TensorFlow框架简介
-
- TensorFlow简介
- TensorFlow核心概念
- TensorFlow特点
- TensorFlow框架架构
-
- 前端
- 后端
- 基本使用步骤
- 总结
TensorFlow简介
TensorFlow 是一款由 Google 开源的人工智能框架,是目前应用最广泛的深度学习框架之一。它可以在各种硬件平台上运行,包括单个 CPU、CPU 集群、GPU,甚至是分布式环境下的 CPU 和 GPU 组合。

除了深度学习领域,TensorFlow 还支持其他机器学习算法和模型,如决策树、SVM、k-means 等。同时,TensorFlow 还提供了各种高层次的 API 和工具库,如Keras、TensorBoard等,方便开发人员进行模型构建和可视化管理。
TensorFlow核心概念
TensorFlow 通过张量、计算图、变量、会话、损失函数和优化器等核心概念来表示、训练和部署各种类型的深度学习模型。其核心概念包括以下几个方面:
1.张量(Tensor):TensorFlow 的基本数据单元,可以看做是多维数组。在 TensorFlow 中,所有数据都是以张量的形式进行存储和传递。
2.计算图(Computational Graph):TensorFlow 中的计算过程可以表示为一个计算图,每个节点表示一个操作,每个边表示数据的流动。TensorFlow 通过构建这样的计算图来完成模型的训练和预测。
3.变量(Variable):TensorFlow 中的变量可以看做是一种特殊的张量,用于保存模型的参数。在训练模型过程中,变量的值会发生变化。在 TensorFlow 中,我们通常使用变量来存储模型中需要学习的参数。
4.会话(Session):TensorFlow 中的会话用于执行图上的操作,通过对计算图进行计算,最终得到模型的输出结果。在 TensorFlow 中,我们需要先创建一个会话对象,然后利用会话对象来执行计算图上的操作。
5.损失函数(Loss Function):TensorFlow 中的损失函数用于衡量模型的预测结果与真实结果的差距。在训练模型时,我们希望通过最小化损失函数来优化模型的参数。
6.优化器(Optimizer):TensorFlow 中的优化器用于根据损失函数的结果来更新模型的参数。常见的优化算法有梯度下降、Adam 等。
TensorFlow特点
1.强大的功能:TensorFlow 可以支持各种类型的机器学习任务,包括图像识别、自然语言处理、语音识别、推荐系统、强化学习等多个领域,且可以构建各种深度学习模型。
2.灵活性:TensorFlow 的计算图模型和动态图机制使得开发者可以选择最适合自己的编程模型来构建深度学习模型,同时也方便模型的调试和修改。
3.高性能:TensorFlow 支持 GPU 加速和分布式计算,可以提升模型训练和预测的速度和效率。
4.易于使用:TensorFlow 提供了丰富的 API 和工具库,使得开发者可以更加方便地构建、训练和部署深度学习模型。同时也有很多文档、教程和示例代码可供参考。
5.大规模应用:TensorFlow 在 Google 内部有广泛的应用,并被其它公司和科研机构所采用,充分体现了它在大规模应用上的可行性和优越性。
TensorFlow框架架构
TensorFlow 的前端和后端是 TensorFlow 架构中的两个层次。

前端
TensorFlow 的前端是 Python API 的部分。它提供了一组高级抽象来帮助用户建立机器学习模型。这包括 Layers API、Keras API 和 Eager Execution API 等。
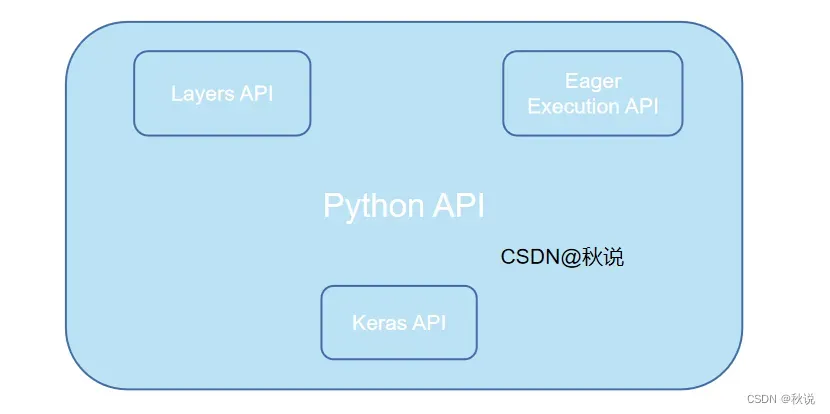
Layers API:Layers API 是 TensorFlow 中最重要的抽象之一,它为神经网络模型提供了标准化的层组件。用户可以使用层 API 去组装深度学习模型,并且可以选择不同的层组件在模型中实现某些特定功能。
Keras API:Keras API 是一个高级的神经网络 API,是 TensorFlow 2.0 中默认的高级 API。Keras API 提供了建立深度学习模型所需的大量工具和组件,同时也很容易上手。
Eager Execution API:Eager Execution API 是 TensorFlow 的一个实验性功能,可以让用户像写 Python 代码一样自由地编写和执行 TensorFlow 代码。与常规 TensorFlow 框架不同的是,Eager Execution API 计算过程是立即返回结果的,而不是在图中计算乘积。
后端
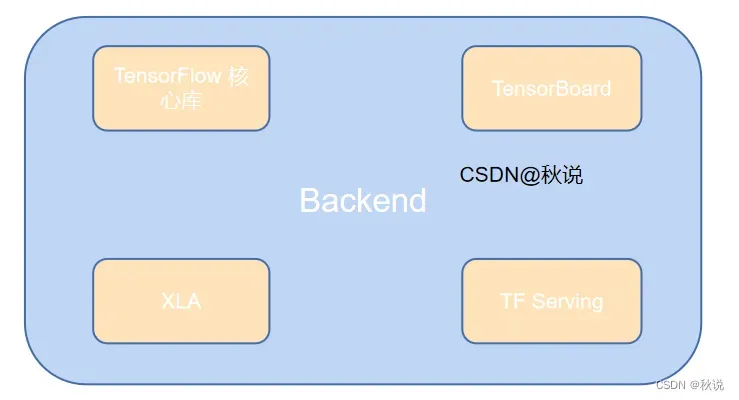
TensorFlow 的后端是用 C++ 编写,它执行前端创建的机器学习模型,这是 TensorFlow 的核心部分。TensorFlow 的后端架构的中心组成部分是计算图,它将机器学习模型表示为一系列节点,这些节点在指定的张量之间执行操作。除了计算图以外,TensorFlow 后端还包含了很多其他重要的组件:
TensorFlow 核心库:TensorFlow 核心库提供了实现节点和运算的基本机制,它实现了支持高层 API 的低层数据流计算框架。
TensorBoard:TensorBoard 是一个 TensorFlow 工具,可用于可视化模型和训练信息。
XLA:XLA 用于加速 TensorFlow 计算和 JIT 编译。
TF Serving:TF Serving 是一个分布式机器学习模型部署系统,用于生产环境的在线预测。
基本使用步骤
使用 TensorFlow 通常包括以下步骤:
1.安装 TensorFlow
使用 Anaconda 来创建一个新的 Python 环境,使用 pip 安装 TensorFlow。安装命令如下:
pip install tensorflow
如果想要使用 GPU 版本的 TensorFlow,则需要安装额外的依赖库,例如 CUDA 和 cuDNN
2.导入 TensorFlow
安装 TensorFlow 后,要在 Python 中使用它,需要首先导入 TensorFlow 库:
import tensorflow as tf
3.创建计算图
使用 TensorFlow 建立一个计算图,这是由一系列节点和张量构成的图形,其中节点表示计算单元,而张量则表示数据。下面代码展示了如何创建一个简单的计算图:
a = tf.constant(5)
b = tf.constant(10)
c = tf.multiply(a, b)
这个计算图中包含了两个常量节点(a和b)和一个乘法节点(c),分别用于存储数值5和10,并将它们相乘。
4.运行计算图
当我们构建了一个计算图之后,可以创建一个 TensorFlow 会话来执行计算操作。在 TensorFlow 会话内,操作会由计算图计算出结果,结果被存储在张量中。
下面是实例代码:
with tf.Session() as sess:
result = sess.run(c)
print(result)
这段代码创建了一个 TensorFlow 会话,并使用 sess.run() 方法运行计算图中的乘法节点。结果被存储在张量c中,并打印出来。
5.优化模型
如果我们想要训练深度学习模型,那么我们需要使用 TensorFlow 的优化算法来更新神经网络中的权重和偏置。优化算法可以通过反向传播算法自动计算误差梯度,然后使用梯度下降的方法来更新权重和偏置。
下面是一个简单的优化过程:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
这个代码段中定义了一个梯度下降优化器,并使用 minimize() 方法来最小化损失函数loss。在训练模型时,利用 train_op 更新神经网络中的权重和偏置。
官方文档:TensorFlow 2.0 教程地址
总结
综上所述,TensorFlow 是一款强大的人工智能框架,可用于构建和训练各种类型的深度学习和机器学习模型,并且具有广泛的社区支持和应用案例。
我是秋说,我们下次见。
版权声明:本文为博主作者:秋说原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2301_77485708/article/details/130899014