实现【卷积-池化-激活】代码,并分析总结
For循环版本:手工实现
代码如下:
import numpy as np
x = np.array([[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]])
print("x=\n", x)
# 初始化 三个 卷积核
Kernel = [[0 for i in range(0, 3)] for j in range(0, 3)]
Kernel[0] = np.array([[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]])
Kernel[1] = np.array([[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]])
Kernel[2] = np.array([[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]])
# --------------- 卷积 ---------------
stride = 1 # 步长
feature_map_h = 7 # 特征图的高
feature_map_w = 7 # 特征图的宽
feature_map = [0 for i in range(0, 3)] # 初始化3个特征图
for i in range(0, 3):
feature_map[i] = np.zeros((feature_map_h, feature_map_w)) # 初始化特征图
for h in range(feature_map_h): # 向下滑动,得到卷积后的固定行
for w in range(feature_map_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * stride # 滑动窗口的起始行(高)
v_end = v_start + 3 # 滑动窗口的结束行(高)
h_start = w * stride # 滑动窗口的起始列(宽)
h_end = h_start + 3 # 滑动窗口的结束列(宽)
window = x[v_start:v_end, h_start:h_end] # 从图切出一个滑动窗口
for i in range(0, 3):
feature_map[i][h, w] = np.divide(np.sum(np.multiply(window, Kernel[i][:, :])), 9)
print("feature_map:\n", np.around(feature_map, decimals=2))
# --------------- 池化 ---------------
pooling_stride = 2 # 步长
pooling_h = 4 # 特征图的高
pooling_w = 4 # 特征图的宽
feature_map_pad_0 = [[0 for i in range(0, 8)] for j in range(0, 8)]
for i in range(0, 3): # 特征图 补 0 ,行 列 都要加 1 (因为上一层是奇数,池化窗口用的偶数)
feature_map_pad_0[i] = np.pad(feature_map[i], ((0, 1), (0, 1)), 'constant', constant_values=(0, 0))
# print("feature_map_pad_0 0:\n", np.around(feature_map_pad_0[0], decimals=2))
pooling = [0 for i in range(0, 3)]
for i in range(0, 3):
pooling[i] = np.zeros((pooling_h, pooling_w)) # 初始化特征图
for h in range(pooling_h): # 向下滑动,得到卷积后的固定行
for w in range(pooling_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * pooling_stride # 滑动窗口的起始行(高)
v_end = v_start + 2 # 滑动窗口的结束行(高)
h_start = w * pooling_stride # 滑动窗口的起始列(宽)
h_end = h_start + 2 # 滑动窗口的结束列(宽)
for i in range(0, 3):
pooling[i][h, w] = np.max(feature_map_pad_0[i][v_start:v_end, h_start:h_end])
print("pooling:\n", np.around(pooling[0], decimals=2))
print("pooling:\n", np.around(pooling[1], decimals=2))
print("pooling:\n", np.around(pooling[2], decimals=2))
# --------------- 激活 ---------------
def relu(x):
return (abs(x) + x) / 2
relu_map_h = 7 # 特征图的高
relu_map_w = 7 # 特征图的宽
relu_map = [0 for i in range(0, 3)] # 初始化3个特征图
for i in range(0, 3):
relu_map[i] = np.zeros((relu_map_h, relu_map_w)) # 初始化特征图
for i in range(0, 3):
relu_map[i] = relu(feature_map[i])
print("relu map :\n", np.around(relu_map[0], decimals=2))
print("relu map :\n", np.around(relu_map[1], decimals=2))
print("relu map :\n", np.around(relu_map[2], decimals=2))
运行结果如下:
x=
[[-1 -1 -1 -1 -1 -1 -1 -1 -1]
[-1 1 -1 -1 -1 -1 -1 1 -1]
[-1 -1 1 -1 -1 -1 1 -1 -1]
[-1 -1 -1 1 -1 1 -1 -1 -1]
[-1 -1 -1 -1 1 -1 -1 -1 -1]
[-1 -1 -1 1 -1 1 -1 -1 -1]
[-1 -1 1 -1 -1 -1 1 -1 -1]
[-1 1 -1 -1 -1 -1 -1 1 -1]
[-1 -1 -1 -1 -1 -1 -1 -1 -1]]
feature_map:
[[[ 0.78 -0.11 0.11 0.33 0.56 -0.11 0.33]
[-0.11 1. -0.11 0.33 -0.11 0.11 -0.11]
[ 0.11 -0.11 1. -0.33 0.11 -0.11 0.56]
[ 0.33 0.33 -0.33 0.56 -0.33 0.33 0.33]
[ 0.56 -0.11 0.11 -0.33 1. -0.11 0.11]
[-0.11 0.11 -0.11 0.33 -0.11 1. -0.11]
[ 0.33 -0.11 0.56 0.33 0.11 -0.11 0.78]]
[[ 0.33 -0.56 0.11 -0.11 0.11 -0.56 0.33]
[-0.56 0.56 -0.56 0.33 -0.56 0.56 -0.56]
[ 0.11 -0.56 0.56 -0.78 0.56 -0.56 0.11]
[-0.11 0.33 -0.78 1. -0.78 0.33 -0.11]
[ 0.11 -0.56 0.56 -0.78 0.56 -0.56 0.11]
[-0.56 0.56 -0.56 0.33 -0.56 0.56 -0.56]
[ 0.33 -0.56 0.11 -0.11 0.11 -0.56 0.33]]
[[ 0.33 -0.11 0.56 0.33 0.11 -0.11 0.78]
[-0.11 0.11 -0.11 0.33 -0.11 1. -0.11]
[ 0.56 -0.11 0.11 -0.33 1. -0.11 0.11]
[ 0.33 0.33 -0.33 0.56 -0.33 0.33 0.33]
[ 0.11 -0.11 1. -0.33 0.11 -0.11 0.56]
[-0.11 1. -0.11 0.33 -0.11 0.11 -0.11]
[ 0.78 -0.11 0.11 0.33 0.56 -0.11 0.33]]]
pooling:
[[1. 0.33 0.56 0.33]
[0.33 1. 0.33 0.56]
[0.56 0.33 1. 0.11]
[0.33 0.56 0.11 0.78]]
pooling:
[[0.56 0.33 0.56 0.33]
[0.33 1. 0.56 0.11]
[0.56 0.56 0.56 0.11]
[0.33 0.11 0.11 0.33]]
pooling:
[[0.33 0.56 1. 0.78]
[0.56 0.56 1. 0.33]
[1. 1. 0.11 0.56]
[0.78 0.33 0.56 0.33]]
relu map :
[[0.78 0. 0.11 0.33 0.56 0. 0.33]
[0. 1. 0. 0.33 0. 0.11 0. ]
[0.11 0. 1. 0. 0.11 0. 0.56]
[0.33 0.33 0. 0.56 0. 0.33 0.33]
[0.56 0. 0.11 0. 1. 0. 0.11]
[0. 0.11 0. 0.33 0. 1. 0. ]
[0.33 0. 0.56 0.33 0.11 0. 0.78]]
relu map :
[[0.33 0. 0.11 0. 0.11 0. 0.33]
[0. 0.56 0. 0.33 0. 0.56 0. ]
[0.11 0. 0.56 0. 0.56 0. 0.11]
[0. 0.33 0. 1. 0. 0.33 0. ]
[0.11 0. 0.56 0. 0.56 0. 0.11]
[0. 0.56 0. 0.33 0. 0.56 0. ]
[0.33 0. 0.11 0. 0.11 0. 0.33]]
relu map :
[[0.33 0. 0.56 0.33 0.11 0. 0.78]
[0. 0.11 0. 0.33 0. 1. 0. ]
[0.56 0. 0.11 0. 1. 0. 0.11]
[0.33 0.33 0. 0.56 0. 0.33 0.33]
[0.11 0. 1. 0. 0.11 0. 0.56]
[0. 1. 0. 0.33 0. 0.11 0. ]
[0.78 0. 0.11 0.33 0.56 0. 0.33]]
手工实现这边其实还是蛮清晰的。
①一开始给了一个9×9的矩阵作为被卷积的图像,给了三个3×3的卷积核分别对该图像进行卷积,步长为1,得到三个7×7的卷积后图像(9+1-3=7),输出这三个。
还有一点就是这里卷积用的是sum()去处理,也就是说在这里并没有除以3×3=9,所以自这之后后面每一次输出都除了9.
②再对这三个矩阵进行池化,因为池化是2×2,所以要对曾经的7×7矩阵进行填充,使其变成8×8的矩阵,这样就可以顺利的进行池化,使用max()对数据处理,再生成三个池化后的矩阵,输出。
③激活是对卷积后的矩阵激活的,使用的是relu函数(小于0的全部按0处理),所以池化后得到的那个矩阵里的所有负数就被0取代,最后得到了一个处理后的矩阵(7×7)。
每一步中都是套了两个循环,从上到下从左向右截取矩阵的,再加一个循环在新的矩阵中添加数据,在代码中的注释里说的很清楚。
for h in range(feature_map_h): # 向下滑动,得到卷积后的固定行
for w in range(feature_map_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * stride # 滑动窗口的起始行(高)
v_end = v_start + 3 # 滑动窗口的结束行(高)
h_start = w * stride # 滑动窗口的起始列(宽)
h_end = h_start + 3 # 滑动窗口的结束列(宽)
window = x[v_start:v_end, h_start:h_end] # 从图切出一个滑动窗口
for i in range(0, 3):
feature_map[i][h, w] = np.divide(np.sum(np.multiply(window, Kernel[i][:, :])), 9)
(不过池化部分的注释也说成了卷积,按说池化≠卷积,可能只是复制过来之后没改…)
Pytorch版本:调用函数完成
代码如下:
# https://blog.csdn.net/qq_26369907/article/details/88366147
# https://zhuanlan.zhihu.com/p/405242579
import numpy as np
import torch
import torch.nn as nn
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape)
print(x)
print("--------------- 卷积 ---------------")
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
conv2 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv2.weight.data = torch.Tensor([[[[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]]
]])
conv3 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv3.weight.data = torch.Tensor([[[[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]]
]])
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9)
print(feature_map2 / 9)
print(feature_map3 / 9)
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size())
print(feature_pool_1 / 9)
print(feature_pool_2 / 9)
print(feature_pool_3 / 9)
print("--------------- 激活 ---------------")
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9)
print(feature_relu2 / 9)
print(feature_relu3 / 9)
torch.Size([1, 1, 9, 9])
tensor([[[[-1., -1., -1., -1., -1., -1., -1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., -1., -1., 1., -1., -1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., -1., -1., -1., -1., -1., -1., -1.]]]])
--------------- 卷积 ---------------
tensor([[[[ 0.7606, -0.1283, 0.0939, 0.3161, 0.5384, -0.1283, 0.3161],
[-0.1283, 0.9828, -0.1283, 0.3161, -0.1283, 0.0939, -0.1283],
[ 0.0939, -0.1283, 0.9828, -0.3505, 0.0939, -0.1283, 0.5384],
[ 0.3161, 0.3161, -0.3505, 0.5384, -0.3505, 0.3161, 0.3161],
[ 0.5384, -0.1283, 0.0939, -0.3505, 0.9828, -0.1283, 0.0939],
[-0.1283, 0.0939, -0.1283, 0.3161, -0.1283, 0.9828, -0.1283],
[ 0.3161, -0.1283, 0.5384, 0.3161, 0.0939, -0.1283, 0.7606]]]],
grad_fn=<DivBackward0>)
tensor([[[[ 0.3295, -0.5594, 0.1073, -0.1150, 0.1073, -0.5594, 0.3295],
[-0.5594, 0.5517, -0.5594, 0.3295, -0.5594, 0.5517, -0.5594],
[ 0.1073, -0.5594, 0.5517, -0.7816, 0.5517, -0.5594, 0.1073],
[-0.1150, 0.3295, -0.7816, 0.9962, -0.7816, 0.3295, -0.1150],
[ 0.1073, -0.5594, 0.5517, -0.7816, 0.5517, -0.5594, 0.1073],
[-0.5594, 0.5517, -0.5594, 0.3295, -0.5594, 0.5517, -0.5594],
[ 0.3295, -0.5594, 0.1073, -0.1150, 0.1073, -0.5594, 0.3295]]]],
grad_fn=<DivBackward0>)
tensor([[[[ 0.3483, -0.0961, 0.5705, 0.3483, 0.1261, -0.0961, 0.7928],
[-0.0961, 0.1261, -0.0961, 0.3483, -0.0961, 1.0150, -0.0961],
[ 0.5705, -0.0961, 0.1261, -0.3183, 1.0150, -0.0961, 0.1261],
[ 0.3483, 0.3483, -0.3183, 0.5705, -0.3183, 0.3483, 0.3483],
[ 0.1261, -0.0961, 1.0150, -0.3183, 0.1261, -0.0961, 0.5705],
[-0.0961, 1.0150, -0.0961, 0.3483, -0.0961, 0.1261, -0.0961],
[ 0.7928, -0.0961, 0.1261, 0.3483, 0.5705, -0.0961, 0.3483]]]],
grad_fn=<DivBackward0>)
--------------- 池化 ---------------
torch.Size([1, 1, 4, 4])
tensor([[[[0.9828, 0.3161, 0.5384, 0.3161],
[0.3161, 0.9828, 0.3161, 0.5384],
[0.5384, 0.3161, 0.9828, 0.0939],
[0.3161, 0.5384, 0.0939, 0.7606]]]], grad_fn=<DivBackward0>)
tensor([[[[0.5517, 0.3295, 0.5517, 0.3295],
[0.3295, 0.9962, 0.5517, 0.1073],
[0.5517, 0.5517, 0.5517, 0.1073],
[0.3295, 0.1073, 0.1073, 0.3295]]]], grad_fn=<DivBackward0>)
tensor([[[[0.3483, 0.5705, 1.0150, 0.7928],
[0.5705, 0.5705, 1.0150, 0.3483],
[1.0150, 1.0150, 0.1261, 0.5705],
[0.7928, 0.3483, 0.5705, 0.3483]]]], grad_fn=<DivBackward0>)
--------------- 激活 ---------------
tensor([[[[0.7606, 0.0000, 0.0939, 0.3161, 0.5384, 0.0000, 0.3161],
[0.0000, 0.9828, 0.0000, 0.3161, 0.0000, 0.0939, 0.0000],
[0.0939, 0.0000, 0.9828, 0.0000, 0.0939, 0.0000, 0.5384],
[0.3161, 0.3161, 0.0000, 0.5384, 0.0000, 0.3161, 0.3161],
[0.5384, 0.0000, 0.0939, 0.0000, 0.9828, 0.0000, 0.0939],
[0.0000, 0.0939, 0.0000, 0.3161, 0.0000, 0.9828, 0.0000],
[0.3161, 0.0000, 0.5384, 0.3161, 0.0939, 0.0000, 0.7606]]]],
grad_fn=<DivBackward0>)
tensor([[[[0.3295, 0.0000, 0.1073, 0.0000, 0.1073, 0.0000, 0.3295],
[0.0000, 0.5517, 0.0000, 0.3295, 0.0000, 0.5517, 0.0000],
[0.1073, 0.0000, 0.5517, 0.0000, 0.5517, 0.0000, 0.1073],
[0.0000, 0.3295, 0.0000, 0.9962, 0.0000, 0.3295, 0.0000],
[0.1073, 0.0000, 0.5517, 0.0000, 0.5517, 0.0000, 0.1073],
[0.0000, 0.5517, 0.0000, 0.3295, 0.0000, 0.5517, 0.0000],
[0.3295, 0.0000, 0.1073, 0.0000, 0.1073, 0.0000, 0.3295]]]],
grad_fn=<DivBackward0>)
tensor([[[[0.3483, 0.0000, 0.5705, 0.3483, 0.1261, 0.0000, 0.7928],
[0.0000, 0.1261, 0.0000, 0.3483, 0.0000, 1.0150, 0.0000],
[0.5705, 0.0000, 0.1261, 0.0000, 1.0150, 0.0000, 0.1261],
[0.3483, 0.3483, 0.0000, 0.5705, 0.0000, 0.3483, 0.3483],
[0.1261, 0.0000, 1.0150, 0.0000, 0.1261, 0.0000, 0.5705],
[0.0000, 1.0150, 0.0000, 0.3483, 0.0000, 0.1261, 0.0000],
[0.7928, 0.0000, 0.1261, 0.3483, 0.5705, 0.0000, 0.3483]]]],
grad_fn=<DivBackward0>)
卷积
好吧显然……逃不过Conv2d这个东西了,在这里学了一下,简略版如下:
nn.Conv2d(in_channel , out_channel , kennel_size , stride ,padding)
in_channel :输入张量的channels数,其实在卷积这里应该就是通道
out_channel : 期望的四维输出张量的channels数
kennel_size :卷积核的大小
stride :步长
padding :图像填充,不写默认为0
conv1 = nn.Conv2d(1, 1, (3, 3), 1)
就是输入1个矩阵,过程是用3×3(其实上面可以直接写成3,试过了可行 )的卷积核、步长为1进行卷积,最后输出1个矩阵。
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
↑↑↑添加卷积核
feature_map1 = conv1(x)
↑↑↑将x进行卷积,卷积之后的图像放入feature_map1中。
怎么说呢,卷积就是省了那个循环套循环,自己截取卷积范围的过程,全部交给了函数自己实现。
池化
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
第一行是创建最大池化(size,padding,stride),第二行是创建填充(Left,Right,Up,Down)
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
使用时先填充再池化,输出给到feature_pool_1就完成了池化。我愿称为一键池化
激活
激活用的依然是卷积后的矩阵feature_map,调用了nn.ReLU()实现
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
可视化:了解数字与图像之间的关系
# https://blog.csdn.net/qq_26369907/article/details/88366147
# https://zhuanlan.zhihu.com/p/405242579
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容
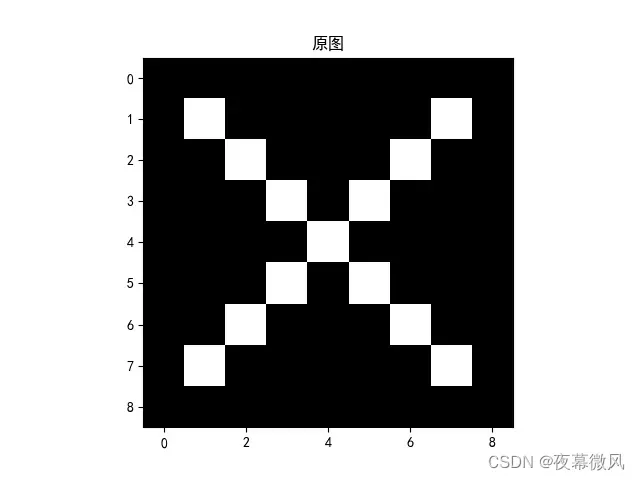
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape)
print(x)
img = x.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('原图')
plt.show()
print("--------------- 卷积 ---------------")
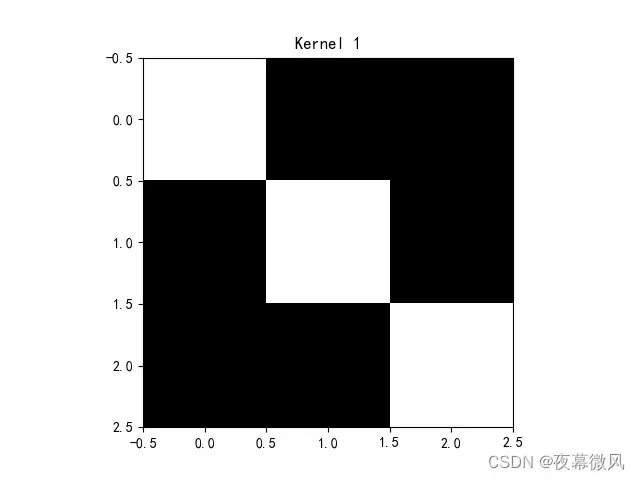
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
img = conv1.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 1')
plt.show()
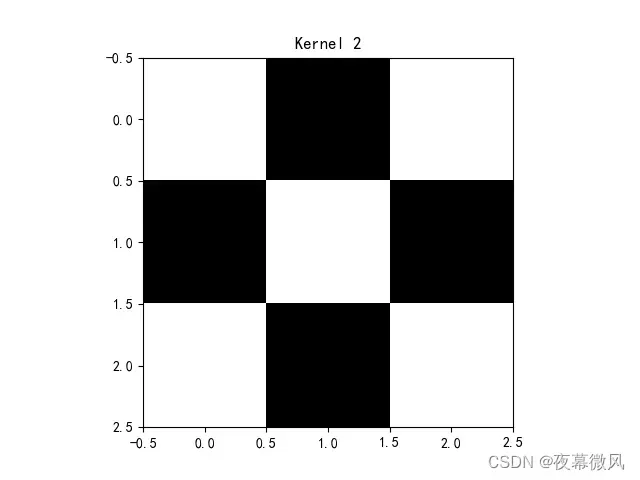
conv2 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv2.weight.data = torch.Tensor([[[[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]]
]])
img = conv2.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 2')
plt.show()
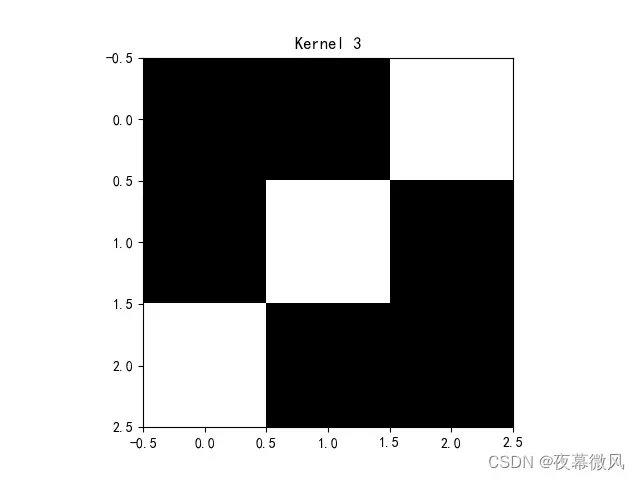
conv3 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv3.weight.data = torch.Tensor([[[[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]]
]])
img = conv3.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 3')
plt.show()
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9)
print(feature_map2 / 9)
print(feature_map3 / 9)
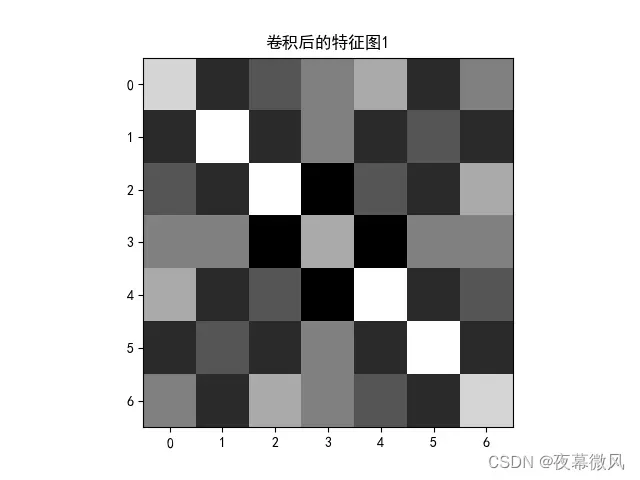
img = feature_map1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积后的特征图1')
plt.show()
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size())
print(feature_pool_1 / 9)
print(feature_pool_2 / 9)
print(feature_pool_3 / 9)
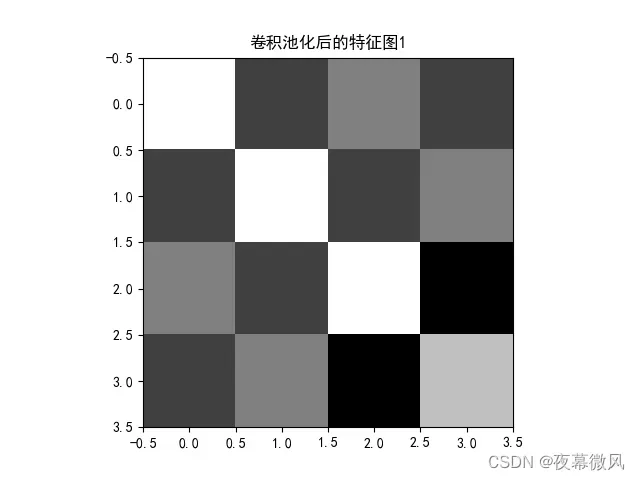
img = feature_pool_1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积池化后的特征图1')
plt.show()
print("--------------- 激活 ---------------")
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9)
print(feature_relu2 / 9)
print(feature_relu3 / 9)
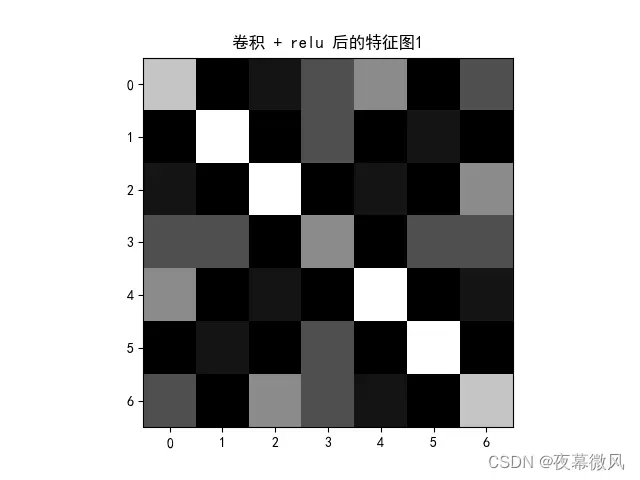
img = feature_relu1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积 + relu 后的特征图1')
plt.show()
运行效果如下:
原图
卷积核
特征图
总结
总结就是,直接用包装好的函数确实方便很多!!暂时还没发现在自由度上的缺陷,可能研究深入了就会有局限吧。
参考资料
【2021-2022 春学期】人工智能-作业5:卷积-池化-激活_HBU_David的博客-CSDN博客
Pytorch的nn.Conv2d()详解_风雪夜归人o的博客-CSDN博客_nn是什么意思
文章出处登录后可见!