扩散模型(Diffusion Model)最近在图像生成领域大火。而在扩散模型中,带有U-Net的卷积神经网络居于统治地位。U-ViT网络是将在图像领域热门的Vision Transformer结合U-Net,应用在了Diffision Model中。本文将从Vision Transformer出发,分析U-ViT这篇CVPR2023的Paper并记录一些感想。
Paper:All are Worth Words: A ViT Backbone for Diffusion Models
Code:https://github.com/baofff/U-ViT
一、Vision Transformer(ViT)
ViT是第一个将标准的transformer block应用在了视觉领域中的网络。在视觉领域中应用transformer最大的难点在于,如果将图片的每个像素点看作一个单词,那么整张图像的像素点太多,会导致序列太长,训练起来十分昂贵或者说根本无法训练。以224x224x3的图像为例,宽W,高H分别为224,可见光有RGB三个通道(channel)。那么一张图片的长度L即为15w+。显然这是不可接受的。
ViT对此的解决方法呢是借鉴了Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self attention and convolutional layers. In ICLR, 2020.这篇论文的思想。将一幅224×224的图像进行Patch化操作,也就是将一副图片分为若干个小块。如图1中左下角所示。
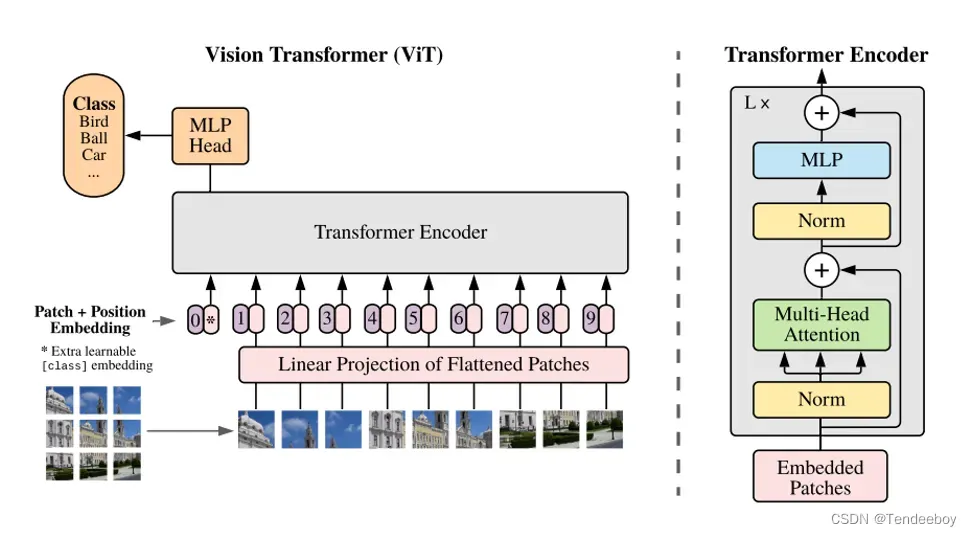
图1 ViT的结构
举个例子更方便理解。假设图像X的shape为[224, 224, 3],Patch Size为16,shape为[16, 16, 3],那么小Patch块的数量N= HW/PP =(224×224)/(16×16)= 196,也就是有196个小Patch块,输入的图片(单词)长度L为197(加1因为还要加上一个可学习的class embedding,用于分类)。每个Patch块的像素总量为16x16x3=768,768即为d_model。然后再经过一个线性投影层Linear Projection,获得图片的特征,最后获得的Patch Embedding的shape为[197, 768]。这样就可以输入transformer进行训练了。
ViT的数据流总的来说如图2所示。在此就不赘述了。如果有误,可以在评论区,欢迎指正!
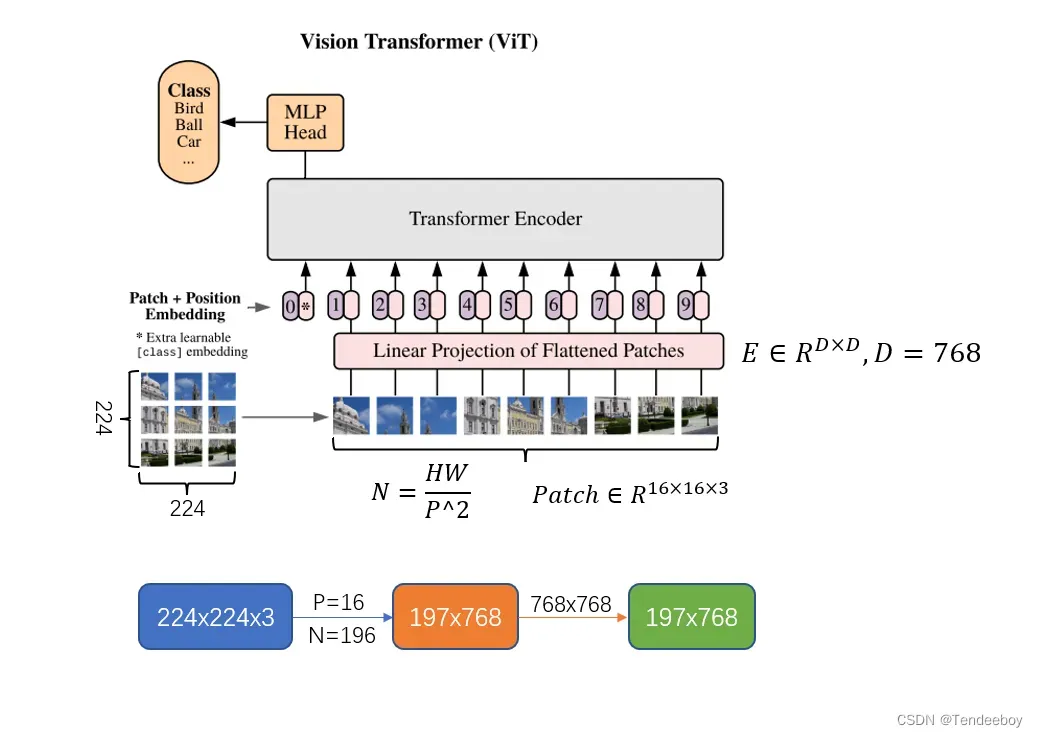
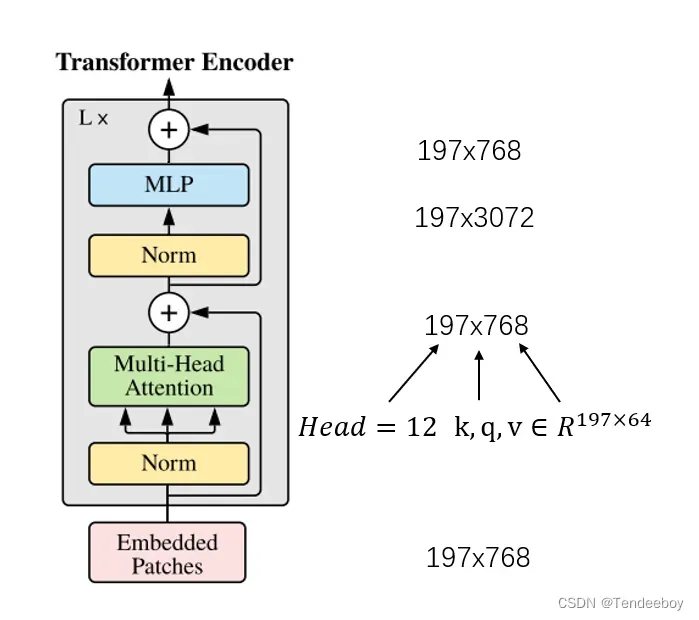
图2 ViT的数据流
其中,E是Linear Project的shape,可以根据d_model变换,主要用于提取图像的特征以及将图片映射(map)到Patch Embedding中。注意,位置为0的embedding就是class token,用于分类。多头自注意力最后进行的是concat操作而不是add,将12个k,q,v组合在一起恢复原来的shape。
二、U-ViT
U-ViT的创新点是在于将transformer替换掉了Difussion Model中原来的带有U-Net设计的CNN,并且在transformer中也应用了U-Net的long skip结构。实现了利用transformer进行图像生成的任务。U-ViT的结构图如图3所示。
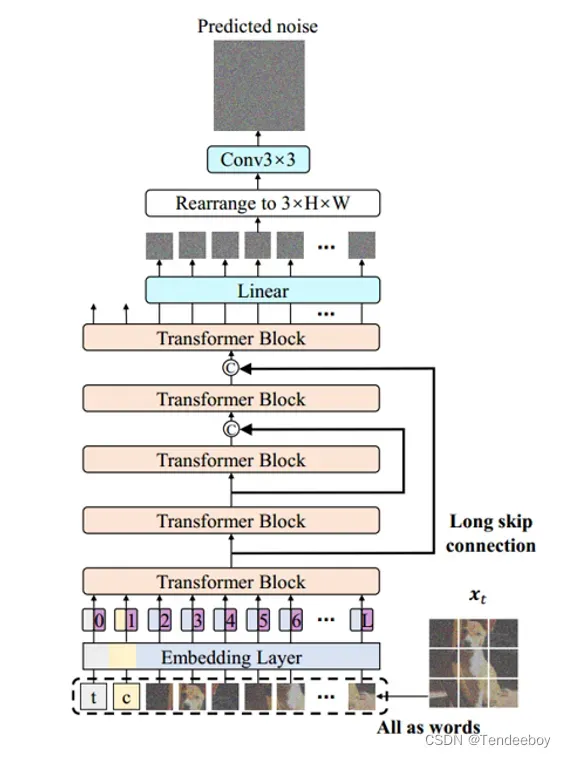
图3 U-ViT的结构
同样的,也是和ViT类似,对图片进行一个Patch化的操作。不同的是引入了time和condition作为新的token进行输入。并且在浅层的transformer和深层的transformer中引入long skip,为的是将低水平的特征在深层也可以得到应用,这是有利于Difussion Model的像素级预测任务。
作者对long skip的设置方式、time的加入方式、放置3x3Conv的位置、Patch Embedding和Positional Embedding进行了消融实验(也就是通过对比,看看怎样设置更好)。实验结果图我就不放上来了,直接说结论。
设hm,hs分别为主支和侧支的Embeddings,有五种情况。
- Linear[ Concat(hm,hs) ],先组合再线性层。
- Add(hm,hs),直接相加。
- Add[ hm,Linear(hs) ],hm加上linear后的hs。
- Linear[ Add(hm,hs) ],先相加再线性层。
- 无long skip,也就是只有hm。
其中,方法1效果最好,方法2最差。对于方法5,方法3和4均有提升。也就是说,long skip是必要的,但是对于hs需要获得它线性投影后的信息,因为在transformer中的加法器具有残差结构,已经可以获得低水平的线性信息了。
对于time token的加入方式尝试了两种。一种是直接作为token,另一种是自适应层归一化AdaLN。自适应层归一化是将time先经过一个Linear Proj得到ys和yb。再利用这两个参数和其他embedding做相关计算。第一种效果更好。
对于模型最后输出层的3×3卷积,也有两种位置。第一种是放在Linear Proj之后,第二种是之前。放在前面效果好。对于Patch Embedding,通过Linear Proj将Patch映射到Embedding的效果比用3×3 、1×1的Conv的方式要好。对于Positional Embedding,1d的位置编码比2d的效果更好,并且对比不用位置编码,使用位置编码生成的图像更合理。这也证明了Positional Information的重要性。
后续再阅读一下代码,看看数据流是如何实现的并利用MNIST数据集复现一个小型的U-ViT。
研0不能提前去学校,先用一下自己的1650学习先…
文章出处登录后可见!