AIGC实战——能量模型
-
- 0. 前言
- 1. 能量模型
-
- 1.1 模型原理
- 1.2 MNIST 数据集
- 1.3 能量函数
- 2. 使用 Langevin 动力学进行采样
-
- 2.1 随机梯度 Langevin 动力学
- 2.2 实现 Langevin 采样函数
- 3. 利用对比散度训练
- 小结
- 系列链接
0. 前言
能量模型 (Energy-based Model, EBM) 是一类常见的生成模型,其借鉴了物理系统建模的一个关键思想,即事件的概率可以用玻尔兹曼分布来表示。玻尔兹曼分布是一种将实值能量函数归一化到 0 和 1 之间的函数,该分布最早由 Ludwig Boltzmann 于 1868 年提出,用于描述处于热平衡状态的气体系统。在本节中,我们将利用这一思想来训练一个生成模型,用于生成 MNIST 手写数字的图像。
1. 能量模型
1.1 模型原理
能量模型是使用玻尔兹曼分布对真实的数据生成分布进行建模的方法,其中 被称为观测值
的能量函数(
energy function,或得分)。玻尔兹曼分布如下:
在实际应用中,需要训练一个神经网络 ,使其对可能出现的观测值输出较低的分数(使
接近
1),对不太可能出现的观测值输出较高的分数(使 接近
0)。
使用这种方式对数据进行建模存在两个挑战。首先,我们不清楚如何使用模型来生成新的观测值——我们可以使用它为给定观测值生成一个分数,但尚不清楚如何生成一个具有较低分数(即合理的观测值)的观测值。
其次,上式中的规范化分母包含一个积分,这通常难以计算。如果我们无法计算这个积分,那么我们就不能使用极大似然估计来训练模型,因为模型训练要求 是一个有效的概率分布。
能量模型的关键思想在于,使用近似技术确保永远不需要计算这个无法处理的分母。这与归一化流方法不同,在归一化流方法中,我们需要确保对标准高斯分布进行的转换不会改变输出仍然是有效的概率分布。
我们通过使用对比散度(用于能量模型 (Energy-based Model, EBM) 是一类常见的生成模型,其借鉴了物理系统建模的一个关键思想,即事件的概率可以用玻尔兹曼分布来表示。玻尔兹曼分布是一种将实值能量函数归一化到 0 和 1 之间的函数,该分布最早由 Ludwig Boltzmann 于 1868 年提出,用于描述处于热平衡状态的气体系统。在本节中,我们将利用这一思想来训练一个生成模型,用于生成 MNIST 手写数字的图像。训练)和 Langevin 动力学(用于采样)技术来绕过无法处理的分母问题,我们会在本节后面详细探讨这些技术,并构建 EBM。
首先,准备一个数据集并设计一个简单的神经网络来表示实值能量函数 。
1.2 MNIST 数据集
本节,我们将使用 MNIST 数据集,其中包含手写数字的灰度图像,数据集中的示例图像如下所示。

该数据集已预置于 TensorFlow 中,可以通过以下代码进行下载:
# Load the data
(x_train, _), (x_test, _) = datasets.mnist.load_data()
将像素值缩放到 [-1, 1] 的范围内,将图像的尺寸填充为 32×32 像素,并将其转换为 TensorFlow Dataset:
# Preprocess the data
def preprocess(imgs):
"""
Normalize and reshape the images
"""
imgs = (imgs.astype("float32") - 127.5) / 127.5
imgs = np.pad(imgs, ((0, 0), (2, 2), (2, 2)), constant_values=-1.0)
imgs = np.expand_dims(imgs, -1)
return imgs
x_train = preprocess(x_train)
x_test = preprocess(x_test)
x_train = tf.data.Dataset.from_tensor_slices(x_train).batch(BATCH_SIZE)
x_test = tf.data.Dataset.from_tensor_slices(x_test).batch(BATCH_SIZE)
1.3 能量函数
构建了数据集后,就可以构建表示能量函数 的神经网络。能量函数
是一个具有参数
的神经网络,它可以将输入图像
转换为一个标量值。在整个网络中,我们使用
swish 激活函数。
Swish 激活函数
Swish 是 Google 在 2017 年引入的替代 ReLU 的激活函数,其定义如下:
Swish 和 ReLU 函数曲线非常相似,但关键区别在于 Swish 是平滑的,这有助于缓解梯度消失问题,这对于基于能量的模型特别重要,Swish 函数曲线如下图所示。
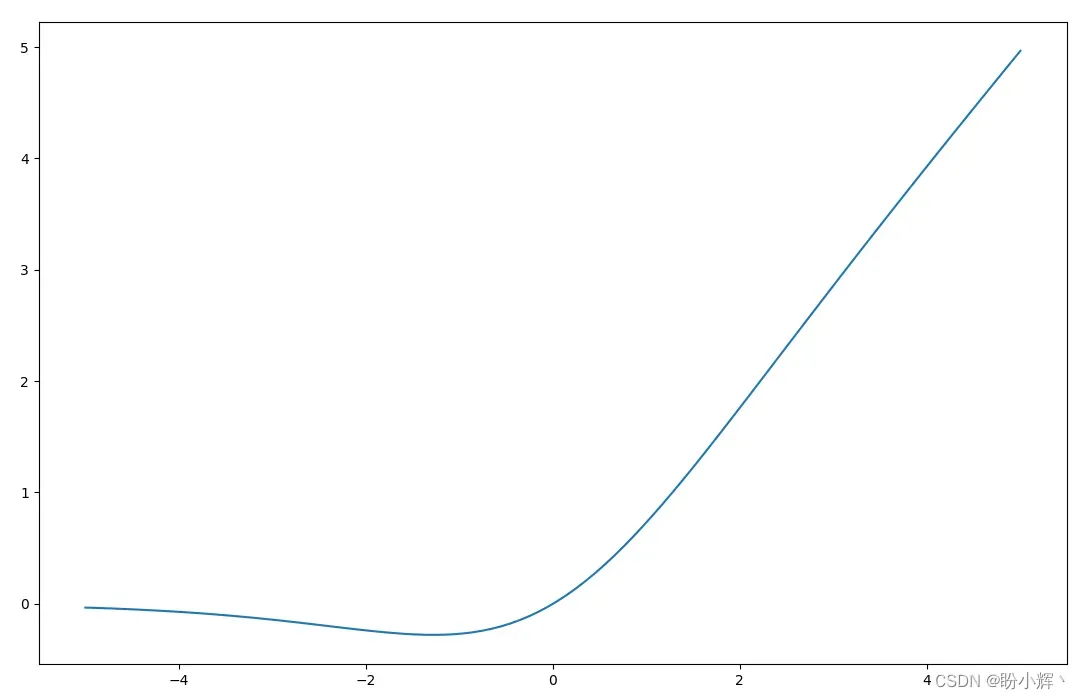
表示能量函数的网络由一组堆叠的 Conv2D 层组成,逐渐减小图像的尺寸并增加通道数。最后一层是一个具有线性激活函数的单个全连接单元,因此网络可以输出范围在 的值。
ebm_input = layers.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, CHANNELS))
# 能量函数是一组堆叠的 Conv2D 层,使用 swish 激活函数
x = layers.Conv2D(
16, kernel_size=5, strides=2, padding="same", activation=activations.swish
)(ebm_input)
x = layers.Conv2D(
32, kernel_size=3, strides=2, padding="same", activation=activations.swish
)(x)
x = layers.Conv2D(
64, kernel_size=3, strides=2, padding="same", activation=activations.swish
)(x)
x = layers.Conv2D(
64, kernel_size=3, strides=2, padding="same", activation=activations.swish
)(x)
x = layers.Flatten()(x)
x = layers.Dense(64, activation=activations.swish)(x)
# 最后一层是一个具有线性激活函数的单个全连接单元
ebm_output = layers.Dense(1)(x)
model = models.Model(ebm_input, ebm_output)
# 构建 Keras 模型将输入图像转换为标量能量值
print(model.summary())
2. 使用 Langevin 动力学进行采样
能量函数仅针对给定的输入输出一个得分,问题在于我们如何利用这个函数生成具有较低能量得分的新样本。
我们将使用 Langevin 动力学 (Langevin dynamics) 技术,利用了计算能量函数相对于其输入的梯度。如果我们从样本空间中的一个随机点出发,并朝着计算得到的梯度相反的方向移动一小段步长,将逐渐降低能量函数。如果神经网络能够正确训练,那么随机噪声应该会转化成一个类似于训练集观测值的图像。
2.1 随机梯度 Langevin 动力学
在穿越样本空间时,我们还必须向输入添加一小部分随机噪声;否则,有可能陷入局部最小值。因此,这种技术称为随机梯度 Langevin 动力学 (Stochastic Gradient Langevin Dynamics),如下图所示,使用三维空间表示二维空间,其中第三个维度是能量函数的值。路径是一个带有噪声的下坡,沿着输入 相对于能量函数
的负梯度方向进行。在
MNIST 图像数据集中,有 1024 个像素,因此需要我们在一个 1024 维空间中计算,但是所用的原理是相通的。
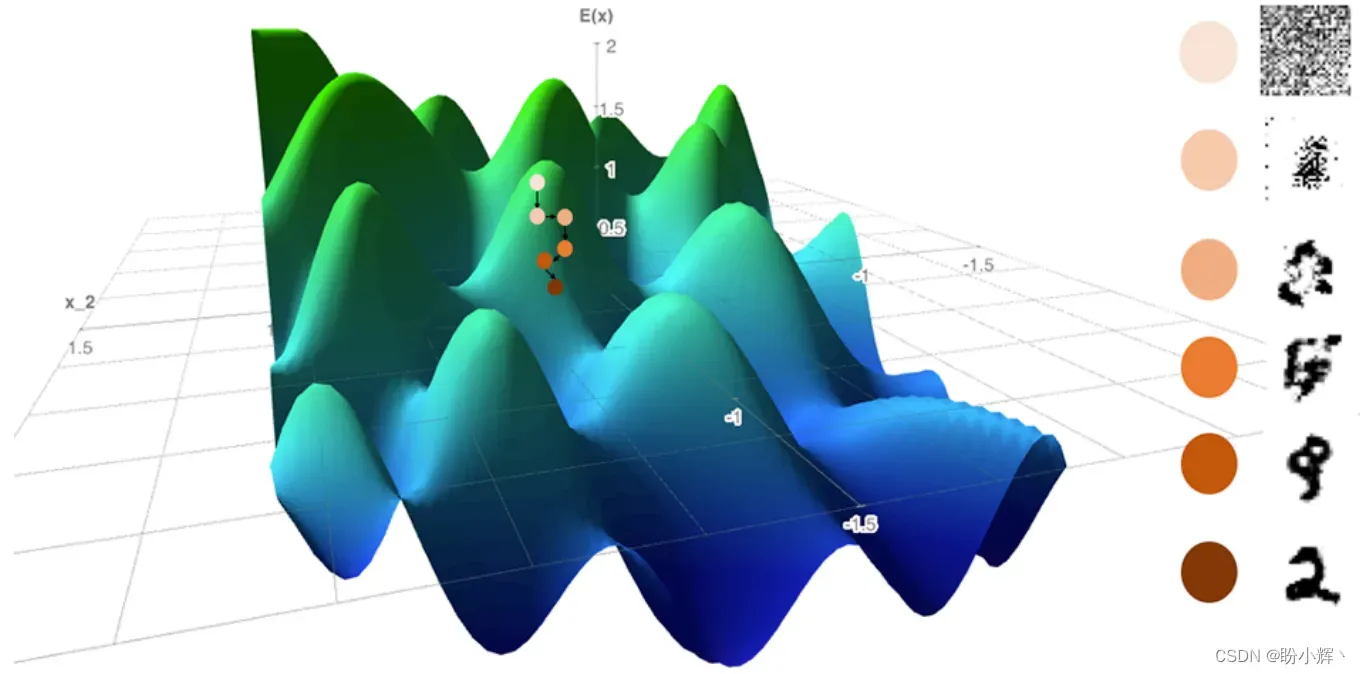
需要注意的是,这种梯度下降的方式与我们通常用于训练神经网络的梯度下降方式之间存在差异。
在训练神经网络时,我们使用反向传播计算损失函数相对于网络参数(即权重)的梯度。然后,缓慢调整参数朝着负梯度的方向更新,以便在多次迭代中逐渐最小化损失。
使用 Langevin 动力学时,我们保持神经网络的权重不变,并计算输出相对于输入的梯度。然后,我们稍微调整输入朝着负梯度的方向更新,以便在多次迭代中逐渐最小化输出(能量得分)。
这两个过程都利用了相同的思想(梯度下降),但应用于不同的函数和实体。
形式上,Langevin 动力学可以用以下方程描述:
其中 。
是需要调整的步长超参数,如果太大,步长会越过最小值,如果太小,算法将收敛过慢。
表示在
[-1, 1] 范围内的均匀分布。
2.2 实现 Langevin 采样函数
接下来,使用 Keras 实现 Langevin 采样函数。
# Function to generate samples using Langevin Dynamics
def generate_samples(
model, inp_imgs, steps, step_size, noise, return_img_per_step=False
):
imgs_per_step = []
# 循环给定的步数
for _ in range(steps):
# 为图像添加少量噪音
inp_imgs += tf.random.normal(inp_imgs.shape, mean=0, stddev=noise)
inp_imgs = tf.clip_by_value(inp_imgs, -1.0, 1.0)
with tf.GradientTape() as tape:
tape.watch(inp_imgs)
# 将图像通过模型,得到能量得分
out_score = model(inp_imgs)
# 计算输出对输入的梯度
grads = tape.gradient(out_score, inp_imgs)
grads = tf.clip_by_value(grads, -GRADIENT_CLIP, GRADIENT_CLIP)
# 将一小部分梯度添加到输入图像中
inp_imgs += step_size * grads
inp_imgs = tf.clip_by_value(inp_imgs, -1.0, 1.0)
if return_img_per_step:
imgs_per_step.append(inp_imgs)
if return_img_per_step:
return tf.stack(imgs_per_step, axis=0)
else:
return inp_imgs
3. 利用对比散度训练
我们已经知道如何从样本空间中采样出一个新的低评分能量点,接下来介绍如何训练模型。
能量模型无法应用最大似然估计,因为能量函数不输出概率,而是输出一个在样本空间上的分数。我们将应用 Geoffrey Hinton 在 2002 年提出的对比散度 (contrastive divergence) 技术,用于训练非规范化评分模型。我们需要最小化数据的负对数似然:
当 采用玻尔兹曼分布形式,具有能量函数
时,可以通过以下方式表示该值的梯度:
直观上讲,我们希望训练模型对真实观测值输出较大的负能量得分,对生成的伪造观测值输出较大的正能量得分,以便使这两类观测值之间的差距尽可能大。
换句话说,我们可以计算真实样本和伪造样本的能量得分之间的差,并将其作为损失函数。
要计算伪造样本的能量得分,我们需要能够从分布 中精确采样,但由于难以求解玻尔兹曼分布的规范化分母,因此难以实现;因此,我们可以使用
Langevin 采样过程生成一组能量得分较低的观测值。这个过程需要无限多的步骤才能生成一个完美的样本(显然并不现实),所以我们只运行较少步骤,并假设这足够产生一个有意义的损失函数。
我们还维护一个来自先前迭代的样本缓冲区,这样我们可以将其作为下一次迭代的起始点(而不完全是随机噪声),使用以下代码生成样本缓冲区。
class Buffer:
def __init__(self, model):
super().__init__()
self.model = model
# 采样缓冲区用一批随机噪声进行初始化
self.examples = [tf.random.uniform(shape=(1, IMAGE_SIZE, IMAGE_SIZE, CHANNELS)) * 2 - 1 for _ in range(BATCH_SIZE)]
def sample_new_exmps(self, steps, step_size, noise):
# 平均而言,每次有 5% 的观测值是从头生成的(即随机噪声)
n_new = np.random.binomial(BATCH_SIZE, 0.05)
rand_imgs = (
tf.random.uniform((n_new, IMAGE_SIZE, IMAGE_SIZE, CHANNELS)) * 2 - 1
)
# 其余观测值是随机从现有缓冲区中提取的
old_imgs = tf.concat(
random.choices(self.examples, k=BATCH_SIZE - n_new), axis=0
)
inp_imgs = tf.concat([rand_imgs, old_imgs], axis=0)
# 将这些观测值连接起来,通过 Langevin 采样运行
inp_imgs = generate_samples(
self.model, inp_imgs, steps=steps, step_size=step_size, noise=noise
)
# 所得到的样本被添加到缓冲区中,缓冲区的最大长度限制为 8,192 个观测样本
self.examples = tf.split(inp_imgs, BATCH_SIZE, axis=0) + self.examples
self.examples = self.examples[:BUFFER_SIZE]
return inp_imgs
下图显示了对比散度的一个训练步骤。算法将真实观测值的分数向下推,将伪造观测值的分数向上拉,而不关心每一步后归一化这些分数。
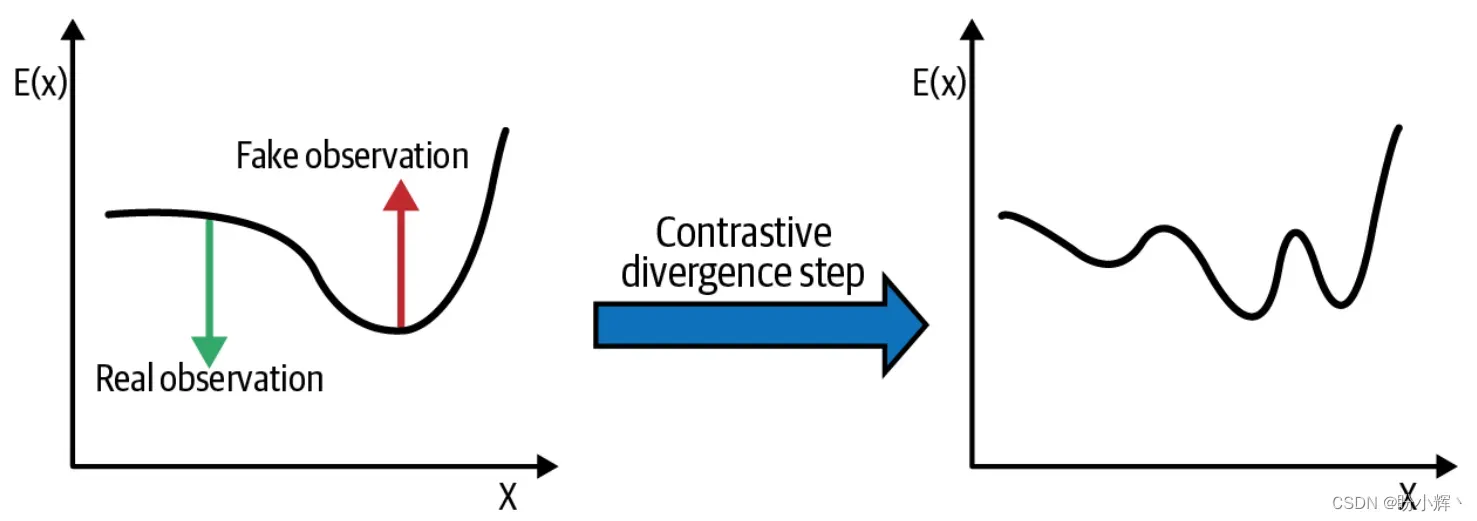
在自定义的 Keras 模型中编写对比散度算法的训练步骤:
class EBM(models.Model):
def __init__(self):
super(EBM, self).__init__()
self.model = model
self.buffer = Buffer(self.model)
self.alpha = ALPHA
self.loss_metric = metrics.Mean(name="loss")
self.reg_loss_metric = metrics.Mean(name="reg")
self.cdiv_loss_metric = metrics.Mean(name="cdiv")
self.real_out_metric = metrics.Mean(name="real")
self.fake_out_metric = metrics.Mean(name="fake")
@property
def metrics(self):
return [
self.loss_metric,
self.reg_loss_metric,
self.cdiv_loss_metric,
self.real_out_metric,
self.fake_out_metric,
]
def train_step(self, real_imgs):
# 为了避免模型过拟合训练集,我们在真实图像中添加一小部分随机噪声
real_imgs += tf.random.normal(shape=tf.shape(real_imgs), mean=0, stddev=NOISE)
real_imgs = tf.clip_by_value(real_imgs, -1.0, 1.0)
# 从缓冲区中采样一组伪造图像
fake_imgs = self.buffer.sample_new_exmps(steps=STEPS, step_size=STEP_SIZE, noise=NOISE)
inp_imgs = tf.concat([real_imgs, fake_imgs], axis=0)
with tf.GradientTape() as training_tape:
# 将真实图像和伪造图像通过模型运行,产生真实图像的得分和伪造图像的得分
real_out, fake_out = tf.split(self.model(inp_imgs), 2, axis=0)
# 对比散度损失是真实观测值和伪造观测值的得分之间之差
cdiv_loss = tf.reduce_mean(fake_out, axis=0) - tf.reduce_mean(real_out, axis=0)
# 为了避免得分过大,添加一个正则化损失
reg_loss = self.alpha * tf.reduce_mean(real_out**2 + fake_out**2, axis=0)
loss = cdiv_loss + reg_loss
# 计算损失函数相对于网络权重的的梯度,用于反向传播
grads = training_tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables))
self.loss_metric.update_state(loss)
self.reg_loss_metric.update_state(reg_loss)
self.cdiv_loss_metric.update_state(cdiv_loss)
self.real_out_metric.update_state(tf.reduce_mean(real_out, axis=0))
self.fake_out_metric.update_state(tf.reduce_mean(fake_out, axis=0))
return {m.name: m.result() for m in self.metrics}
def test_step(self, real_imgs):
# 在验证过程中使用 test_step,计算随机噪声集和来自训练集的数据之间的对比散度,用作评估模型训练效果的指标
batch_size = real_imgs.shape[0]
fake_imgs = (tf.random.uniform((batch_size, IMAGE_SIZE, IMAGE_SIZE, CHANNELS)) * 2 - 1)
inp_imgs = tf.concat([real_imgs, fake_imgs], axis=0)
real_out, fake_out = tf.split(self.model(inp_imgs), 2, axis=0)
cdiv = tf.reduce_mean(fake_out, axis=0) - tf.reduce_mean(real_out, axis=0)
self.cdiv_loss_metric.update_state(cdiv)
self.real_out_metric.update_state(tf.reduce_mean(real_out, axis=0))
self.fake_out_metric.update_state(tf.reduce_mean(fake_out, axis=0))
return {m.name: m.result() for m in self.metrics[2:]}
ebm = EBM()
# Compile and train the model
ebm.compile(
optimizer=optimizers.Adam(learning_rate=LEARNING_RATE), run_eagerly=True
)
ebm.fit(x_train, shuffle=True, epochs=300, validation_data=x_test)
为了评估模型的性能,我们还设置了一个验证过程,该过程不会从缓冲区中进行采样,而是对一组随机噪声进行评分,并将其与训练集中的样本得分进行比较。随着模型的改善,对比散度随训练逐渐下降,即模型在区分随机噪声和真实图像方面的性能逐渐增强。
从能量模型生成新样本只需运行 Langevin 采样多个步骤,从一个起点(随机噪声)开始,观测值沿着得分函数相对于输入的梯度向下移动,以便在噪声中获取一个合理的观测值。
start_imgs = (np.random.uniform(size=(10, IMAGE_SIZE, IMAGE_SIZE, CHANNELS)) * 2 - 1)
gen_img = generate_samples(
ebm.model,
start_imgs,
steps=1000,
step_size=STEP_SIZE,
noise=NOISE,
return_img_per_step=True,
)
在训练 50 个 epoch 后,采样生成的一些观测样本如下图所示。
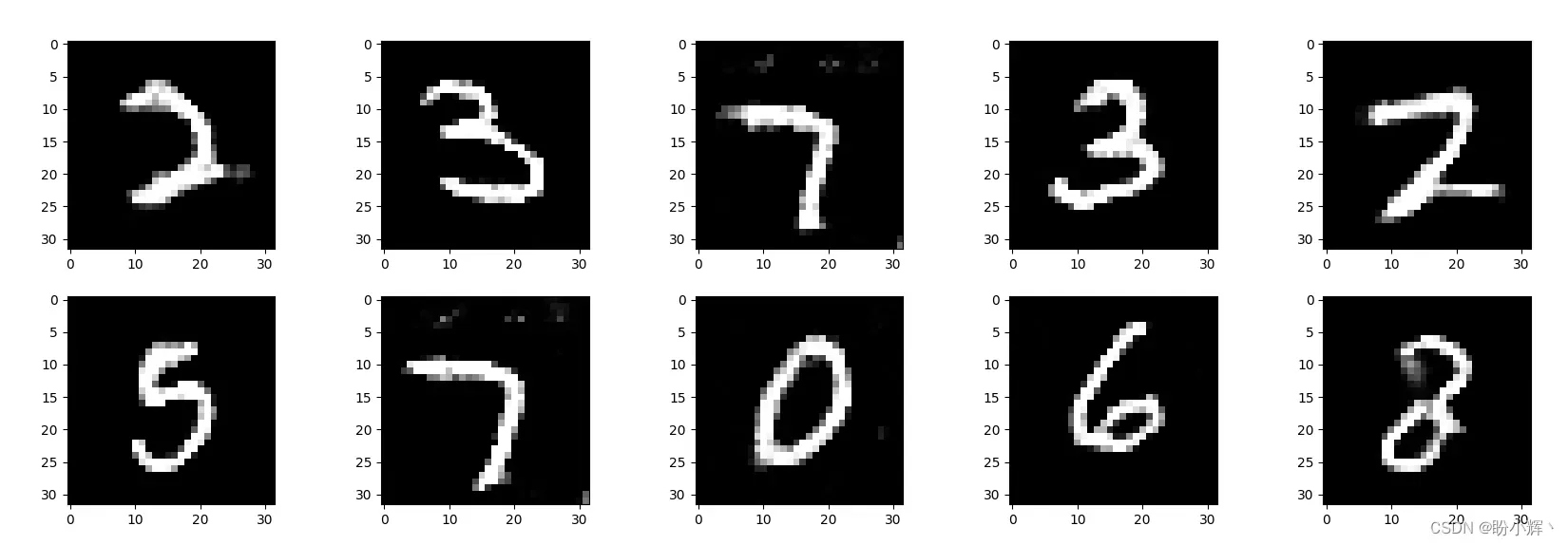
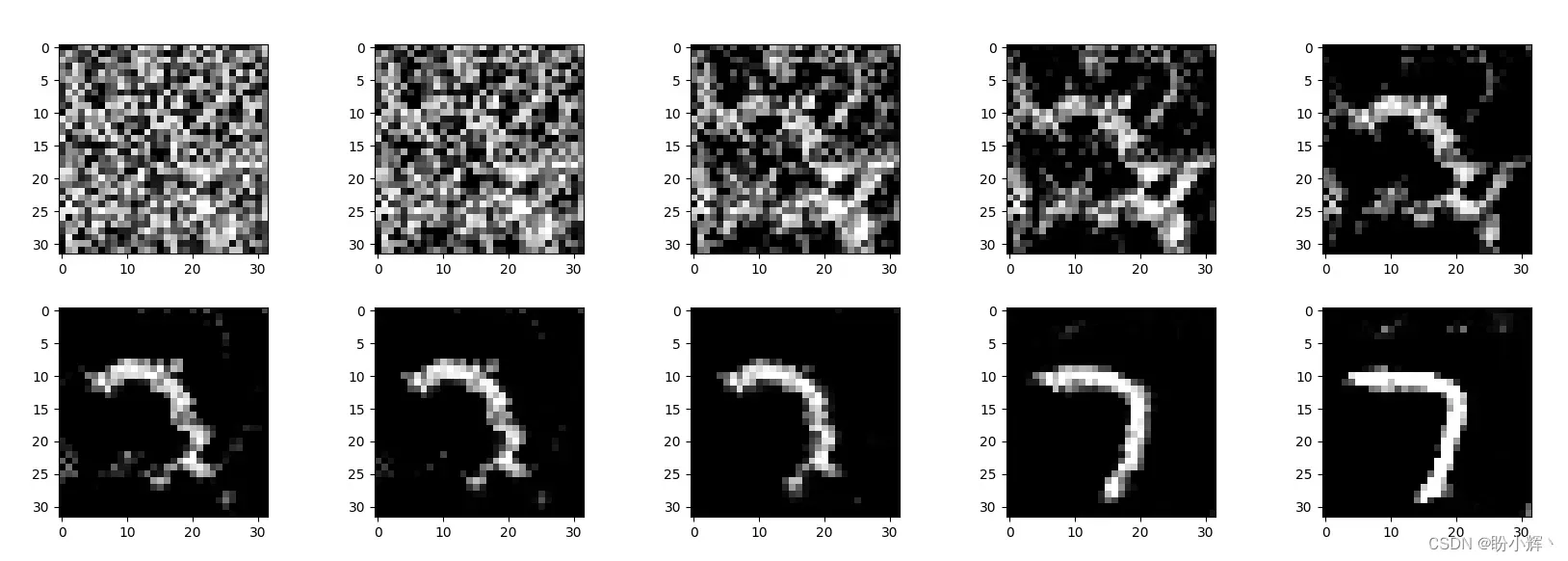
通过可视化 Langevin 采样过程中的中间状态观察观测样本的生成过程,如下图所示。
小结
能量模型 (Energy-based Model, EBM) 是一类利用能量评分函数的生成模型,其训练用于为真实观测值输出较低得分、为生成观测值输出较高得分的神经网络。计算由该评分函数给出的概率分布需要通过一个无法计算的分母进行归一化。EBM 通过利用两个技巧避免了这个问题:对比散度用于训练网络,Langevin 动力学用于采样新观测值。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
版权声明:本文为博主作者:盼小辉丶原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/LOVEmy134611/article/details/136125887