国庆假期,赶上疫情,因此只能在家学习了。之前有一些很酷的想法,在CPU上计算效率不够,无法应用到工程中,但在GPU上有对应的解决方案,因此趁此机会,学习一下GPU编程的相关基础知识。
正好,之前大概是19年,为了解决板材缺陷分类问题,自己购置了一张RTX2060显卡,使用开源yolov3框架。但调用的都是别人写好的库,真正的GPU编程还没有接触过。
本文主要是记录一下学习GPU编程的过程,在一到两天的时间里,对GPU编程思想有一个大概的认识,为将来深入学习打下基础,也对GPU编程可以解决的问题边界有一个认知,不被讲PPT的忽悠。
本文使用的显卡是Nvidia,编程语言是CUDA。
历史背景
GPU是计算机游戏发展的产物,为了提高游戏性能,在20世纪90年代产生了加速浮点运算的外插卡。后来板卡厂商将3D图像渲染采用专用硬件实现,用来处理大量的三角片纹理映射等浮点计算,逐渐发展成GPU(Graphics Processing Unit)。再后来研究高性能计算的学者,提出可以将本领域的问题,通过图像学API伪装成三角片映射,以此实现高效求解。GPU制造商发现了这一趋势,转而开发更加通用的GPU产品,称为GPGPU(通用GPU),Nvidia就是这些制造商之一。
GPGPU只是硬件,要想实现功能,还需要有软件体系结构。当前主流的两种GPU语言有CUDA和OpenCL。
CUDA(Compute Unified Device Architecture),由显卡厂商NVIDIA在2007年推出,提供了一套通用的并行计算架构与编程模型。使开发人员可以使用c语言开发在GPU上运行的代码,利用GPU的并行特性,这些代码可以达到极高的运行效率。
基本概念
CPU和主存被称为主机(Host),GPU和显存被称为设备(Device),CPU无法直接读显存,GPU无法直接读主存,两者间需要数据传输。
要为两个完全不同的处理设备编写程序,最好的办法是设计能同时编译CPU和GPU代码的编译器,使一套代码同时在CPU和GPU运行。Nvidia给出的解决方案是nvcc编译器。
hello world
介绍任何语言的开头必定会有一个“hello world”的例子。
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
__global__ void hello_world(void)
{
printf("GPU: Hello world! Thread id : %d\n", threadIdx.x);
}
int main()
{
cudaError_t cudaStatus;
cudaStatus = cudaSetDevice(0);
//调用核函数,在GPU执行
hello_world <<<1, 5>> >();
//必须被调用来供调试工具分析
cudaDeviceReset();
system("pause");
return 0;
}
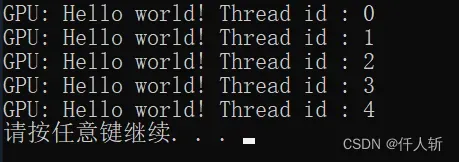
执行结果如下:
两个数组相加
这是CUDA编程自带的一个例子
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
cudaError_t cudaStatus;
//用于计时
cudaEvent_t time0, time1;
cudaEventCreate(&time0); cudaEventCreate(&time1);
//选择显卡设备,默认是0,多显卡环境下调用
cudaStatus = cudaSetDevice(0);
int a[10] = { 0,1,2,3,4,5,6,7,8,9 };
int b[10] = { 0,11,22,33,44,55,66,77,88,99 };
int c[10] = { 0 };
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
//在显卡上分配内存
cudaStatus = cudaMalloc((void**)&dev_a, 10 * sizeof(int));
cudaStatus = cudaMalloc((void**)&dev_b, 10 * sizeof(int));
cudaStatus = cudaMalloc((void**)&dev_c, 10 * sizeof(int));
//内存拷贝到显存
cudaStatus = cudaMemcpy(dev_a, a, 10 * sizeof(int), cudaMemcpyHostToDevice);
cudaStatus = cudaMemcpy(dev_b, b, 10 * sizeof(int), cudaMemcpyHostToDevice);
//调用和函数,执行GPU处理
cudaEventRecord(time0, 0);
addKernel << <1, 10 >> >(dev_c, dev_a, dev_b);
cudaEventRecord(time1, 0);
//告诉Nvidia运行时引擎,对给定的事件执行同步操作,确保时间正确
cudaEventSynchronize(time0); cudaEventSynchronize(time1);
//由两个事件计算得到时间
float ms = 0;
cudaEventElapsedTime(&ms, time0, time1);
std::cout << "GPU耗时:" << ms << "ms" << std::endl;
cudaEventDestroy(time0); cudaEventDestroy(time1);
//执行过程是否有问题
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
return -1;
}
//等待所有kernal执行完
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
return -1;
}
//从显存拷贝到主存
cudaStatus = cudaMemcpy(c, dev_c, 10 * sizeof(int), cudaMemcpyDeviceToHost);
//释放显存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
//必须被调用来供调试工具分析
cudaDeviceReset();
system("pause");
return 0;
}
好的,那么接下来:

图像翻转
首先是bmp文件的读写
#pragma pack(2)
typedef struct tagBITMAPFILEHEADER
{
unsigned short bfType; // 19778,必须是BM字符串,对应的十六进制为0x4d42,十进制为19778,否则不是bmp格式文件(0-4)
int bfSize; // 文件大小 以字节为单位(2-5字节) (4-8)
unsigned short bfReserved1; // 保留,必须设置为0 (6-7字节) (8-10)
unsigned short bfReserved2; // 保留,必须设置为0 (8-9字节) (10-12)
int bfOffBits; // 从文件头到像素数据的偏移 (10-13字节) (12-16)
}BITMAPFILEHEADER;
#pragma pack()
typedef struct tagBITMAPINFOHEADER
{
unsigned int biSize; // 此结构体的大小 (14-17字节)
long biWidth; // 图像的宽 (18-21字节)
long biHeight; // 图像的高 (22-25字节)
unsigned short biPlanes; // 表示bmp图片的平面属,显然显示器只有一个平面,所以恒等于1 (26-27字节)
unsigned short biBitCount; // 一像素所占的位数,一般为24 (28-29字节)
unsigned int biCompression; // 说明图象数据压缩的类型,0为不压缩。 (30-33字节)
unsigned int biSizeImage; // 像素数据所占大小, 这个值应该等于上面文件头结构中bfSize-bfOffBits (34-37字节)
long biXPelsPerMeter; // 说明水平分辨率,用象素/米表示。一般为0 (38-41字节)
long biYPelsPerMeter; // 说明垂直分辨率,用象素/米表示。一般为0 (42-45字节)
unsigned int biClrUsed; // 说明位图实际使用的彩色表中的颜色索引数(设为0的话,则说明使用所有调色板项)。 (46-49字节)
unsigned int biClrImportant; // 说明对图象显示有重要影响的颜色索引的数目,如果是0,表示都重要。(50-53字节)
} BITMAPINFOHEADER;
核函数定义
__global__ void Hflip(uint8_t* pSrc, uint8_t* pDst, int nW)
{
int ThrPreBlk = blockDim.x;//每块多少线程 256
int MYbid = blockIdx.x; //块索引
int MYtid = threadIdx.x;//线程索引
int MYgtid = ThrPreBlk * MYbid + MYtid; //全局索引
int BlkPerRow = (nW + ThrPreBlk - 1) / ThrPreBlk;//每行使用多少block,因为一个像素使用一个线程
int RowBytes = (nW * 3 + 3)&(~3);//每行像素数,向上取4的倍数
int MYRow = MYbid / BlkPerRow;
int MYCol = MYgtid - MYRow*BlkPerRow*ThrPreBlk;
if (MYCol >= nW) return;
int MYMirrorCol = nW - 1 - MYCol;
int MYOffset = MYRow*RowBytes;
int MYSrcIndex = MYOffset + 3 * MYCol;
int MYDstIndex = MYOffset + 3 * MYMirrorCol;
pDst[MYDstIndex] = pSrc[MYSrcIndex];
pDst[MYDstIndex+1] = pSrc[MYSrcIndex+1];
pDst[MYDstIndex+2] = pSrc[MYSrcIndex+2];
}
主流程:
int main()
{
//bmp文件读取
std::ifstream ifs;
ifs.open("D:\\1.bmp", std::ifstream::in | std::ifstream::binary);
if (!ifs.is_open())
{
std::cout << "文件打开失败" << std::endl;
return;
}
char buf[54];
ifs.read(buf, 54);
BITMAPFILEHEADER* pHeader = (BITMAPFILEHEADER*)buf;
BITMAPINFOHEADER* pInfo = (BITMAPINFOHEADER*)(buf + 14);
if (pInfo->biBitCount != 24)
{
std::cout << "必须是24位图像" << std::endl;
return;
}
int lineByte = (pInfo->biWidth * pInfo->biBitCount / 8 + 3) / 4 * 4; //向上取4的整倍数
int nSize = lineByte * pInfo->biHeight;
uint8_t* pSrc = new uint8_t[nSize + 31];
uint8_t* pDst = new uint8_t[nSize + 31];
ifs.read((char*)pSrc, nSize);
ifs.close();
//开始进行图像翻转处理
cudaError_t cudaStatus;
cudaEvent_t time0, time1;
cudaEventCreate(&time0); cudaEventCreate(&time1);
uint8_t* pGPUSrc, *pGPUDst;
//在显卡上分配内存
cudaStatus = cudaMalloc((void**)&pGPUSrc, nSize * sizeof(uint8_t));
cudaStatus = cudaMalloc((void**)&pGPUDst, nSize * sizeof(uint8_t));
//图像数据拷贝到显存
cudaStatus = cudaMemcpy(pGPUSrc, pSrc, nSize * sizeof(uint8_t), cudaMemcpyHostToDevice);
//GPU处理
int ThrPerBlk = 256;
int BlkPerRow = (pInfo->biWidth + ThrPerBlk - 1) / ThrPerBlk;
int NumBlks = pInfo->biHeight*BlkPerRow;
cudaEventRecord(time0, 0);
Hflip << <NumBlks, ThrPerBlk >> > (pGPUSrc, pGPUDst, pInfo->biWidth);
cudaEventRecord(time1, 0);
//告诉Nvidia运行时引擎,对给定的事件执行同步操作,确保时间正确
cudaEventSynchronize(time0); cudaEventSynchronize(time1);
//由两个事件计算得到时间
float ms = 0;
cudaEventElapsedTime(&ms, time0, time1);
std::cout << "GPU耗时:" << ms << "ms" << std::endl;
//等待所有kernal执行完
cudaStatus = cudaDeviceSynchronize();
//从显存拷贝到主存
cudaStatus = cudaMemcpy(pDst, pGPUDst, nSize * sizeof(uint8_t), cudaMemcpyDeviceToHost);
//释放显存
cudaFree(pGPUSrc);
cudaFree(pGPUDst);
//必须被调用来供调试工具分析
cudaDeviceReset();
//将bmp数据写回
std::ofstream ofs;
ofs.open("D:\\1-Hflip.bmp", std::ios::out);
ofs.write(buf, 54); //图像头
ofs.write((char*)pDst, nSize2);
ofs.close();
return 0;
}
执行结果:

设备属性获取
cudaDeviceProp GPUProp;
cudaGetDeviceProperties(&GPUProp, 0);
std::cout
<< "全局内存大小:" << GPUProp.totalGlobalMem/1024/1024/1024.0 << "GB" << std::endl
<< "gridsize[0]:" << GPUProp.maxGridSize[0] << std::endl //一个网格中每个维度的block数量
<< "gridsize[1]:" << GPUProp.maxGridSize[1] << std::endl
<< "gridsize[2]:" << GPUProp.maxGridSize[2] << std::endl
<< "sharedMemPerBlock:" << GPUProp.sharedMemPerBlock/1024.0 << "kB" <<std::endl//每block共享内存
<< "regsPerBlock:" << GPUProp.regsPerBlock << std::endl//每block32为寄存器个数
<< "ThrePerBlock:" << GPUProp.maxThreadsPerBlock << std::endl//每block最多多少线程
<< "maxThreadsDim[0]" << GPUProp.maxThreadsDim[0] << std::endl
<< "maxThreadsDim[1]" << GPUProp.maxThreadsDim[1] << std::endl
<< "maxThreadsDim[2]" << GPUProp.maxThreadsDim[2] << std::endl
<< "设备上处理器数量:" << GPUProp.multiProcessorCount << std::endl
<< "canMapHostMemory:" << GPUProp.canMapHostMemory << std::endl
<< std::endl;
总结
GPU编程的通用流程:
- 初始化, 将必要数据拷贝到GPU设备的显存
- CPU调用GPU函数,启动GPU多核同时计算
- CPU和GPU异步计算
- 将GPU计算结果拷贝回主机,得到计算结果
后续会有:图像颜色空间转换,图像滤波(卷积)等操作在GPU上的实现
文章出处登录后可见!