目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的全景图像拼接系统
课题背景和意义
随着全景摄影技术的日益普及,全景图像拼接技术在虚拟现实、无人驾驶、智能监控等领域的应用越来越广泛。基于深度学习的全景图像拼接系统旨在通过深度学习技术实现全景图像的自动、高效拼接,克服传统方法中的对齐不准确、拼接痕迹明显等问题。这一课题的研究不仅有助于提升全景图像拼接的技术水平,还将推动相关领域的发展和应用。
实现技术思路
一、算法理论技术
1.1 神经网络
卷积神经网络(CNN)相较于全连接神经网络,在结构和性能上有了显著优化。它通过引入卷积和池化操作,不仅减少了参数数量,提升了训练效率,还能更好地保留特征的空间位置信息。这使得CNN在图像处理和计算机视觉任务中表现出色,能够高效地进行特征提取、分类和分割等操作,成为现代深度学习领域的重要基石。
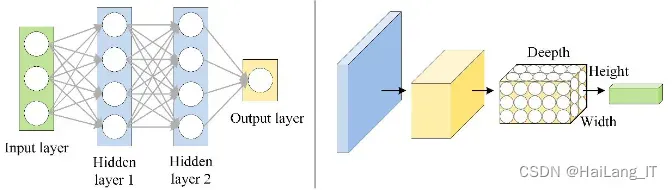
卷积神经网络通过卷积层的局部感受野和权值共享特点,有效减少了连接和权重数量,提升了训练效率,并赋予了网络平移不变性。多核卷积则进一步增强了模型的表达能力。同时,池化层通过压缩图像、提取重要特征信息,去除了冗余,降低了计算负担,其中Max pooling因其广泛适用性而尤为常用。这些设计共同使得卷积神经网络在图像处理任务中表现出色。
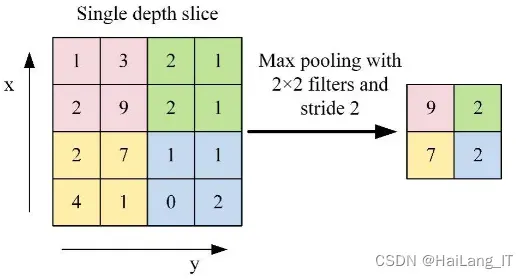
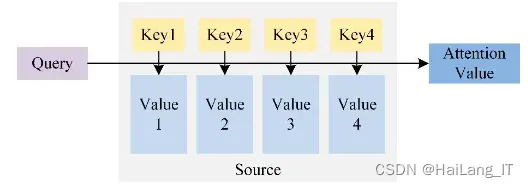
注意力机制的原理主要基于对人类视觉的研究。在处理大量信息时,人类会选择性地关注重要部分,同时忽略其他可见的信息,这种机制被称为注意力机制。在深度学习和神经网络中,注意力机制的实现方式是通过计算每个输入位置的注意力权重,然后将权重与对应的输入相乘并求和,得到加权的输入表示。这样,模型可以更加关注重要的信息,提高处理效率和准确性。可以帮助模型更加准确地把握关键信息,提高处理效率和准确性。同时,注意力机制也具有很强的可解释性,可以帮助我们更好地理解模型的工作原理。
1.2 图像拼接
全景图像拼接算法是一个多步骤的过程,它旨在将多幅具有重叠区域的图像无缝地拼接成一幅宽广视角的全景图。这个过程开始于对待拼接图像的预处理,通过这一步可以去除图像中的噪声、畸变等不利因素,为后续的拼接工作奠定基础。接下来,算法会定位图像中相似的部分,这些相似部分通常是不同图像之间的重叠区域,它们提供了将图像拼接在一起的线索。根据这些相似部分的位置,算法能够推导出待拼接图像之间的变换模型,这个模型描述了图像之间在空间上的相对关系。利用这个变换模型,可以将多幅待拼接图像变换到同一坐标系下,实现图像的精确配准。最后,为了获得更加自然和平滑的拼接效果,算法会使用图像融合技术对拼接区域进行调整,这一步骤能够消除拼接缝隙,使得不同图像在拼接处实现无缝过渡。通过这些步骤,全景图像拼接算法能够有效地将多幅图像融合成一幅宽广、连续的全景图,为用户提供更加全面和沉浸式的视觉体验。
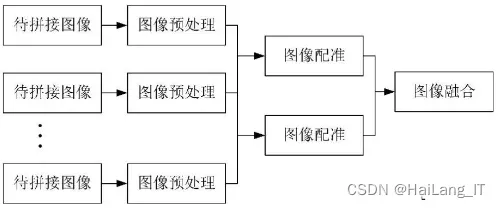
图像配准在全景图像拼接中扮演了至关重要的角色,其质量直接决定了最终拼接结果的好坏。基于像素的配准方法虽然通过寻找图像间的相似重叠区域并进行相似度评估来实现配准,但其时间复杂度高且对图像灰度变化敏感,应用场景有限。相比之下,基于特征的图像配准方法通过检测图像中的特殊点(如斑点、角点等)来进行特征提取和描述,不仅显著减少了计算量、提高了匹配速度,而且由于其特征点对光照和噪声的敏感性较低,具有平移和旋转不变性,因此配准质量更高。目前,基于特征的图像配准方法因其高效性和鲁棒性而成为最受欢迎的配准技术,其中SIFT、SURF等特征描述子被广泛使用,为图像拼接领域的发展做出了重要贡献。

SIFT算法是一种强大的图像特征提取和描述技术,它通过检测图像中的关键点并生成对应的特征描述符来实现对图像内容的理解和分析。SIFT算法具有尺度、旋转和光照不变性,这意味着即使图像在大小、方向或光照条件上发生变化,SIFT也能准确地识别和匹配相应的特征点。这种特性使得SIFT在图像拼接、目标跟踪、三维重建等众多计算机视觉应用中表现出色。SIFT算法通过构建尺度空间、定位关键点、确定关键点的主方向和生成特征描述符等步骤来实现特征提取和描述,其生成的描述符具有丰富的信息量和高度区分性,能够有效地应对图像中的复杂变化和挑战。
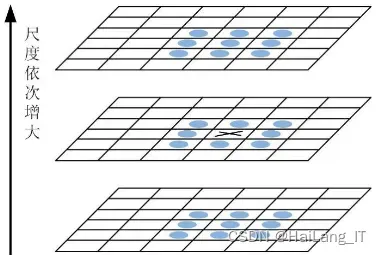
1.3 特征匹配模型
特征匹配模块是计算机视觉任务中的关键组件,尤其在图像配准、目标跟踪、三维重建等领域发挥着重要作用。该模块的核心目标是通过分析两幅或多幅图像中的局部特征,建立起它们之间的准确对应关系。工作流程通常从最低层次(如stage-1级)的特征图开始,这些特征图往往包含了图像的基本结构和纹理信息。在这一阶段,算法会尝试对图像中的特征点进行初步配对,生成一个初始的特征点匹配矩阵。这个矩阵描述了在不同图像中哪些像素点或特征点可能是相同的或相似的。
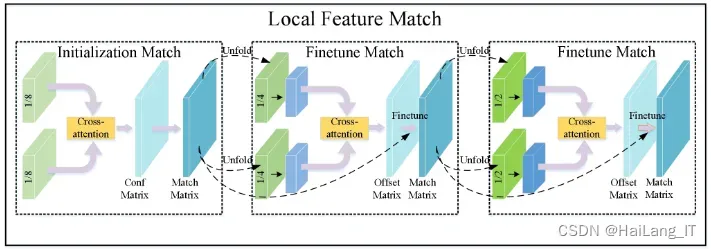
图像局部特征提取模块是一个复杂的结构,它结合了卷积层和自注意层,并采用了多粒度卷积特征结合特征金字塔的设计。这种设计旨在更有效地处理图像中的多尺度变化和细节特征,通过特征金字塔结构实现底层特征的共享。为了提高计算效率,该模块主要使用了深度可分离卷积技术。在每个卷积核上只操作一个通道,显著减少了计算量和模型复杂度。标准卷积中,每个卷积核会同时处理输入特征图的所有通道,输出通道数与卷积核数相同。而在深度可分离卷积中,卷积核与输入特征通道一一对应,输出的通道数与输入通道数保持一致。这种卷积方式不仅降低了模型的计算需求,还有助于保持图像的空间信息和细节特征,从而提高了特征提取的效率和准确性。
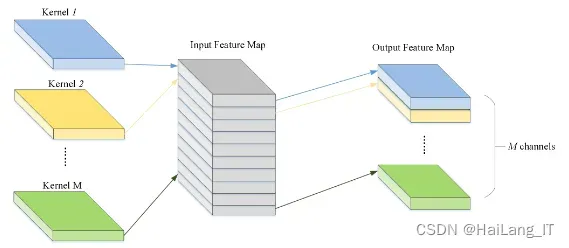
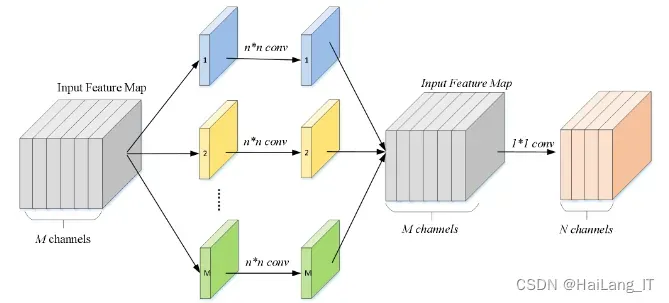
深度可分离卷积是一种高效的卷积方式,其中Depthwise Convolution对每个通道独立进行卷积计算,降低了计算复杂度。然而,这种方式导致不同通道之间的信息无法交互和共享,可能影响网络的表达能力。为了解决这个问题,通常在Depthwise Convolution之后加上Pointwise Convolution,即使用1*1的卷积核对通道进行信息整合,生成新的特征图。这种组合方式既保持了计算效率,又增强了网络对通道间信息的处理能力。因此,深度可分离卷积在实际应用中广泛被采用,成为提高模型性能的重要手段。
二、实验及结果分析
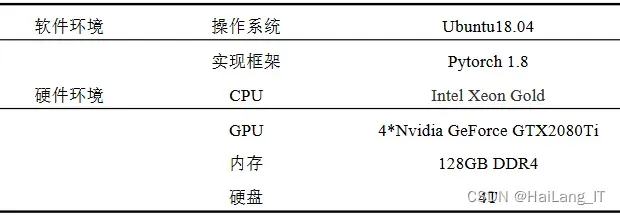
2.1 实验环境搭建
2.2 模型训练
现有的公开数据集并不能完全满足我的研究需求。为了提高系统的拼接性能和泛化能力,我决定自行构建一组全景图像数据集。我通过多种渠道收集了大量不同场景、不同角度的全景图像,并对这些图像进行了预处理和标注工作。在预处理阶段,我对图像进行了裁剪、缩放、去噪等操作,以确保图像的质量和一致性。在标注过程中,我使用专业的标注工具对图像中的关键点进行了标注,为后续的拼接工作提供了准确的参考。最终,我构建了一个包含丰富多样全景图像的数据集,这个数据集不仅涵盖了各种场景和角度的图像,还包含了实际应用中可能遇到的各种复杂情况和挑战。
相关代码示例:
import cv2
import numpy as np
images = [cv2.imread('image1.jpg'), cv2.imread('image2.jpg'), ...]
sift = cv2.SIFT_create()
keypoints_list = []
descriptors_list = []
for image in images:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
keypoints, descriptors = sift.detectAndCompute(gray, None)
keypoints_list.append(keypoints)
descriptors_list.append(descriptors)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
matches_list = []
for i in range(len(descriptors_list)):
for j in range(i+1, len(descriptors_list)):
matches = bf.match(descriptors_list[i], descriptors_list[j])
matches = sorted(matches, key=lambda x: x.distance)
matches_list.append(matches)
result = cv2.hconcat([images[0], images[1]]) # 假设只有两张图像,水平拼接
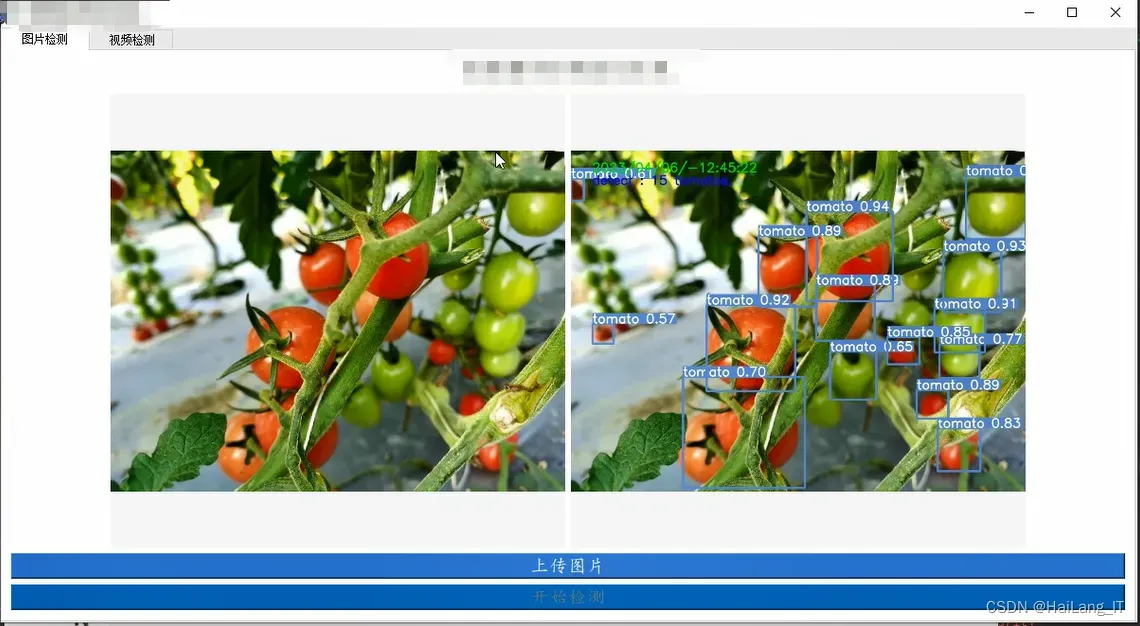
实现效果图样例:

最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
版权声明:本文为博主作者:HaiLang_IT原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_37340229/article/details/136050387