排序有先后,后面的基本是基于前面方法的不足进行改进。
好的激活函数应该满足的条件
1.非线性:这是必须的,也是添加激活函数的原因。
2.几乎处处可微:反向传播中,损失函数要对参数求偏导,如果激活函数不可微,那就无法使用梯度下降方法更新参数了。(ReLU只在零点不可微,但是梯度下降几乎不可能收敛到梯度为0)
3.计算简单:神经元(units)越多,激活函数计算的次数就越多,复杂的激活函数会降低训练速度。
4.非饱和性:饱和指在某些区间梯度接近于零,使参数无法更新。Sigmoid和tanh都有这个问题,而ReLU就没有,所以普遍效果更好。
5.有限的值域:这样可以使网络更稳定,即使有很大的输入,激活函数的输出也不会太大。
现有比较好的激活函数(SiLU,Mish,ELU)是有下界、无上界、平滑、非单调。
有下界:可以提高正则化效果
无上界:防止网络饱和,及梯度为零
平滑:可以避免在不可导点的一些问题,更容易优化
非单调:可以保留一些负输入,提高网络的表达能力
Sigmoid(逻辑函数logistic)
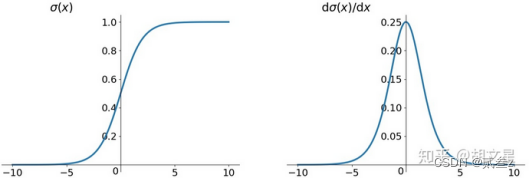
缺点:
1.容易饱和:输入太大或太小都会使其梯度接近0,在反向传播中梯度接近0时参数就会难以更新。另外还需要将参数初始化得比较小才能避免刚开始就梯度为0。
2.非零均值:模型收敛需要更多时间。
解释:反向传播更新参数公式如下,xi是上层的输出,恒正,f(1-f)恒正,所以所有wi的更新方向一致。
![]()
![]()
3.幂运算相对计算量较大
tanh(双曲正切)
![]()
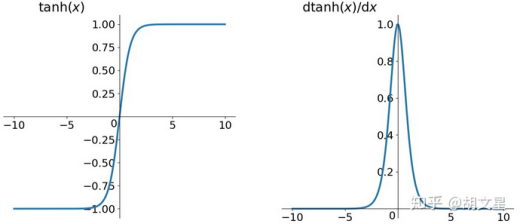
缺点:解决了非零均值问题,仍存在梯度消失和计算量大的问题。
ReLU
ReLU,线性整流函数(Rectified Linear Unit),又称修正线性单元。
![]()
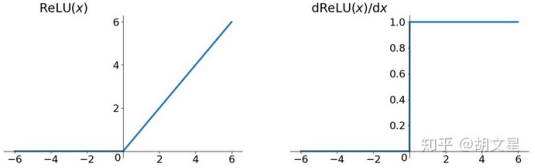
优点:1.在正区间解决了梯度消失问题;2.计算速度快,只需要判断正负;3.收敛速度快于Sigmoid和tanh
缺点:1.非零均值;2. Dead ReLU Problem:一些神经元可能永远不能被激活,导致相应参数不能更新。
解释Dead ReLU Problem:
![]()
![]()
因为xi是上层各个神经元的输出,即上层每个神经元的激活函数的输出,可知其值一定为0或者正数,为方便说明现在假设xi都为正数。看上式,现在xi为正数,学习率n肯定也是正数,若损失函数对激活函数的导数也是正数且足够大,并假设学习率n也不小,那么很多wi更新这一次后就变成了负数,这会导致下层的输入是负数,下层的输出就变成0。
造成Dead ReLU Problem问题的主要原因可能为:1.学习率n太大导致参数更新幅度太大;2.糟糕的权重初始化。
解决方法:避免学习率设置过大,使用adagrad等可以自动调节学习率的方法。
Softplus
![]()
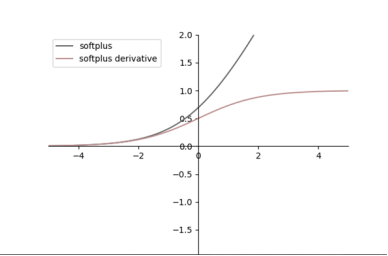
优点:类似于ReLU,但有下界,无上界,平滑
缺点:导数小于1,可能存在梯度消失的问题;单调,无法保留负输入;非零均值,收敛慢。
ELU(Exponential Linear Units)
指数的线性单元,![]()
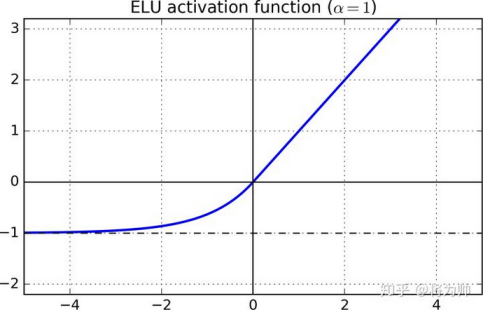
优点:解决了Dead ReLU Problem问题;有下界、无上界、平滑。
缺点:计算量较大
Leaky Relu(YOLOv5 5.0之前)
![]() α = 0.01(通常)
α = 0.01(通常)
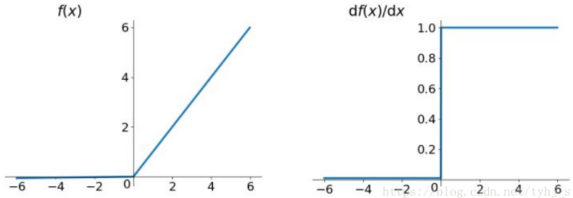
优点:解决了Dead ReLU Problem问题以及所有ReLU的优点(在正区间解决了梯度消失的问题,计算简单,收敛速度快)。
SiLU(Swish)(YOLOv5 6.0之后)
![]() β = 1就是SiLU
β = 1就是SiLU
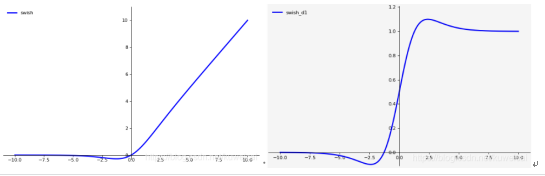
优点:ReLU有无上界和有下界的特点,而Swish相比ReLU又增加了平滑和非单调的特点,这使得其在ImageNet上的效果更好。
缺点:引入了指数函数,增加了计算量.
Mish
![]()
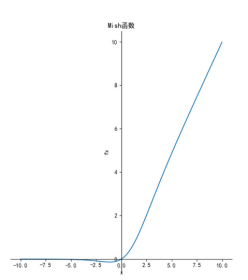
优点:平滑、非单调、无上界、有下界
缺点:引入了指数函数,增加了计算量
作者注:其实Mish那篇文章说比SiLU效果更好,但是一些人复现后发现就差不多,作者也认为差不多,函数和导数图像如此之像能有多大差别[掩面而泣]
文章出处登录后可见!