这是机器未来的第1篇文章
原文首发地址:https://blog.csdn.net/RobotFutures/article/details/124745966
CSDN话题挑战赛第1期
活动详情地址:https://marketing.csdn.net/p/bb5081d88a77db8d6ef45bb7b6ef3d7f
参赛话题:自动驾驶技术学习记录
话题描述:自动驾驶是当前最火热的技术之一,吸引了无数的开发者与学习者融入其中。然而,自动驾驶技术是系统硬件平台与人工智能、物联网、大数据、云计算等新一代信息技术深度融合的产物,具有知识新、内容杂、难度深、缺少系统教程等特点,让许多开发者眼花缭乱。
本话题通过记录分享自动驾驶相关技术,为大家提供相互学习与交流的平台。话题分享与讨论的技术点包括不限于:自动驾驶算法、自动驾驶系统基础架构、智能驾驶交互技术、虚拟仿真、自动化测试、无人系统与车辆平台、自动驾驶计算平台与传感器等。
1. 概述
物体检测是自动驾驶感知层的重要基础,障碍物检测、行人检测、交通标志检测、车道线检测…等都基于物体检测理论来实现,物体检测的模型框架较多,本文着重描述tensorflow object detection api。
tensorflow object detection api一个框架,它可以很容易地构建、训练和部署对象检测模型,并且是一个提供了众多基于COCO数据集、Kitti数据集、Open Images数据集、AVA v2.1数据集和iNaturalist物种检测数据集上提供预先训练的对象检测模型集合。
tensorflow object detection api是目前最主流的目标检测框架之一,主流的目标检测模型如图所示:
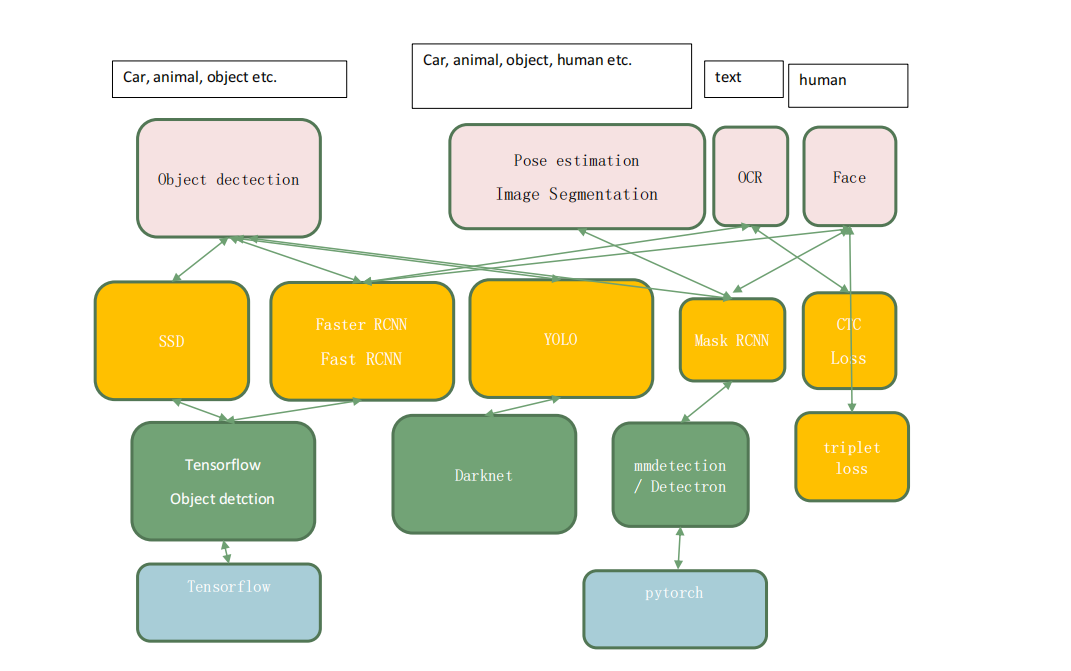
本文描述了基于Tensorflow2.x Object Detection API构建自定义物体检测器的保姆级教程,详细地描述了代码框架结构、数据集的标准方法,标注文件的数据处理、模型流水线的配置、模型的训练、评估、推理全流程。
最终的测试效果如下:标注物体的位置、物体的类型及置信度。

2. 组织工程文档结构
- 创建父目录
创建tensorflow文件夹,将下载的object detection api源码models目录拷贝到tensorflow目录下,结构如下:
TensorFlow/
└─ models/
├─ community/
├─ official/
├─ orbit/
├─ research/
└─ ...
- 创建工作区
cd tensorflow;
mkdir training_demo ;cd training_demo;
创建完毕后的文档组织结构如下:
TensorFlow/
├─ models/
│ ├─ community/
│ ├─ official/
│ ├─ orbit/
│ ├─ research/
│ └─ ...
└─ workspace/
└─ training_demo/
- 项目目录
mkdir annotations exported-models images/ images/test/ images/train/ models/ pre_trained_models/;
touch README.md
创建完毕后的项目结构如下
training_demo/
├─ annotations/ # annotations存标签映射文件和转换后的TFRecord文件
├─ exported_models/ # 存放训练完毕后导出的模型文件
├─ images/ # 存放原始图像数据文件
│ ├─ test/ # 存放评估图像数据集和标注文件集
│ └─ train/ # 存放训练图像数据集和标注文件集
├─ models/ # 存放训练中的pipline.config、模型数据、tensorboard事件数据
├─ pre_trained_models/ # 存放下载的预训练模型
└─ README.md # 工程说明文档
3. 标注数据集
- 标注工具labelImg
- 标注示例
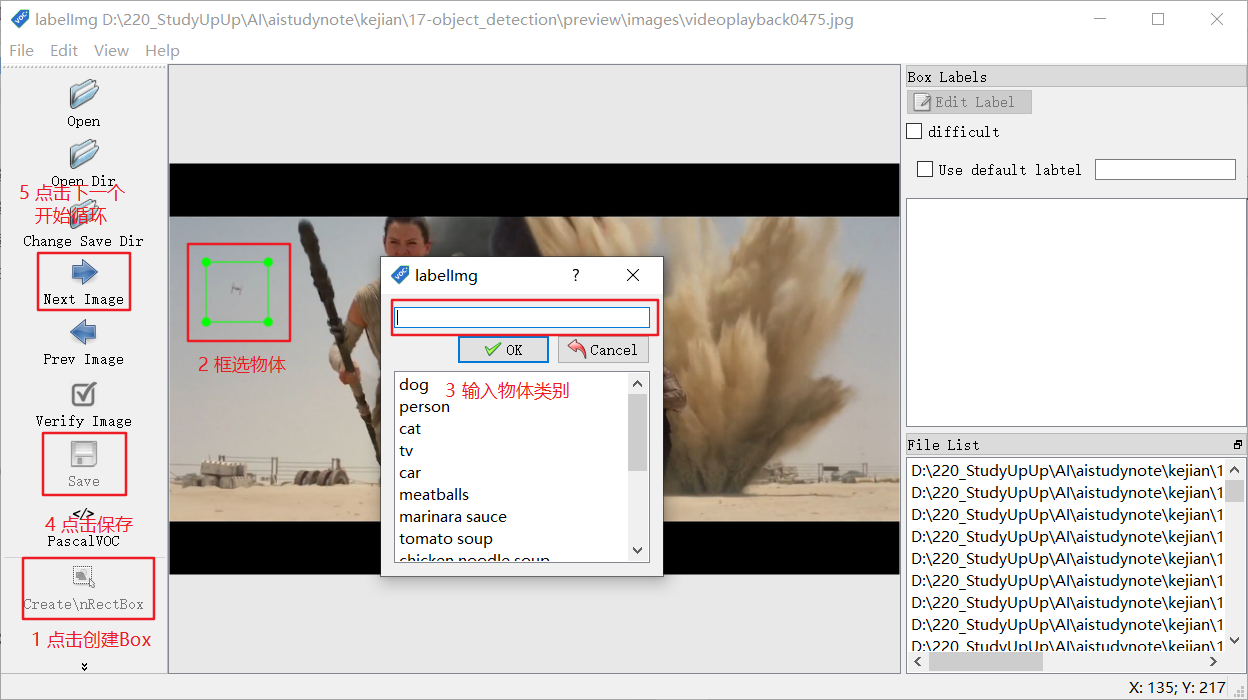
- 标注后的xml文件统一存放到training_demo/images目录下
- 划分训练、评估数据集
首先创建一个公共目录tensorflow/scripts/preprocessing用于存放脚本,偏于将来复用
mkdir tensorflow/scripts
mkdir tensorflow/scripts/preprocessing
创建完成后的目录结构如下:
tensorflow/
├─ models/
│ ├─ community/
│ ├─ official/
│ ├─ orbit/
│ ├─ research/
│ └─ ...
├─ scripts/
│ └─ preprocessing/
└─ workspace/
└─ training_demo/
在tensorflow/scripts/preprocessing目录下添加训练集划分脚本partition_dataset.py,脚本内容如下:
""" usage: partition_dataset.py [-h] [-i IMAGEDIR] [-o OUTPUTDIR] [-r RATIO] [-x]
Partition dataset of images into training and testing sets
optional arguments:
-h, --help show this help message and exit
-i IMAGEDIR, --imageDir IMAGEDIR
Path to the folder where the image dataset is stored. If not specified, the CWD will be used.
-o OUTPUTDIR, --outputDir OUTPUTDIR
Path to the output folder where the train and test dirs should be created. Defaults to the same directory as IMAGEDIR.
-r RATIO, --ratio RATIO
The ratio of the number of test images over the total number of images. The default is 0.1.
-x, --xml Set this flag if you want the xml annotation files to be processed and copied over.
"""
import os
import re
from shutil import copyfile
import argparse
import math
import random
def iterate_dir(source, dest, ratio, copy_xml):
source = source.replace('\\', '/')
dest = dest.replace('\\', '/')
train_dir = os.path.join(dest, 'train')
test_dir = os.path.join(dest, 'test')
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
images = [f for f in os.listdir(source)
if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(?i)(.jpg|.jpeg|.png)$', f)]
num_images = len(images)
num_test_images = math.ceil(ratio*num_images)
for i in range(num_test_images):
idx = random.randint(0, len(images)-1)
filename = images[idx]
copyfile(os.path.join(source, filename),
os.path.join(test_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
copyfile(os.path.join(source, xml_filename),
os.path.join(test_dir,xml_filename))
images.remove(images[idx])
for filename in images:
copyfile(os.path.join(source, filename),
os.path.join(train_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
copyfile(os.path.join(source, xml_filename),
os.path.join(train_dir, xml_filename))
def main():
# Initiate argument parser
parser = argparse.ArgumentParser(description="Partition dataset of images into training and testing sets",
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument(
'-i', '--imageDir',
help='Path to the folder where the image dataset is stored. If not specified, the CWD will be used.',
type=str,
default=os.getcwd()
)
parser.add_argument(
'-o', '--outputDir',
help='Path to the output folder where the train and test dirs should be created. '
'Defaults to the same directory as IMAGEDIR.',
type=str,
default=None
)
parser.add_argument(
'-r', '--ratio',
help='The ratio of the number of test images over the total number of images. The default is 0.1.',
default=0.1,
type=float)
parser.add_argument(
'-x', '--xml',
help='Set this flag if you want the xml annotation files to be processed and copied over.',
action='store_true'
)
args = parser.parse_args()
if args.outputDir is None:
args.outputDir = args.imageDir
# Now we are ready to start the iteration
iterate_dir(args.imageDir, args.outputDir, args.ratio, args.xml)
if __name__ == '__main__':
main()
执行脚本:
python partition_dataset.py -x -i [PATH_TO_IMAGES_FOLDER] -r [test_dataset ratio]
示例:
python partition_dataset.py -x -i ../../training_demo/images/ -r 0.1
# -x 表明输入文件格式是xml文件
# -i 指定图像文件所在目录
# -r 指定训练集、评估集切分比例,0.1代表评估集占比10%
4. 创建标签分类映射文件
在training_demo/annotations目录下创建label_map.pbtxt,内容为标签分类及ID, 示例如下:
item {
id: 1
name: 'cat'
}
item {
id: 2
name: 'dog'
}
示例表明数据集一共有2个类别,分别为cat和dog,分配的分类ID分别为1和2
5. 将标注数据xml文件转换为record格式文件
- 脚本内容如下:
""" Sample TensorFlow XML-to-TFRecord converter
usage: generate_tfrecord.py [-h] [-x XML_DIR] [-l LABELS_PATH] [-o OUTPUT_PATH] [-i IMAGE_DIR] [-c CSV_PATH]
optional arguments:
-h, --help show this help message and exit
-x XML_DIR, --xml_dir XML_DIR
Path to the folder where the input .xml files are stored.
-l LABELS_PATH, --labels_path LABELS_PATH
Path to the labels (.pbtxt) file.
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Path of output TFRecord (.record) file.
-i IMAGE_DIR, --image_dir IMAGE_DIR
Path to the folder where the input image files are stored. Defaults to the same directory as XML_DIR.
-c CSV_PATH, --csv_path CSV_PATH
Path of output .csv file. If none provided, then no file will be written.
"""
import os
import glob
import pandas as pd
import io
import xml.etree.ElementTree as ET
import argparse
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import tensorflow.compat.v1 as tf
from PIL import Image
from object_detection.utils import dataset_util, label_map_util
from collections import namedtuple
# Initiate argument parser
parser = argparse.ArgumentParser(
description="Sample TensorFlow XML-to-TFRecord converter")
parser.add_argument("-x",
"--xml_dir",
help="Path to the folder where the input .xml files are stored.",
type=str)
parser.add_argument("-l",
"--labels_path",
help="Path to the labels (.pbtxt) file.", type=str)
parser.add_argument("-o",
"--output_path",
help="Path of output TFRecord (.record) file.", type=str)
parser.add_argument("-i",
"--image_dir",
help="Path to the folder where the input image files are stored. "
"Defaults to the same directory as XML_DIR.",
type=str, default=None)
parser.add_argument("-c",
"--csv_path",
help="Path of output .csv file. If none provided, then no file will be "
"written.",
type=str, default=None)
args = parser.parse_args()
if args.image_dir is None:
args.image_dir = args.xml_dir
label_map = label_map_util.load_labelmap(args.labels_path)
label_map_dict = label_map_util.get_label_map_dict(label_map)
def xml_to_csv(path):
"""Iterates through all .xml files (generated by labelImg) in a given directory and combines
them in a single Pandas dataframe.
Parameters:
----------
path : str
The path containing the .xml files
Returns
-------
Pandas DataFrame
The produced dataframe
"""
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
filename = root.find('filename').text
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text)
for member in root.findall('object'):
bndbox = member.find('bndbox')
value = (filename,
width,
height,
member.find('name').text,
int(bndbox.find('xmin').text),
int(bndbox.find('ymin').text),
int(bndbox.find('xmax').text),
int(bndbox.find('ymax').text),
)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def class_text_to_int(row_label):
return label_map_dict[row_label]
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(args.output_path)
path = os.path.join(args.image_dir)
examples = xml_to_csv(args.xml_dir)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecord file: {}'.format(args.output_path))
if args.csv_path is not None:
examples.to_csv(args.csv_path, index=None)
print('Successfully created the CSV file: {}'.format(args.csv_path))
if __name__ == '__main__':
tf.app.run()
- 注意事项
在使用脚本之前,请确认已经安装了pandas,使用脚本确认是否安装,如下命令显示版本号即为安装:
root@cc58e655b170# python -c "import pandas as pd;print(pd.__version__)"
1.4.1
未安装时,可以按照当前环境安装
conda install pandas # Anaconda
# or
pip install pandas # pip
- 脚本调用格式
# Create train data:
python generate_tfrecord.py -x [PATH_TO_IMAGES_FOLDER]/train -l [PATH_TO_ANNOTATIONS_FOLDER]/label_map.pbtxt -o [PATH_TO_ANNOTATIONS_FOLDER]/train.record
# Create test data:
python generate_tfrecord.py -x [PATH_TO_IMAGES_FOLDER]/test -l [PATH_TO_ANNOTATIONS_FOLDER]/label_map.pbtxt -o [PATH_TO_ANNOTATIONS_FOLDER]/test.record
- 使用脚本转换train、test数据集
# For example
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# python generate_tfrecord.py -x ../../training_demo/images/train/ -l ../../training_demo/annotations/label_map.pbtxt -o ../../training_demo/annotations/train.record
Successfully created the TFRecord file: ../../training_demo/annotations/train.record
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# python generate_tfrecord.py -x ../../training_demo/images/test/ -l ../../training_demo/annotations/label_map.pbtxt -o ../../training_demo/annotations/test.record
Successfully created the TFRecord file: ../../training_demo/annotations/test.record
脚本执行完毕后,在training_demo/annotations目录下会生成train.record和test.record文件
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# ls ../../training_demo/annotations/
label_map.pbtxt test.record train.record
6. 配置训练流水线
6.1 下载预训练模型
使用wget命令行下载预训练detection模型
wget -c http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.tar.gz
如果提示找不到wget命令,使用apt工具安装
apt install wget
特别注意:此处下载的模型为detection模型,pipline.config中的fine_tune_checkpoint_type:配置为"detection"才有效,否则会报错
6.2 解压缩预训练模型
使用tar命令tar zxvf ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.tar.gz解压预训练模型
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo/pre_trained_models# tar zxvf ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.tar.gz
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0.data-00000-of-00001
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/checkpoint
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0.index
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/saved_model.pb
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/assets/
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/variables/
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/variables/variables.data-00000-of-00001
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model/variables/variables.index
解压后预训练模型在training_demo/pre_trained_models目录下:
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo/pre_trained_models# ls
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
预训练模型的目录结构如下
training_demo/
├─ ...
├─ pre_trained_models/
│ └─ ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/
│ ├─ checkpoint/
│ ├─ saved_model/
│ └─ pipeline.config
└─ ...
6.3 配置预训练模型
-
拷贝流水线文件到指定目录
在training_demo/models目录下创建my_ssd_resnet50_v1_fpn目录,将流水线配置文件training_demo/pre_trained_models/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config拷贝到该目录下,拷贝后的目录结构如下training_demo/ ├─ ... ├─ models/ │ └─ my_ssd_resnet50_v1_fpn/ │ └─ pipeline.config └─ ... -
配置pipline.config
相关的配置项及描述如下代码所示:
model {
ssd {
num_classes: 2 # num_classes为自定义对象检测器所检测的物体分类总数,此处为2
image_resizer {
fixed_shape_resizer {
height: 640
width: 640
}
}
......
train_config {
batch_size: 8 # batch_size依赖可用的内存,可根据需要添加或减少,且至少保证大于样本数
data_augmentation_options {
random_horizontal_flip {
}
}
......
# fine_tune_checkpoint为预训练模型的文件路径配置
fine_tune_checkpoint: "pre_trained_models/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0"
num_steps: 2000 # num_steps为训练的epochs的数量
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection" # 因为要训练完整的检测模型,这里填写detection,而不是classification
use_bfloat16: false # 使用TPU训练时置为true
fine_tune_checkpoint_version: V2
}
train_input_reader {
label_map_path: "annotations/label_map.pbtxt" # 配置标签映射文件
tf_record_input_reader {
input_path: "annotations/train.record" # 配置待训练的训练集TFRecord 文件
}
}
......
eval_input_reader {
label_map_path: "annotations/label_map.pbtxt" # 配置标签映射文件
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "annotations/test.record" # 配置待训练的测试集TFRecord 文件
}
}
7. 训练模型
7.1 拷贝脚本到工程目录
拷贝models/research/object_detection/model_main_tf2.py到training_demo目录
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# cp ../../models/research/object_detection/model_main_tf2.py .
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# ls
README.md annotations exported-models images model_main_tf2.py models pre_trained_models
7.2 训练模型
python model_main_tf2.py --model_dir=models/ssd_mobilenet_v1_fpn --pipeline_config_path=models/my_ssd_resnet50_v1_fpn/pipeline.config
训练输出如下所示:
2022-03-18 16:31:18.185503: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.05GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
INFO:tensorflow:Step 100 per-step time 0.690s
I0318 16:31:54.968108 140508069689152 model_lib_v2.py:705] Step 100 per-step time 0.690s
INFO:tensorflow:{'Loss/classification_loss': 0.5467333,
'Loss/localization_loss': 0.62460774,
'Loss/regularization_loss': 0.37178832,
'Loss/total_loss': 1.5431294,
'learning_rate': 0.014666351}
I0318 16:31:54.968450 140508069689152 model_lib_v2.py:708] {'Loss/classification_loss': 0.5467333,
'Loss/localization_loss': 0.62460774,
'Loss/regularization_loss': 0.37178832,
'Loss/total_loss': 1.5431294,
'learning_rate': 0.014666351}
7.2.1 训练模型过程中遇到的问题:
6.2.1.1 ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
- 解决办法:
- 查看numpy、pycocotools版本
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# python -c "import numpy as np;print(np.__version__)"
1.21.5
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# python -m pip show pycocotools
Name: pycocotools
Version: 2.0.5
Summary: Official APIs for the MS-COCO dataset
Home-page: None
Author: None
Author-email: None
License: UNKNOWN
Location: /usr/local/lib/python3.8/dist-packages
Requires: cython, matplotlib, setuptools
Required-by: tf-models-official, object-detection
numpy的版本为1.21.5,pycocotools 的版本为2.0.5,将pycocotools 的版本降为2.0.1可以解决问题
pip install --upgrade pycocotools==2.0.1
7.2.1.2 模型输入输出访问错误: Input/output error [Op:SaveV2]
```
I0320 12:47:20.331673 139707635332928 model_lib_v2.py:705] Step 1000 per-step time 0.433s
INFO:tensorflow:{'Loss/classification_loss': 0.26997942,
'Loss/localization_loss': 0.30341092,
'Loss/regularization_loss': 2.2776012,
'Loss/total_loss': 2.8509917,
'learning_rate': 0.0266665}
I0320 12:47:20.331962 139707635332928 model_lib_v2.py:708] {'Loss/classification_loss': 0.26997942,
'Loss/localization_loss': 0.30341092,
'Loss/regularization_loss': 2.2776012,
'Loss/total_loss': 2.8509917,
'learning_rate': 0.0266665}
2022-03-20 12:47:23.322429: W tensorflow/core/framework/op_kernel.cc:1745] OP_REQUIRES failed at save_restore_v2_ops.cc:138 : UNKNOWN: models/my_ssd_resnet50_v1_fpn/ckpt-3_temp/part-00000-of-00001.data-00000-of-00001.tempstate1791880307736640246; Input/output error
Traceback (most recent call last):
File "model_main_tf2.py", line 115, in <module>
tf.compat.v1.app.run()
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/platform/app.py", line 36, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/usr/local/lib/python3.8/dist-packages/absl/app.py", line 312, in run
_run_main(main, args)
File "/usr/local/lib/python3.8/dist-packages/absl/app.py", line 258, in _run_main
sys.exit(main(argv))
File "model_main_tf2.py", line 106, in main
model_lib_v2.train_loop(
File "/usr/local/lib/python3.8/dist-packages/object_detection/model_lib_v2.py", line 713, in train_loop
manager.save()
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/checkpoint_management.py", line 813, in save
save_path = self._checkpoint.write(prefix)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/tracking/util.py", line 2105, in write
output = self._saver.save(file_prefix=file_prefix, options=options)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/tracking/util.py", line 1262, in save
save_path, new_feed_additions = self._save_cached_when_graph_building(
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/tracking/util.py", line 1206, in _save_cached_when_graph_building
save_op = saver.save(file_prefix, options=options)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/saving/functional_saver.py", line 371, in save
return save_fn()
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/saving/functional_saver.py", line 345, in save_fn
sharded_saves.append(saver.save(shard_prefix, options))
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/training/saving/functional_saver.py", line 80, in save
return io_ops.save_v2(file_prefix, tensor_names, tensor_slices, tensors)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/ops/gen_io_ops.py", line 1707, in save_v2
return save_v2_eager_fallback(
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/ops/gen_io_ops.py", line 1728, in save_v2_eager_fallback
_result = _execute.execute(b"SaveV2", 0, inputs=_inputs_flat, attrs=_attrs,
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/execute.py", line 54, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
tensorflow.python.framework.errors_impl.UnknownError: models/my_ssd_resnet50_v1_fpn/ckpt-3_temp/part-00000-of-00001.data-00000-of-00001.tempstate1791880307736640246; Input/output error [Op:SaveV2]
```
- 解决办法:
- 重启电脑后解决。
7.3 tensorboard查看训练过程曲线
执行命令tensorboard --logdir=training_demo/models/ssd_mobilenet_v1_fpn/train查看tensorboard面板
root@cc58e655b170:/home/zhou/tensorflow/workspace# tensorboard --logdir=training_demo/models/my_ssd_resnet50_v1_fpn/train
2022-03-18 16:38:07.080715: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-03-18 16:38:07.100073: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-03-18 16:38:07.101614: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
NOTE: Using experimental fast data loading logic. To disable, pass
"--load_fast=false" and report issues on GitHub. More details:
https://github.com/tensorflow/tensorboard/issues/4784
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit)
- 打开浏览器,输入
http://127.0.0.1:6006/#scalars,浏览器效果如图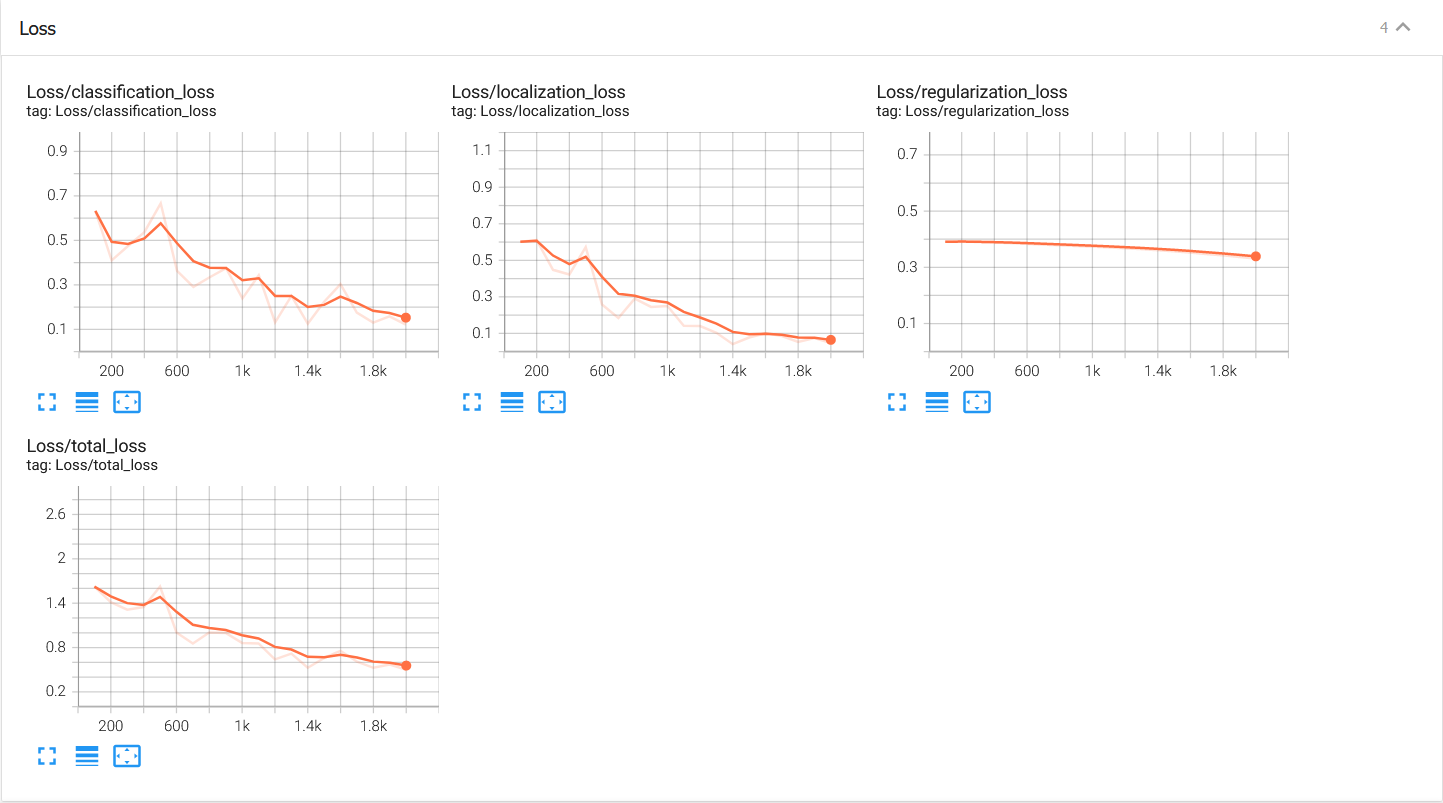
注意事项:
- tensorboard: error: invalid choice: ‘Recognizer\logs’ (choose from ‘serve’, ‘dev’)
- 命令的logdir的=号两侧不可以有空格
tensorboard --logdir=[train_path]
- 命令的logdir的=号两侧不可以有空格
7.4 评估模型
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# python model_main_tf2.py --model_dir=models/ssd_mobilenet_v1_fpn --pipeline_config_path=models/ssd_mobilenet_v1_fpn/pipeline.config --checkpoint_dir=models/ssd_mobilenet_v1_fpn
......
2022-03-18 17:10:21.973191: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 3951 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5
INFO:tensorflow:Reading unweighted datasets: ['annotations/test.record']
I0318 17:10:22.271144 140242454390592 dataset_builder.py:163] Reading unweighted datasets: ['annotations/test.record']
INFO:tensorflow:Reading record datasets for input file: ['annotations/test.record']
I0318 17:10:22.272839 140242454390592 dataset_builder.py:80] Reading record datasets for input file: ['annotations/test.record']
INFO:tensorflow:Number of filenames to read: 1
I0318 17:10:22.273008 140242454390592 dataset_builder.py:81] Number of filenames to read: 1
WARNING:tensorflow:num_readers has been reduced to 1 to match input file shards.
W0318 17:10:22.273125 140242454390592 dataset_builder.py:87] num_readers has been reduced to 1 to match input file shards.
......
INFO:tensorflow:Waiting for new checkpoint at models/my_ssd_resnet50_v1_fpn
I0318 17:10:32.268154 140242454390592 checkpoint_utils.py:136] Waiting for new checkpoint at models/my_ssd_resnet50_v1_fpn
INFO:tensorflow:Found new checkpoint at models/my_ssd_resnet50_v1_fpn/ckpt-6
I0318 17:10:32.275528 140242454390592 checkpoint_utils.py:145] Found new checkpoint at models/my_ssd_resnet50_v1_fpn/ckpt-6
/usr/local/lib/python3.8/dist-packages/keras/backend.py:450: UserWarning: `tf.keras.backend.set_learning_phase` is deprecated and will be removed after 2020-10-11. To update it, simply pass a True/False value to the `training` argument of the `__call__` method of your layer or model.
......
INFO:tensorflow:Performing evaluation on 2 images.
I0318 17:11:09.182368 140242454390592 coco_evaluation.py:293] Performing evaluation on 2 images.
creating index...
index created!
INFO:tensorflow:Loading and preparing annotation results...
I0318 17:11:09.182641 140242454390592 coco_tools.py:116] Loading and preparing annotation results...
INFO:tensorflow:DONE (t=0.00s)
I0318 17:11:09.182915 140242454390592 coco_tools.py:138] DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.02s).
Accumulating evaluation results...
DONE (t=0.01s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.275
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.538
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.167
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.276
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.250
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.350
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.550
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.550
INFO:tensorflow:Eval metrics at step 1000
I0318 17:11:09.223372 140242454390592 model_lib_v2.py:1015] Eval metrics at step 1000
INFO:tensorflow: + DetectionBoxes_Precision/mAP: 0.275370
I0318 17:11:09.227210 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP: 0.275370
INFO:tensorflow: + DetectionBoxes_Precision/mAP@.50IOU: 0.538462
I0318 17:11:09.231014 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP@.50IOU: 0.538462
INFO:tensorflow: + DetectionBoxes_Precision/mAP@.75IOU: 0.166667
I0318 17:11:09.233924 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP@.75IOU: 0.166667
INFO:tensorflow: + DetectionBoxes_Precision/mAP (small): -1.000000
I0318 17:11:09.238049 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP (small): -1.000000
INFO:tensorflow: + DetectionBoxes_Precision/mAP (medium): -1.000000
I0318 17:11:09.241585 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP (medium): -1.000000
INFO:tensorflow: + DetectionBoxes_Precision/mAP (large): 0.275628
I0318 17:11:09.245546 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Precision/mAP (large): 0.275628
INFO:tensorflow: + DetectionBoxes_Recall/AR@1: 0.250000
I0318 17:11:09.250303 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@1: 0.250000
INFO:tensorflow: + DetectionBoxes_Recall/AR@10: 0.350000
I0318 17:11:09.255020 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@10: 0.350000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100: 0.550000
I0318 17:11:09.266462 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@100: 0.550000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (small): -1.000000
I0318 17:11:09.269966 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@100 (small): -1.000000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (medium): -1.000000
I0318 17:11:09.272413 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@100 (medium): -1.000000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (large): 0.550000
I0318 17:11:09.275286 140242454390592 model_lib_v2.py:1018] + DetectionBoxes_Recall/AR@100 (large): 0.550000
INFO:tensorflow: + Loss/localization_loss: 0.467712
I0318 17:11:09.278475 140242454390592 model_lib_v2.py:1018] + Loss/localization_loss: 0.467712
INFO:tensorflow: + Loss/classification_loss: 0.517050
I0318 17:11:09.281271 140242454390592 model_lib_v2.py:1018] + Loss/classification_loss: 0.517050
INFO:tensorflow: + Loss/regularization_loss: 0.373590
I0318 17:11:09.284374 140242454390592 model_lib_v2.py:1018] + Loss/regularization_loss: 0.373590
INFO:tensorflow: + Loss/total_loss: 1.358352
I0318 17:11:09.287869 140242454390592 model_lib_v2.py:1018] + Loss/total_loss: 1.358352
8. 导出模型
- 拷贝models/research/object_detection/exporter_main_v2.py脚本到training_demo目录下
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# cp ../../models/research/object_detection/exporter_main_v2.py .
- 执行导出
python exporter_main_v2.py \
--input_type image_tensor \
--pipeline_config_path models/ssd_mobilenet_v1_fpn/pipeline.config \
--trained_checkpoint_dir models/ssd_mobilenet_v1_fpn \
--output_directory "exported_models/my_model"
输出如下:
2022-03-18 17:31:40.560733: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 3951 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5
WARNING:tensorflow:From /usr/local/lib/python3.8/dist-packages/tensorflow/python/autograph/impl/api.py:458: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with back_prop=False is deprecated and will be removed in a future version.
Instructions for updating:
back_prop=False is deprecated. Consider using tf.stop_gradient instead.
Instead of:
results = tf.map_fn(fn, elems, back_prop=False)
Use:
results = tf.nest.map_structure(tf.stop_gradient, tf.map_fn(fn, elems))
W0318 17:31:40.987179 139643789973312 deprecation.py:610] From /usr/local/lib/python3.8/dist-packages/tensorflow/python/autograph/impl/api.py:458: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with back_prop=False is deprecated and will be removed in a future version.
Instructions for updating:
back_prop=False is deprecated. Consider using tf.stop_gradient instead.
Instead of:
results = tf.map_fn(fn, elems, back_prop=False)
Use:
results = tf.nest.map_structure(tf.stop_gradient, tf.map_fn(fn, elems))
2022-03-18 17:32:03.258760: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:tensorflow:Skipping full serialization of Keras layer <object_detection.meta_architectures.ssd_meta_arch.SSDMetaArch object at 0x7f0064491a00>, because it is not built.
W0318 17:32:06.718129 139643789973312 save_impl.py:71] Skipping full serialization of Keras layer <object_detection.meta_architectures.ssd_meta_arch.SSDMetaArch object at 0x7f0064491a00>, because it is not built.
W0318 17:32:25.107337 139643789973312 save.py:260] Found untraced functions such as WeightSharedConvolutionalBoxPredictor_layer_call_fn, WeightSharedConvolutionalBoxPredictor_layer_call_and_return_conditional_losses, WeightSharedConvolutionalBoxHead_layer_call_fn, WeightSharedConvolutionalBoxHead_layer_call_and_return_conditional_losses, WeightSharedConvolutionalClassHead_layer_call_fn while saving (showing 5 of 208). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: exported-models/my_model/saved_model/assets
I0318 17:32:32.900944 139643789973312 builder_impl.py:779] Assets written to: exported-models/my_model/saved_model/assets
INFO:tensorflow:Writing pipeline config file to exported-models/my_model/pipeline.config
I0318 17:32:33.612621 139643789973312 config_util.py:253] Writing pipeline config file to exported-models/my_model/pipeline.config
结构如下:
root@cc58e655b170:/home/zhou/tensorflow/workspace/training_demo# tree exported-models/my_model/
exported-models/my_model/
├── checkpoint
│ ├── checkpoint
│ ├── ckpt-0.data-00000-of-00001
│ └── ckpt-0.index
├── pipeline.config
└── saved_model
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
4 directories, 7 files
注意事项:
- 路径不能使用反斜杠,必须使用’/’
- 路径不可以有‘-’符号,有的话,需要使用双引号将路径引用起来,否则会报错
FATAL Flags parsing error: flag --output_directory=None: Flag --output_directory must have a value other than None.
9. 模型推理
python inference_main_v2.py -m "exported_models/my_model/saved_model" -l "annotations/label_map.pbtxt" -i "images/test" -o "inference_result/"
脚本内容如下:
#!/usr/bin/env python
# coding: utf-8
"""
Object Detection From TF2 Saved Model
=====================================
"""
# %%
# This demo will take you through the steps of running an "out-of-the-box" TensorFlow 2 compatible
# detection model on a collection of images. More specifically, in this example we will be using
# the `Saved Model Format <https://www.tensorflow.org/guide/saved_model>`__ to load the model.
# %%
# Download the test images
# ~~~~~~~~~~~~~~~~~~~~~~~~
# First we will download the images that we will use throughout this tutorial. The code snippet
# shown bellow will download the test images from the `TensorFlow Model Garden <https://github.com/tensorflow/models/tree/master/research/object_detection/test_images>`_
# and save them inside the ``data/images`` folder.
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import pathlib
import tensorflow as tf
import argparse
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
# Enable GPU dynamic memory allocation
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# Initiate argument parser
parser = argparse.ArgumentParser(
description="model inference sample")
parser.add_argument("-m",
"--saved_model_dir",
help="Path to saved model directory.",
type=str, default="exported_models/my_model/saved_model")
parser.add_argument("-l",
"--labels_path",
help="Path to the labels (.pbtxt) file.", type=str, default="annotations/label_map.pbtxt")
parser.add_argument("-i",
"--images_dir",
help="Path of input images file.", type=str, default="images/test")
parser.add_argument("-o",
"--output_inference_result",
help="Path of output inference result file.", type=str, default='inference_result/')
args = parser.parse_args()
# %%
# Load the model
# ~~~~~~~~~~~~~~
# Next we load the downloaded model
import time
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
# PATH_TO_SAVED_MODEL = "exported_models/my_model/saved_model"
# PATH_TO_LABELS = "annotations/label_map.pbtxt"
# PATH_TO_IMAGES = "images/test"
# PATH_TO_INFERENCE_RESULT = 'inference_result/'
PATH_TO_SAVED_MODEL = args.saved_model_dir
PATH_TO_LABELS = args.labels_path
PATH_TO_IMAGES = args.images_dir
PATH_TO_INFERENCE_RESULT = args.output_inference_result
print('Loading model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
# %%
# Load label map data (for plotting)
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Label maps correspond index numbers to category names, so that when our convolution network
# predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility
# functions, but anything that returns a dictionary mapping integers to appropriate string labels
# would be fine.
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
# %%
# Putting everything together
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~
# The code shown below loads an image, runs it through the detection model and visualizes the
# detection results, including the keypoints.
#
# Note that this will take a long time (several minutes) the first time you run this code due to
# tf.function's trace-compilation --- on subsequent runs (e.g. on new images), things will be
# faster.
#
# Here are some simple things to try out if you are curious:
#
# * Modify some of the input images and see if detection still works. Some simple things to try out here (just uncomment the relevant portions of code) include flipping the image horizontally, or converting to grayscale (note that we still expect the input image to have 3 channels).
# * Print out `detections['detection_boxes']` and try to match the box locations to the boxes in the image. Notice that coordinates are given in normalized form (i.e., in the interval [0, 1]).
# * Set ``min_score_thresh`` to other values (between 0 and 1) to allow more detections in or to filter out more detections.
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import warnings
import os
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
def load_images_path(images_dir):
images_path_list = []
images_filename_list = os.listdir(images_dir)
for img_path in images_filename_list:
if img_path.endswith(".jpg") == True:
img_path = os.path.join('%s/%s' % (images_dir, img_path))
images_path_list.append(img_path)
return images_path_list
IMAGE_PATHS = load_images_path(PATH_TO_IMAGES)
for image_path in IMAGE_PATHS:
print('Running inference for {}... '.format(image_path), end='')
image_np = load_image_into_numpy_array(image_path)
# Things to try:
# Flip horizontally
# image_np = np.fliplr(image_np).copy()
# Convert image to grayscale
# image_np = np.tile(
# np.mean(image_np, 2, keepdims=True), (1, 1, 3)).astype(np.uint8)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image_np)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
# input_tensor = np.expand_dims(image_np, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_np_with_detections = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.30,
agnostic_mode=False)
plt.figure()
# plt.imshow(image_np_with_detections)
image_filename = os.path.join(PATH_TO_INFERENCE_RESULT, os.path.basename(image_path))
plt.imsave(image_filename, image_np_with_detections)
print('Done')
# plt.show()
# sphinx_gallery_thumbnail_number = 2
- 结果展示



以上就是一个完整的基于TF2 OD API自定义物体检测器的完整操作流程。
10. 总结
推理结果中仍然有同一个物体被框选2次的情况,需要调节NVS进一步优化。除此之外,还可以尝试使用不同的模型,例如SSD等,选择出效果最优的训练模型。
11. 项目源代码及数据集有偿下载
在以上的博文中,博主已经将相关的脚本均已经贴出来来了,如果仍然需要完整的源代码及数据集,博主提供有偿下载:https://download.csdn.net/download/RobotFutures/85656313
参考资料:
- 异常:ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
- 异常:在使用tensorboard时报错tensorboard: error: invalid choice: ‘Recognizer\logs’ (choose from ‘serve’, ‘dev’)
《物体检测快速入门系列》快速导航:
写在末尾:
- 博客简介:专注AIoT领域,追逐未来时代的脉搏,记录路途中的技术成长!
- 专栏简介:记录博主从0到1掌握物体检测工作流的过程,具备自定义物体检测器的能力
- 面向人群:具备深度学习理论基础的学生或初级开发者
- 专栏计划:接下来会逐步发布跨入人工智能的系列博文,敬请期待
- Python零基础快速入门系列
- 快速入门Python数据科学系列
- 人工智能开发环境搭建系列
- 机器学习系列
- 物体检测快速入门系列
- 自动驾驶物体检测系列
- …

CSDN话题挑战赛第1期
活动详情地址:https://marketing.csdn.net/p/bb5081d88a77db8d6ef45bb7b6ef3d7f
文章出处登录后可见!