一、思路和基础知识
因为我们要进行文件相关的操作,所以需要在一开始使用import导入Python内置的os模块。
我们需要先获取该文件夹下所有的答题卡列表,再使用for循环遍历文件夹中所有学生的答题卡,以便之后逐个读取信息。
完成了第一个步骤,接下来,我们就需要在for循环里,依次获取每位学生的班级、姓名、学号、选择题分数和填空题分数。
面对总共三个班的学生,每位学生都有相对应的五条信息,我们应该如何在程序中存储这些数据呢?我们可以在for循环内,使用字典来存储每位学生的信息。在这个字典中,我们用5个键(key)值(value)对来分别存储学生的班级、姓名、学号、填空题成绩和选择题成绩。键的名称和对应数据如图所示。
确定使用字典来存储每个学生的数据后,我们可以在for循环外,使用一个列表来汇总存储所有学生的字典数据。如图所示:列表中的每个元素就是一个装了学生信息的字典。
# 使用import导入os模块
import os
# 将乔老师的答题卡文件夹路径 /Users/qiao/answerKey 赋值给变量allKeyPath
allKeyPath = "/Users/qiao/answerKey"
# 使用os.listdir()函数获取该路径下所有的文件,并赋值给变量allItems
allItems = os.listdir(allKeyPath)
# 定义一个空列表allStudentsData存储所有学生数据
allStudentsData = []
# 使用for循环逐个遍历所有学生答题卡
for item in allItems:
# 定义一个空字典studentData存储单个学生数据
studentData = {}
# 使用os.path.splitext()函数获取文件名的前半段,并赋值给变量fileName
fileName = os.path.splitext(item)[0]
# 使用split()函数以"-"分隔文件名,将第1部分班级信息赋值到学生数据字典的classInfo键里
studentData["classInfo"] = fileName.split("-")[0]
# 使用split()函数以"-"分隔文件名,将第2部分姓名信息赋值到学生数据字典的name键里
studentData["name"] = fileName.split("-")[1]
# 使用append()函数将studentData添加到总学生数据allStudentsData中
allStudentsData.append(studentData)
# 使用print输出变量allStudentsData
print(allStudentsData)
刚刚我们已经完成了前两步,现在我们来完成第三步:确定答题卡中要读取的信息位置。
在开始确定答题卡中要读取的信息位置前,我们需要先学习一下Word文档的基本结构。
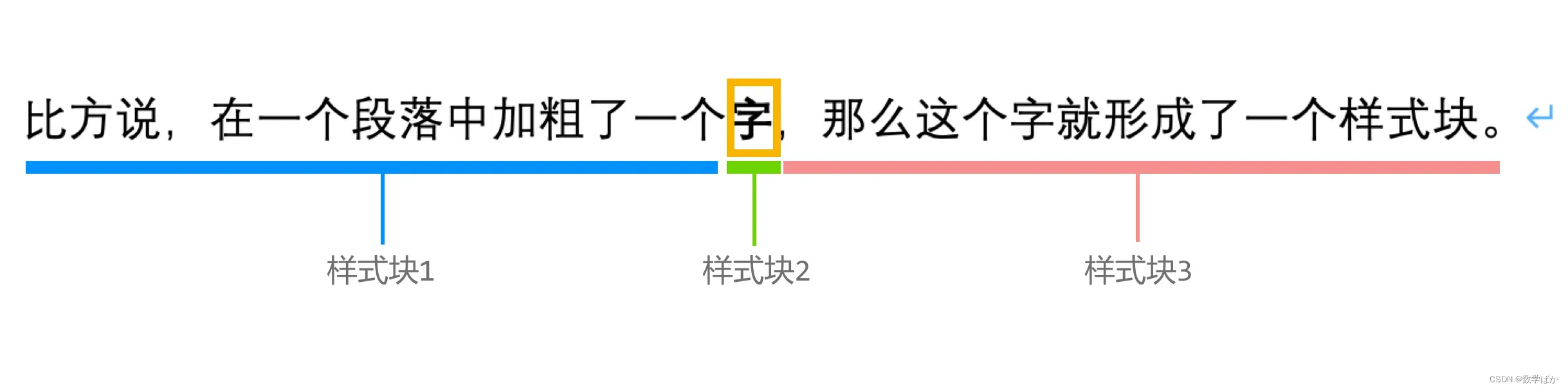
一个Word文件就是一个Word文档(Document)。Word文档(Document)的基本组成单位是段落(Paragraph)。标题、目录、正文、图形、空行都是段落。每个段落之中的内容可以具有不同的样式(Style)。常见的样式有:字体、字形、字号、字体颜色、下划线、删除线、上标和下标等。连续具有相同样式的基本单元可称为一个样式块(run)。 例如,图中这一段话原本是同一个样式块。但在这个段落中加粗一个字,那么这个字就形成了一个样式块。并且这个加粗的字的左右两边都被切割成了新的样式块。这样这句话就变成了三个样式块。 没有任何内容的空行段落里没有样式块。段落里只要有内容就至少包含一个样式块。
除了段落外,Word文档中还能嵌入表格(Table)。表格和段落在Word文档中属于并列级别。也就是说表格不属于任何段落,我们不能够通过遍历段落来获取表格。
和Excel表格的结构很相似,Word文档中的表格也是由单元格(Cell)组成。 单元格中的内容可以包含段落和表格,相当于独自构成了一个完整的Word文档。
和Excel表格的结构很相似,Word文档中的表格也是由单元格(Cell)组成。 单元格中的内容可以包含段落和表格,相当于独自构成了一个完整的Word文档。
二、安装docx
要使用Python对Word文档进行读取,我们需要安装一个用于读取数据的工具python-docx。
python-docx是一个用于创建和更新Word文档的开源模块。需要注意的是,该模块只可读取、写入.docx文件,不支持.doc文件。
安装python-docx非常简单,在终端中输入代码:pip install python-docx即可。
如果在自己电脑上安装不上或安装缓慢,可在命令后添加如下配置进行加速:
pip install python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple/
三、读取doc文档
在安装和导入python-docx之后,读取指定路径下的Word文档需要使用函数:docx.Document()。只需将Word文档的路径作为参数传入该函数中即可。docx.Document()函数读取成功后,会返回一个Word文档对象。
乔老师要读取文件夹中的每一份答题卡,就需要在for循环里,先使用os.path.join()函数拼接出当前答题卡的路径。我们将拼接好的路径赋值给了keyPath。 然后,再将keyPath作为参数传入到***docx.Document()***函数内即可。 我们把读取出来的结果赋值给了变量doc,并输出进行查看。
可以看到,读取出的结果是一个个的Word文档对象。
# 使用import导入os模块
import os
# 使用import导入docx
import docx
# 将乔老师的答题卡文件夹路径 /Users/qiao/answerKey 赋值给变量allKeyPath
allKeyPath = "/Users/qiao/answerKey"
# 使用os.listdir()函数获取该路径下所有的文件,并赋值给变量allItems
allItems = os.listdir(allKeyPath)
# 定义一个空列表allStudentsData存储所有学生数据
allStudentsData = []
# 使用for循环逐个遍历所有学生答题卡
for item in allItems:
# 定义一个空字典studentData存储单个学生数据
studentData = {}
# 使用os.path.splitext()函数获取文件名的前半段,并赋值给变量fileName
fileName = os.path.splitext(item)[0]
# 使用split()函数以"-"分隔文件名,将第1部分班级信息赋值到学生数据字典的classInfo键里
studentData["classInfo"] = fileName.split("-")[0]
# 使用split()函数以"-"分隔文件名,将第2部分姓名信息赋值到学生数据字典的name键里
studentData["name"] = fileName.split("-")[1]
# 使用os.path.join()函数拼接出答题卡路径,并赋值给变量keyPath
keyPath = os.path.join(allKeyPath, item)
# 读取答题卡并赋值给变量doc
doc = docx.Document(keyPath)
# 使用print输出doc
print(doc)
# 使用append()函数将studentData添加到总学生数据allStudentsData中
allStudentsData.append(studentData)
结果
<docx.document.Document object at 0x7f7b215519b0>
<docx.document.Document object at 0x7f7b21555be0>
<docx.document.Document object at 0x7f7b2155ea00>
<docx.document.Document object at 0x7f7b215657d0>
<docx.document.Document object at 0x7f7b215685a0>
<docx.document.Document object at 0x7f7b21568f50>
<docx.document.Document object at 0x7f7b2156cd20>
<docx.document.Document object at 0x7f7b214f1eb0>
<docx.document.Document object at 0x7f7b214f6c80>
<docx.document.Document object at 0x7f7b214f8a50>
四、读取段落
逐个读取答题卡后,我们可以访问Word文档(Document)中的 .paragraphs 属性,来获取文档中的段落列表。
段落列表的组成元素是所有的段落对象,可以使用索引定位到指定的段落对象。
import docx
doc = docx.Document("假装这是一份答题卡.docx")
para = doc.paragraphs[3]
五、读取指定样式
获取了第四段的段落对象后,还需要读取这一段中指定的样式块。要获取段落中的样式块列表,需要访问段落对象中的 .runs 属性。样式块列表的组成元素是所有的样式块对象。同样,可以通过 索引 获取到指定的样式块。
通过上节课的定位,我们知道了学生学号具体位于第4段中的第2个样式块。

那么,用2这个数字减一即可得到对应的索引来进行读取,具体代码如下:
# 使用import导入os模块
import os
# 使用import导入docx
import docx
# 将乔老师的答题卡文件夹路径 /Users/qiao/answerKey 赋值给变量allKeyPath
allKeyPath = "/Users/qiao/answerKey"
# 使用os.listdir()函数获取该路径下所有的文件,并赋值给变量allItems
allItems = os.listdir(allKeyPath)
# 定义一个空列表allStudentsData存储所有学生数据
allStudentsData = []
# 使用for循环逐个遍历所有学生答题卡
for item in allItems:
# 定义一个空字典studentData存储单个学生数据
studentData = {}
# 使用os.path.splitext()函数获取文件名的前半段,并赋值给变量fileName
fileName = os.path.splitext(item)[0]
# 使用split()函数以"-"分隔文件名,将第1部分班级信息赋值到学生数据字典的classInfo键里
studentData["classInfo"] = fileName.split("-")[0]
# 使用split()函数以"-"分隔文件名,将第2部分姓名信息赋值到学生数据字典的name键里
studentData["name"] = fileName.split("-")[1]
# 使用os.path.join()函数拼接出答题卡路径,并赋值给变量keyPath
keyPath = os.path.join(allKeyPath, item)
# 读取答题卡并赋值给变量doc
doc = docx.Document(keyPath)
# 读取第四段学号段,并赋值给变量idPara
idPara = doc.paragraphs[3]
# 读取学号段中第二个样式块,并赋值给变量idRun
idRun = idPara.runs[1]
# 使用append()函数将studentData添加到总学生数据allStudentsData中
allStudentsData.append(studentData)
六、读取指定内容
刚刚我们获取到的是段落和样式块对象,要想读取到真正的文本内容,需要通过***.text***属性来访问。不同的需求对应不同的操作。
比如:如果想读取某一段落中的所有文本,就使用**.paragraphs[{段落索引}]**获取到段落对象后,再访问它的.text属性;
如果想读取某一个样式块中的文本内容,则是在使用***doc.paragraphs[{段落索引}].runs[{样式块索引}]***读取到具体的样式块对象后,访问.text属性。
本例中,展示了读取学号的具体代码,也就是读取第四段的第二个样式块的文本内容。我们将读取出来的结果存储到了studentData字典里的id键中。在代码最后,使用print输出了存储所有学生信息的列表allStudentsData
# 使用import导入os模块
import os
# 使用import导入docx
import docx
# 将乔老师的答题卡文件夹路径 /Users/qiao/answerKey 赋值给变量allKeyPath
allKeyPath = "/Users/qiao/answerKey"
# 使用os.listdir()函数获取该路径下所有的文件,并赋值给变量allItems
allItems = os.listdir(allKeyPath)
# 定义一个空列表allStudentsData存储所有学生数据
allStudentsData = []
# 使用for循环逐个遍历所有学生答题卡
for item in allItems:
# 定义一个空字典studentData存储单个学生数据
studentData = {}
# 使用os.path.splitext()函数获取文件名的前半段,并赋值给变量fileName
fileName = os.path.splitext(item)[0]
# 使用split()函数以"-"分隔文件名,将第1部分班级信息赋值到学生数据字典的classInfo键里
studentData["classInfo"] = fileName.split("-")[0]
# 使用split()函数以"-"分隔文件名,将第2部分姓名信息赋值到学生数据字典的name键里
studentData["name"] = fileName.split("-")[1]
# 使用os.path.join()函数拼接出答题卡路径,并赋值给变量keyPath
keyPath = os.path.join(allKeyPath, item)
# 读取答题卡并赋值给变量doc
doc = docx.Document(keyPath)
# 读取第四段学号段,并赋值给变量idPara
idPara = doc.paragraphs[3]
# 读取学号段中第二个样式块,并赋值给变量idRun
idRun = idPara.runs[1]
# 读取学号,并赋值到学生数据字典的id键里
studentData["id"] = idRun.text
# 使用append()函数将studentData添加到总学生数据allStudentsData中
allStudentsData.append(studentData)
# 使用print输出变量allStudentsData
print(allStudentsData)
七、读取Word内置段落样式名称
第11课中,我们提到“每个段落之中的内容可以具有不同的样式(Style)”。在python-docx模块中,每一个内置样式都有不同的样式名称。
通过访问段落下的 .style 属性,可以获取段落中的样式列表。
然后,再通过访问样式列表下的 .name 属性,就可以获取到真正的样式名称啦。
例如,获取段落para的样式名称,并赋值给变量styleName的代码为:
styleName = para.style.name
“万能思路”是Word文档中的Title(标题)
“适用题目”是Word文档中的Heading 1(标题 1)
“练习”是Word文档中的Heading 2(标题 2)
“答案”是Word文档中的Normal(正文)
八、遍历索引
简单来说,enumerate()函数用来遍历一个可遍历对象中的元素,同时通过一个计数器变量记录当前元素所对应的索引值。
比如刚才的代码中:
存储标准答案的列表standardTwo可以作为可遍历的对象;
而记录学生答案的索引idx则可以看作是用于计数的变量。
***enumerate()***函数常用于for循环中。当我们既需要一个计数器,又需要可遍历对象的值时,就可以使用enumerate()函数。
1)修改起始索引
要设置索引的初始值,可以直接将初始值作为可选参数传入enumerate()函数中。比如,我们希望idx从8开始,直接将8传入enumerate()中即可。根据输出可以看到,现在idx的值,就是学生填空题答案的段落索引,起始值为8。
# 使用for循环和enumerate()函数
# 遍历储存标准答案的列表standardTwo的同时
# 生成一个从8开始的index
for idx,value in enumerate(standardTwo,8):
# 格式化输出:索引值n所对应的列表元素是xxx
print(f"索引值{idx}所对应的列表元素是{value}")
#value用于在for循环里,存储遍历时standardTwo中的元素。
#idx相当于一个计数器变量,用于在for循环里,记录standardTwo里各元素所对应的索引值。
结果
索引值8所对应的列表元素是东临碣石
索引值9所对应的列表元素是行舟绿水前
索引值10所对应的列表元素是孤山寺北贾亭西
九、批量写入Word文档的表格
需要注意的是,Excel工作簿中这几列存储的数据是整型(int),不是字符串。
但是add_text()和add_run()函数的参数只能接收字符串类型,所以在读取数据时需要将整型数据转化为字符串。
1、数据类型转为字符串
在Python中,可以通过***str()***函数,将一个对象转化为string格式。只需将需要转换的对象作为参数,传入str()函数中即可。
文章出处登录后可见!