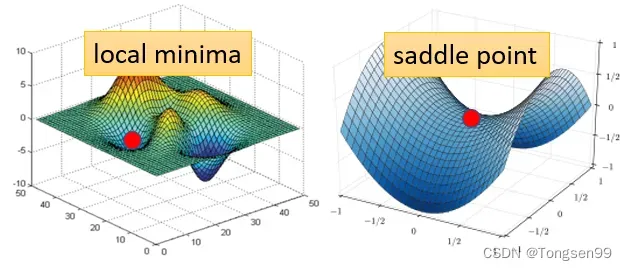
局部极小值(Local Minima)与鞍点(Saddle Point)
Critical Point:梯度(gradient)为0的点
- local minima:局部极小值
如果卡在local minima,那可能就没有路可以走了。 - saddle point:鞍点
如果卡在saddle point,saddle point旁边还是有路可以走的。
判断
如何判断?
- 考察
附近Loss的梯度→泰勒展开→海塞矩阵
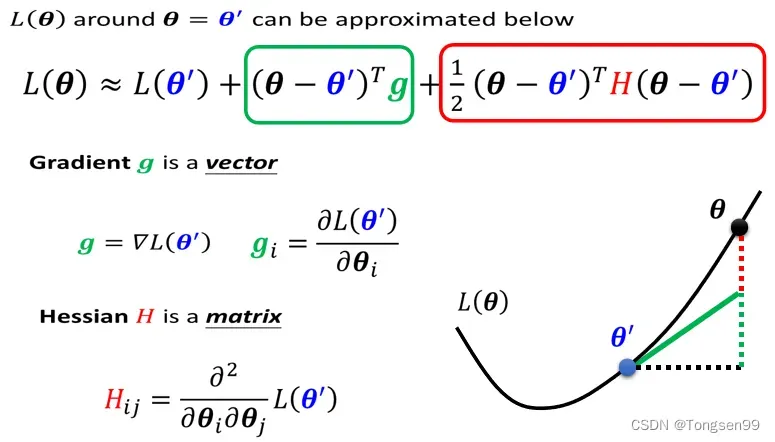
- 第一项中,
,当
很近的时候,
很靠近。
- 第二项中,
代表梯度(一阶导数),可以弥补
之间的差距。
表示
个component,就是
的第
- 第三项中,
表示海塞矩阵,是
在Critical point附近时:第二项为0,根据第三项来判断→则只需考察H的特征值。
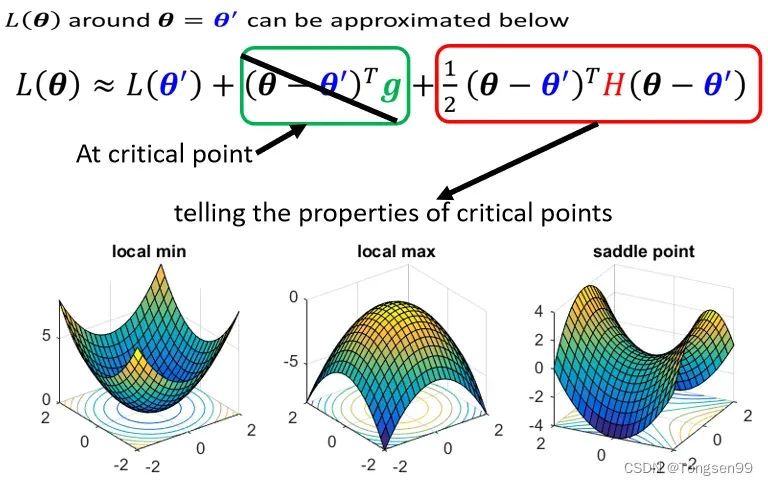
- 如果所有eigen value(特征值)都是正的,H是positive definite(正定矩阵),此时就是local minima
- 如果所有eigen value都是负的,H是negative definite,此时是local maxima
- 如果eigen value有正有负,那就代表是saddle point

- 令特征值小于0,得到对应的特征向量
,在
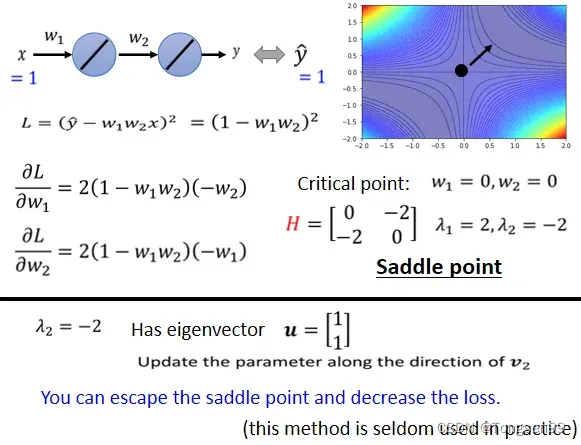
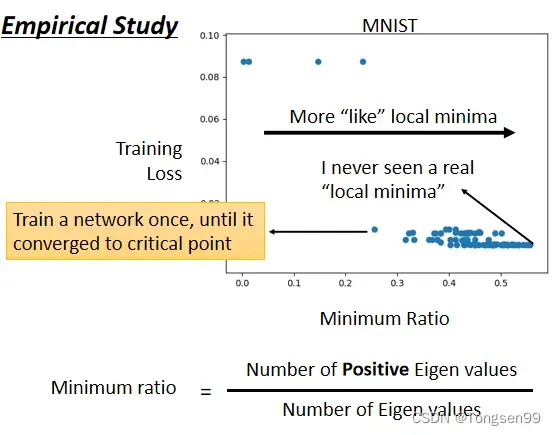
- Local Minima比Saddle Point少
批次(Batch)与动量(Momentum)
Optimization with Batch
-
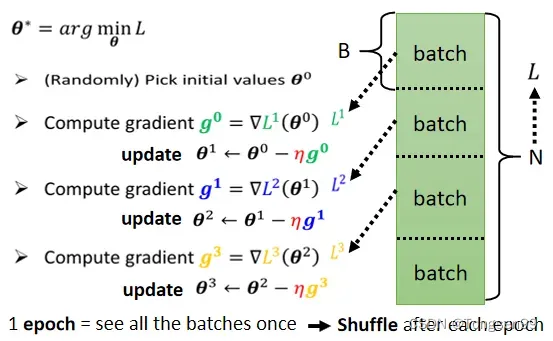
根据计算梯度的样本个数,可分为批量梯度下降(全部样本,batch size=N)、小批量梯度下降(分为batch个数的样本)、随机梯度下降(单个样本,batch size=1)。
-
所有的 batch 经过一遍,叫做一个epoch。
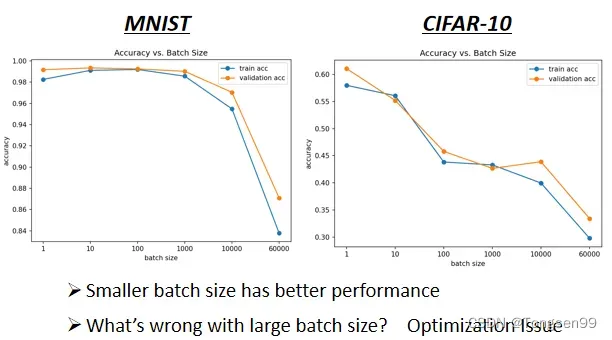
Small Batch v.s. Large Batch

- 左边蓄力时间长,但是精准有效
- 右边冷却时间短,但是比较noisy(其实noisy的gradient反而可以帮助 training)
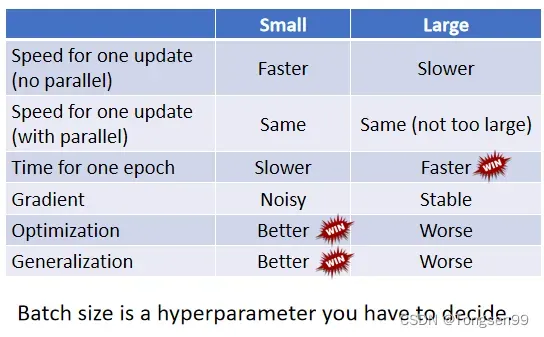
- batch size从1到1000,each update所需要的时间几乎是一样的。
- 增加到 10000,乃至增加到60000的时候,一个batch(一次update)所要耗费的时间,确实随着batch size的增加而逐渐增长。
原因:
- 有GPU可以做并行运算。
- GPU并行运算的能力还是有极限的,当batch size非常非常巨大的时候,GPU在跑完一个 batch计算出gradient所花费的时间,还是会随着batch size的增加而逐渐增长。
对总时间的影响
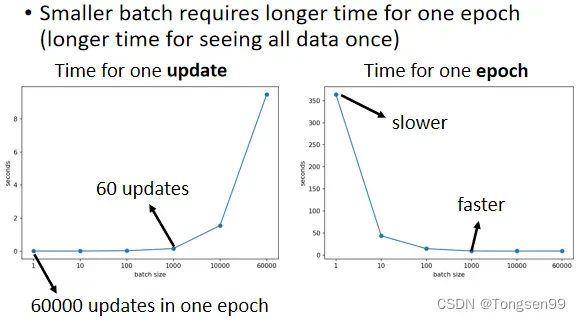
- for one update:small batch size更快
- for one epoch:large batch size更快(因为有GPU可以做并行运算)
small batch size的优势
small batch size优势1:在更新参数时会有noisy⇒有利于训练
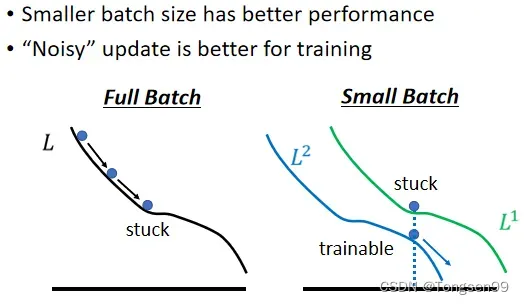
- 不同的batch求得的Loss略有差异,有时候可以避免局部极小值“卡住”
small batch size优势2:可以避免Overfitting⇒有利于测试(Testing)
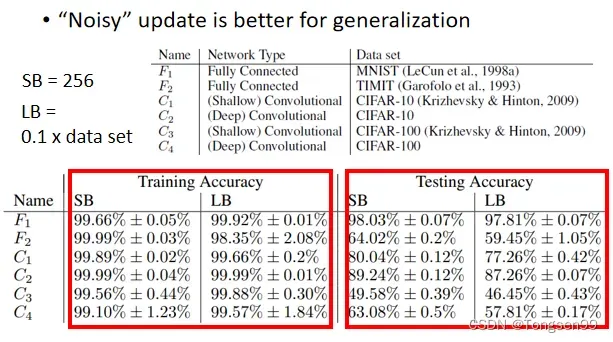
Batch总结
- batch size是一个需要调整的参数,它会影响训练速度与优化效果。
Optimization with Momentum
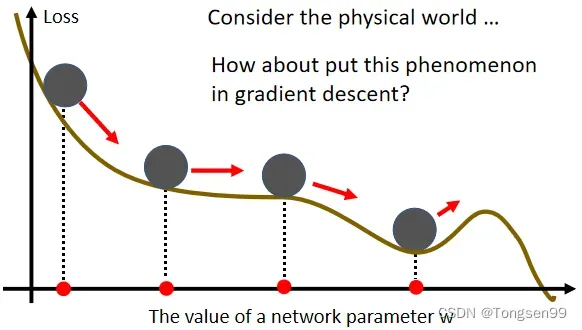
Vanilla Gradient Descent(普通梯度下降)
- 只考虑梯度的方向,向反方向移动。
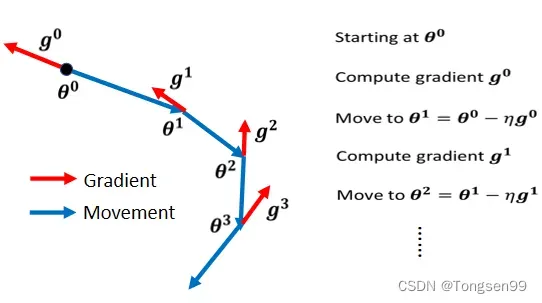
Gradient Descent+Momentum(考虑动量)
- 综合梯度+上一步的方向。
所谓的Momentum,update 的方向不是只考虑现在的gradient,而是考虑过去所有gradient的总和。
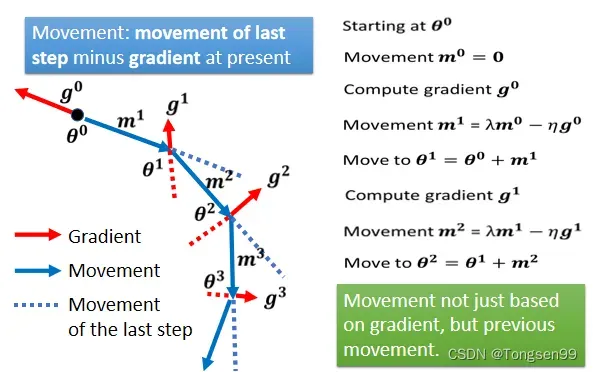
自动调整学习速率(Learning Rate)
- 问题1:training stuck ≠ small gradient⇒Loss不再下降时,未必说明此时到达Critical Point,梯度可能还很大。
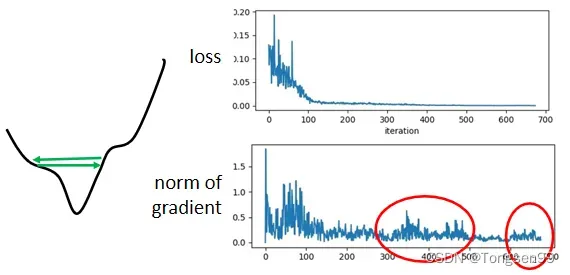
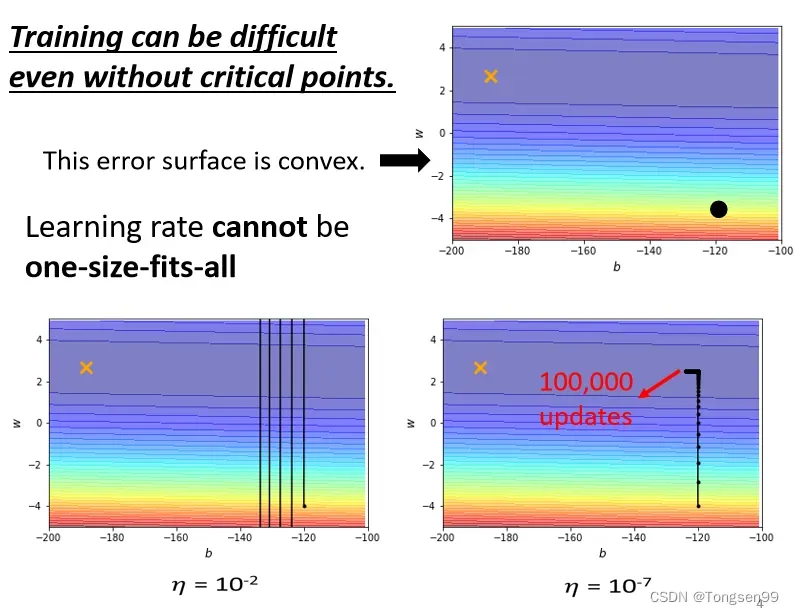
- 问题2:如果使用“固定的”学习率,即使是在“凸面体”的优化,都会让优化的过程非常困难⇒需要客制化“学习率” ⇒不同的参数需要不同的学习率。
- 较大的学习率:Loss在山谷的两端震荡而不会下降。
- 较小的学习率:梯度较小时几乎难以移动。
客制化“学习率”
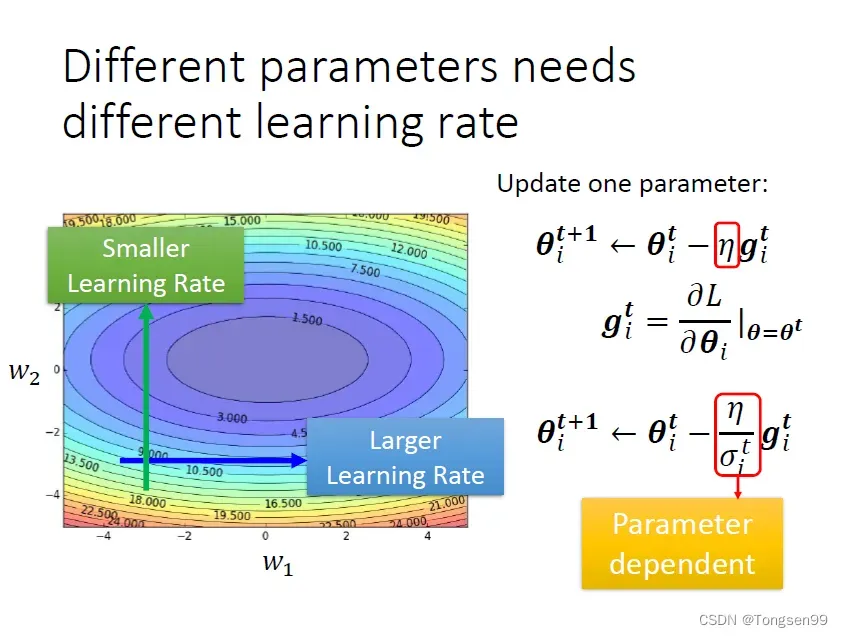
根据参数此时的实际情况,调整的大小,实现对参数
的更新。
- 基本原则:
- 某一个方向上gradient的值很小,非常平坦⇒learning rate调大一点,
- 某一个方向上非常陡峭,坡度很大⇒learning rate可以设得小一点
- 求取
的方式:Root Mean Square(均方根)
Adagrad(自适应学习率梯度下降)
- 考虑之前所有的梯度大小⇒对本次及之前计算出的所有梯度求均方根,然后每个参数的学习率都除上该均方根。
普通梯度下降为:
是一个参数
Adagrad可以做的更好:
:对本次及之前所有梯度求得的均方根。对于每个参数都是不一样的。
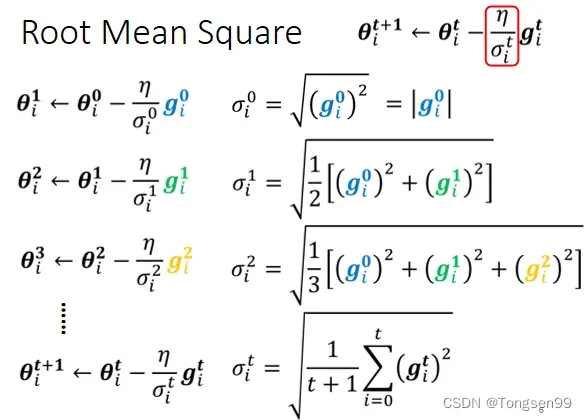
- 矛盾:在 Adagrad 中,当梯度越大的时候,步伐应该越大,但下面分母又导致当梯度越大的时候,步伐会越小。
- 缺陷:不能“实时”考虑梯度的变化情况。
RMSProp
- 调整当前梯度与历史梯度的权重。
添加参数:
- α设很小趋近于0,就代表这一步算出的
- α设很大趋近于1,就代表现在算出来的
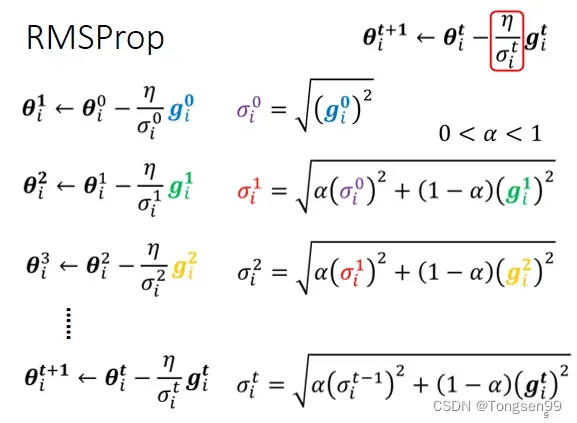
最常用的策略:Adam=RMSProp+Momentum
Learning Rate Scheduling⇒让Learning Rate与 “训练时间”有关
- Learning Rate Decay:随着时间不断进行,随着参数不断update,
越来越小
- 黑科技:Warm Up⇒让learning rate先变大后变小。
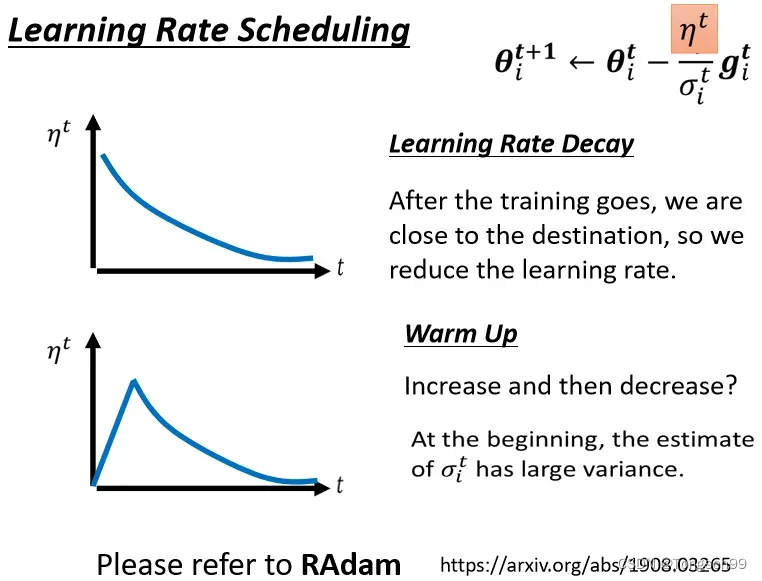
解释:指示某一个方向它到底有多陡/多平滑,这个统计的结果,要看足够多的数据以后才精准,所以一开始我们的统计是不精准的。一开始learning rate比较小,是让它探索收集一些有关error surface的情报,在这一阶段使用较小的learning rate,限制参数不会走得离初始的地方太远。等到
统计得比较精准以后再让learning rate慢慢爬升。
- 补充:RAdam
将Error Surface“铲平”⇒Batch Normalization(批次标准化)
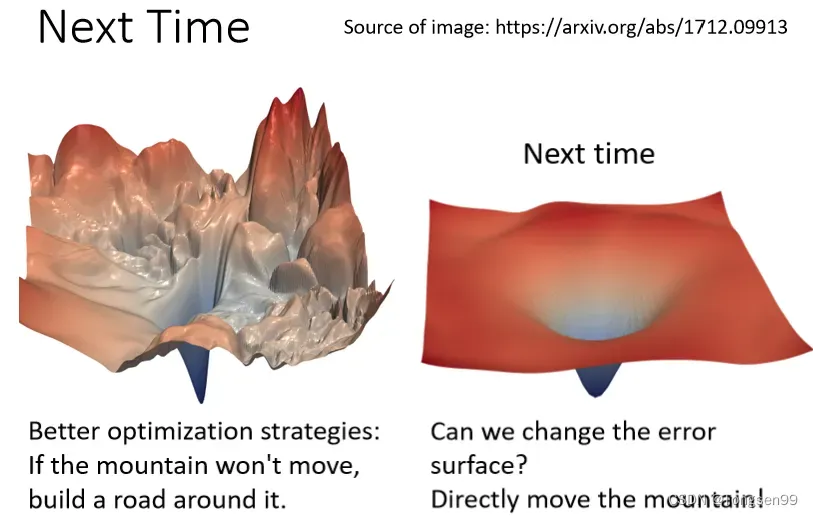
- 不同的参数发生变化,引起Loss变化的程度不同。
的值很小时,当参数
有一个很小的变化,对
的影响很小,从而对Loss的影响也比较小。
的值很大时,当参数
有一个同样大小的变化,对
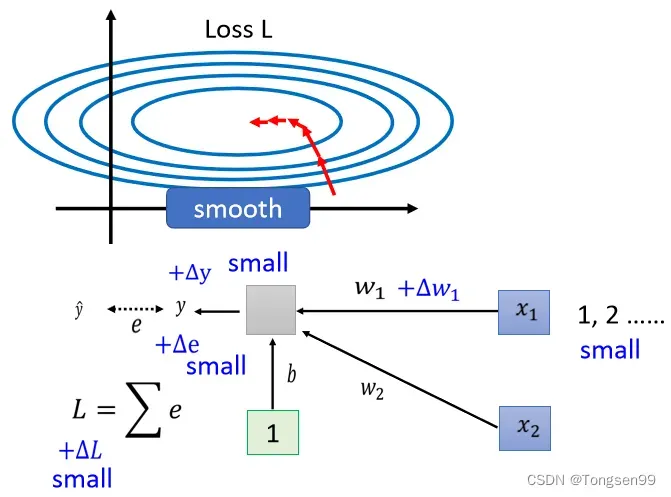
标准化:类似于标准正态分布过程,将这组数据处理成均值为0,方差为1。。
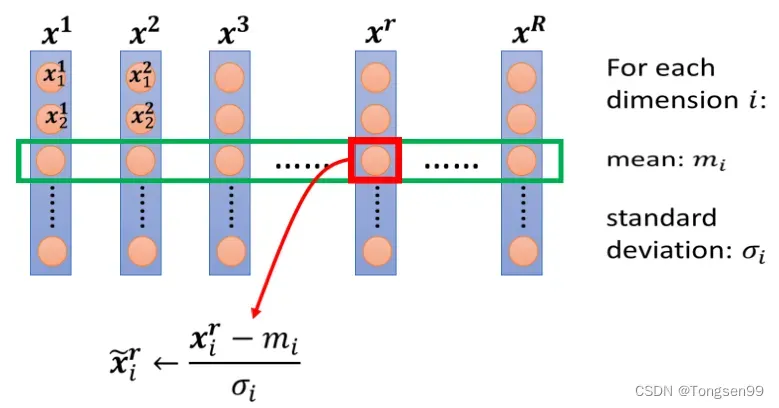
- 在深度学习中,每一层都需要一次Normalization。
经过
矩阵后,
,
数值的各维度分布仍然有很大的差异,要train第二层的参数
也会有困难。所以需要对
或者
进行Normalization。
- 如果选择的是 Sigmoid,那可能比较推荐对
做Feature Normalization,因为Sigmoid在0附近斜率比较大,所以如果你对
- 通常而言,Normalization放在activation function之前或之后都是可以的。
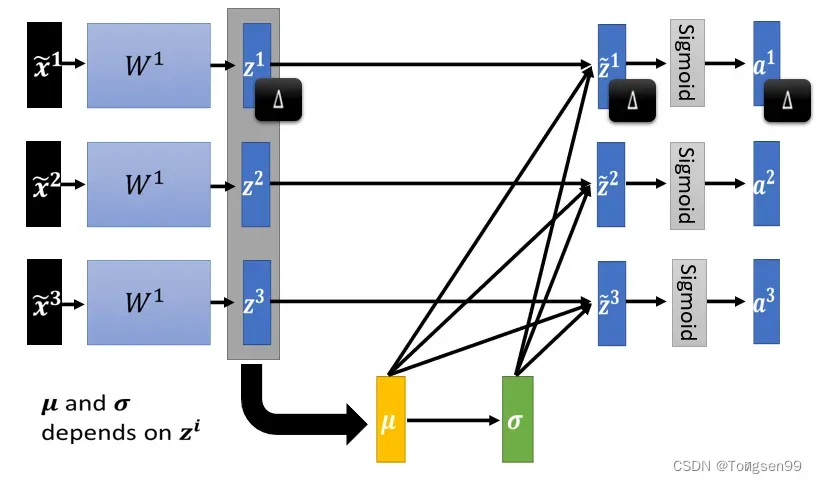
Batch Normalization:实际上做Normalization时,只能考虑有限数量的数据⇒考虑一个Batch内的数据⇒近似整个数据集。
-
Batch Normalization适用于batch size比较大时。其中data可以认为足以表示整个数据集的分布,从而,将对整个数据集做Feature Normalization这件事情,改成只在一个batch中做Feature Normalization作为近似。
-
“还原”:引入向量
,将原本被标准化到
的各维度数据恢复到某一分布。
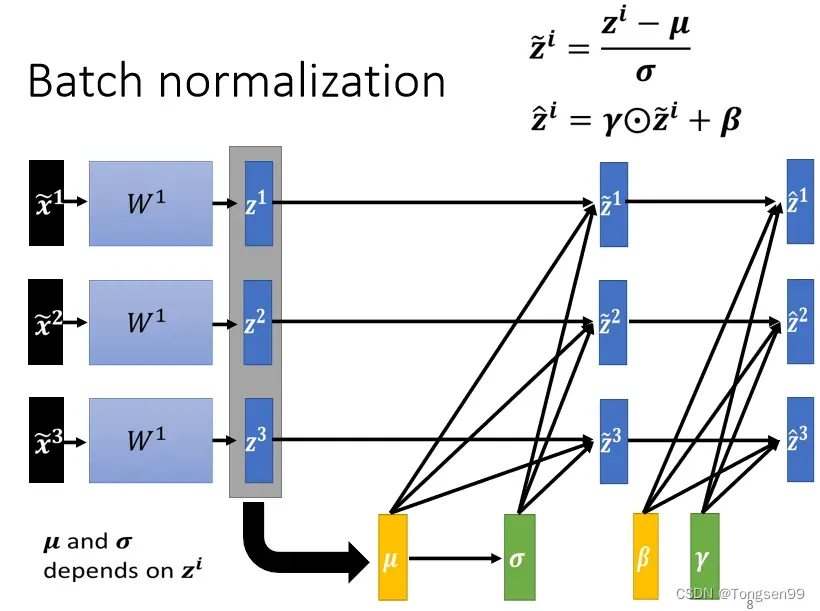
-
做Normalization以后
平均就一定是 0,可以视作是给network一些限制,也许这个限制会带来什么负面的影响,因而进行“还原”操作,让模型自己学习
,
。
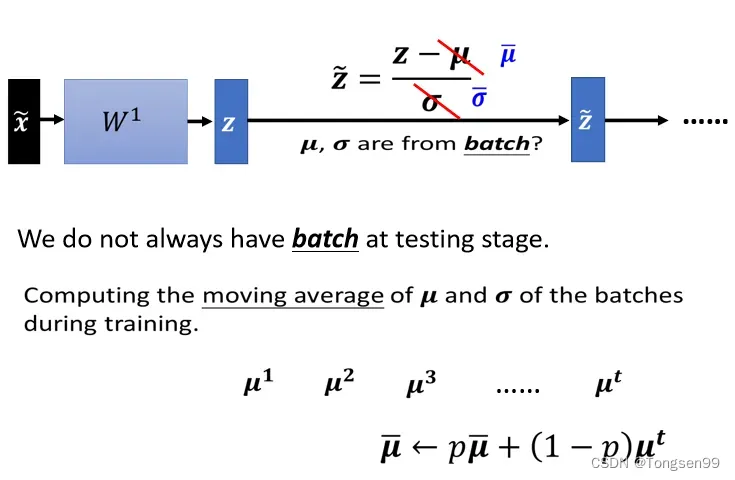
-
训练时:初始将
问题:Testing开始的时候没有足够的数据,无法得到,
,也就无法进行Normalization。
Loss of Classification
Classification as Regression
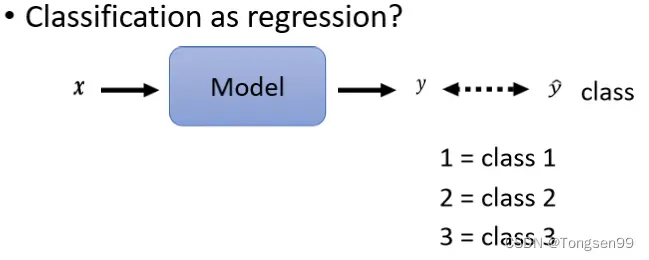
- 有一个可能,我们其实可以把Classification当作是Regression来看。
- 这个方法只适合定序数据,即数字可以表示个体在有序状态中所处的位置,比如此时的假设意味着class1跟class2比较像,跟class3比较不像。但不适合定类数据,即数字仅用于区分类别,没有序次关系。
Class as one-hot vector
- 在做分类问题的时候,比较常见的做法是把Class用one-hot vector来表示。

- 其中,任何两个分类的距离都相同。
产生多个数值
- 怎么产生多个数值呢?⇒把本来output一个数值的方法重复多次。
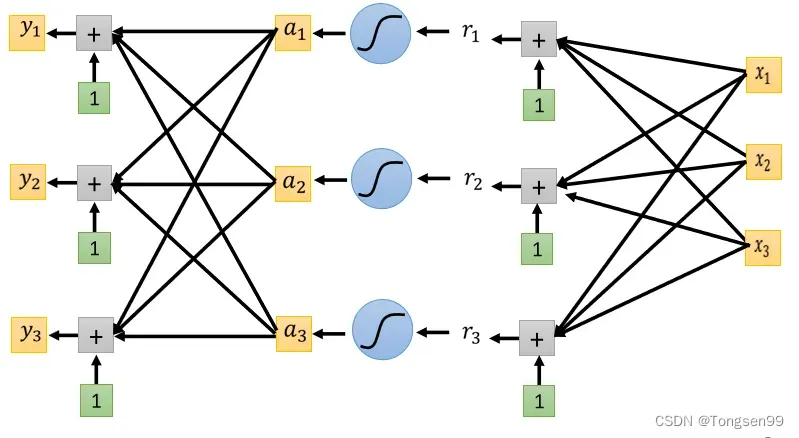
Classification with softmax
- 我们的目标只有0和1,而
- 输出值变成0到1之间。
- 输出值的和为1。
- 原本大的值和小的值之间的差距更大。
如果只有两个class⇒既可以直接套用softmax这个function,但更常用的是sigmoid(这两件事情是等价的)。
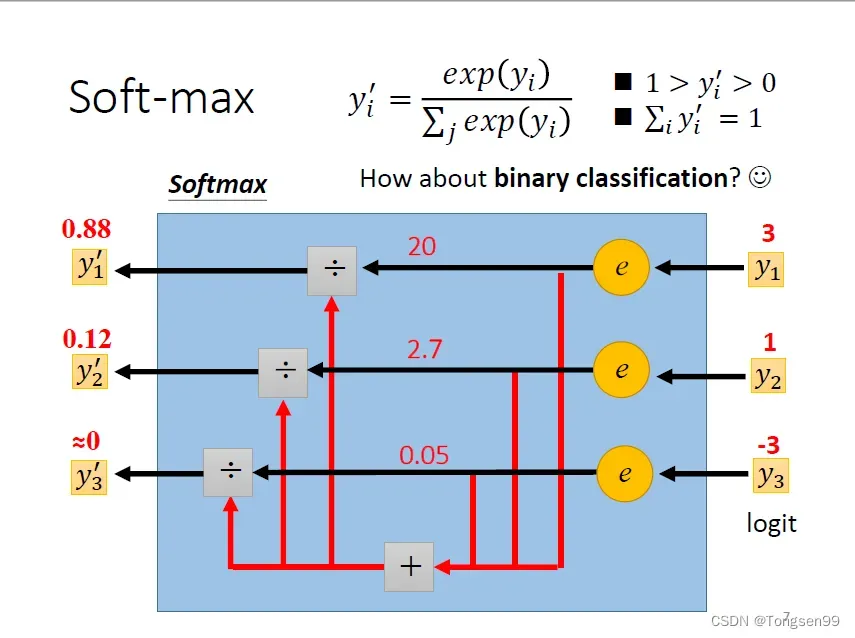
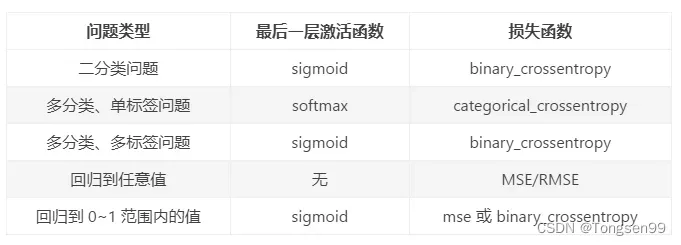
Loss of Classifacation
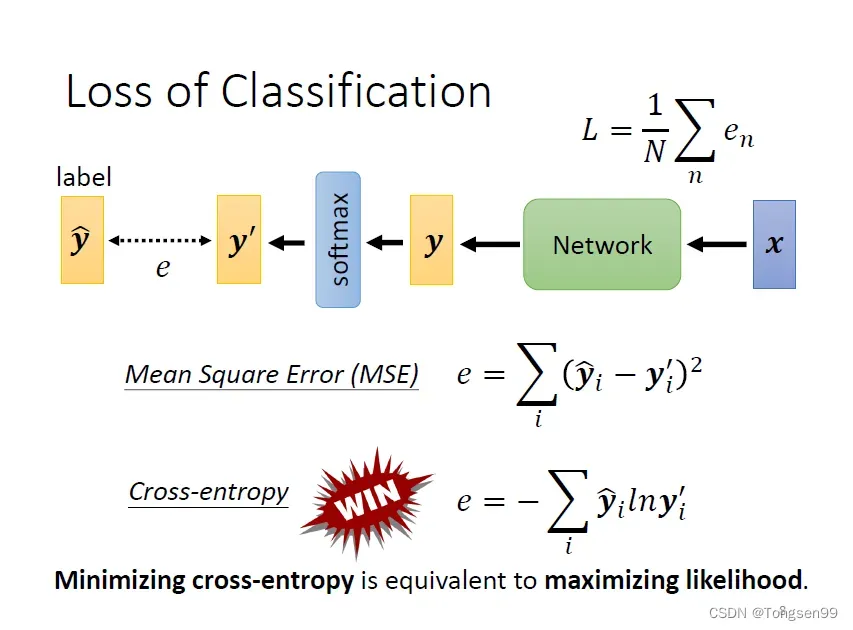
- MSE,Cross-entropy都可以减小
和
之间的差距
。
- Cross-entropy比MSE更加适用于分类问题。
- 在Pytorch中,softmax被内建在Cross-enrtopy损失函数中(捆绑使用)。
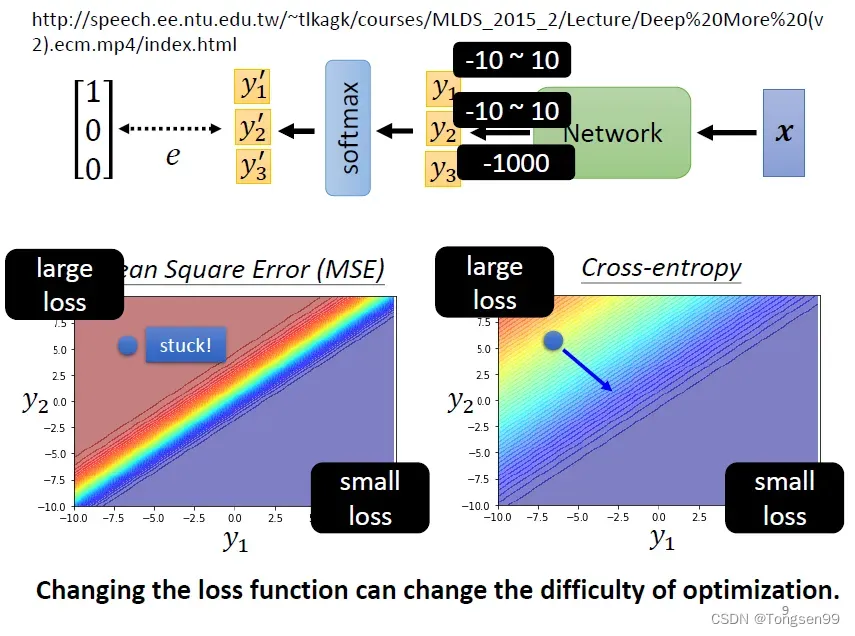
- 使用MSE时,左上角的位置虽然Loss很大,但梯度平坦(趋近于0),就无法用gradient descent顺利走到右下角,难以优化。
- 而Cross-entropy则更易收敛⇒改变Loss函数,可以影响训练的过程,改变optimization的难度。
文章出处登录后可见!