🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝
🥰 博客首页:knighthood2001
😗 欢迎点赞👍评论🗨️
❤️ 热爱python,期待与大家一同进步成长!!❤️
深度学习的基本原理其实与人工神经网络的思想是一致的,而人工神经网络是从信号处理角度对于人的大脑神经元网络的抽象模型。简单来说,在一个系统中,输入信号通过某一层处理之后输出了另一个信号, 当输入信号和输出信号之间互相连接的处理层数更多、结构更复杂时,即可将其看作一个人工神经网络。
这样也就反映出了深度学习同样是一个处理单元串接另外一个处理单 元的结构,这种结构与人的神经元之间进行神经冲动的传播形式是一样的。 因此,我们将深度学习中的每一个处理单元称为一个层,通过不同种类的层之间相互堆叠,形成了一个完整的、能够实现一定功能的复杂网络,这个比传统的人工神经网络更为复杂的网络便是深度学习神经网络。
因此,我们通过对每一个深度学习网络的层进行抽象,由深度学习库来实现每一个层,并提供给用户进行使用,然后我们就可以像搭积木一样来构建属于我们自己的深度学习神经网络了。当前的绝大多数的深度学习框架也都是按照这个思路来实现的,keras也不例外。
此外,对于一个深度学习神经网络,无论简单的也好,复杂的也罢,都是通过一个个神经网络层连接起来的,笔者争对一些常用的神经网络层进行简单的介绍。
目录
1、全连接层
全连接层的每一个节点都与上一层所有的节点相连,从而把前边提取到的特征综合起来。
函数定义
在keras中全连接层即Dense层,其完整的定义如下:
keras.layers.Dense(units,activation=None,use_bias=True,kernel_initializer='glorot_ uniform',bias_initializer='zeros',kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,kernel_constraint=None,bias_constraint=None,**kwargs)
参数含义
units:是一个正整数,表示输出空间的维度;
activation=None:激活函数,默认不使用激活函数,即线性激活,输入与输出相同;
use_bias=True:布尔型变量,代表该层是否使用偏置向量;
kernel_initializer='glorot_uniform':kernel权值矩阵的初始化器;
bias_initializer='zeros':偏置向量的初始化器;
kernel_regularizer=None:运用到kernel权值矩阵的正则化函数;
bias_regularizer=None:运用到偏置向量的正则化函数;
activity_regularizer=None:运用到输出结果的正则化函数;
kernel_constraint=None:运用到kernel权值矩阵的约束函数;
bias_constraint=None:运用到偏置向量的约束函数。对于序列模型的第1层的Dense层,需要指定输人数据的维度,即input_shape参数。
Dense层在Keras中实现以下操作:
output = activation(input·kernel + bias)
其中,activation是按逐个元素计算的激活函数;kernel是由网络层创建的权值矩阵,其与输入该层的input矩阵进行点乘;bias是由层创建的偏置向量(仅在 use_bias 为 True 时适用)。这些都是 `Dense` 的属性。
Input_shape:N-D 张量,形状:(batch_size, ..., input_dim)。最常见的情况是形状为 (batch_size, input_dim) 的 2D 输入。Output_shape:N-D 张量,形状:(batch_size, ..., units)。例如,对于形状为 (batch_size, input_dim) 的 2D 输入,输出的形状为 (batch_size, units)。
举例
import keras.layers
import tensorflow as tf
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(16,)))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dense(32))
print(model.output_shape)创建一个“Sequential”模型并添加一个 Dense 层作为第一层。
现在模型将采用形状 (None, 16) 的输入数组和形状 (None, 32) 的输出数组。
注意,在第一层之后,你不需要再指定输入的大小了。
2、二维卷积层
在对图像数据进行处理时,用卷积进行处理具有天然代势,因此应用最多的神经网络层主要就是卷积层。在卷积层中使用参数共享可以用来控制参数的数量,因此卷积层不像全连接层那样具有非常多的参数,可以减少过拟合现象,同时也能加快网络中计算的速度。
以卷积层为主的神经网络层即为卷积神经网络(Convolutional Neural Network,CNN).通常的卷积神经网络主要由输入层、卷积层、激活函数、池化层、全连接层等组成,卷积神经网络在图像处理、语音识别等领域具有重要作用。当前主流的人脸识别深度学习神经网络基本都是卷积神经网络。
Keras为我们提供的卷积层不仅有二维卷积层一种,还包括一维卷积层和三维卷积层,同时还有深度方向可分离的卷积层以及反卷积层等。由于一维卷积主要用于时序数据处理,二维卷积用于对图像的空间卷积,三维卷积主要用于对立体空间卷积,因此笔者在这里主要介绍二维卷积。
函数定义
Keras为我们提供的二维卷积即为Conv2D层,其完整的定义如下:
keras.layers.Conv2D(filters,kernel_size,strides=(1, 1),padding='valid', data_format=None,dilation_rate=(1, 1),groups=1,activation=None, se_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros', kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None, kernel_constraint=None,bias_constraint=None,**kwargs)
参数含义
filters:卷积核的个数,即卷积操作后输出空间的维度。
kernel_size: 可以是一个整数,也可以是一个元组,表示卷积窗口的宽度和高度。
strides=(1, 1):可以是一个整数, 也可以是一个元组,表明卷积沿宽度和高度方向的步长,即卷积操作每一步移动的步长。
padding='valid':只能为“valid"或“same”,设置图像在卷积过程中边界像素如何填充。
data_format=None:可以设置为“channels_last" (默认) 或“channels_frst”二者之一,表示输入中维度的顺序。
dilation_rate=(1, 1):可以是一个整数,也可以是一个元组,指定膨胀卷积的膨胀率。
groups=1:一个正整数,指定输入沿通道轴拆分的组数。每个组分别与“过滤器组”过滤器进行卷积。输出是沿通道轴的所有“组”结果的串联。输入通道和“过滤器”都必须能被“组”整除。
activation=None:卷积层要使用的激活函数。默认不激活,输入输出相同,即f(x)=x。
use_bias=True:指定该层是否使用偏置向量。
kernel_initializer='glorot_uniform':kernel权值矩阵的初始化器。
bias_initializer='zeros':偏置向量的初始化器。
kernel_regularizer=None:应用于kernel权重矩阵的正则化函数。
bias_regularizer=None:运用到偏置向量的正则化函数。
activity_regularizer=None:运用到层输出(它的激活值)的正则化函数。
kernel_constraint=None:运用到kernel权值矩阵的约束函数。
bias_constraint=None:运用到偏置向量的约束函数。Input shape: 4+D tensor with shape: `batch_shape + (channels, rows, cols)` if `data_format='channels_first'` or 4+D tensor with shape: `batch_shape + (rows, cols, channels)` if `data_format='channels_last'`. Output shape: 4+D tensor with shape: `batch_shape + (filters, new_rows, new_cols)` if `data_format='channels_first'` or 4+D tensor with shape: `batch_shape + (new_rows, new_cols, filters)` if `data_format='channels_last'`. `rows` and `cols` values might have changed due to padding.
该层创建了filters 个卷积核,使用这些尺寸的卷积核对输入数据进行卷积计算并生成输出数据。每一个卷积核对应一个输出数据,被称为特征图( feature map)。如果使用该层作为模型的第1层,需要提供input_shape参数。例如,输人数据为64×64像素的彩色图片,在data_fomat参数为canels_last (默认值,可不更改)时,该参数值应该设置为input_shape=(64, 64, 3)。
卷积层进行的计算就是对前一层数据做卷积运算,二维卷积层也就是对图像进行卷积运算。假设输入的图像是64 x64大小的RGB彩色图像,则其尺寸大小为(64, 64,3),那么我们就可以通过如下代码实现一个卷积层。
举例
from keras.models import Sequential
from keras.layers import Conv2D
# 产生一个序列模型对象
model = Sequential()
model.add(Conv2D(kernel_size=(9, 9), activation="relu", filters=48, strides=(4, 4), input_shape=(64, 64, 3)))
print(model.output_shape)在上面的代码中我们可以看到,如果卷积层作为输入层的话,需要提前指定输人数据的维度。上述彩色图像是(64, 64, 3),如果将其转换为灰度图像的话,那么输入数据的维度就变成了(64, 64,1)。与此同时,我们给定卷积核的尺寸kermel_size为(9,9),这是卷积层中每一个filter的尺寸,由于经过卷积核得到的特征图都源自这个的卷积核与原图像中9×9的区域做卷积运算,因此该卷积层的感受野为(9×9), strides 参数是(4, 4)。
值得一提的是,卷积核除了具有高度和宽度之外,也具有通道数。例如上面的例子中,我们使用的是RGB图像,对应了3个通道,那么卷积层同样具有3个通道,在卷积计算过程中输人数据分别乘以卷积核对应的RGB图像3个通道的数值,再相加,从而得到输出张量对应位置的数值。
其中activation参数指的是该层的激活函数ReLU是一种常用的激活函数,被称为线性整流函数,该函数具有加快模型训练时收敛速度的优点,其函数形式(如下)很容易理解。
f(x) = max(O,x)
3、池化层
池化层也称为抽样层,是一种在图像的特定范围内聚合不同位置特征的操作。这是因为卷积运算后的图像具有局部特征,并且图像的每个像素区域通常具有很高的相似性。图像区域中的特征平均值或最大值可以用来表示该区域的整体特征,分别称为均值池化和最大池化。这样做不仅可以压缩数据,还会改善结果,使得神经网络不容易发生过拟合。
池化层一般与卷积层结合在一起使用,在卷积层的后面放置一层池化层能够有效减少数据量,起到降采样的作用。因此,这个过程也可以看作对经过卷积层运算之后的结果进行进一步的特征提取与压缩的过程。
典型的池化方式有以下3种。
①均值池化(mean-pooling):选择特定区域中所有值的均值。
②随机池化(stachastic-poling):随机选择特定区域中的任意一个值。
③最大池化(max-poling);选择特定区域中值最大的值。这也是最常用的一种池化方式。
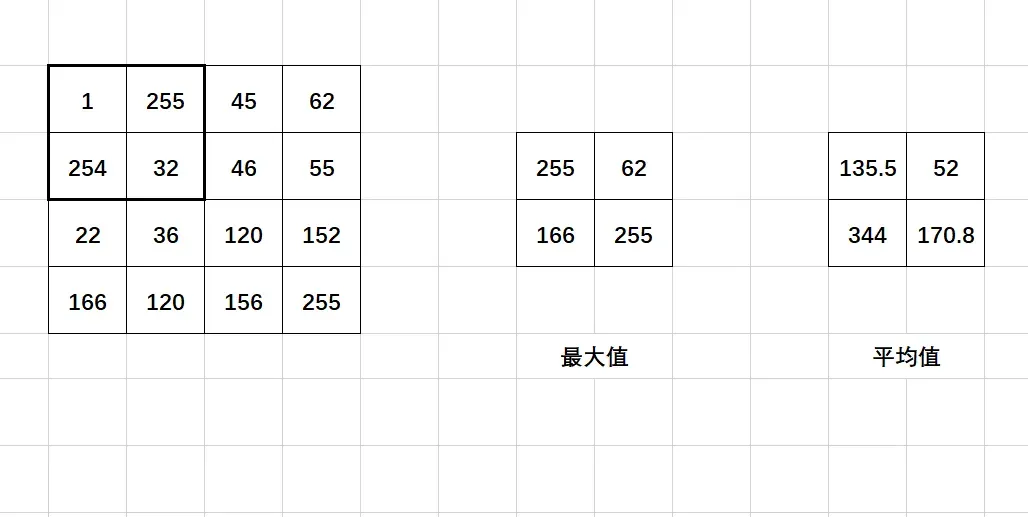
如上图展示了池化过程,池化过程的滑动窗口大小为4×4,从左到右,从上到下依次滑动,在不重叠的情况下,可获得最大池化后的输出结果,获得均值池化的输出结果如上。
通过上面的例子,我们可以看到一个4×4维度的数据,经过池化后变成了2×2的数据,数据得到了进一步的压缩。
使用池化与卷积层进行配合,使用的另一个好处就是具有更好的平移不变性,因为图像平移前后的数据经过池化,数据后的差距可能已经很小了。
函数定义
keras提供了很多种池化层,与卷积层一样,我们在图像处理中同样可以使用二维池化层,其定义如下:
keras.layers.MaxPooling2D(pool_size=(2, 2),strides=None,padding='valid', data_format=None,**kwargs)
参数含义
pool_size=(2, 2):池化窗口的大小,可以是一个整数或者由两个整数组成的元组。默认值为(2, 2)。例如上面,其池化窗口大小就为(2, 2)。如果只使用一个整数,那么两个维度都会使用同样的窗口长度。
strides=None:可以是整数、整数元组或是None,代表池化窗口进行滑动的步长值。池化窗口都是不重复的,默认值None即代表与pool sie 相同,如果进行重叠池化,即相邻池化窗口之间会有重叠区域,则可以自定义此值。
padding='valid':"valid" 或"same"之一。"valid"表示没有填充。"same"导致在输入的左右或上下均匀填充,以使输出具有与输入相同的高宽尺寸。代表池化窗口滑动到图像边界区域时,边界区域被池化窗口覆盖后尚有空余时的处理方式。
data_format=None:输入张量中的维度顺序,是一个字符串,可以设置为“ channels_first”
或“channels_last”之一,代表图像的通道维的位置。channels_last对应于形状为 (batch, height, width, channels)的输入,而 channels_first对应于形状为 (batch, channels, height, width) 的输入。如果您从未设置它,那么它将是“channels_last”。
Input shape: - If `data_format='channels_last'`: 3D tensor with shape `(batch_size, steps, features)`. - If `data_format='channels_first'`: 3D tensor with shape `(batch_size, features, steps)`. Output shape: - If `data_format='channels_last'`: 3D tensor with shape `(batch_size, downsampled_steps, features)`. - If `data_format='channels_first'`: 3D tensor with shape `(batch_size, features, downsampled_steps)`
类似的,二维平均池化定义如下:
keras.layers.AveragePooling2D(pool_size=(2, 2),strides=None,padding='valid',
data_format=None,**kwargs)
举例
演示了在卷积层后面接上一个池化层
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
# 产生一个序列模型对象
model = Sequential()
model.add(Conv2D(kernel_size=(9, 9), activation="relu", filters=48, strides=(4, 4), input_shape=(64, 64, 3)))
# 在一个卷积层后面接上一个池化层
model.add(MaxPooling2D((3, 3), strides=(2, 2), padding='same'))
print(model.output_shape)4、总结
以上只是讲了一部分常见的神经网络层,后续会继续更新该方面知识!!如果觉得笔者写的不错的话,记得支持一下!!
文章出处登录后可见!