本文的代码整理来自b站大佬Bubbliiiing和霹雳吧啦Wz的视频整理,感兴趣的朋友可以去观看相关视频,本博客是对该视频内容的学习总结经验,如有不正确的地方,还望指出。
接下来先介绍一下V3网络,后续说V3+网络
内容
DeepLabV3网络的介绍
ASPP结构的改动
两种型号的区别
DeepLabV3+网络
增强的特征提取网络描述
DeepLabV3网络的介绍
相比于V2网络,V3网络的改进有如下三点:
1、引入了Multi-grid,可以输入大分辨率图片
2、对ASPP结构进行改进
3、将CRFs后处理删掉
ASPP结构的改动
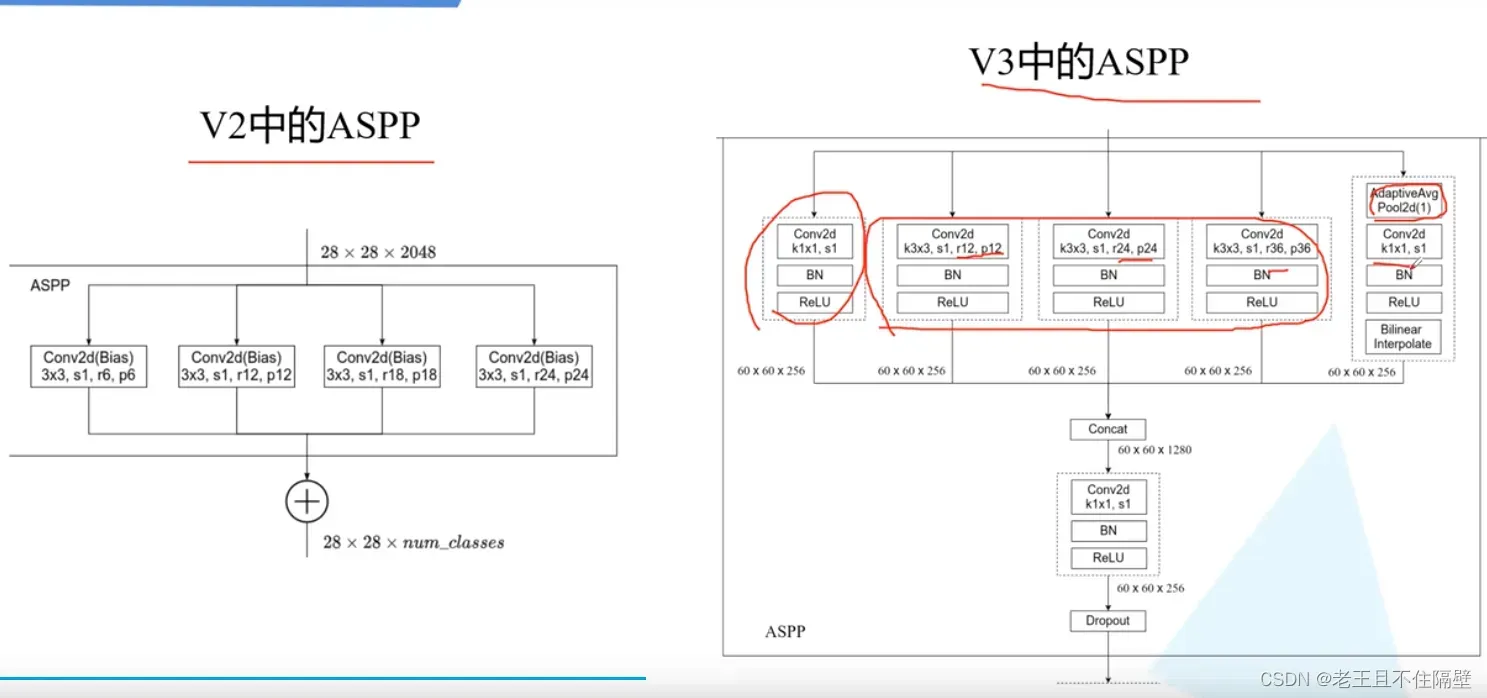
由上图可发现,V2的ASPP结构是通过四个相同3 * 3 膨胀卷积,没有使用BN(Batch-Normalization,膨胀系数不同;(r=rate,p=padding)
V3的ASPP结构是通过一个1*1普通卷积,三个3*3的膨胀卷积,一个全局平均池化层(后接1*1卷积,通过双线性差值得到输入的W,H),使用了BN和ReLu,膨胀系数不同。
两种型号的区别
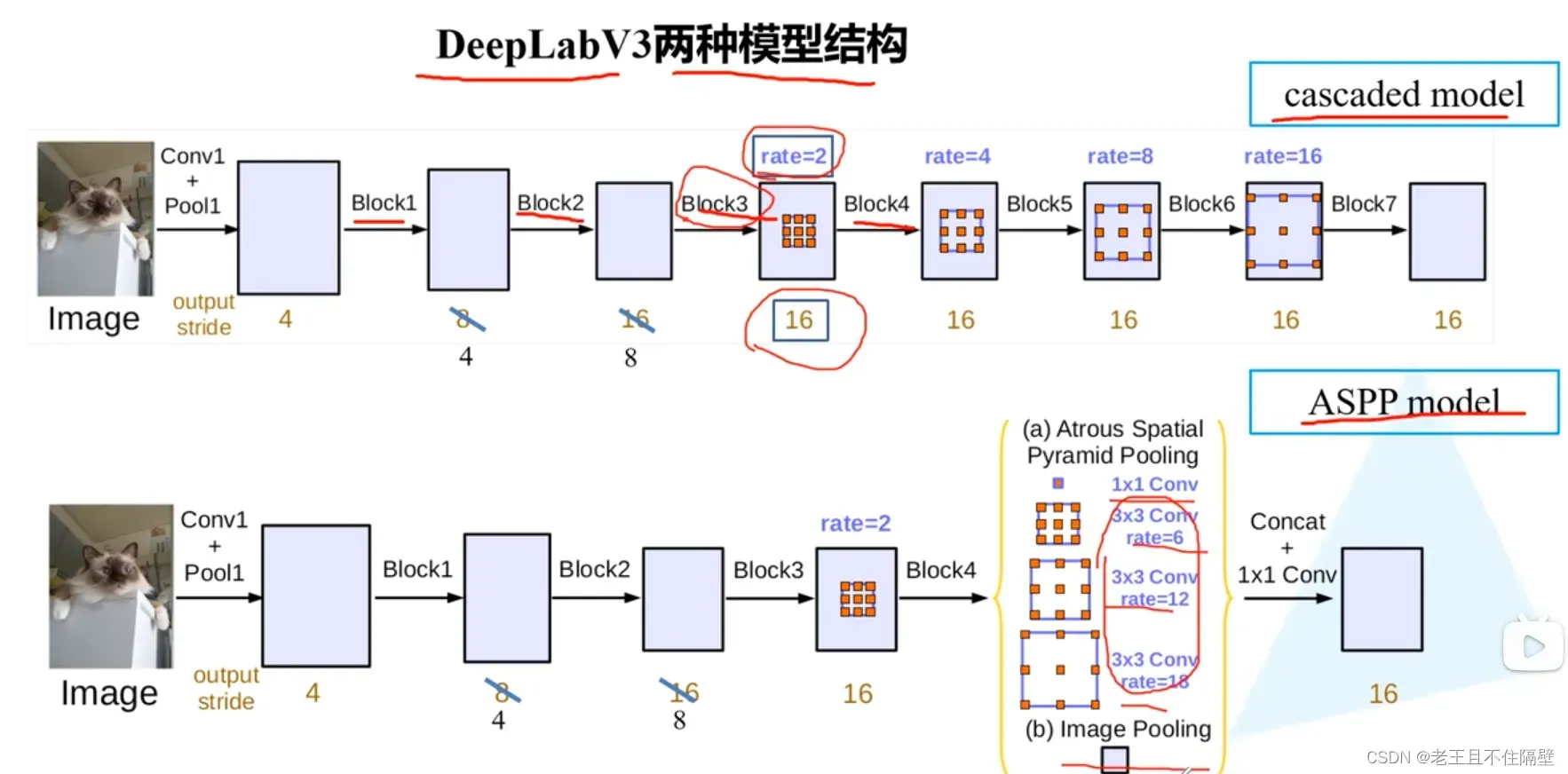
由图知,两种结构分别为cascaded model级联型 和 ASPP model金字塔池化型
cascaded model中Block1,2,3,4是ResNet网络的层结构(V3主干网络采用ResNet50或101),但Block4中将3*3卷积和捷径分支1*1卷积步长Strid由2改为1,不进行下采样,且将3*3卷积换成膨胀卷积,后面的Block5,6,7是对Blockd的copy。(图中rate不是真正的膨胀系数,真正的膨胀系数=rate * Multi-grid参数)
论文中使用较多的结构还是还是ASPP模型,两者模型在效果上差距不大。
DeepLabV3+网络
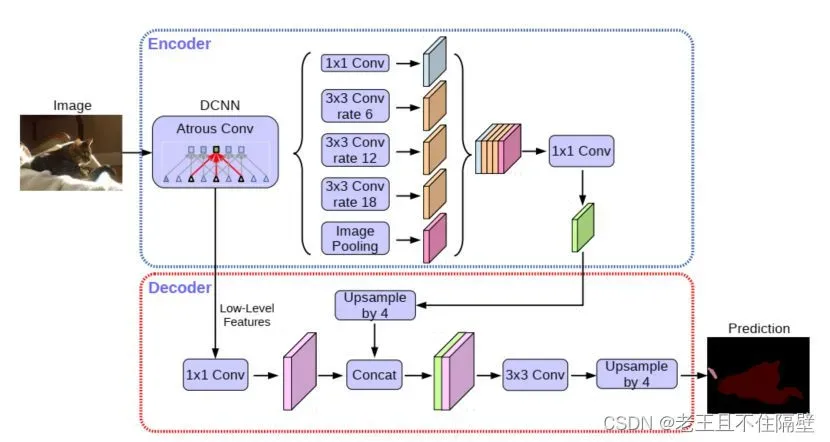
网络主要分为两个部分,Encoder,Decoder;论文中采用的是Xception作为主干网络(在代码中也可以根据需求替换成MobileNet),然后使用了ASPP结构,解决多尺度问题;为了将底层特征与高层特征融合,挺高分割边界准确度,引入Decoder部分。
增强的特征提取网络描述
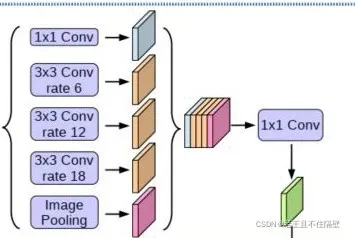
1、在Encoder部分,对压缩四次的初步有效特征层利用ASPP结构特征提取,然后进行合并,再进行1×1卷积压缩特征。如下图
2、在Decoder中,我们会对压缩两次的初步有效特征层利用1×1卷积调整通道数,与上面经过ASPP处理的特征进行连接,之后进行两次卷积操作得到最终的特征图。
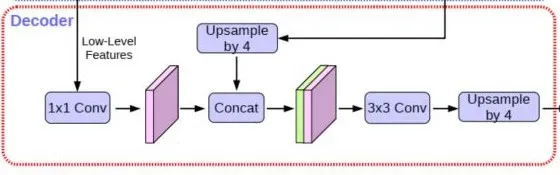
3、利用得到的最终特征图,进行预测,还需两步操作
(1)利用一个1×1卷积进行通道调整,调整成类别总数目
(2)resize,上采样使输出预测图片恢复原图大小。
后续博客将介绍用V3+代码训练自己的数据集。
文章出处登录后可见!