提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近在一个项目中需要使序列标注的方法来进行命名实体识别,目前使用序列标注方法进行命名实体识别主要有两种实现方法:一是基于统计的模型:HMM、MEMM、CRF,这类方法需要关注特征工程;二是深度学习方法:RNN、LSTM、GRU、CRF、RNN+CRF…
本篇记录了如何使用sklearn_crfsuite工具进行中文命名实体识别。
一、条件随机场(CRF,Conditional Random Fields)
条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示,
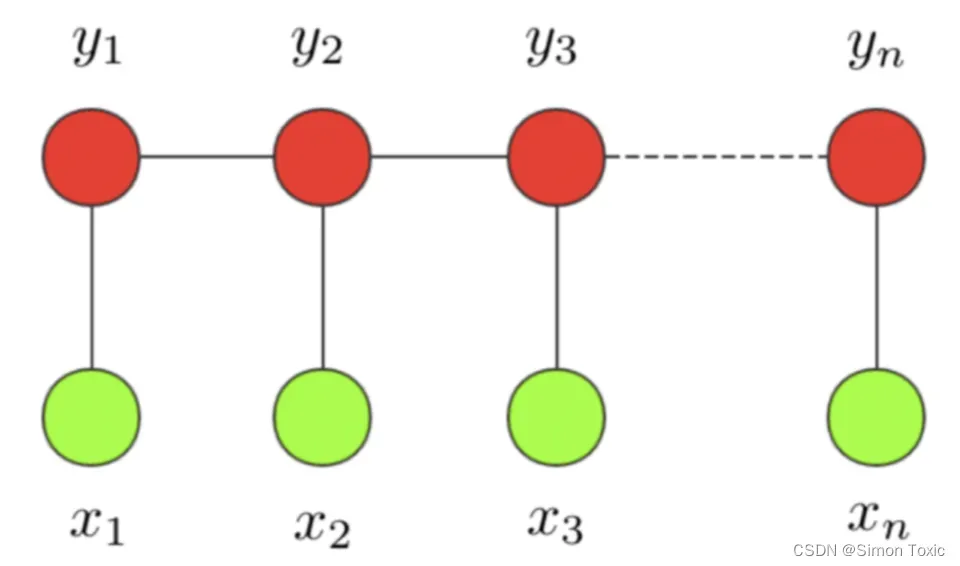
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类,一类是 x 与 y 之间的连线,表示其相关性;另一类是相邻时刻的 y之间的相关性。也就是说,在预测某时刻 y时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
对于 CRF,我们给出准确的数学语言描述:设 X 与 Y 是随机变量,P(Y|X) 是给定 X 时 Y 的条件概率分布,若随机变量 Y 构成的是一个马尔科夫随机场,则称条件概率分布 P(Y|X) 是条件随机场。
二、使用sklearn_crfsuite进行命名实体识别
本文使用sklearn_crfsuite进行命名实体识别模型的训练,官方教程的链接如下:https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html
1.安装说明
首先需要确保你已安装了scikit-learn这个库,然后通过pip安装sklearn-crfsuite
pip install sklearn-crfsuite
注意sklearn-crfsuite 需要 Python 2.7+ 或 3.3+
2.准备数据
这里我使用的是清华大学开源的cluner数据集。数据集的下载地址:https://www.cluebenchmarks.com/introduce.html
CLUENER2020共有10个不同的类别,包括:
组织(organization)
人名(name)
地址(address)
公司(company)
政府(government)
书籍(book)
游戏(game)
电影(movie)
职位(position)
景点(scene)
在拿到数据之后,我将数据处理成了下面的格式:
浙 B-company
商 I-company
银 I-company
行 I-company
企 O
业 O
信 O
贷 O
部 O
字与标签之间以空格隔开,每句话中间以换行分割
3.构造特征
确定好所需要训练的数据集之后,最重要的步骤就是定义特征模板。
在本示例中主要使用了词的上下文信息来构造特征模板。当然更多特征可以参考官方的示例进行设置。
这里使用的特征字典如下:
def word2features(sent, i):
word = sent[i][0]
#构造特征字典,我这里因为整体句子长度比较长,滑动窗口的大小设置的是6 在特征的构建中主要考虑了字的标识,是否是数字和字周围的特征信息
features = {
'bias': 1.0,
'word': word,
'word.isdigit()': word.isdigit(),
}
#该字的前一个字
if i > 0:
word1 = sent[i-1][0]
words = word1 + word
features.update({
'-1:word': word1,
'-1:words': words,
'-1:word.isdigit()': word1.isdigit(),
})
else:
#添加开头的标识 BOS(begin of sentence)
features['BOS'] = True
#该字的前两个字
if i > 1:
word2 = sent[i-2][0]
word1 = sent[i-1][0]
words = word1 + word2 + word
features.update({
'-2:word': word2,
'-2:words': words,
'-3:word.isdigit()': word2.isdigit(),
})
#该字的前三个字
if i > 2:
word3 = sent[i - 3][0]
word2 = sent[i - 2][0]
word1 = sent[i - 1][0]
words = word1 + word2 + word3 + word
features.update({
'-3:word': word3,
'-3:words': words,
'-3:word.isdigit()': word3.isdigit(),
})
#该字的后一个字
if i < len(sent)-1:
word1 = sent[i+1][0]
words = word1 + word
features.update({
'+1:word': word1,
'+1:words': words,
'+1:word.isdigit()': word1.isdigit(),
})
else:
#若改字为句子的结尾添加对应的标识end of sentence
features['EOS'] = True
#该字的后两个字
if i < len(sent)-2:
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2
features.update({
'+2:word': word2,
'+2:words': words,
'+2:word.isdigit()': word2.isdigit(),
})
#该字的后三个字
if i < len(sent)-3:
word3 = sent[i + 3][0]
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2 + word3
features.update({
'+3:word': word3,
'+3:words': words,
'+3:word.isdigit()': word3.isdigit(),
})
return features
4.详细流程
1 导包
import re
import sklearn_crfsuite
from sklearn_crfsuite import metrics
import joblib
import yaml
import warnings
warnings.filterwarnings('ignore')
2 定义通用函数
def load_data(data_path):
data_read_all = list()
data_sent_with_label = list()
with open(data_path, mode='r', encoding="utf-8") as f:
for line in f:
if line.strip() == "":
data_read_all.append(data_sent_with_label.copy())
data_sent_with_label.clear()
else:
data_sent_with_label.append(tuple(line.strip().split(" ")))
return data_read_all
3 定义一些特征
def word2features(sent, i):
word = sent[i][0]
#构造特征字典,我这里因为整体句子长度比较长,滑动窗口的大小设置的是6 在特征的构建中主要考虑了字的标识,是否是数字和字周围的特征信息
features = {
'bias': 1.0,
'word': word,
'word.isdigit()': word.isdigit(),
}
#该字的前一个字
if i > 0:
word1 = sent[i-1][0]
words = word1 + word
features.update({
'-1:word': word1,
'-1:words': words,
'-1:word.isdigit()': word1.isdigit(),
})
else:
#添加开头的标识 BOS(begin of sentence)
features['BOS'] = True
#该字的前两个字
if i > 1:
word2 = sent[i-2][0]
word1 = sent[i-1][0]
words = word1 + word2 + word
features.update({
'-2:word': word2,
'-2:words': words,
'-3:word.isdigit()': word2.isdigit(),
})
#该字的前三个字
if i > 2:
word3 = sent[i - 3][0]
word2 = sent[i - 2][0]
word1 = sent[i - 1][0]
words = word1 + word2 + word3 + word
features.update({
'-3:word': word3,
'-3:words': words,
'-3:word.isdigit()': word3.isdigit(),
})
#该字的后一个字
if i < len(sent)-1:
word1 = sent[i+1][0]
words = word1 + word
features.update({
'+1:word': word1,
'+1:words': words,
'+1:word.isdigit()': word1.isdigit(),
})
else:
#若改字为句子的结尾添加对应的标识end of sentence
features['EOS'] = True
#该字的后两个字
if i < len(sent)-2:
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2
features.update({
'+2:word': word2,
'+2:words': words,
'+2:word.isdigit()': word2.isdigit(),
})
#该字的后三个字
if i < len(sent)-3:
word3 = sent[i + 3][0]
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2 + word3
features.update({
'+3:word': word3,
'+3:words': words,
'+3:word.isdigit()': word3.isdigit(),
})
return features
4 从数据中提取特征
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [ele[-1] for ele in sent]
5 读取数据
train=load_data('data/cluner_train.txt')
valid=load_data('data/cluner_dev.txt')
print('训练集规模:',len(train))
print('验证集规模:',len(valid))
sample_text=''.join([c[0] for c in train[0]])
sample_tags=[c[1] for c in train[0]]
X_train = [sent2features(s) for s in train]
y_train = [sent2labels(s) for s in train]
X_dev = [sent2features(s) for s in valid]
y_dev = [sent2labels(s) for s in valid]
print(X_train[0])

6 模型训练
crf_model = sklearn_crfsuite.CRF(algorithm='lbfgs',c1=0.25,c2=0.018,max_iterations=300,
all_possible_transitions=True,verbose=True)
crf_model.fit(X_train, y_train)
7 验证模型效果
labels=list(crf_model.classes_)
labels.remove("O") #对于O标签的预测我们不关心,就直接去掉
y_pred = crf_model.predict(X_dev)
metrics.flat_f1_score(y_dev, y_pred,
average='weighted', labels=labels)
sorted_labels = sorted(labels,key=lambda name: (name[1:], name[0]))
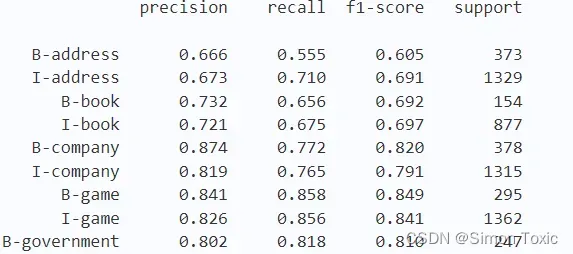
print(metrics.flat_classification_report(
y_dev, y_pred, labels=sorted_labels, digits=3
))
8 保存模型
import joblib
joblib.dump(crf_model, "checkpoint/crf_model.joblib")
总结
本篇记录了如何借助sklearn_crfsuite这个库实现crf模型进行中文命名实体识别,当然实现的方法有很多,比如使用CRF++开源工具做文本序列标注.
文章出处登录后可见!