目录
前言
这一篇文章主要分两部分讲解张量之间的数据处理,第一部分主要是张量的维度变换,包括张量形状的改变、维度的增加和删除、转置以及张量的拼接;第二部分是数据的采样,主要以鸢尾花数据为例讲解特定行、列的选取
函数表
将全文讲解过的函数归纳于此表,便于参考和查询
| 形状处理部分 | 解释 |
| tf.reshape(tensor,shape) | 改变形状 |
| tf.concat(tensors,axis) | 张量拼接 |
| tf.expand_dims(input,axis) | 增加维度 |
| tf.squeeze(input,axis) | 删除维度 |
| tf.transpose(a,perm) | 转置 |
| 数据取样(张量以tf1为例) | 解释 |
| tf.gather(params,axis,indices) | 按索引值取值 |
维度变换
在讲解函数之前,为了更好的理解“维”这个概念,这里有必要做出个人对TensorFlow中的“维”的看法,首先这个维度最初的定义是为了咱们更好地去理解数据间的各种排列组合而人为定义的,比如我们习惯说的零维数据就是一个点,一维数据就是一条线,二维数据就是一个面,三维便是一个体;每多一个维度,数据就会多向着某个方向展开;而张量中也谈及维度的概念,我们说三维张量其实就是三维数组的意思,但是有时候也会习惯性将数据的行数和列数称之为“维”,比如三行两列的二维张量,其在行上面(从上往下看)就有三个维(三行),显然依次类推,在列上面(左右看)就有两个维(两列);其实也是一种叫法的不统一,大家在理解这些概念的时候就见仁见智了。
-
tf.reshape()
tf.reshape(tensor,shape);第一个参数tensor是传入的张量,第二个参数shape是将张量重组成需要的形状。对于shape这个参数,作者略微提及几点:1、形状改变后,数据填入新形状的顺序是按照“从左至右、从上至下”的顺序从原张量中取出数据然后按照这个原则将数据填入新张量;2、新张量形状维度参数的乘积必须等于原数据维度参数的乘积,比如一个4X4的二维张量,其两个维度参数的乘积是16,那么新张量的维度参数的乘积必须也是16,比如这组数据可以填入一个2X2X4的三维张量
- 将 1X16 的张量形状改变成 2X8
import tensorflow as tf
tf1 = tf.range(16) # 创建从0到15的张量
tf2 = tf.reshape(tf1,[2,8]) # 将其改变成一个 2 X 8 的二维数组,数据排序规则是从左往右,排满之后从上向下排output:
>>>print(tf1)
tf.Tensor([ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15], shape=(16,), dtype=int32)
>>>print(tf2)
tf.Tensor(
[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]], shape=(2, 8), dtype=int32) # 这里的形状是2 X 8,表示从行上来看有两维(两行),从列上看有八维(八列)
- 有时候可以在形状参数中看到-1,这个是系统自动识别形状然后形成形状;比如 1X16 的张量,可以通过tf.shape(tf1,[4,-1]),将其改编成 4X4 的张量或是 [8,-1];将其改变成 8X2 的张量
import tensorflow as tf
tf1 = tf.range(16) # 创建从0到15的张量
tf2 = tf.reshape(tf1,[2,8])
tf3 = tf.reshape(tf1,[2,-1]) # 输入 -1 ,让系统帮我识别形状output:
>>>print(tf2)
tf.Tensor(
[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]], shape=(2, 8), dtype=int32)
>>>print(tf3)
tf.Tensor(
[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]], shape=(2, 8), dtype=int32)
-
tf.concat()、tf.contrack()
tf.concat(tensors,axis);第一个参数是传入的张量们;第二个参数是指定沿着哪一个轴进行拼接;作者依然会对此参数提及几点(对于一些重要的函数提及一些比较实用的价值):拼接的数组可以形状不一样,但必须要匹配,即其沿着行(上下)拼接,必须列数一致;其沿着列(左右)拼接,必须行数一致;2、可以多个符合条件的张量一块拼接
- 代码示例
import tensorflow as tf # 每次都导入一次库是为了方便大家复制而不必再去寻找我使用的库,如以后出现了项目实战,就会一次性将结果放在最后
tf1 = tf.constant([[1,2,3],[4,5,6]]) # shape(2,3)
tf2 = tf.constant([[7,8,9],[10,11,12]]) # shape(2,3)
tf3 = tf.constant([[1,2,3]]) #shape(1,3)
# 原则:其沿着行(上下)拼接,必须列数一致;其沿着列(左右)拼接,必须行数一致
tf4 = tf.concat([tf1,tf2],axis=0) # 沿着行拼接
tf5 = tf.concat([tf1,tf2],axis=1) # 沿着列拼接
# 沿着行拼接,可以形状不一致,但只要列数一致就行
tf6 = tf.concat([tf1,tf3],axis=0)
tf7 =tf.concat([tf1,tf2,tf3],axis=0) # 符合条件的参数一起拼接output:
>>>print(tf4)
tf.Tensor(
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]], shape=(4, 3), dtype=int32)
>>>print(tf5)
tf.Tensor(
[[ 1 2 3 7 8 9]
[ 4 5 6 10 11 12]], shape=(2, 6), dtype=int32)
>>>print(tf6)
tf.Tensor(
[[1 2 3]
[4 5 6]
[1 2 3]], shape=(3, 3), dtype=int32)
>>>print(tf7)
tf.Tensor(
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]
[ 1 2 3]], shape=(5, 3), dtype=int32)-
tf.expand_dims() 和 tf.squeeze()
tf.expand_dims(input,axis) 第一个参数是输入张量,第二个参数是在第几个轴上增加一个维度;比如在 2X8 的二维张量上增加一个维度;关于这个函数,作者依然提出自己的看法:这个函数用法和其名字一样,增加一个维度,如一维变二维,二维变三维;axis这个参数其添加维度其原则是“插空法”(高中数学古典排序中的插空法),我们以对 2X8 的数组进行增加维度为例讨论其原理,这个两个(维度)数前后最多可以有三个空位: _2_8_ (“_”表示空位),也就是新产生的维度可以依次填入这个位置,比如填入第0个位置,则为128,插入第1个位置:218;插入第2个位置:281;axis即可以理解为插入第几个空位;下面我就以此为例展开说明:
- 分别在三个空位(轴)添加新维度
import tensorflow as tf
tf1 = tf.range(16) # 创建从0到15的张量
tf2 = tf.reshape(tf1,[2,8])
tf3 = tf.expand_dims(tf2,0) # 在第0维加维度
tf4 = tf.expand_dims(tf2,1) # 在第1维加维度
tf5 = tf.expand_dims(tf2,2) # 在第2维加维度
print(tf2.shape)
print(tf3.shape)
print(tf4.shape)
print(tf5.shape)output:
(2, 8)
(1, 2, 8)
(2, 1, 8)
(2, 8, 1)
tf.squeeze(input,axis)的第一个参数“input”是输入的张量,第二个参数是指定剔除某一维度且维数为一的张量;这里就使用到了“维”这个概念了,其和维度不一致;关于这个函数需要注意以下几点:1、这个函数只能剔除维数为1的张量,比如形状为(1,2,3,4,1)的维张量,其每一维度上面的维数分别为1、2、3、4、1,若使用此函数,则只会剔除第一个和最后一个维度,因为他们的维数为1;2、剔除维度并不会改变原来的数据,即不会减少也不会变得混乱,因此也产生了一个好处,即可以减少产生的中括号,因为一般维数为1的维度其内涵只是在原来张量外多增添了一层括号罢了;
- 效果示范
import tensorflow as tf
tf1 = tf.range(16) # 创建从0到15的张量
tf2 = tf.reshape(tf1,[1,2,8,1]) # 先创建一个四维张量
tf3 = tf.squeeze(tf2) # 单纯输入张量,其作用是剔除所有 维数为一 的维度
# 剔除张量的维度,其不会剔除存储的数据
tf4 = tf.squeeze(tf2,[0]) #若传入第二个参数,即剔除指定维度的 维数为一 的维度output:
>>>print(tf2.shape)
(1, 2, 8, 1)
>>>print(tf3.shape)
(2, 8)
>>>print(tf4.shape)
(2, 8, 1)-
tf.transpose()
tf.transpose(a,perm);第一个参数传入张量,第二个是改变维度的顺序;其内核是调整维度中顺序来实现转置一类的操作的,比如shape(3,2)是一个三行两列的二维张量,其使用该函数之后变成shape(2,3)的两行三列的参数,再比如一个shape(1,3,4)的三维张量,其可以通过第二个参数来调节各维度的顺序,比如填入一个[1,0,2];即将原张量第二维度放在第一维度,第一维度放在第二维度,第三维度还是第三维度,依次类推,再高维度的张量也可以通过此函数来任意调节~
- 实现张量的转置
import tensorflow as tf
tf1 = tf.range(16) # 创建从0到15的张量
tf2 = tf.reshape(tf1,[2,8]) # 先创建一个二维张量
tf3 = tf.transpose(tf2) # 使用其默认转置
tf4 = tf.transpose(tf2,[1,0]) # 将第二维度放在第一维度处,第一维度放在第二维度处output:
# 其结果一致
>>>print(tf3.shape)
(8, 2)
>>>print(tf4.shape)
(8, 2)数据取样(特定行列的选取)
数据取样表示从张量中取得所需行数或者列数以及数值的方法;一般有两种方式取样,各有其优缺点
-
与numpy的取法
这是一种与numpy取法类似的数据采样方式,大致上如:张量[行,列],这样的取法;但相比去numpy也存在些许缺点,可以说其基本上没有办法使用条件表达式,这使得我们取样数据的时候变得比较单一和复杂,但转换思路,我们何尝不可以将其转化为narray(数组),然后处理完数据之后再转换回来呢,各取其优点,tensorflow优点在于其在机器学习上面的优势,因此数据采样相对麻烦~
数据采样的学习,重点在于多练习,然后产生思路,然后代码实现来验证自己的思路;一下我在代码中进行多次演示,阐述减少,大家多练习,自行体会其中的奥妙~,以下为大家提供鸢尾花数据进行实战
- 鸢尾花数据下载,作者也在文末提供了鸢尾花数据集的百度网盘链接,下不了也不用担心;
import tensorflow as tf
TRAIN_URL = 'http://download.tensorflow.org/data/iris_training.csv' # 鸢尾花数据下载
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL) # 将鸢尾花数据存储于电脑中output:获取路径后,根据路径取获取鸢尾花数据
>>>print(train_path)
C:\Users\27437\.keras\datasets\iris_training.csv- 导入鸢尾花数据,并进行特定值、特定行和列的取样
import tensorflow as tf
import pandas as pd # 导入pandas库,如果没有可以看我的第一篇文章,后面有介绍如何导入该库
df = pd.read_csv('iris_training.csv',header=None,index_col=False) # 导入鸢尾花数据,注意一定要将数据放在函数的文件夹下,这份数据我剔除了第一行,只是为了少使用其他库的代码- 开始进行数据采样(可以看到,这是个120X5行的数据)
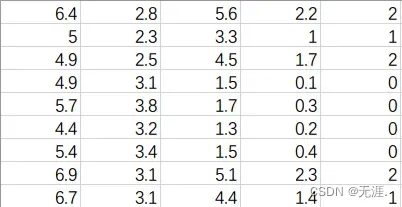
import tensorflow as tf
import pandas as pd
df = pd.read_csv('iris_training.csv',header=None,index_col=False) # 导入鸢尾花数据
tf1 = tf.constant(df.values) # 讲数据转化为一个 120X5 的张量
print(tf1[1,1]) # 取出(1,1)处的数据
print(tf1[1][1])# 取出(1,1)处的数据,可以看出两者表达一直,但我们通常使用前者
print(tf1[0:3,1:4]) # 第0~2行,第1~3列的数据output:
>>>print(tf1[1,1]) # 取出(1,1)处的数据
tf.Tensor(2.3, shape=(), dtype=float64)
>>>print(tf1[1][1])# 取出(1,1)处的数据,可以看出两者表达一直,但我们通常使用前者
tf.Tensor(2.3, shape=(), dtype=float64)
>>>print(tf1[0:5:2,:]) # 第0~4行步长为2的所有行
tf.Tensor(
[[6.4 2.8 5.6 2.2 2. ]
[4.9 2.5 4.5 1.7 2. ]
[5.7 3.8 1.7 0.3 0. ]], shape=(3, 5), dtype=float64)
>>>print(tf1[0:3,1:4]) # 第0~2行,第1~3列的数据
tf.Tensor(
[[2.8 5.6 2.2]
[2.3 3.3 1. ]
[2.5 4.5 1.7]], shape=(3, 3), dtype=float64)
-
gather()
tf.gather(params,axis,indices);第一个参数传入张量;第二个参数是指定取第几个轴(0代表行,1代表列);第三个参数传入数值索引;
- 代码示例(以鸢尾花为例;取第0、3、4行的数据)
import tensorflow as tf
import pandas as pd
df = pd.read_csv('iris_training.csv',header=None,index_col=False) # 导入鸢尾花数据
tf1 = tf.constant(df.values) # 讲数据转化为一个 120X5 的张量
tf2 = tf.gather(tf1,axis=0,indices=[0,3,4])output:
>>>print(tf2)
tf.Tensor(
[[6.4 2.8 5.6 2.2 2. ]
[4.9 3.1 1.5 0.1 0. ]
[5.7 3.8 1.7 0.3 0. ]], shape=(3, 5), dtype=float64)
鸢尾花数据链接
链接:https://pan.baidu.com/s/1RsCOzFI6tax210qEpgLUcA?pwd=ppnb
提取码:ppnb
文章出处登录后可见!