1.基本信息
2021年A会ICSE论文
作者
- Nan Jiang 普渡大学
- Thibaud Lutellier 滑铁卢大学
- Lin Tan 普渡大学
关键词
automatic program repair(APR), software reliability,NMT模型,JAVA
2.论文概述
motivation
现有的neural machine translation(NMT) techniques有两个主要限制。
- 他们的搜索空间通常不包含正确的fix
- 他们的搜索策略忽略了软件知识,例如严格的代码语法
由于这些限制,现有的基于NMT的技术表现不如最好的基于模板的方法。
solution
提出CURE,一个基于NMT的APR技术,有3个创新点:
- 在APR任务之前,CURE在大型软件代码库上预先训练编程语言(PL)模型,以学习类似开发人员的源代码。
- CURE设计了一种新的代码感知搜索策略,通过关注可编译补丁和长度接近bug代码的补丁,可以找到更多正确的补丁。
- CURE使用子词标记技术生成更小的搜索空间,其中包含更多正确的修复。
result
CURE正确地修复了57个Defects4J的bug和26个QuixBugs里的bug,在这两个基准数据库上超过了所有现有的APR技术。
3.Introduction
PS:刚开始接触自动代码修复,很多东西不是很懂,还在学习。
NMT模型是什么?
NMT模型利用深度学习技术将有bug的源代码自动编码为潜在空间的中间表示,然后将编码后的表示解码为目标正确的代码。
对于search-based APR approach (including NMT-based techniques),产生一个正确的fix,需要满足两个条件:
- 正确的修复必须在搜索空间中
- 搜索策略必须在合理的时间内有效
NMT模型面临的挑战
- 1.源代码的严格语法对于NMT模型来说是很难学习的。
原因: - 现有技术从错误代码片段和相应的fix的正确代码片段中学习(通常每个错误几行到几十行),不使用整个源代码库(通常每个项目数百万行代码)。因此,现有的基于NMT的APR方法对编程语言的严格语法和开发人员如何编写代码的总体知识有限。
- 不了解开发人员如何编写代码,现有的基于NMT的APR技术也会生成可编译但明显不正确的补丁,因为它们看起来不像开发人员编写的代码。
- 2.无限数量的可能标识符使NMT技术要处理大量的词汇。
- 如果使用word-level tokenization,其中词汇表包含NMT模型识别的所有唯一标记。
- 考虑到NMT体系结构的复杂性,基于NMT的APR模型使用庞大的词汇表在计算上过于昂贵。
- 然而,由于词汇量有限,他们的搜索空间并不包含所有正确的fix。
our approach
Programming language models
为了帮助NMT模型学习类似开发人员的源代码(即,不仅是可编译的,而且类似于程序员编写的代码)。本文将预训练和微调工作流程应用于APR任务。作者参考预训练语言模型在NLP中的有效应用,提出了在NMT体系结构中加入一个预先训练过的软件代码语言模型,称为编程语言(PL)模型,以创建一个新的APR体系结构。
Code-aware search strategy
现有的Beam search搜索策略,在APR的NMT模型中使用需要更大的beam sizes(100-1000)去生成足够的候选patches。然而,对于较大的beam大小,普通的bean search会选择许多坏的补丁,这些补丁要么是不可编译的,要么是长度不正确。
解决:
- 第一:提出并设计了一种有效标识符检查策略来改进vanilla beam search,该策略通过静态分析来识别所有的有效标识符,然后强制beam search只生成具有有效标记的序列。
- 第二:由于我们的训练数据中的正确fix通常与the buggy lines的长度相似,所以我们使用长度控制策略来惩罚过短和过长的序列,以提示CURE生成与the buggy lines长度相似的patches。
(我对长度控制策略有疑问,如下例所示,长度相差较大)
Subword tokenization
以前的工作没有恰当处理合成词(eg.binsearch”作为一个单词,也就是OOV【out of vocabulary words】,而不是把它分解成“bin”和“search”,它们都在词汇表中。),作者提出使用byte-pair encoding(BPE)(一种subword tokenization技术)对复合词和生僻字进行标记,以进一步解决OOV问题。
contribution
- 一种预训练APR PL模型的方法在一个非常大的软件代码库404万methods来自1700个开源项目——用来捕获代码语法和类似开发人员的源代码
- 一个新的APR架构,结合了预先训练的PL模型和NMT架构,以学习代码语法和修复模式
- 一种新的代码感知beam搜索策略,它使用有效标识符检查和长度控制策略来找到更多正确的修复
- 将subword tokenization应用到APR任务中,有效地解决了OOV问题
- 一个新的APR方法,CURE,结合了上面的技术,和它在两个广泛使用的基准测试Defects4J和QuixBugs上的评估,其中CURE修复了最多的bug,分别是57和26个bug,超过了所有现有的APR工具。CURE是第一个基于NMT的方法(首次将NMT模型用于自动代码修复),在Defects4J上优于所有先进的APR方法
4.Approach
为了应对上述挑战,我们设计并应用了三种新技术。
|
| techniques | challenge |
|---|---|
| subword tokenization | improve the search space |
| programming language model | learn developer-like source code and improve patch ranking |
| code-aware beam-search strategy | improve patch ranking and generate more correct patches |
4.1overview
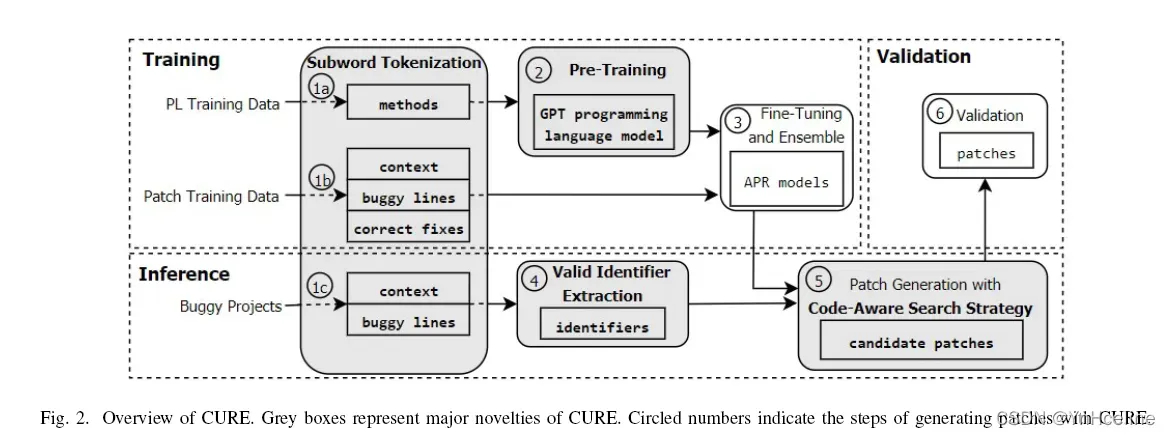
PL training data:open-source Java projects。
Patch training data:从开源项目commit历史中提取的the buggy lines、上下文和正确的fix。
Buggy projects:用户提供一个APR的标准输入,一个有bug的项目和bug的位置。
- 1a:从开源项目中提取method(如何定义method),称为PL训练数据,并对它们进行token,这里用到了subword tokenization。
- 2:CURE使用这些标记化的方法来训练一种new programming language model,该模型可以学习具有正确语法的类似开发人员的源代码。
- 1b:CURE将从开源项目提交历史中提取的the buggy lines、上下文和正确的修复程序(称为补丁训练数据)token为序列;
- 3:利用预训练的PL模型和有buggy的token序列来微调一个APR模型的集合,每个APR模型结合了PL模型和上下文感知的神经机器翻译(CoNuT)模型。
- 1c:在inference阶段,用户提供一个APR的标准输入,一个有bug的项目和bug的位置。CURE token bug和上下文行
- 4:分析源代码以提取the buggy lines范围内的有效标识符列表。
- 5:补丁生成模块使用一种新的代码感知beam搜索策略生成候选补丁列表。
- 6:CURE通过编译和执行补丁项目的测试套件来验证候选补丁。CURE输出可行补丁的列表,供开发人员检查。
4.2 Subword tokenization
为了解决OOV问题,减小词汇量,作者采用了字节对编码(BPE),它是一种无监督学习算法,通过迭代合并最频繁的字节对来找到语料库中最频繁的子词。(拆分合成词)
这是一个例子,图b使用了复制机制,但仍不能产生正确的fix,是因为它只能复制出现在buggy行的token。因为charno是在if行出现的,在if行就被认定为是OOV ,定为unknown,因此在buggy行的token也是unknown,所以复制失败。
4.3 Programming Language Model
为了解决学习developer-like源码的挑战,作者在开源程序上预训练出一个语言模型,称为programming language model (PL model)。
作者使用Generative Pre-trained Transformer (GPT)用于PL建模,因为GPT已被证明可以改进许多不同性的能NLP任务。
对PL模型进行预训练可以将编程语言学习与补丁学习分离开来。好处有两个:
- 首先,GPT学习是无监督的,只需要完整的方法;因此,可以自动准确地提取大量的数据,对其进行训练。
- 其次,在微调期间,APR模型已经知道PL语法(这要归功于PL模型),这使得微调更加高效。
x表示一个method token后形成的一个sequence,PL模型就是最大化平均似然,函数如下: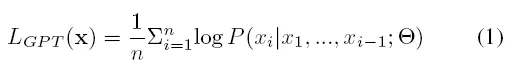
sitar表示PL模型的训练权重矩阵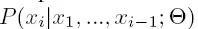
表示下一个token是Xi的概率。
PL模型训练的目标是找到最优的权值sitar,使token序列x1;:::;xn表示项目中的实方法,其LGPT得分高于其他序列。
4.4 Fine-Tuning for APR with a PL Model
作者将CoNuT作为CURE的NMT模型。即overview中“1b”得到的模型。
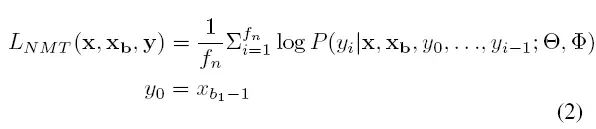
P函数指得是,PL模型和CoNuT模型分别以不同的权重,参与到预测fix中下一个token的过程中,并使得Lnmt最大化平均对数可能性。
微调出的模型是结合之前训练好的PL模型和CoNuT得到的NMT模型。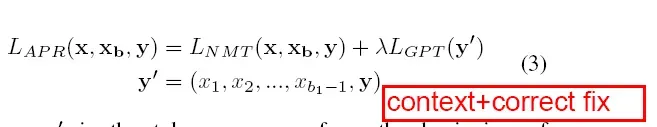
微调阶段的目的是找到对于所有Patch training data中数据最好的参数集sitar和φ去最大化Lapr。
下图是如何生成fix的过程。(需要认真去看论文了解过程)
疑问:编码和阶码的目的是什么?(感觉跟NMT的定义有关,需要仔细去了解下)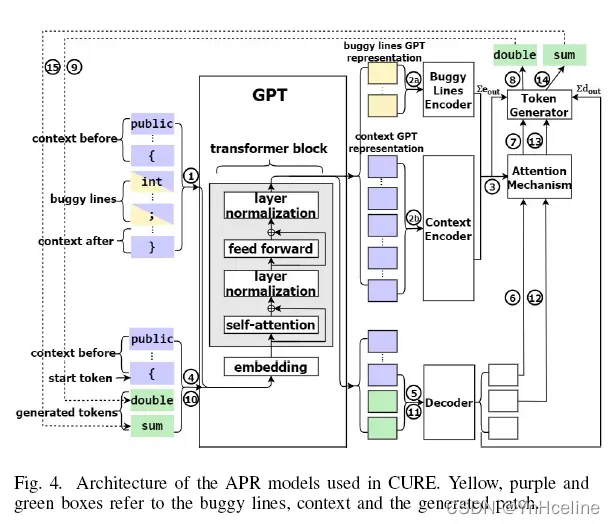
4.5 Code-Aware Beam-Search Strategy and Patch Generation
为了生成有效的identifiers,CURE首先静态分析并提取有有效标识符。
下图是一个提取buggy line valid identifiers的过程:
5.实验
数据源
PL Training Data:
根据GHTorrent[42],从GitHub下载所有(1700个)开源Java项目,在Defects4J第一个错误之前至少有一个提交,并将它们回滚到2006年之前的版本,以避免使用未来的数据。
然后使用JavaParser来提取除抽象method和长于1024个token的method之外的所有method。
最终:PL训练数据包含404万个方法,以及30000个验证实例。
Patch Training Data:
使用在GitHub上分享的CoCoNuT的训练数据作为我们的补丁训练数据,这是从45180个Java项目中提取的。将这些数据集用于PL训练成本太高,因此在子词标记化之后,丢弃上下文或正确补丁长度超过1,024个令牌的实例。
最终:我们的patch训练数据包含272万个训练实例和
16920个验证实例。
实验装置
结果
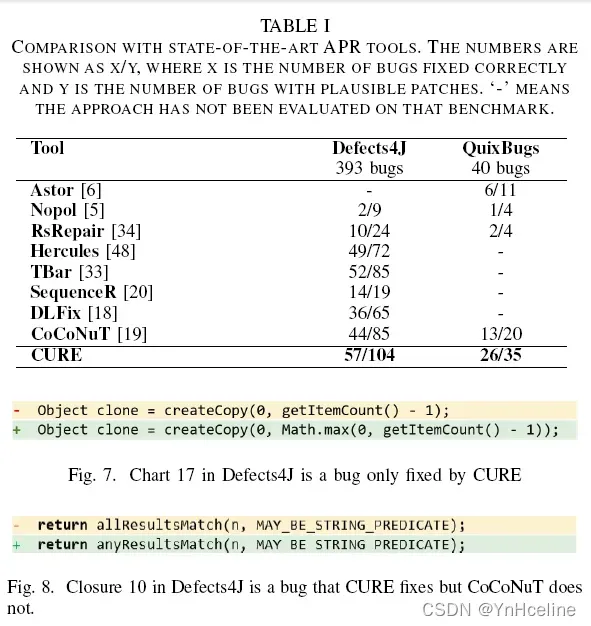
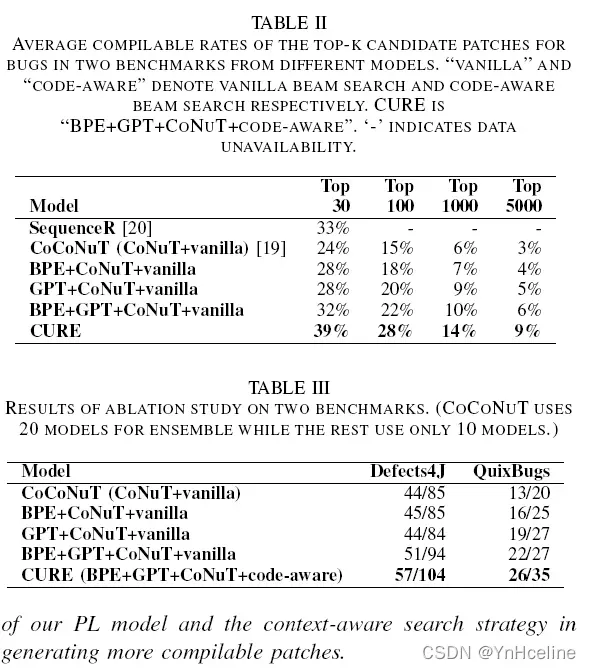
6.limitation
- 与以往工作的比较:我们的工作很难与以往所有的工作进行公平的比较,因为他们使用了不同的训练数据和FL方法。为了尽可能公平起见,我们使用了与最先进的NMT技术CoCoNuT相同的训练数据,并在两个benchmark上显示出了显著的改进。以前的一些工作使用不同的训练数据,但数据的选择和提取也是技术的关键组成部分。此外,为了与之前的APR技术进行比较,我们选择使用完美定位法,因为它是首选的比较方法,之前的工作评价了大多数具有完美FL的APR技术。
- 推广到其他benchmark和PL:作者在两个Java benchmark上评估CURE,但是这种方法既不绑定到特定的PL也不绑定到特定的benchmark。通过更新PL解析器,CURE可推广到其他语言。
- 训练集的准确性:由于我们的训练和训练前的数据提取是自动进行的,因此存在数据不准确的风险。训练数据是在之前的工作中提取的,并且在随机样本上显示出相当准确的结果。对于训练前的数据,我们提取了所有完整的函数,其中一些函数可能有bug或不正确。然而,预训练的目标是学习PL的语法,因此,我们主要关心的是数据遵循PL语法,这是经过验证的,因为我们只保留由Java解析器成功解析的方法。
总结
对patch的处理:
- 将patch分为:context(Similar to CoCoNuT, we use the method surrounding the buggy lines as context.)、buggy lines(带)、correct fuxes
- 对以上信息进行Word-level tokenization,token为sequences。
- 接着使用Subword tokenization处理上一步遗留的Out-of-vocabulary Issue。
- 具体参见作者之前的工作:CoCoNuT:Combining Context-Aware Neural Translation Models Using Ensemble for Program Repair
文章出处登录后可见!