使用CV2,skimage,PIL三种图像库做图像标签数据集的方法
1)方法一:利用opencv-python库生成图像标签数据集
2)方法二:利用scikit-image库生成图像标签数据集
3)方法三:利用PIL.Image图像处理包生成图像标签数据集
目标:掌握独立使用CV2,skimage,PIL此三种图像库做(图像+标签)数据集的方法
- 学习数据集制作方法,图像预处理方法。不同图像库自带的预处理方法各有不同。
- 学会让自己的数据集设计模式规范化,以后的数据集处理会变得信手拈来。
- 制作清晰明确的数据集,可以让后期训练使用中得心应手,让每一个字节划过心房。
- 独立使用不同图像库,不交叉不重叠,可避免数据混乱,尤其是w,h,c的混乱。
- 基于策略模式构建具有三种能力的图像标签数据集生成器接口。
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
前面做了一篇关于服装关键点检测算法的博客,因为重点在算法模型上,所以数据集这一块做的比较粗糙。评论区对于数据集的问题还蛮多,所以,我在这篇文章重点介绍一下数据集。
本文将提供三种生成数据集的方案。供大家参考。
关键点检测算法的数据集生成器模块的环境配置requirements.txt
python==3.7
numpy
pandas
pillow
opencv-python
scipy
scikit-image
pytorch==1.5.1
torchvision
数据集图像-标签: 目录和标签数据结构
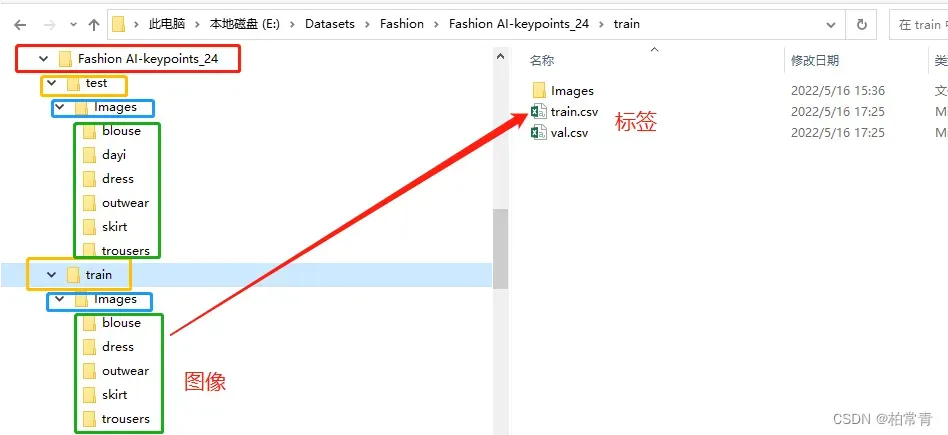
csv文件
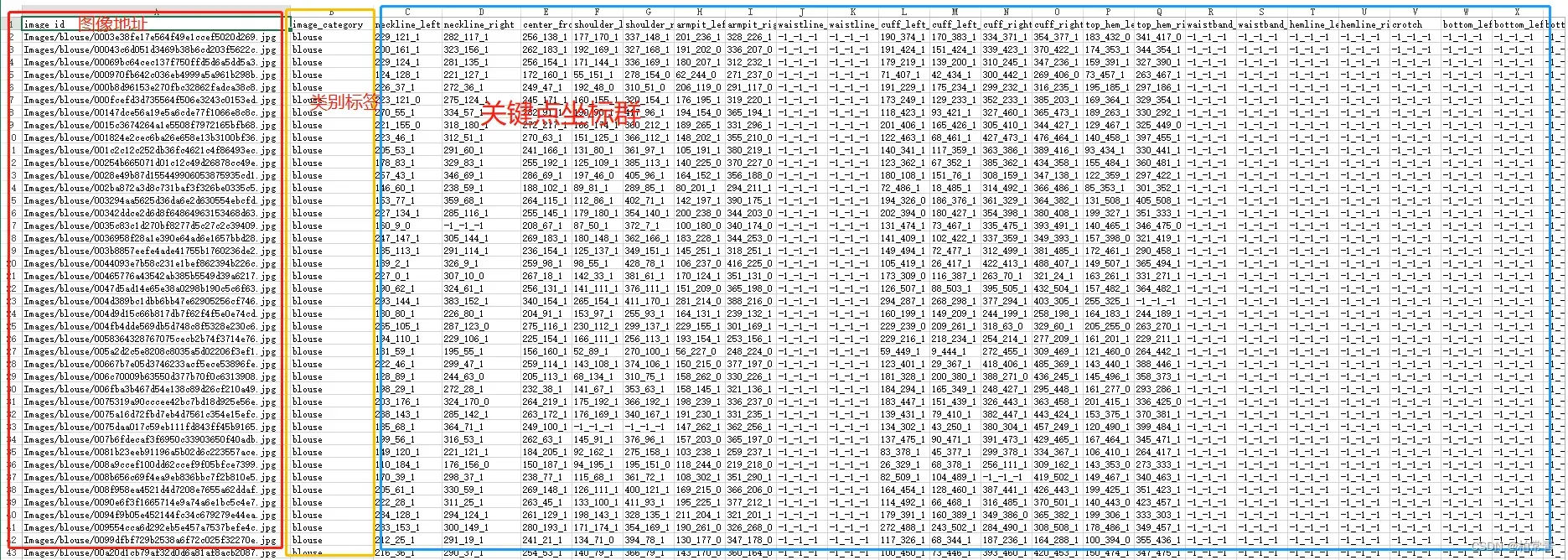
提示:以下是本篇文章正文内容,结合三种图像标签数据集生成方法的总接口
一、提供三种生成数据集的方案总接口
利用策略模式设计数据集接口:
代码:dataset_design_patterns.py
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 10:42
# @Author : Hyan Tan
# @File : dataset_design_patterns.py
import os
from abc import abstractmethod, ABCMeta
import numpy as np
import pandas as pd
import cv2
from skimage import io, transform, draw
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from transformation import RandomAdd, ImageResize, RandomCrop, RandomFlip, RandomRotate, Distort
# ------抽象数据集------抽象策略
class KeyPointsDataSet(Dataset):
"""服装-类型-关键点群标记数据集"""
def __init__(self, root_dir=r'E:/Datasets/Fashion/Fashion AI-keypoints_24/train/', image_set='train',
transforms=None):
"""
初始化数据集
:param root_dir: 数据目录(.csv和images的根目录)
:param image_set: train训练,val验证,test测试
:param transforms(callable,optional):图像变换-可选
标签数据文件格式为csv_file: 标签csv文件(内容:图像相对地址-category类型-标签coordination坐标)
"""
super(KeyPointsDataSet, self).__init__()
self._imgset = image_set
self._image_paths = []
self._labels = []
self._cates = [] # 标签:服装类别
self._csv_file = os.path.join(root_dir, image_set + '.csv') # csv标签文件地址
self._categories = ['blouse', 'outwear', 'dress', 'trousers', 'skirt', ]
self._root_dir = root_dir
self._transform = transforms
self.__getFileList() # 图地址列表和标签列表
def __getFileList(self):
file_info = pd.read_csv(self._csv_file)
self._image_paths = file_info.iloc[:, 0] # 图像地址在第一列
self._cates = file_info.iloc[:, 1] # 第二列,服装类型:blouse,trousers,skirt,dress,outwear
if self._imgset == 'train': # 只有训练和验证有标签,测试没有标签。
landmarks = file_info.iloc[:, 2:26].values # panda中DataFrame数据的读取
for i in range(len(landmarks)):
label = []
for j in range(24):
plot = landmarks[i][j].split('_')
coor = []
for per in plot:
coor.append(int(per))
label.append(coor)
self._labels.append(np.concatenate(label))
self._labels = np.array(self._labels).reshape((-1, 24, 3))
else:
self._labels = np.ones((len(self._image_paths), 24, 3)) * (-1)
def __len__(self):
return len(self._image_paths)
# ---具体数据集生成器---通过cv2读取图像数据---具体策略1
class DatasetByCv(KeyPointsDataSet):
def __getitem__(self, idx):
label = self._labels[idx]
image = cv2.imread(os.path.join(self._root_dir, self._image_paths[idx]), cv2.IMREAD_COLOR)
imgSize = image.shape # cv2读取的是图像数组类型 BGR H W C
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
if self._transform:
image = self._transform(image)
afterSize = image.shape
# bi = np.array(afterSize[0:2]) / np.array(imgSize[0:2])
# 坐标(x,y)代表的是w,h。图像是h,w,c的格式,所以此处反着来
bi = np.array((afterSize[1], afterSize[0])) / np.array((imgSize[1], imgSize[0]))
label[:, 0:2] = label[:, 0:2] * bi # 图像伸缩变换,坐标同步伸缩
image = image.astype(np.float32)
# image = image.transpose((2, 0, 1))
return image, label, category
# ---具体数据集生成器---通过Skimage读取图像数据---具体策略2
class DatasetBySkimage(KeyPointsDataSet):
def __getitem__(self, idx):
label = np.asfortranarray(self._labels[idx]) # (x, y, 显隐)=(宽,高,显隐性)
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
img_id = self._image_paths[idx]
img_id = os.path.join(self._root_dir, img_id)
image = io.imread(img_id) # (高,宽,通道数)= (h, w, c)
imgSize = image.shape[0:2] # 原始图像宽高
if self._transform:
# image = self._transform(image) # self._transform此处不可用
image = transform.resize(image, output_shape=(256, 256)) # 使用skimage库自带transform
else:
image = transform.resize(image, output_shape=(256, 256)) # 使用skimage库自带transform
afterSize = image.shape[0:2] # 缩放后图像的宽高
bi = np.array((afterSize[1], afterSize[0])) / np.array((imgSize[1], imgSize[0]))
label[:, 0:2] = label[:, 0:2] * bi
return image, label, category
# ---具体数据集生成器---通过PIL.Image读取图像数据---具体策略3
class DatasetByPIL(KeyPointsDataSet):
def __getitem__(self, idx):
img_id = self._image_paths[idx]
img_id = os.path.join(self._root_dir, img_id)
image = Image.open(img_id).convert('RGB') # [3, 256, 256](通道数,高,宽)= (c, h, w)
imgSize = image.size # 原始图像宽高
label = np.asfortranarray(self._labels[idx]) # (x, y, 显隐)=(宽,高,显隐性)
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
if self._transform:
image = self._transform(image) # 返回torch.Size([3, 256, 256])
afterSize = image.numpy().shape[1:] # 缩放后图像的宽高
else:
image.resize((256, 256)) # 使用resize
afterSize = (256, 256) # 缩放后图像的宽高
bi = np.array(afterSize) / np.array(imgSize)
label[:, 0:2] = label[:, 0:2] * bi
return image, label, category
# ------总接口------
class Content(object):
def __init__(self, root_dir, image_set='train', strategy='cv2', outsize=256):
"""
:param root_dir: 数据目录
:param image_set: train,val,test
:param strategy: cv2,skimage,pil
:param outsize:
"""
self.root_dir = root_dir
self.img_set = image_set
self.strategy = strategy
self.outsize = outsize
self._transform = None
self.set_transform()
self._data = None
self.crate_dataset()
def set_transform(self):
train_transform = None
val_transform = None
test_transform = None
if self.strategy == 'cv2':
train_transform = transforms.Compose([
ImageResize(size=self.outsize),
])
val_transform = train_transform
test_transform = transforms.Compose([
ImageResize(size=288),
RandomCrop(in_size=288, out_size=self.outsize), # 随机裁剪,测试可用,验证也不可用
RandomFlip(), # 随机翻转
RandomRotate(), # 随机旋转
Distort() # 歪曲
])
if self.strategy == 'pil' or self.strategy == 'skimage':
# 训练和验证集采用transform做变换
train_transform = transforms.Compose([
transforms.Resize([self.outsize, self.outsize]), # 把图片resize
transforms.ToTensor(), # 将图像转为Tensor,数据归一化了欸!img.float().div(255)
])
val_transform = train_transform
# 测试集采用test_transform做变换
test_transform = transforms.Compose([
transforms.Resize([288, 288]), # 把图片resize为256*256
transforms.RandomCrop(self.outsize), # 随机裁剪,测试时无标签
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.ToTensor(), # 将图像转为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
if self.img_set == 'train':
self._transform = train_transform
elif self.img_set == 'val':
self._transform = val_transform
elif self.img_set == 'test':
self._transform = test_transform
def crate_dataset(self):
if self.strategy == 'cv2':
self._data = DatasetByCv(self.root_dir, self.img_set, self._transform)
if self.strategy == 'skimage':
self._data = DatasetBySkimage(self.root_dir, self.img_set, self._transform)
if self.strategy == 'pil':
self._data = DatasetByPIL(self.root_dir, self.img_set, self._transform)
def get_dataLoader(self, batch_size=2, shuffle=False, num_workers=4, drop_last=True):
return DataLoader(self._data,
batch_size=batch_size,
shuffle=shuffle,
# num_workers=num_workers,
drop_last=drop_last
)
if __name__ == "__main__":
data_root = r'E:/Datasets/Fashion/Fashion AI-keypoints_24/train/' # 数据文件夹:包含train和test
num_workers = 4
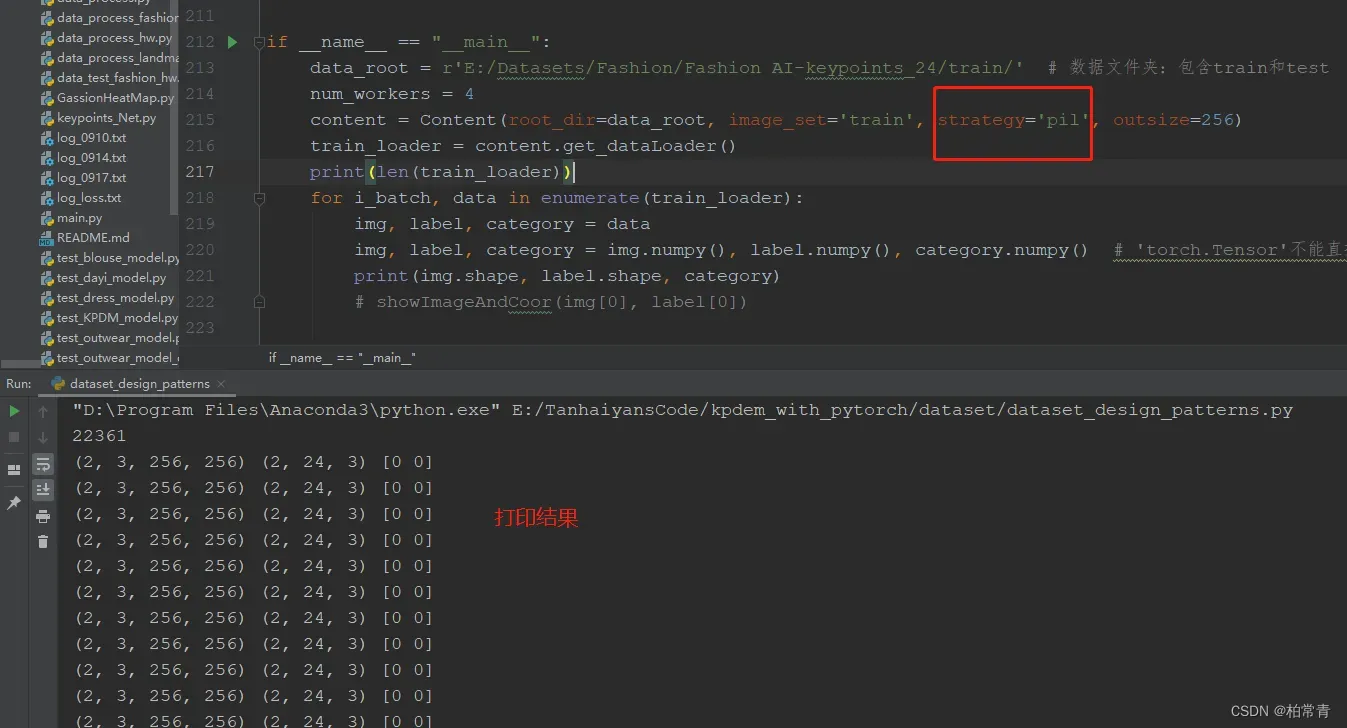
content = Content(root_dir=data_root, image_set='train', strategy='pil', outsize=256)
train_loader = content.get_dataLoader()
print(len(train_loader))
for i_batch, data in enumerate(train_loader):
img, label, category = data
img, label, category = img.numpy(), label.numpy(), category.numpy() # 'torch.Tensor'不能直接显示,需要转换程io能处理的numpy数组格式。
print(img.shape, label.shape, category)
# showImageAndCoor(img[0], label[0])
选择不同的策略,生成数据集的测试结果
1.选择opencv图像处理包生成图像标签数据集
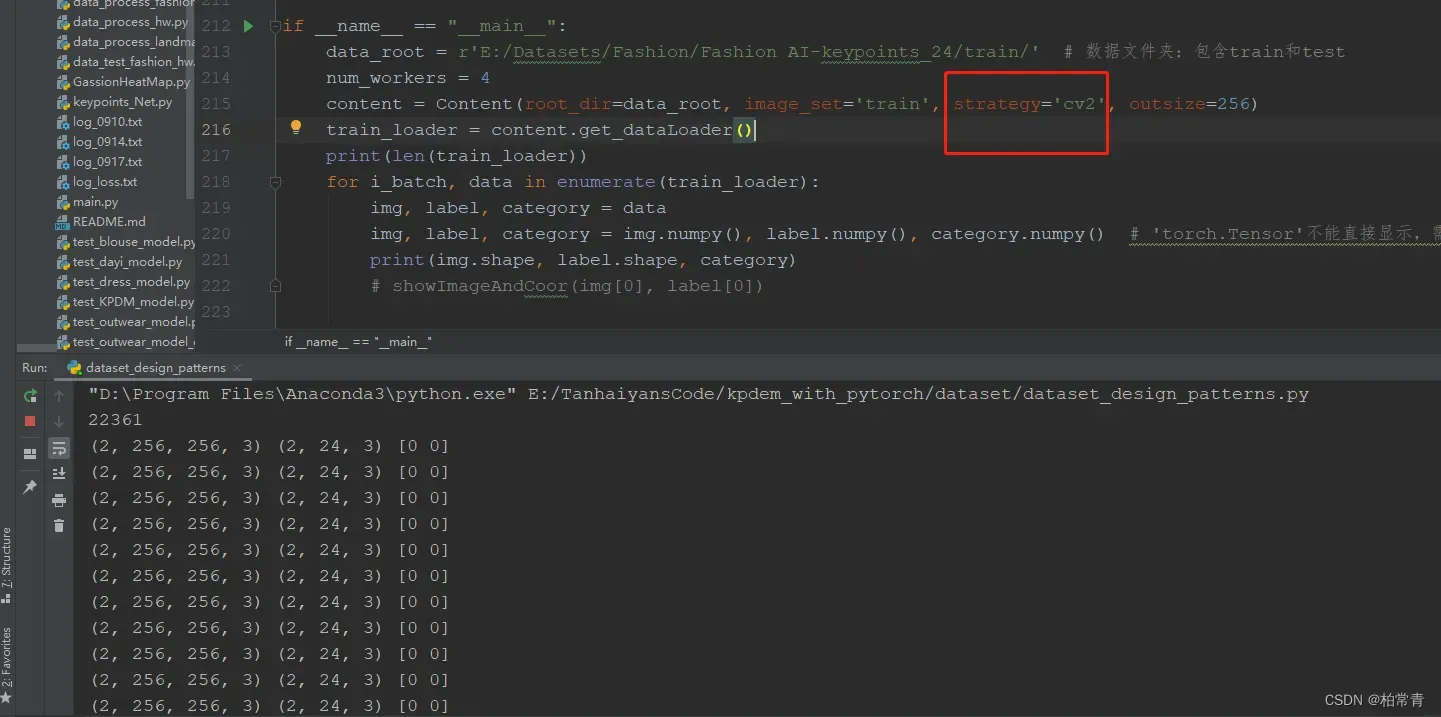
2. 选择skimage图像处理包生成图像标签数据集
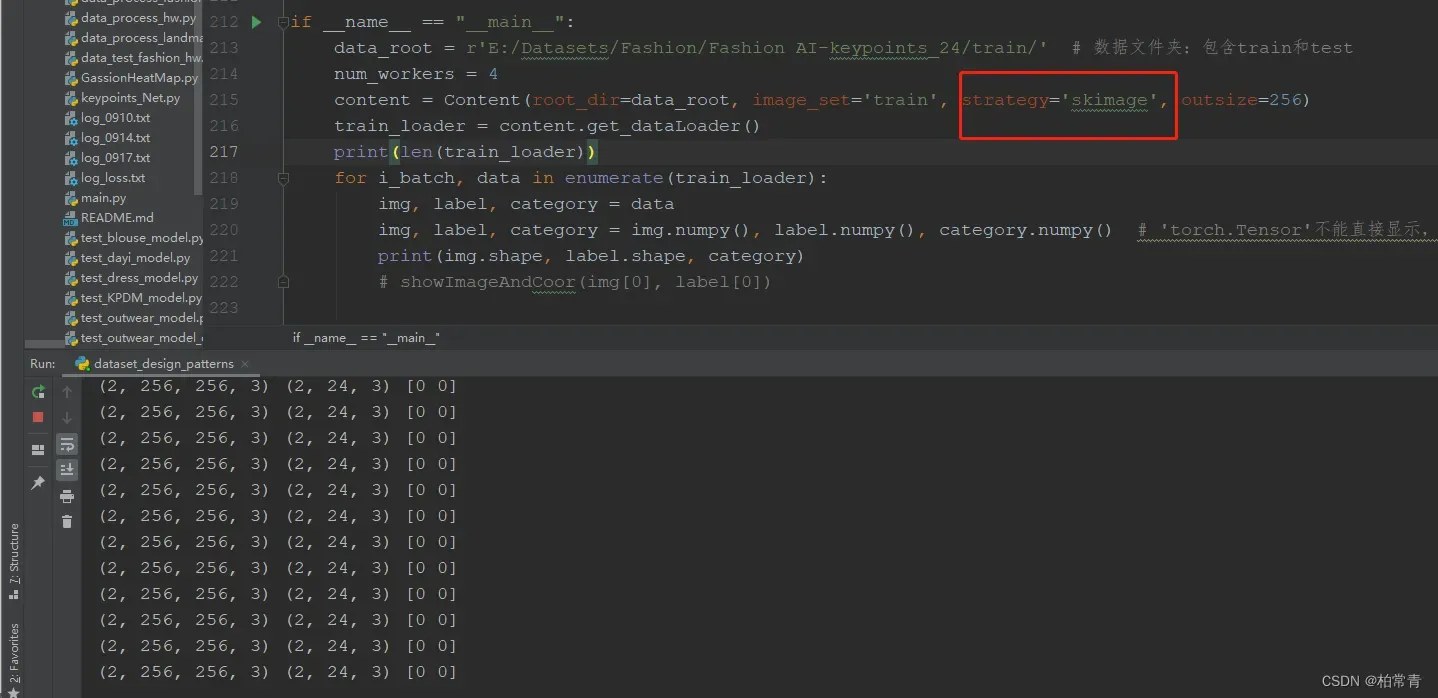
3. 选择PIL.Image图像处理包生成图像标签数据集
二、利用opencv-python库生成图像标签数据集
1)方法一:利用opencv-python库生成图像标签数据集
三、利用scikit-image库生成图像标签数据集
2)方法二:利用scikit-image库生成图像标签数据集
四、利用PIL.Image图像处理包生成图像标签数据集
3)方法三:利用PIL.Image图像处理包生成图像标签数据集
五、总结
熟练构建数据集、清晰每一条数据、很重要;运用设计模式写代码,是自我成长的体现!
- 13种设计模式分享
设计模式的定义:为了解决面向对象系统中重要和重复的设计封装在一起的一种代码实现框架,可以使得代码更加易于扩展和调用
四个基本要素:模式名称,问题,解决方案,效果 - 关注每一个方法的注意事项,便于找到问题和解决问题。
文章出处登录后可见!
已经登录?立即刷新