
图1.1:YOLOv8初始测试
YOLOv8🔥于 2023年1月10日由Ultralytics发布。它在计算机视觉方面提供了进展,带来了对我们感知、分析和理解视觉世界的巨大创新。它将为各个领域带来前所未有的可能性。
在速度、准确性和架构方面进行了相当大的改进。它是从头开始实现的,没有使用任何来自YOLOv5的主要模块(即模型架构)。它的速度更快,比其先前版本(YOLOv7)更准确,并且在平均精度均值(MAP)方面获得了53.7的新高。
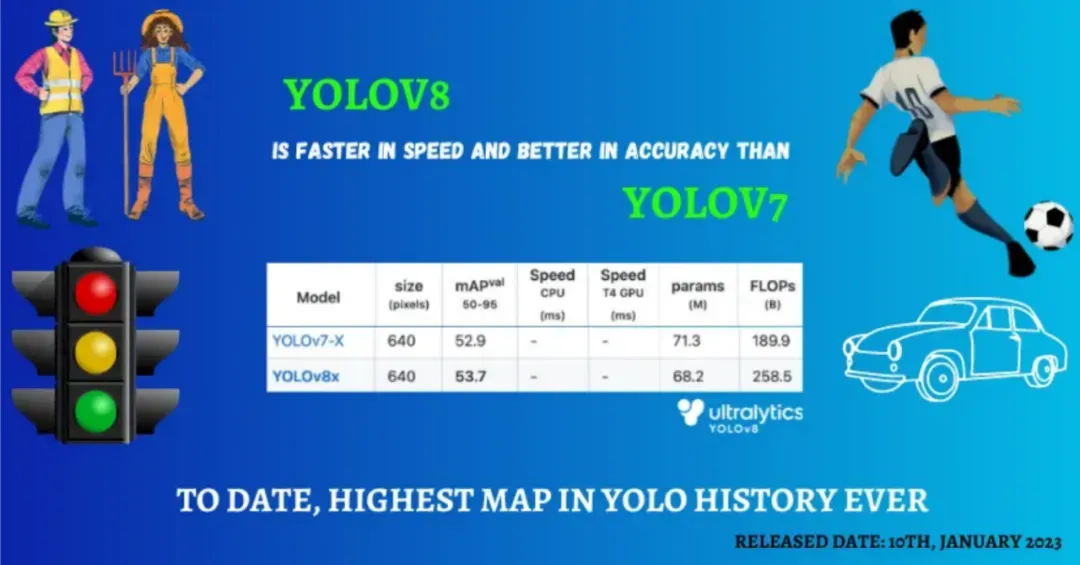
图1.2:YOLOv8平均精度均值
在本文中,我们将重点介绍训练YOLOv8自定义数据集所需的步骤。您可以按照下面提到的步骤在自己的数据上训练YOLOv8。所有提到的步骤都经过了适当的测试,在Windows和Linux操作系统上运行良好。
安装模块
预训练的目标检测
使用自定义数据训练YOLOv8
使用自定义权重进行推理
安装模块
YOLOv8发布了一个名为“ultralytics”的软件包,您可以使用下面提到的命令进行安装。
pip install ultralytics==8.0.0
or
# latestversion
pip install ultralytics以上命令将安装所有必要的软件包,以便您可以在自己的数据上使用YOLOv8进行检测和训练。
注意:请确保您的系统上安装了Python 3.7.0或更高版本。
预训练的目标检测
如果您只需要运行单个命令来以高效的方式进行目标检测并提供更准确和快速的结果,那您会有什么感受呢?
您可以在终端/(命令提示符)中运行以下命令,在所选视频/图像上使用预训练权重进行检测,使用YOLOv8。
#for image
yolo task=detect mode=predict model=yolov8n.pt source="test.png"
#for video
yolo task=detect mode=predict model=yolov8n.pt source="test.mp4"如果一切顺利,您将在当前目录内的“runs/detect/exp”文件夹中获得结果。

Fig-1.3: 预训练对象检测(作者提供的图像)
在自定义数据上训练 YOLOv8
训练 YOLOv8 对象检测模型的步骤可以概括如下:
收集数据
标记数据
划分数据集(训练集、测试集和验证集)
创建配置文件
开始训练
步骤 1:收集数据
为 YOLOv8 自定义训练创建一个数据集。如果没有数据,可以使用来自 openimages 数据库的数据集或以下网站提供的数据集:https://medium.com/nerd-for-tech/extraction-of-frames-from-multiple-videos-3ddbced6f3c2
YOLOv8 将标签数据存储在文本(.txt)文件中,格式如下:
<object-class-id> <x> <y> <width> <height>步骤 2:标记数据
您可以使用 labelImg 工具或 Roboflow 平台进行数据标注,具体取决于您的需求。如果您想了解 labelImg 工具的工作流程,可以查看以下文章:
https://medium.com/nerd-for-tech/labeling-data-for-object-detection-yolo-5a4fa4f05844
步骤 3:划分数据集(训练集、测试集和验证集)
当您想在自定义数据上训练计算机视觉模型时,将数据分成训练集和测试集非常重要。训练集用于教授模型如何进行预测,而测试集用于评估模型的准确性。常见的分割比例是 80-20%,但实际比例可能取决于数据集的大小和您正在处理的具体任务。例如,如果您有一个小数据集,您可能希望使用更高的百分比进行训练,而如果您有一个大数据集,您可以使用较小的百分比进行训练。
对于数据拆分,您可以查看 split-folders,它会将数据随机拆分为训练集、测试集和验证集。split-folders链接:https://pypi.org/project/split-folders/
文件夹结构:
├── yolov8
## └── train
####└── images (folder including all training images)
####└── labels (folder including all training labels)
## └── test
####└── images (folder including all testing images)
####└── labels (folder including all testing labels)
## └── valid
####└── images (folder including all testing images)
####└── labels (folder including all testing labels)步骤 4:创建配置文件
创建自定义配置文件可以是组织和存储计算机视觉模型的所有重要参数的有用方式。
在你已经打开终端/(命令提示符)的当前目录内创建一个文件名为“custom.yaml”的文件。将下面的代码粘贴到该文件中。设置数据集文件夹的正确路径,更改类及其名称,然后保存它。
path: (dataset directory path)
train: (Complete path to dataset train folder)
test: (Complete path to dataset test folder)
valid: (Complete path to dataset valid folder)
#Classes
nc: 5# replace according to your number of classes
#classes names
#replace all class names list with your classes names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane']注意:确保设置正确的训练和测试目录路径,因为训练过程将完全依赖于该文件。
步骤 5:开始训练
一旦你完成了预处理步骤,例如数据收集,数据标注,数据拆分和创建自定义配置文件,你可以使用下面在终端/(命令提示符)中提到的命令开始在自定义数据上训练YOLOv8。
yolo task=detect mode=train model=yolov8n.pt data=custom.yaml epochs=3 imgsz=640task = detect(可以是分割或分类)
mode = train(可以是预测或验证)
model = yolov8n.pt(可以是yolov8s / yolov8l / yolov8x)
epochs = 3(可以是任何数字)
imgsz = 640(可以是320、416等,但请确保它是32的倍数)

图1.5:在自定义数据上训练YOLOv8
如果有任何图像损坏,YOLOv8将不会开始在自定义数据上进行训练。如果一些标签文件损坏,那么训练不会有问题,因为YOLOv8将忽略这些(图像和标签)文件。
等待训练完成,然后使用新创建的权重进行推断。自定义训练的权重将保存在下面提到的文件夹路径中。
[runs/train/exp/weights/best.pt]
使用自定义权重推理
使用自定义权重进行推断时,请使用下面提到的命令进行检测。
yolo task=detect mode=predict model="runs/train/exp/weights/best.pt" source="test.png"
or
yolo task=detect mode=predict model="runs/train/exp/weights/best.pt" source="test.mp4"· END ·
HAPPY LIFE

文章出处登录后可见!