一、概述
这是2018年阿里Guorui Zhou等人发表在KDD上的一篇论文。论文提出在CTR任务中,丰富的用户历史行为数据包含了用户多种兴趣,对于不同的候选广告,起作用的用户历史行为数据表示应该不同。所以该论文提出了深度兴趣网络(Deep Interest Network, DIN)来根据指定广告,自适应的建模用户行为数据,进而提升CTR准确率。此外,针对工业界亿万级别的参数量,提出了两项训练深度学习模型的新技术:小批量感知正则(mini-batch aware regularization)和数据自适应激活函数(data adaptive activation function)。
二、INTRODUCTION
用户兴趣的实际情况:在一个电商网站中,用户可能同时对多种类型的商品感兴趣,即用户兴趣是多样的。用户兴趣通常由用户行为数据建模。
传统的对用户历史行为数据建模的方法是将用户的历史行为数据转化为一个固定长度的向量。一个固定长度的向量用于表示用户的不同兴趣。事实上,载体的表达能力是有限的。
为什么不扩大定长向量的维度,提高向量表达用户多样化兴趣的能力呢?
- 会增加待学习参数的规模,同时在训练数据有限的情况下会增加过拟合的风险;
- 增加的计算和存储负担,工业级在线系统可能无法容忍。
- 在预测给定广告的点击时,给定用户没有必要表达他所有的兴趣,因为只有部分用户的兴趣会影响这种行为。 (例如,一位女性游泳者会点击推荐的泳镜,主要是因为她买了泳衣,而不是上周购物清单上的鞋子。)
本文提出的深度兴趣网络DIN,针对给定的候选广告,建模与其相关的用户历史行为数据,自适应的计算用户的兴趣表示向量。该方法在有限的向量维度下,提升了模型对于用户兴趣的表示能力。
三、Motivation
CTR预估任务是,根据给定广告、用户和上下文情况等信息,对每次广告的点击情况做出预测。其中,对于用户历史行为数据的挖掘尤为重要,从这些历史行为中我们可以获取更多的关于用户兴趣的信息,从而帮助作出更准确的CTR预估。
许多应用于CTR预估的深度模型已经被提出。它们的基本思路是将原始的高维稀疏特征映射到一个低维空间中,也即对原始特征做了embedding操作,之后一起通过一个全连接网络学习到特征间的交互信息和最终与CTR之间的非线性关系。这里值得注意的一点是,在对用户历史行为数据进行处理时,每个用户的历史点击个数是不相等的,我们需要把它们编码成一个固定长的向量。以往的做法是,对每次历史点击做相同的embedding操作之后,将它们做一个求和或者求最大值的操作,类似经过了一个pooling层操作。论文认为这个操作损失了大量的信息,于是引入attention机制,提出一种更好的表示方式。
论文的动机是从用户有丰富的历史行为中捕捉用户兴趣,从而提升广告CTR。基于对阿里电商领域广告业务的实践与思考,文中指出用户兴趣有如下两个特点:
- 多样性(Diversity) 即用户在线上购物时往往同时表现出多种兴趣,这个很好理解,例如从一个年轻妈妈的历史行为中,可以看到她的兴趣非常广泛:羊毛衫、帆布包、耳环、童装、奶粉等等。
- 局部聚焦(Local Activation) 即用户是否会点击推荐给他的某一件商品,往往是基于他之前的部分兴趣,而非所有兴趣。例如,对一个热爱游泳与吃零食的用户,推荐给他一个泳镜,他是否会点击与他之前购买过泳裤、泳衣等行为相关,但与他之前买过冰淇淋、旺仔牛仔等行为无关。
受到NLP里提出的Attention机制启发,Deep Interest Network (DIN) 采用来类似机制实现用户兴趣的Diversity和Local Activation。直观理解,Attention机制就是对不同特征赋予不同weight,这样某些weight高的特征便会主导这一次的预测,就好像模型对这些特征pay attention。DIN针对当前候选广告局部地激活用户的历史兴趣,赋予和候选广告相关的历史兴趣更高的weight,从而实现Local Activation,而weight的多样性同时也实现了用户兴趣的多样性表达。
四、DIN模型详解
4.1 特征表示
在阿里的系统中使用的特征集合如下表所示,总共包含4类特征,其中丰富的用户行为特征包含了用户兴趣。在这篇论文中没有使用组合特征,旨在通过深度神经网络来获取组合特征。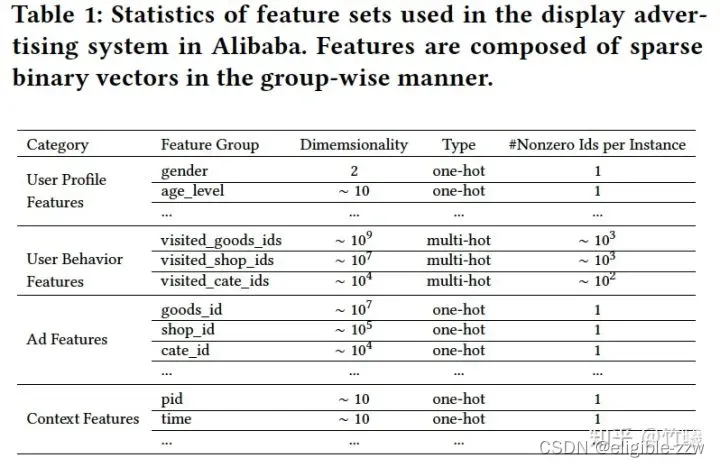
特征类型说明:
goods类表示商品ID;
shop类特征表示店铺ID;
cate类特征表示商品种类ID。
所以用户行为特征/广告特征是从这3个维度来刻画不同商品信息的。
4.2 一般CTR网络结构:
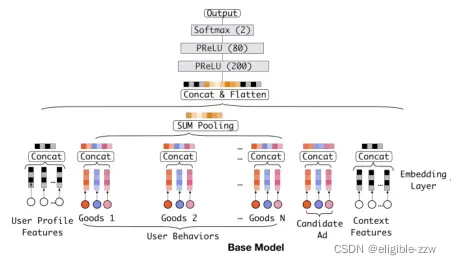
输入数据:
1.用户属性特征(每种属性都有其对应的one-hot表示);
2.用户行为特征(用户点击的每种货物包含3部分特征,商品ID、店铺ID、商品种类ID),输入一般会罗列用户最近点击的N种货物,多了剪短,少了padding 0补全;
3.候选广告特征(同货物一样,由相同的3部分特征组成);
4.情景特征(包含一些时间等背景特征)
Embedding层:
将one-hot向量分别转化为低维稠密向量;
Concat层和Pooling层:
将用户行为特征进行pooling操作。一般有求和pooling、平均pooling。
具体计算方法是将所有用户行为特征相加或平均,然后得到定长用户行为特征的向量表示。
将另外3种类别的特征,各自内部进行concat操作。
Concat层:
将上述操作获取的各个类别的特征进行concat,得到一个整体的特征表示。
MLP层:
上面得到的特征使用全连接层自动学习得到最终的点击预测结果。
损失函数:
负对数似然函数,如下:
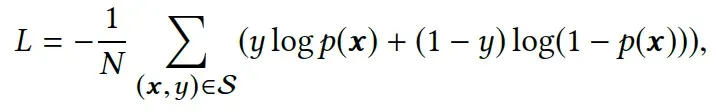
4.3 DIN网络结构
DIN的网络结构并不复杂,下图描述得非常清晰。它遵循传统的Embedding&MLP框架,即先对one-hot特征做embedding,对multi-hot特征做embeddings后再做pooling得到定长的embedding,随后将它们拼接作为DNN的输入。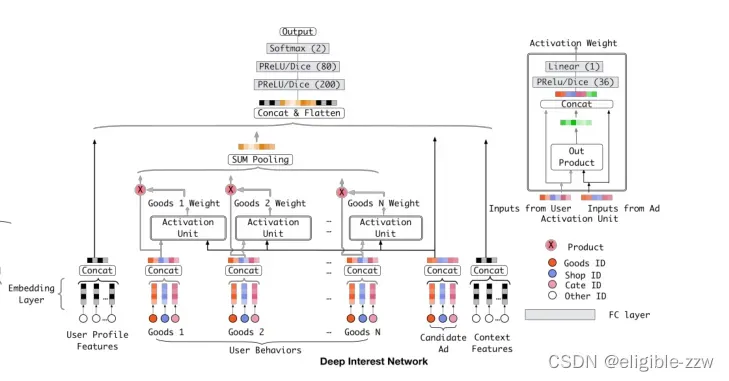
输入数据:
同一般CTR网络结构。
Embedding层:
同一般CTR网络结构。
Concat层和Pooling层:
在处理用户行为数据时,在concat层后,先添加了激活单元,计算出每个用户行为针对与当前选定广告的相关度(即权重),然后再采用加权求和的方式计算sum pooling。
这样,针对不同的广告,根据用户行为计算出的用户兴趣特征表示是不同的,这也符合我们通常对用户兴趣与用户行为关系的观察。
激活单位:
激活单元的输入为两个部分,一个是用户的其中一个行为的向量表示,另一个是待计算点击率的广告的向量表示,这两个部分首先计算对位点乘得到新的向量表示(文中写得是外积,感觉是作者这里写错了,实际就是对位点乘),将这三个向量concat到一起,经过两层全链接层的表示,得到该广告对于用户行为的权重。这里得到的权重分别各自对应的用户行为特征相乘,然后再做sum pooling,从而得到广告关注下的用户行为特征表示。
注意:
这篇论文在这里得到的广告对用户行为的权重没有经过我们常规理解的激活函数,同时,不同行为之间的权重也没有使用softmax使得权重之和为0,而是仅仅使用了全连接层的线性变换得到的实数。
为什么不在这里规范化?
初步一看,感觉不符合常理,因为归一化更加可以解释用户的兴趣分布,比如总体就是1,然后不同的部分分别是用户兴趣的百分比。这里作者解释,激活单元直接得到的值在某种程度上是激活用户兴趣的近似值。比如在T恤和手机两个候选广告中,T恤激活了大部分属于服装的历史行为,并可能获得比手机更大的权重值。传统的注意方法通过对激活单元的输出进行归一化,在权重值的数值尺度上失去了分辨率,所以这里不进行归一化。
4.4 Activation Unit (AU)
DIN的关键点在于 AU 的设计,DIN会计算候选广告与用户最近N个历史行为商品的相关性权重weight,将其作为加权系数来对这N个行为商品的embeddings做sum pooling,用户兴趣正是由这个加权求和后的 [公式] 来体现。
AU 通过 weight 的多样化实现了更Diverse的用户兴趣表达。而 weight 是根据候选广告与历史行为一起决定的,即使用户的历史行为相同,但不同的候选广告与各个行为的weight也是不同的,即用户兴趣表示也是不同的。DIN希望通过 Activation Unit 实现“pay attension”,即赋予和候选广告相关的历史兴趣更高的weight,从而实现Local Activation。AU 内部是一个简单的多层网络,输入是候选广告的embedding、历史行为商品的embedding、以及两者的叉乘。
- 为什么增加叉乘作为输入呢?因为两个embedding的叉乘是显示地反映了两者之间的相关性,加入后有助于更好学习weight。
- 为什么选叉乘而非其他形式呢?其实论文的初版使用的是两个embedding的差,发表的最新版才转为使用叉乘,相信也都是经过了一系列的尝试和实验对比。
- 为什么使用简单的MLP实现AU呢?同样是尝试出来的,作者也尝试过 LSTM结构实现AU,效果并不理想。文中给出的一个possible解释是,文本是在语法严格约束下的有序序列,而用户历史行为序列可能包含了多个同时存在的用户兴趣点,用户会在这些兴趣点之间“随意切换”,这使得这个序列并不是那么严格的“有序”,产生了一些噪声。
传统深度模型和DIN模型的对比如下图: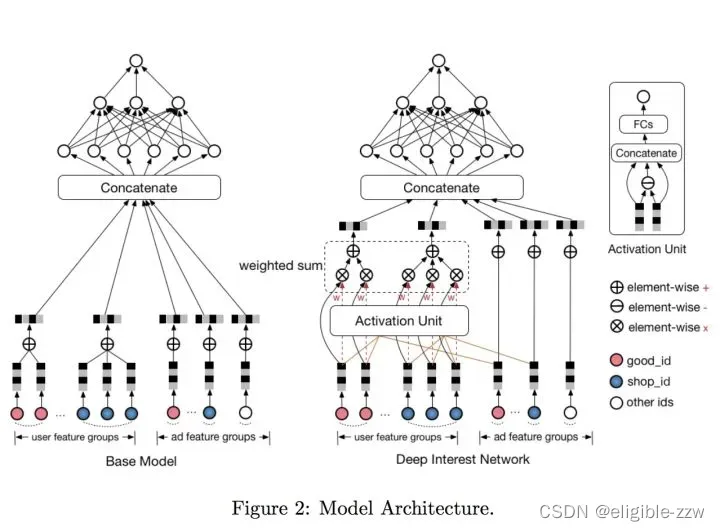
DIN模型在对用户的表示计算上引入了attention network (也即图中的Activation Unit) 。DIN把用户特征、用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过attention network,对每个兴趣表示赋予不同的权值。这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的,如此模型结构符合了之前的两个观察——用户兴趣的多样性以及部分对应。attention network 的计算公式如下, Vu代表用户表示向量, Vi 代表用户兴趣表示向量, Va代表广告表示向量: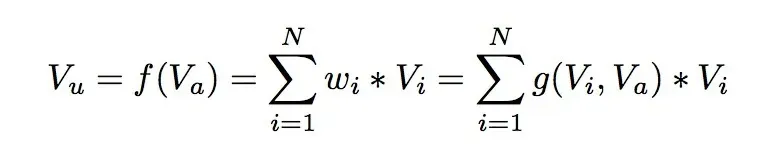
五、Training Techniques
文中提出了两个技巧来辅助工业级深度网络模型的训练,同时也提升了DIN的性能。
- Adaptive Regularization / Mini-batch Aware Regularization(MAR)

在阿里的实际业务中使用深度学习的时候,作者发现深度学习可能会过拟合,尤其是在大规模的ID特征上(例如本文介绍的 good_id 特征维度就到达了6亿),当参数量非常大,模型很复杂时,非常容易过拟合。这点在下面介绍的实验部分图1可以看出来,可以看到直接使用DIN在第一轮训练后training loss就下降得很厉害,但test loss却在之后升高。
论文初版中解释,使用的特征具有显著的“长尾效应”,即很多feature id只出现了几次,只有小部分feature id出现多次,这在训练过程中增加了很多噪声,并且加重了过拟合。谷歌团队在Deep&Wide中解释Deep部分也提出了类似的问题:
但在推荐系统中,当user-item matrix非常稀疏时,例如有和独特爱好的users以及很小众的items,NN很难为users和items学习到有效的embedding。这种情况下,大部分user-item应该是没有关联的,但dense embedding 的方法还是可以得到对所有 user-item pair 的非零预测,因此导致 over-generalize并推荐不怎么相关的物品。
很有趣的是,Deep&Wide解释这导致了“over-generalize“,而DIN论文初版解释这导致了“over-fitting”。两种解释的出发点不同,DIN从train/test的整体loss曲线关注过拟合情况,而Deep&Wide关注推荐物品的相关性,导致的后果都是一致的,即模型在测试集或线上的效果下降。
正则化是处理过拟合的常见技巧,但正则方法在稀疏数据深度学习上的使用,还没有一个公认的好方法。论文使用的特征具有显著的稀疏性,对绝大部分样本来说,很多特征都是0,只有很小一部分特征非0。但直接使用正则,不管特征是不是0都是要正则的,要梯度计算。对大规模的稀疏特征,参数规模也非常庞大(最大头的参数来源就是embedding),这种计算量是不可接受的。
文中提出了自适应正则,即每次mini-batch,只在非0特征对应参数上计算L2正则(针对特征稀疏性),且正则强度与特征频次有关,频次越高正则强度越低,反之越高(针对特征长尾效应)。例如,在第m次mini-batch训练,对第 j 个特征的embedding向量 Wj的梯度更新:

- 数据自适应激活函数 – Data Adaptive Activation Function (Dice)


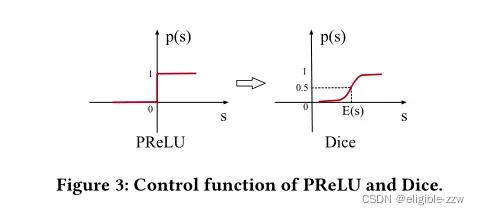
Dice的主要动机是随数据分布变化动态地调整 rectified point,虽说是动态调整,其实它也把rectified point限定在了数据均值 E[s] ,实验显示对本文的应用场景Dice比PRelu效果更好。
六、Experiments
- 实验装置
数据集 文中使用了2个公开数据集以及阿里实际业务数据集,实验中详细设置如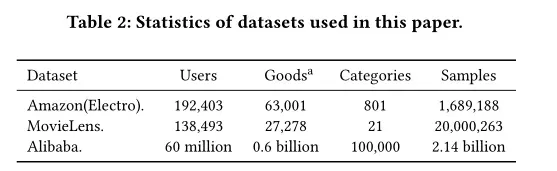
Amazon平均每个user / goods对应5条review,用户行为信息丰富。特征包含good_id、cate_id, user reviewed good_id_list, cate_id_list 四类。假设用户对n个goods产生过行为,取用户review过的前k个good作为训练( k <= n-2),目标是预测第k+1个用户review的good,测试时,将前n-1个good作为历史行为,预测最后一个review的good。使用SGD+exponential decay优化,初始学习率1,衰减率0.1,mini-batch大小32。
MovieLens用户对电影进行0-5的打分,将用户打分4-5的作为正例,其他作为负例,随机将 100000个user划分到train,剩下划分到test,目标是预测某部电影用户是否会打出高于3的评分。特征包含 movie_id, movie_cate_id, user rated movie_id_list, movie_cate_id_list 四类,其他配置与Amazon一致。
Alibaba取过去某2周线上产生的数据作为train,紧接着一天的数据作为test。因为数据量巨大,mini-batch大小设为5000,使用Adam+exponential decay 作为优化器,初始学习率0.001,衰减率0.9。
离线指标 使用GAUC与RelaImpr两个指标,其表达式分别如下: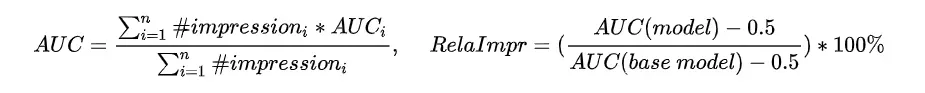
其他设置 实验中Embedding的维度设为12,MLP结构设为192 × 200 × 80 × 2。
- 实验结果
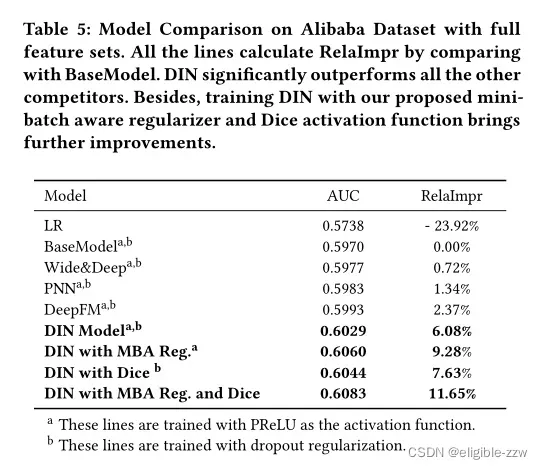
在公开数据集上的实验结果如下表所示,其中BaseModel可以看成DIN结构中去除了AU设计,是传统的Embedding&MLP框架。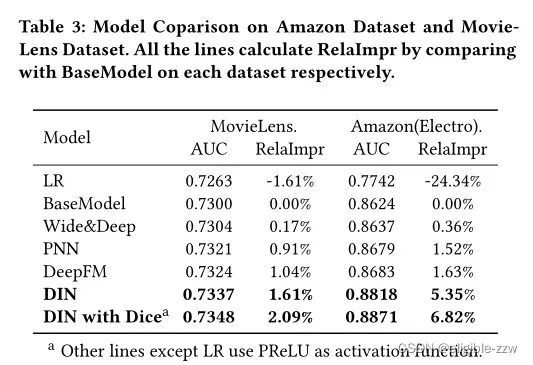
这两个数据集上的特征维度并不高(10万左右),过拟合问题并不明显,但在Alibaba数据集中过拟合合问题非常严重,下面在以BaseModel为例,使用不同的防过拟合方法的实验结果,本文提出的MBA效果最好: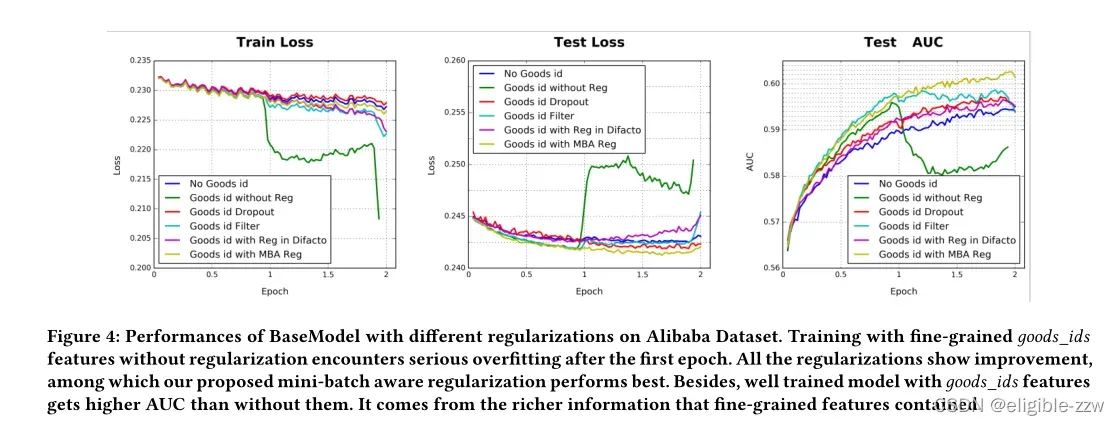
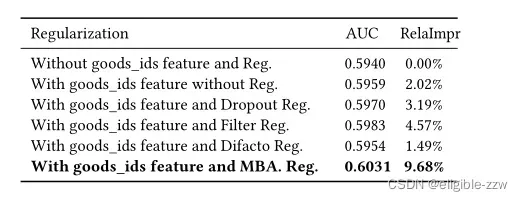
加上MBA与Dice后,在Alibaba数据集上的实验结果如表3所示。此外,在2017.5-2017.6的线上ab测试中,DIN使广告CTR与RPM分别提高了10%与3.8%,目前已经成为主流量模型。
- 视觉实验
以一个候选广告为例,与某用户历史行为商品的weight输出如下,可以看到相关的衣服类商品的weight较高,说明 DIN 实现了用户兴趣的 Local Activation。
此外,论文随机选取了9个类别,各类别100个商品,同类商品用同样形状表示,通过t-SNE对它们在DIN种的embedding结果进行可视化。如下图所示,特征空间中的向量地展现出很好的聚类特性。另外,图中点的颜色代表了DIN预测的某个特定用户购买这个商品的可能性,颜色越暖表示预测值越高,下图反映了用户兴趣分布,可看到该用户的兴趣分布有多个峰,说明DIN捕捉到了用户兴趣的Diversity。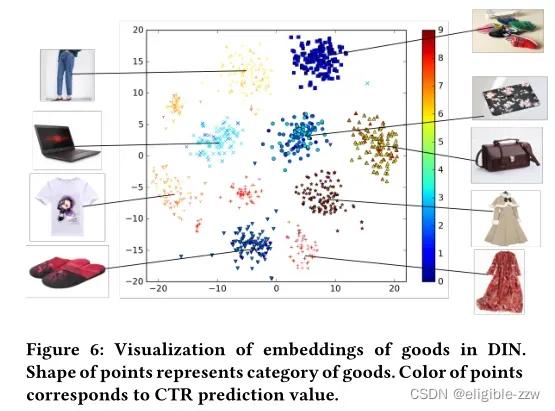
七、总结(Conclusion)
- 通过对实际业务的观察思考,提出了用户兴趣具有 Diversity 与 Local Activation 两个特点
- 提出 Deep Interest Network,DIN 从用户历史行为中挖掘用户兴趣,针对每个候选广告,使用Activation Unit计算其与用户历史行为商品的相关weight,有效捕捉了用户兴趣的两个特点
- 在模型训练优化上,提出了Dice激活函数与自适应正则,有效提升了模型性能
- 在公开数据集以及Alibaba实际数据集中取得了非常有效的提升
版权声明:本文为博主eligible-zzw原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/zhaozhiwei314/article/details/123024809