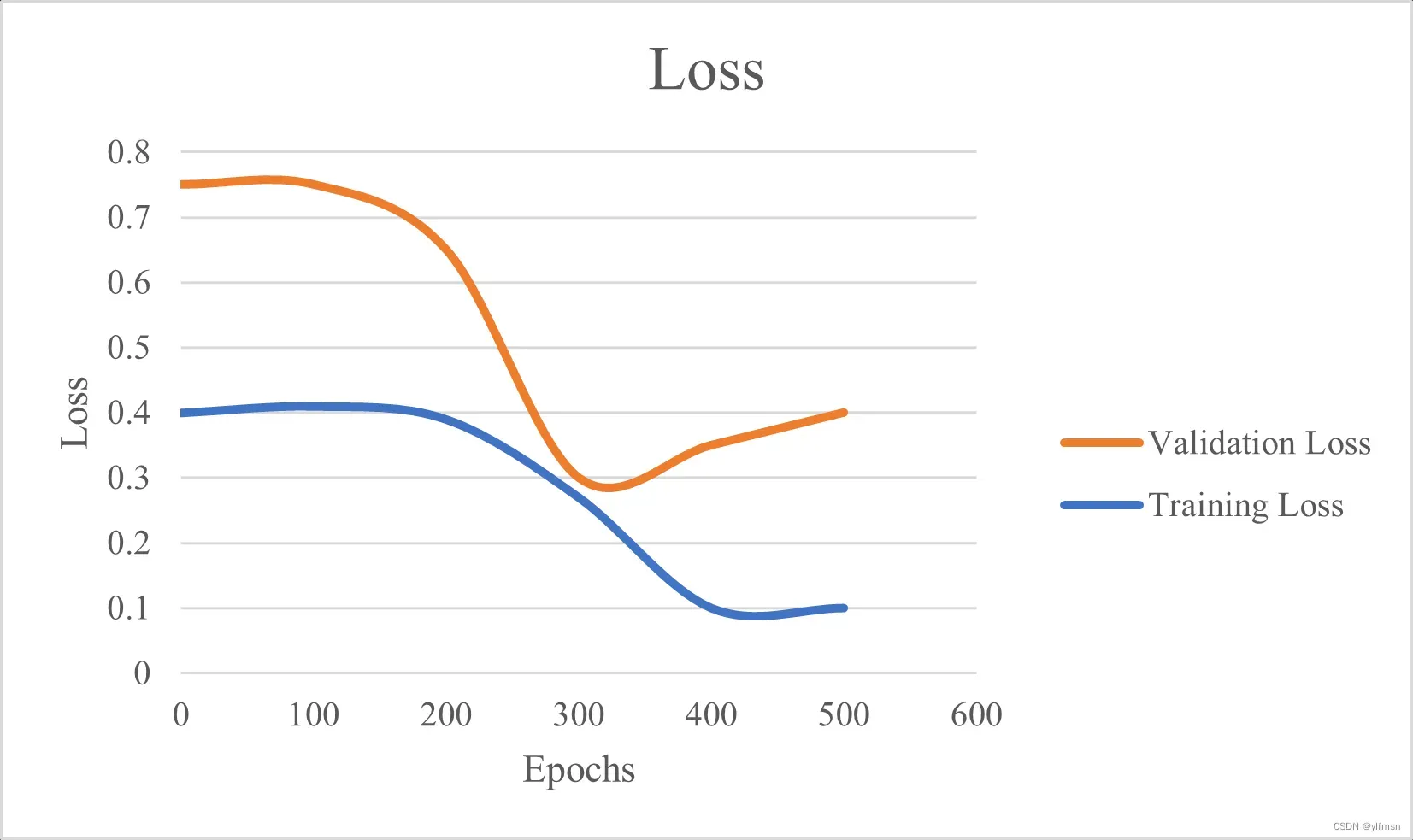
这通常表明模型过度拟合,无法对新数据进行泛化。特别是,该模型在训练数据上表现良好,但在验证集中的新数据上表现不佳。在某一时刻,验证损失减少但又开始增加。
发生这种情况的一个值得注意的原因是模型对于数据来说可能过于复杂,或者模型训练了很长时间。这种情况下,当损失很低且稳定时可以停止训练,这通常被称为提前停止。提前停止是用于防止过度拟合的众多方法之一。
4.3 拟合
下图中,训练损失和验证损失都在减少并稳定在特定点:
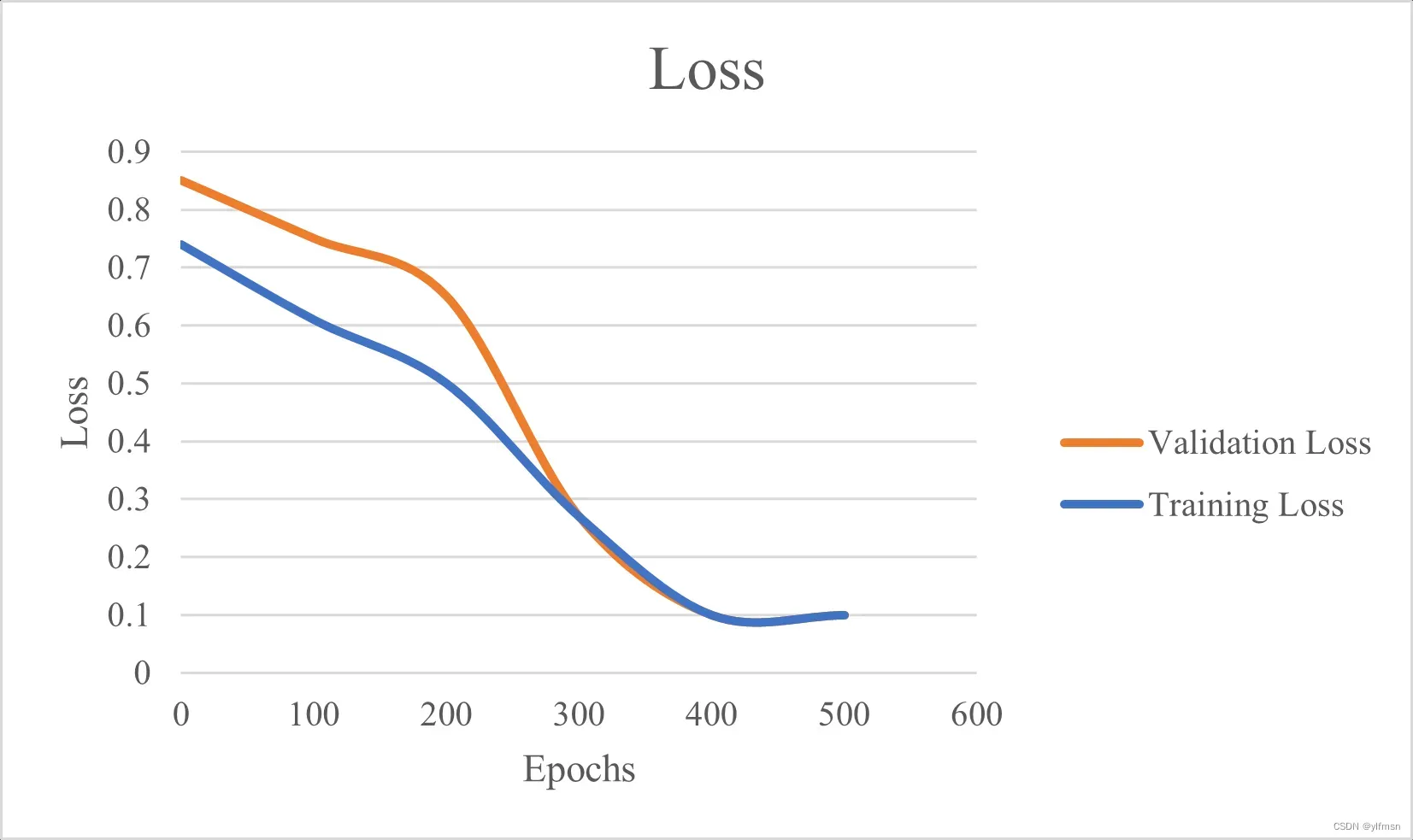
这表示最佳拟合,即不会过拟合或欠拟合的模型。
文章出处登录后可见!