每一次epoch的训练过程,总结下来就是:
① 前向传播,求预测值。
② 根据预测值和真实值求loss损失值
③ 反向传播计算梯度
④ 根据梯度,更新参数
代码如下:
# y = 3*x
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[3.0],[6.0],[9.0]])
#设计模型
class LinearModel(torch.nn.Module):
def __init__(self):#构造函数
super(LinearModel,self).__init__()#继承父类的__init__函数
self.linear=torch.nn.Linear(1,1)#1和1分别代表输入维度和输出维度
def forward(self,x):#forward函数是一定要写的
y_pred = self.linear(x)
return y_pred
model = LinearModel()
#设计损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
epoch_list = []
loss_list = []
#training cycle
#Forward、Backward、Update
for epoch in range(10000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)#计算损失值
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()#记得清空,否则就会累加
loss.backward()#自动计算梯度
optimizer.step()#更新w和b的值
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
最终的计算结果为:
w= 3.0
b= 1.0373099001981245e-07
Loss值的更新图如下:
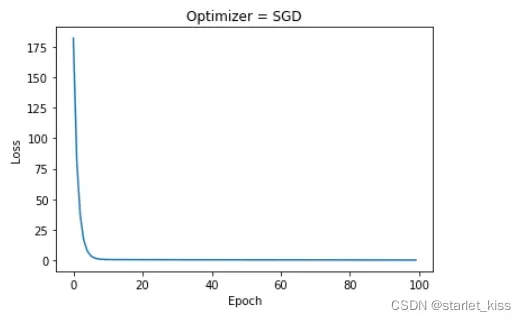
这是优化器取SGD的情况下,下面是优化器取Adam的更新图
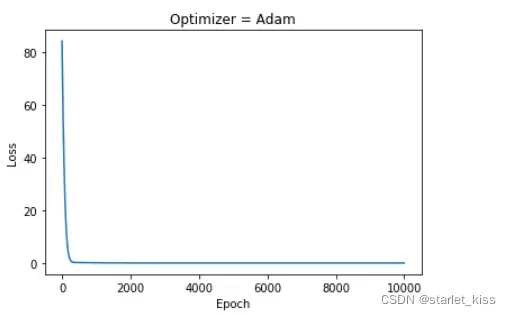
优化器为Adam时,更新过程要比SGD时慢一些。关于其他的优化器,可以自行尝试一下。
努力加油a啊
版权声明:本文为博主starlet_kiss原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/starlet_kiss/article/details/122587995