track_sequence_anomaly_detection
由时间空间成对组成的轨迹序列,通过循环神经网络,自编码器,时空密度聚类完成异常检测
1.rnn
word embedding预训练时空点词向量,通过rnn预测下一个时空点的概率分布,计算和实际概率分布的kl离散度,kl距离越大异常分越高
执行代码
python data_preprocessing.py
python data_loader.py
python pre_embedding.py
python main.py
python predict.py
轨迹数据格式:hour_location hour_location hour_location …
[1] 6_10101 7_10094 8_10096 9_10102 10_10097
[2] 6_10094 8_10103 10_10101 11_10103 11_10095 14_10097
[3] 12_10094 12_10094 12_10097 13_10096 13_10094 14_10097 16_10096 18_10102
轨迹检测
[×]异常轨迹,[ ]正常轨迹
请输入轨迹序列:7_10106 7_10096 8_10095 8_10095 8_10100 9_10102 11_10101 11_10104 12_10103 12_10104 12_10097 13_10097 14_10094 15_10095 15_10103 15_10104 16_10097 17_10094 17_10094 17_10096
[ ] 交叉熵:7.609000205993652, kl离散度:7.873, 移动轨迹:['7_10106'] => 7_10096
[ ] 交叉熵:7.607999801635742, kl离散度:8.403, 移动轨迹:['7_10106', '7_10096'] => 8_10095
[ ] 交叉熵:7.60699987411499, kl离散度:8.662, 移动轨迹:['7_10106', '7_10096', '8_10095'] => 8_10095
[ ] 交叉熵:7.572999954223633, kl离散度:9.714, 移动轨迹:['7_10106', '7_10096', '8_10095', '8_10095'] => 8_10100
[ ] 交叉熵:7.599999904632568, kl离散度:10.423, 移动轨迹:['7_10096', '8_10095', '8_10095', '8_10100'] => 9_10102
[ ] 交叉熵:7.598999977111816, kl离散度:9.946, 移动轨迹:['8_10095', '8_10095', '8_10100', '9_10102'] => 11_10101
[ ] 交叉熵:7.5289998054504395, kl离散度:9.099, 移动轨迹:['8_10095', '8_10100', '9_10102', '11_10101'] => 11_10104
[ ] 交叉熵:7.59499979019165, kl离散度:10.283, 移动轨迹:['8_10100', '9_10102', '11_10101', '11_10104'] => 12_10103
[ ] 交叉熵:7.520999908447266, kl离散度:8.919, 移动轨迹:['9_10102', '11_10101', '11_10104', '12_10103'] => 12_10104
[ ] 交叉熵:7.453000068664551, kl离散度:8.242, 移动轨迹:['11_10101', '11_10104', '12_10103', '12_10104'] => 12_10097
[ ] 交叉熵:7.599999904632568, kl离散度:10.468, 移动轨迹:['11_10104', '12_10103', '12_10104', '12_10097'] => 13_10097
[ ] 交叉熵:7.567999839782715, kl离散度:9.526, 移动轨迹:['12_10103', '12_10104', '12_10097', '13_10097'] => 14_10094
[×] 交叉熵:7.609000205993652, kl离散度:10.895, 移动轨迹:['12_10104', '12_10097', '13_10097', '14_10094'] => 15_10095
[ ] 交叉熵:7.5970001220703125, kl离散度:9.827, 移动轨迹:['12_10097', '13_10097', '14_10094', '15_10095'] => 15_10103
[ ] 交叉熵:7.546000003814697, kl离散度:9.446, 移动轨迹:['13_10097', '14_10094', '15_10095', '15_10103'] => 15_10104
[ ] 交叉熵:7.548999786376953, kl离散度:9.49, 移动轨迹:['14_10094', '15_10095', '15_10103', '15_10104'] => 16_10097
[ ] 交叉熵:7.585999965667725, kl离散度:10.284, 移动轨迹:['15_10095', '15_10103', '15_10104', '16_10097'] => 17_10094
[ ] 交叉熵:7.455999851226807, kl离散度:8.381, 移动轨迹:['15_10103', '15_10104', '16_10097', '17_10094'] => 17_10094
[ ] 交叉熵:7.570000171661377, kl离散度:9.628, 移动轨迹:['15_10104', '16_10097', '17_10094', '17_10094'] => 17_10096
2.auto_encoder
时空维度展开记录出现次数,转tfidf,自编码预测复现损失MAE,复现损失越大异常分越高
执行代码
python data_preprocessing.py
python main.py
python predict.py
轨迹检测
cardno,loss
be4fqkgr66n89gdna5cg,0.000996691407635808
be4d5d0r66n89gdldnj0,0.0009965329663828015
be4ct7or66n89gdl8760,0.000997029128484428
be4d12or66n89gdlat3g,0.0010041424538940191
be4d4ogr66n89gdldac0,0.0009971902472898364
be4fdogr66n89gdn0rh0,0.0009968323865905404
be4crt8r66n89gdl79cg,0.0009975525317713618
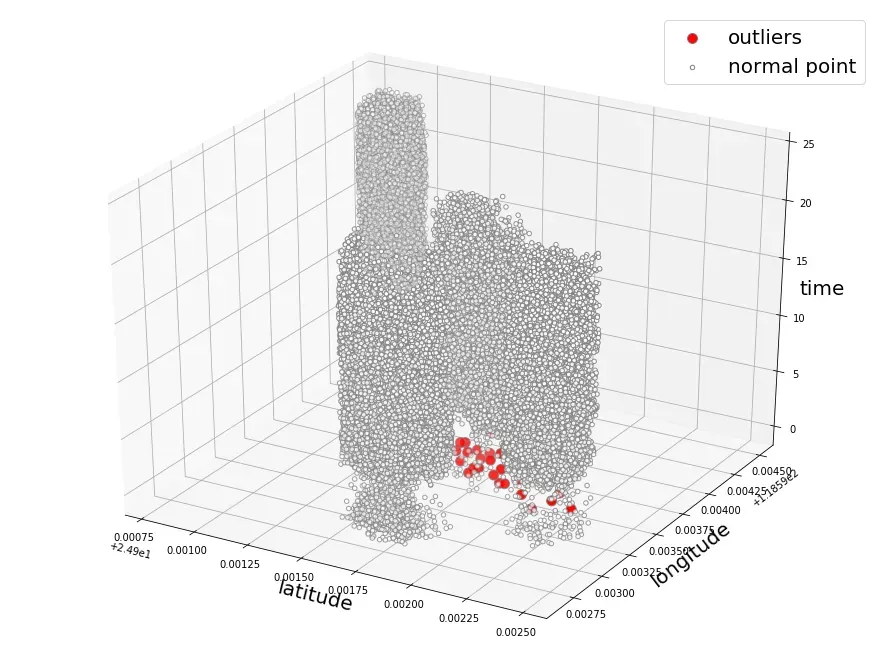
2.st-dbscan
以地理位置距离作为半径,时间范围作为高,在空间画圆柱,进行密度聚类检测异常点。使用KDTree,BallTree,Faiss进行近邻检索加速。
执行代码
python stdbscan.py
python stdbscan_fast.py --tim 0.4 --geo 30 --min_samples 20 --method kdtree
轨迹检测
版权声明:本文为博主newlw原创文章,版权归属原作者,如果侵权,请联系我们删除!