最近阅读了一篇论文,介绍了一个语义分割中比较小众的研究方向——域自适应(Unsupervised Domain Adaptation,UDA)。小众并不意味着不重要,相反,语义分割中域自适应是一个很有意义的研究,尤其是在遥感图像处理领域。
文章为2018年CVPR中的一篇经典文章,较少了语义分割UDA几大研究领域中的一个方向——基于对抗学习的UDA。
论文地址:https://arxiv.org/abs/1802.10349
代码地址:https://github.com/wasidennis/AdaptSegNet
知识点
语义分割无监督域自适应简介
1)语义分割为什么需要无监督域自适应
在自然影像中,虽然近年来精度上取得了很大的进步,并且在实际应用中已经能够开始有所应用,但是这主要依赖于高质量的像素级的标注数据。然而这种标注是需要大量的人力和物力的。所以大家开始去探索怎么用更少的人力物力来得到一个与现有正常的语义分割同等的精度。之前的文章中也见过一个常见的想法,那就是弱监督语义分割。即用更容易获取的标签去完成语义分割。那么这里,又是另一个想法,用游戏中的合成数据来训练模型。在游戏中,我们基本不需要任何成本就能用电脑去获取游戏场景中的图片及其像素级标签。但是这种图片在分割上与真实场景的图片有着很大的差异(如图1),他们相当于两个域。如果直接用游戏场景(源域)训练的模型拿到真实场景(目标域)进行分割预测,性能会出现很大的下降。所以,无监督预适应的提出便是如何实现在一个域上训练的模型在另一个域上也能达到与源域的效果一致,从而使得我们可以以零成本训练分割模型。

在遥感影像中,因为不同地区的景观不一致,不同传感器、不同天气导致成像不一致,使得不同地区甚至同一地区不同时间、传感器形成的数据集的风格存在着很大的差异从而形成很多个域。而遥感图像是海量的,为每一个域标注像素级标签显然不现实。所以无监督域自适应的提出也可以使得在一个地区上(源域)训练的模型能够在其他地区(目标域)上使用。

2)无监督域自适应的定义
定义一系列相似的风格的图像集合Xs为源域。Xs有其对应的像素级标签Ys。存在另一个风格相似的图像集合Xt,定义它为目标域。Xt不存在任何标签。无监督域自适应(UDA)就是通过Xs,Xt,Yt来训练一个模型使得模型可以仅在Ys的监督之下,也能较好的在目标域上达到相近的性能。
3)无监督的自适应的几个研究方向
以下是根据所阅读的文献对无监督自适应的方法的大致分类:
1)基于对抗学习:这一类的方法出发点在于目标域与源域在同一Encoder后编码的特征能够尽量相似。主要在FCAN与ADVENT的基础上寻求突破与创新。
2)风格迁移:这一类的方法出发点在于转换源域图片的风格使得其与目标域相似。代表方法有CycleGAN。
3)自监督学习:在目标域上形成伪标签来训练模型。
摘要
基于卷积神经网络的语义分割方法依赖于像素级ground-truth标记,但可能对未知领域泛化效果并不好。由于标记过程繁琐且劳动密集,因此开发能够将源域的ground truth标记适配到目标域的算法非常有意义。本文我们提出了一种基于语义分割的领域适应性对抗学习方法。考虑语义分割是结构化的输出,包含源域和目标域的空间相似性,我们在输出空间中采用了对抗式学习。为了进一步增强适配模型,我们构建一个多层对抗网络,在不同特征级别上有效的执行输出空间域适配。一系列的实验和消融研究在不同域适配下进行,包括合成到真实和跨城市场景。我们表明提出的方法在精度和视觉质量方面,超过了现有的最先进的方法。
一、动机
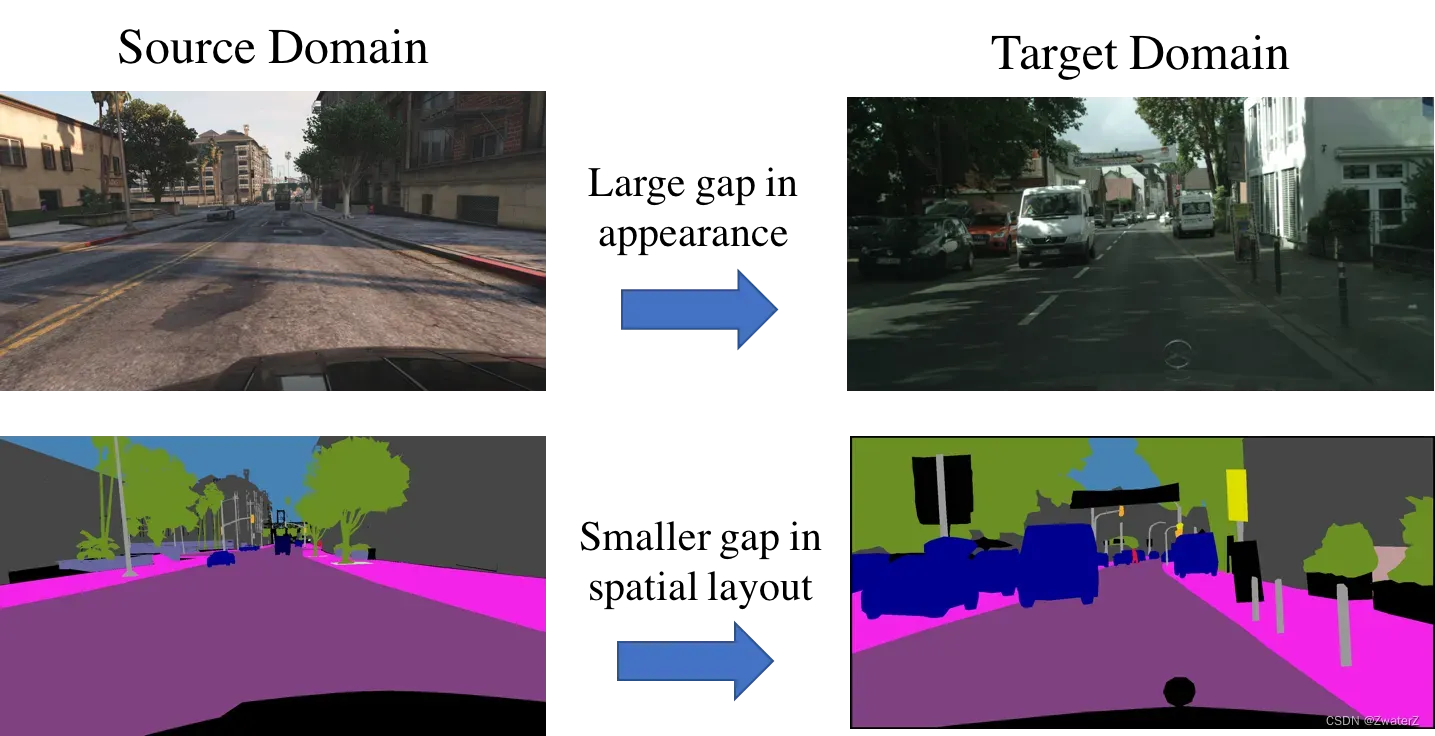
基于CNN方法的关键是注释大量可能包含场景变化的图像。然而,这种训练模型可能无法很好地泛化到没有见过的图像,尤其是当训练(源)图像和测试(目标)图像之间存在域间隙时。例如,不同城市的物体和场景的外观分布可能会有所不同,甚至同一城市的天气和照明条件也会发生显著变化。在这种情况下,仅依靠需要在不同场景中重新标注每像素的 ground truth 的监督模型将导致高昂的人工成本。
这篇 paper 在输出空间学习自适应的动机是:虽然图像在外观上可能非常不同,但是它们的输出是结构化的,并且有许多相似之处,例如空间布局和局部上下文,这促使作者提出一种适配像素级预测任务的有效方法,而不是使用特征适配。
二、 创新点
1)提出了一个领域自适应方法对于像素级的语义分割通过对抗学习;
2)证明了在输出(分割)空间进行适配可以有效地对齐源域和目标域图像的场景分布和局部上下文信息;
3)提出了一个多层对抗学习机制来以适应不同层次的细分模型,从而提升性能。
我们使用像素级预测是结构化输出的属性。这包含了空间和局部的信息,提出了有效的领域适应算法的对抗在输出空间中学习。
三、网络结构和训练
本篇论文是像素级别的域自适应,用了生成对抗网络的结构。网络结构包括语义分割网络G,域判别网络(鉴别器)Di,i表示多层次对抗性学习中鉴别器的层次。
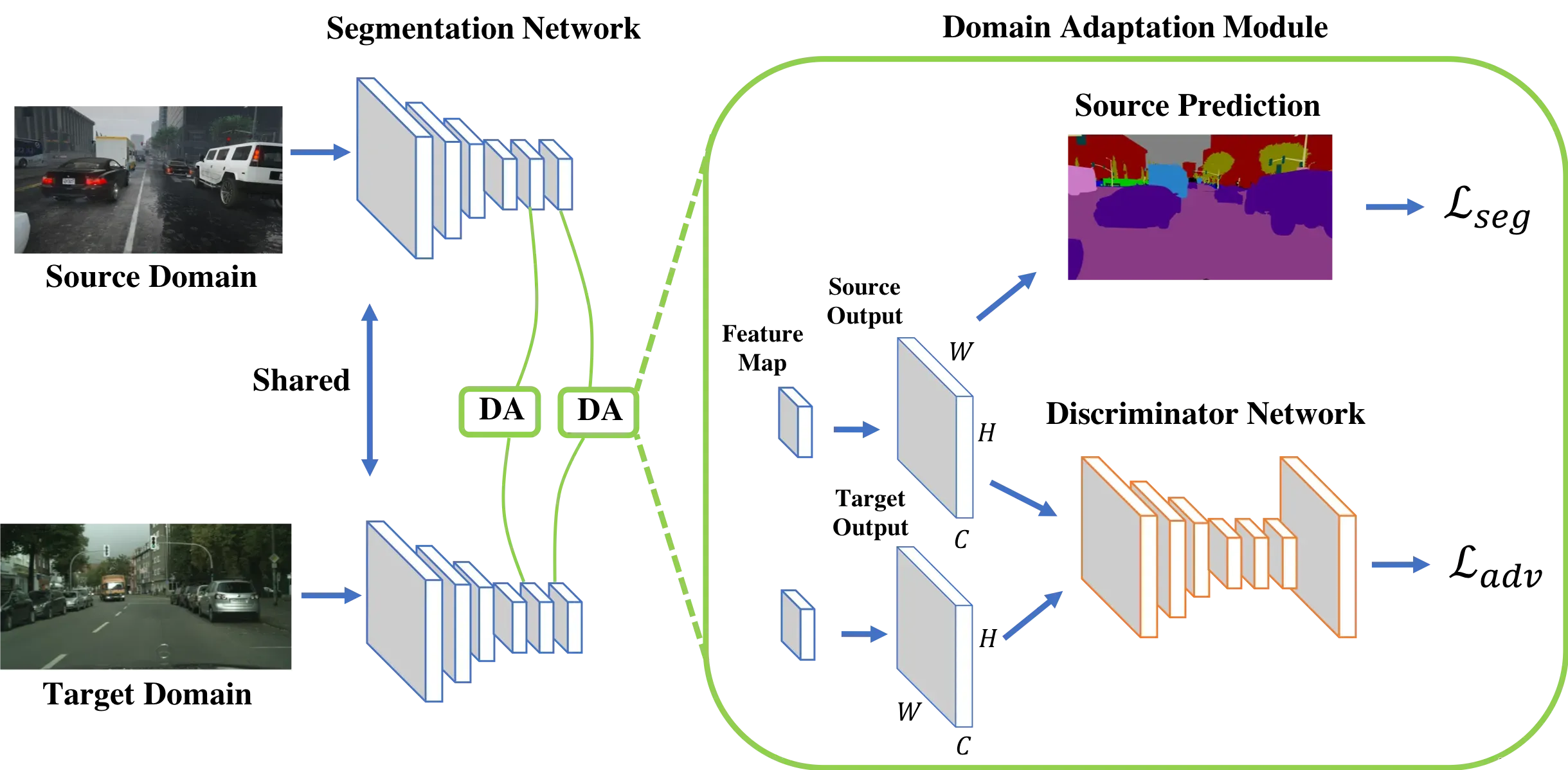
图中画了两个分割网络,但是也标注了参数共享,所以实际上就是一个网络。源域与目标域的图片输入进来之后分别形成两个特征图,然后经过卷积与上采样得到原图分辨率且通道数为类别数的Source output与Target output。
从正常的分割网络训练来看,我们直接用Source output与对应的ground truth就可以计算交叉熵损失函数Lseg从而训练好分割网络。但是这样的方式训练的模型往往在源域分割得很好而无法对目标域的图片进行正确的预测。所以,我们加入了一个判别器网络。
判别器网络以Source output与Target output为输入,并以两个完全相反的损失函数为优化目标。这两个优化目标组成了图中的Ladv。具体来说的话,第一个优化目标为:
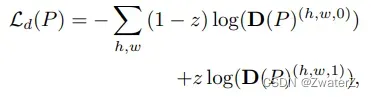
其中,z代表对目标域源域的标注,source output被标注为0,target output被标注为1。而D§代表着域判别器的输出, 其右上角的0和1分别代表着这个输出来自目标域还是源域。稍微分析一下这个损失函数就可以得出这个优化目标在于使得判别器能够判别出分割网络的输出是来自源域还是目标域。***需要注意的是,这个优化目标只优化判别器的参数,我们人为地将其梯度在传播到分割网络前截断。***这样让判别器专注于区分output来自目标域还是源域。另一个优化目标为:
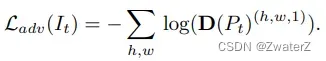
(1)Discriminator鉴别器
利用全卷积保留信息空间。该网络由5个卷积层组成,其中kernel为4*4,stride为2,通道数分别为(64,128,256,512,1)。除了最后一层,每个卷积层后面都有一个0.2参数化的leakyReLU。在最后一个卷积层上添加一个上采样层resize到和输入大小一样,以便将输出重新缩放到输入的大小。我们不使用任何 batch-normalization layers,因为我们联合训练鉴别器与分割网络使用 a small batch size。
(2)Segmentation Network分割网络
本文采用DeepLab-v2框架和在ImageNet上预训练的ResNet-101模型作为分割基础网络。但是,由于内存问题,我们没有使用多尺度融合策略。与最近的语义分割工作类似,我们删除了最后一个分类层,并将最后两个卷积层的步长从2修改为1,使得输出特征图的分辨率比输入图像的大小有效地提高了1/8倍。为了扩大接收域,我们分别在conv4和conv5层中使用了扩展卷积层,其步长分别为2和4。在最后一层之后,我们使用Atrous Spatial Pyramid Pooling (ASPP)作为最终的分类器。最后,我们应用一个上采样层和softmax输出来匹配输入图像的大小。
(3)Multi-level Adaptation Model多级别自适应模型
在此基础上,我们构造了上述的鉴别器和分割网络作为我们的单层自适应模型。对于多层结构,我们从conv4层中提取特征映射,并添加一个ASPP模块作为辅助分类器。类似地,为对抗学习添加了具有相同体系结构的鉴别器。下图中显示了提出的多级适应模型。在这篇文章中,作者使用两个层次来平衡它的效率和准确性。
(至此,多层级就是利用了conv4和conv5)
(4)训练过程
在一个阶段进行联合训练。首先,在每个训练批次中,我们首先对源图像进行促进,利用(3)中的Lseg优化分割网络,生成输出Ps。对于目标图像,我们得到分割输出Pt,并将其与Ps一起传递给鉴别器进行(2)中的Ld优化。此外,我们还计算了(4)中目标域预测值Pt的逆向损失Ladv。对于(5)中的多级训练目标,我们只是对每个自适应模块重复相同的过程。
剩余的是训练的时候参数的介绍。
本文发现联合训练分割网络和判别器是有效的。在每一个训练batch中,首先前向传播这个原图片I_s优化分割网络得到L_seg和产生输出P_s,对于目标图片I_t,获得分割输出I_t。把它和P_s一起传递到判别器中优化L_d,还要计算对抗损失L_adv对于多级预测,仅仅是重复一样的过程对于每一个自适应模块。
训练分割网络,使用SGD,Nesterov加速,momentum是0.9,weight decay是10e-4,初始化学习率是2.5 x 10e-4,使用poly学习率减少,power=0.9。训练判别器,使用Adam优化器,学习率为10e-4和分割网络一样的学习率下降方式,momentum设置为0.9和0.99。
lamda_adv=0.001,所提出的适应方法。输出空间的性能优于特征中的。适应在特征空间对λ_adv更敏感,导致训练过程更困难,而输出空间适应允许更广泛的范围。其中一个原因是由于在高维空间中进行了特征适应,因此鉴别器的问题变得更加容易。因此,这种适应性模型不能通过对抗性学习有效地匹配源域和目标域之间的分布。由于低水平的输出携带较少的信息来预测分割,所以我们在分割和对抗性损失中使用更小的权重。λ_seg_2= 0.1和λ_adv_2= 0.0002,λ_seg_1= 1和λ_adv_2= 0.001)。评价结果表明,我们的多层次对抗性适应进一步提高了分割的准确性。
四、算法概述
给定源域和目标域中大小 H ∗ W 的图像,通过分割网络获得输出预测。对于 C 类的源域预测,基于源域 ground truth 计算分割损失。为了使目标域预测更接近于源域预测,使用判别器来区分输入来自源域还是目标域。然后在目标预测上计算对抗损失,并将其反向传播到分割网络。此过程被称为一个自适应模块,并在这里通过采用两个不同层次的自适应模块来说明我们提出的多层对抗学习。( 流程:(a)首先将带标注的源域图像Is输入到分割网络中,对分割网络 G进行优化;(b)然后对无标注的目标域图像 It预测分割 softmax 输出 Pt ;(c)因为我们的目标是使源域和目标域的分割预测(Ps和Pt)彼此相近,所以我们 将这两个预测作为判别器 Di 的输入来区分输入是来自于源域还是目标域。对目标预测做对抗损失,网络从 Di 向 G传播梯度,这将促使 G在目标域中生成和源域预测相似的分割分布。)
目标函数
优化目标为:
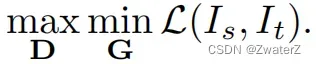
最终的目的是最小化源域图像在 G中的分割损失,同时最大化目标域预测看作源域预测的概率。
网络训练优化
单层对抗学习:
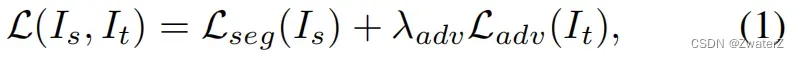
其中,Lseg是在源域中使用 ground truth 标注的交叉熵损失,而 Ladv是使目标域图像的预测分割适配于源域预测分布的对抗损失。在公式(1)中,λadv用于平衡这两个损失的权重。
(a)判别器训练:
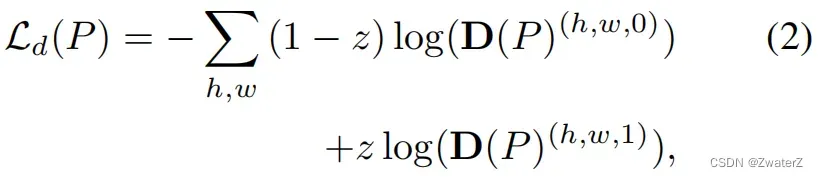
其中,z = 0表示样本来自于目标域,z = 1表示样本来自于源域。
(b)分割网络训练:首先定义公式(1)中的分割损失,
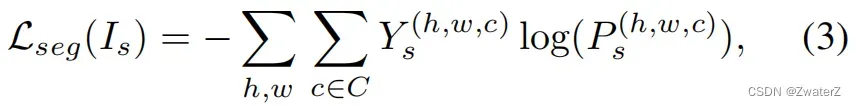
其中,Ys是源域图像的 ground truth 标注,Ps = G ( Is )是分割输出。然后,对目标域图像进行分割预测 Pt = G ( It )。为了使 Ps和Pt的分布更加接近,在公式(1)中用一个对抗损失 Ladv
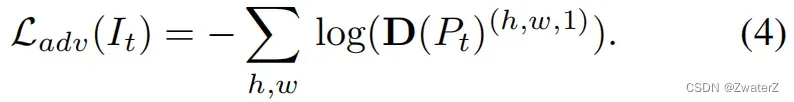
该损失函数用来训练分割网络,并且通过最大化目标域预测看作源域预测的概率来骗过判别器。
多层对抗学习:分割网络的训练目标函数可以改写为下式
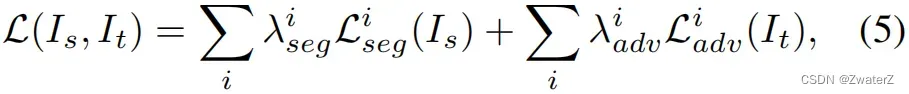
其中 i 表示用于预测分割输出的层。我们注意到,在通过用于对抗学习的单个判别器之前,分割输出仍然是在每个特征空间中预测的。因此,L^{i}{seg}(I_s)和 L^{i}{adv}(I_t)分别保持与公式(3)和(4)相同的形式。
优化过程:为了训练提出的单/多层自适应模型,我们发现在一个阶段中联合训练分割网络和判别器是有效的。在每个训练 batch 中,首先输入源域图像 Is为公式(3)中的 Lseg优化分割网络 G GG 并生成输出 Ps。然后得到目标域图像 It的分割输出 Pt,并将其与 Ps一同输入到判别器中来优化公式(2)中的 Ld。此外,对目标预测 Pt计算公式(4)中的对抗损失 Ladv 。对于公式 (5) 中的多层训练目标,我们只是对每个自适应模块简单地重复相同的步骤。
五、实验结果
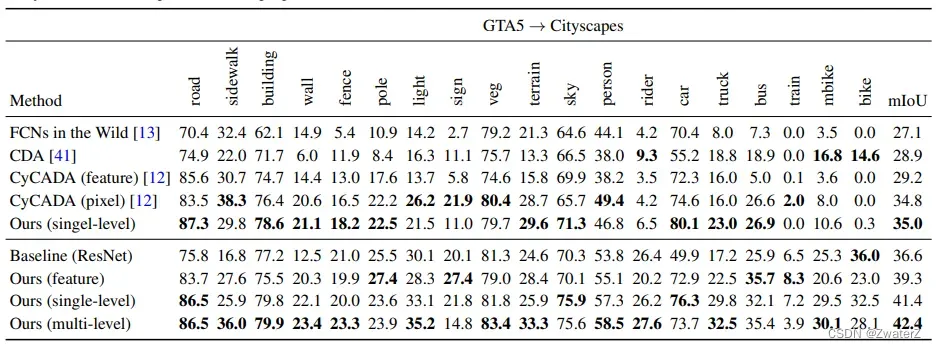
上图是从GTA5到Cityspaces这个任务的实验结果。我们可以看到,第一条数据Baseline(Resnet)在源域上训练一个模型,然后拿到目标域上去测试。第二条数据是在特征维度上做出来一个结果,39.3。虽然相比于source only的模型有所提升,但是和下面两个在output space上做的对抗是相对较低的。第一个single level,是直接在Resnet最后一层提取出了特征,然后输入到分类器产生得到的结果;第二个multi-level是在Resnet倒数一二层都做对抗,结果可以看到,是会更好。
论文复现
1、代码:
代码是开源的,下载地址我在文章开头也附上了。
网络上关于论文的有很多笔记,先阅读内容,配合代码学习。代码基本上不用改,但是还是有一定难度,我反正第一次看是没太看懂,还是需要再啃一啃,如果只是复现的话走一遍就可以了。
2、数据集:
根据readme里面的链接下载了GTA5以及cityscapes数据集
1、GTAV数据集
可点此链接 ,下载Images和Labels,如下图所示:
 并将下载好的文件,按照如下的方式其构建目录:
并将下载好的文件,按照如下的方式其构建目录:
dataset
|- GTA5
|- images
|- ...
|- labels
|- ...
2、Cityscape数据集
可点此链接 下载gtFine_trainvaltest.zip 和 leftImg8bit_trainvaltest.zip 两个文件。
并将下载好的文件,按照如下的方式其构建目录:
|- Cityscapes
|- data
|- gtFine
|- test
|- train
|- val
|- leftImg8bit
|- test
|- train
|- val
注意:数据集真的很大,一定要留足空间
3、训练。
放好数据集就可以进行训练~因为要训练好几天,训练指令参照源代码的readme文件。
4、测试
主要参照readme文件
python evaluate_cityscapes.py --restore-from ./snapshots/GTA2Cityscapes_multi/GTA5_150000.pth
测试预训练模型:
python evaluate_cityscapes.py --restore-from ./model/GTA2Cityscapes_multi-ed35151c.pth

我自己的效果还在跑了,已经跑了三天了,我比它还累TOT
5、计算miou
python compute_iou.py 参数1 参数2
参数1是cityscape的gtfine文件的地址
参数2是/result/cityscapes/
文章出处登录后可见!