训练细节
这篇内容主要是介绍关于instructGPT在训练的过程中代码细节。InstructGPT一共有三个训练阶段,分别是有监督的微调,reward模型的训练,以及PPO的训练。对于这三个阶段理论上有了之后,更加重要的是如何用代码来实现这些理论的细节。笔者认为,了解理论还不够,必须要真正的将理论用代码的方式实现出来,才是能真正的心安。
在以下的介绍中,会分别从数据的准备,模型的准备,和损失的计算三方面做各个阶段的代码介绍。注意,以下只是介绍核心的部分,从而了解核心后,读者可以自己应用到自己的框架中。
核心部分指的是对某一个小batch(1个或者多个样本),演示如何准备必要的模型输入,模型的训练以及推理,以及模型的输出的损失计算。所以代码中不会包含Dataset类,train以及eval的函数,等通用的训练框架的构建。
1. 有监督的微调
在之前的介绍中,有监督的微调其实就是继续在initial_model上next token prediction的任务。
1.1 数据的准备
假设当前只有一个样本,这个样本是关于阿凡达电影的介绍,期望设计一个prompt从而,使用模型来生成对这个电影的评价,详细的batch的准备如下
raw_input = "《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。"
# 当前使用这个prompt,将其粘贴在raw的后面,从而读起来更加通顺
# 当前也可以设计多个prompt,和后面的label做笛卡尔积扩充数据也是没有问题的
prompt = "看完这部电影后,"
# label是在豆瓣上收集到的关于阿凡达的电影评价,当前之选3个样本,用于后期batch的构建
label = [
"致喜欢但不怎么爱《阿凡达》的朋友:《阿凡达》让我大受震撼。这部续作在视觉效果、故事叙述和表演上都非常出色,让我在整个观影过程中都目瞪口呆",
"感觉拥有我所见过的最令人难以置信的视觉特效,美得令人窒息(我看的3D版),但是故事本身比第一个要弱",
"超出我的预期,大银幕属性极强,观赏性奇佳,亲情和对他人他物的关爱表达极易带入。"
]
# 通过for循环的方式将raw_input, prompt, 评价拼接起来
initial_data_ = [raw_input + prompt + i for i in label]对于initial_model来说准备使用预训练过的GPT2的中文模型,uer/gpt2-chinese-cluecorpussmall,选择这个模型的原因主要是因为小,下载快且计算的速度快,便于结果的输出和验证。
from transformers import AutoTokenizer
initial_tokenizer = AutoTokenizer.from_pretrained('uer/gpt2-chinese-cluecorpussmall')这里实例化的了一个gpt2用的tokenizer,使用这个tokenizer来对initial_data_做encode的动作。
# 先准备模型的输入
initial_token_info = initial_tokenizer.batch_encode_plus(
initial_data_,
max_length=256,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# 此时initial_token_info是一个字典,字典中包含'input_ids', 'token_type_ids', 'attention_mask',这些keys正好是模型所需要的parameters。
# 更加重要的是当前使用了return_tensors='pt', 自动的将所有的结果都转化成二纬的tensor数据,直接用于数据的计算模型的输入已经准备完毕,但是对于labels还没有准备完毕。由于当前做的是next token prediction的任务,那么labels其实就是输入。注意,labels不用做shift的处理,将labels放入模型中之后,模型会自动对输入和输出做shift的动作,从而正确的计算损失。这里需要对labels做的是将padding的部分变成-100,这样最终模型自己算crossentropy的时候自动ignore掉-100上的损失。
以下以图的方式展示数据的处理方式,粉色的部分是raw_input, 蓝色的部分是prompt,黑色的部分是希望模型能生成的有监督的labels。
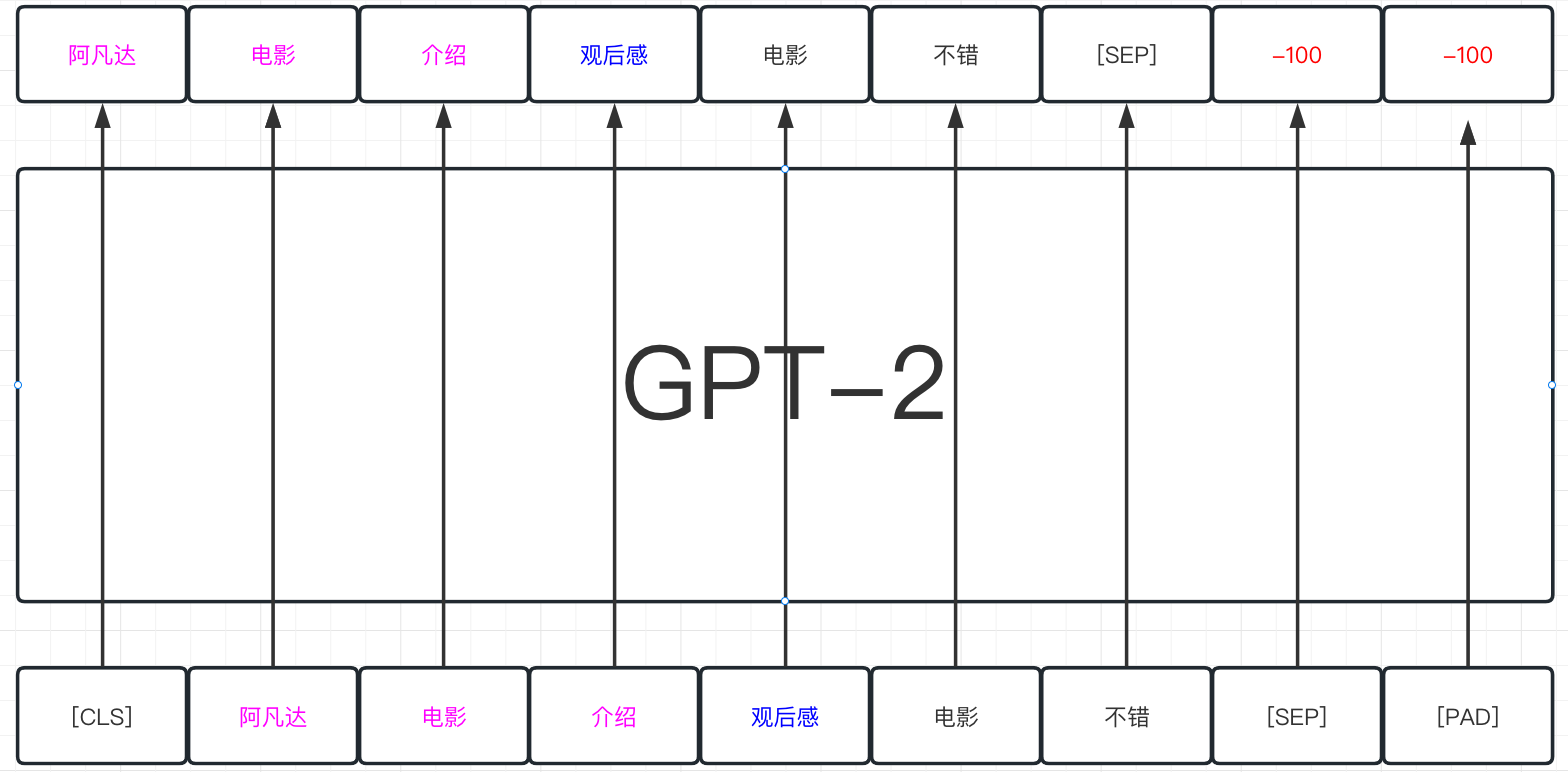
# 将labels也加到字典中,这是因为model的parameters中也有labels这个parameters
initial_token_info['labels'] = initial_token_info['input_ids']
initial_token_info['labels'] = torch.where(
initial_token_info['labels']==0,
-100,
initial_token_info['labels']
)这个时候关于initial阶段的输入部分也就准备完毕了,这里准备labels的方式是直接将padding的部分变成-100,从而来完成标准的next token prediction的任务的训练。当然其实也可以进一步严格一点,如果我们只关注模型在generated部分的损失,那么其实也可以将raw_input+prompt部分的整体的token也全部抹掉,具体做法如下。
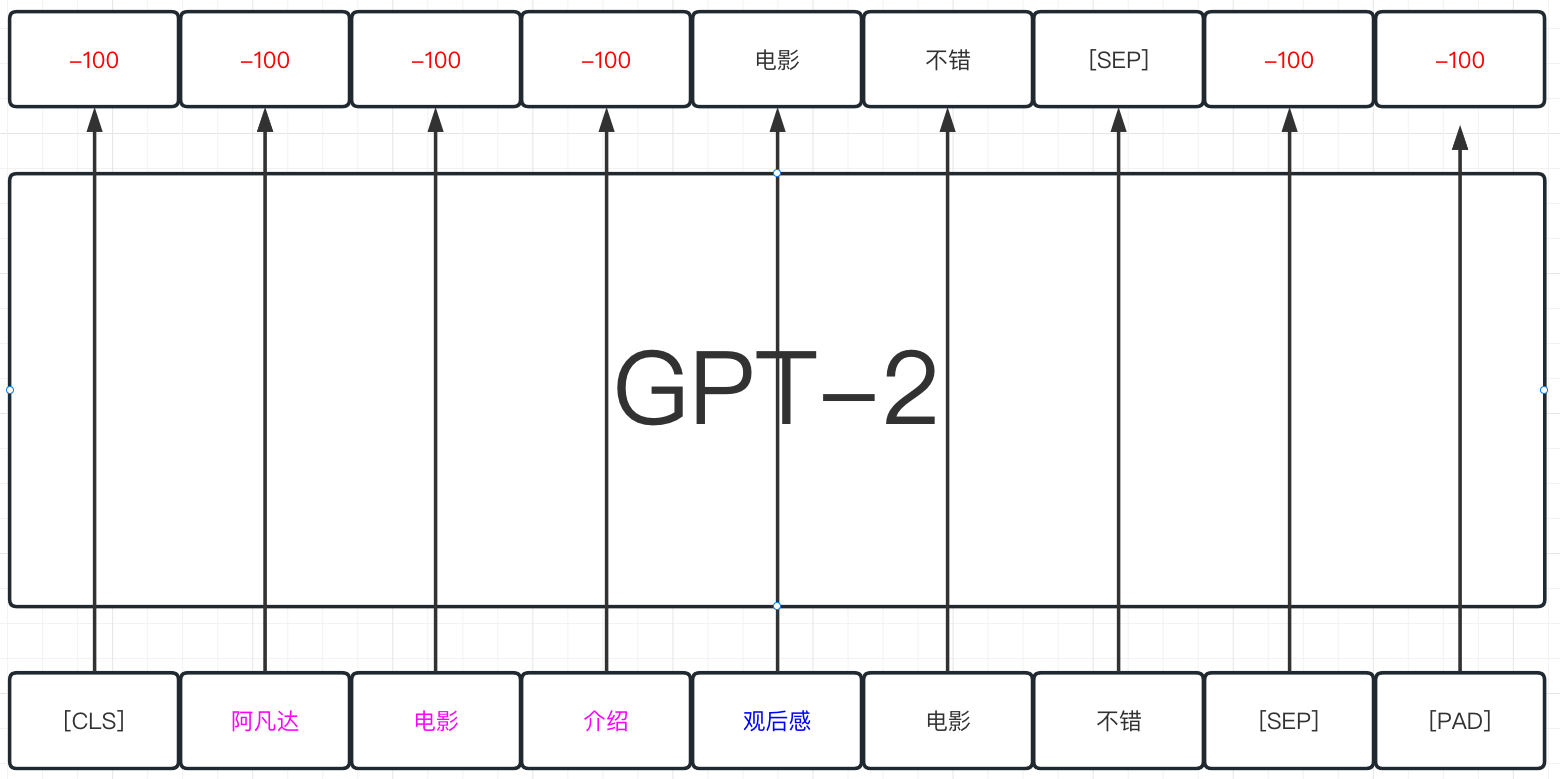
注意以下代码全部注释,只是给出另外一种方案,不带入实际的计算
# initial_token_info['labels'] = initial_token_info['input_ids']
# 这里可以尝试重新encode下raw_input + prompt,并且不加任何的参数,得到list,算其length
# raw_prompt_len = len(initial_tokenizer.encode(raw_input + prompt))
# 因为每个样本的前面的部分都是raw_input+prompt, 都是相同的,所有将所有的行,前面相同的部分全部变成0
# initial_token_info['labels'][:, :raw_prompt_len] = 0
# 最终整体的来尝试将0的部分变成-100
# initial_token_info['labels'] = torch.where(
# initial_token_info['labels']==0,
# -100,
# initial_token_info['labels']
# )1.2 模型的训练
这个地方模型的训练还是非常的容易的,由于在之前的inital_token_info中已经准备好的所有模型所需要的输入了,并且initial_token_info字典的key和model的parameters名字一模一样,那么直接用**的方式即可传参数
# 首先看下initial_token_info包含哪些
# initial_token_info = {
# 'input_ids' : batch_size * max_length,
# 'token_type_ids' : batch_size * max_length,
# 'attention_mask' : batch_size * max_length,
# 'labels' : batch_size * max_length # 模型的输入中也可以传入labels, 会自动的去做shift以及teacher forcing, 并且使用cross_entropy_loss自动的算loss
# }
from transformers import AutoModelForCausalLM
initial_model = AutoModelForCausalLM.from_pretrained('uer/gpt2-chinese-cluecorpussmall')
outputs = initial_model(**initial_token_info)1.3 损失的计算
由于模型中传了labels的值,模型自动算loss并且记录在ouputs中,取出即可
# 模型的ouputs自动带loss, loss拿出来做backward即可
outputs.loss.backward()2 Reward函数的训练
在这个阶段中,主要的目标针对initial_model的prompt的输出,以及输出的打分数据,做reward模型的训练。这里的reward的选择有很多种。原paper中提到的方式是将initial_model最上层的embedding去掉,使用输入的last_hidden_state中的CLS token做句向量来做后续的计算,这种方式可行,但是主要是这种GPT的unidirectional模型计算有点慢,也可以直接用Bert模型来做也没有问题。在下面的代码中,reward模型选择使用bert-base-chinese来做。
在做之前,首先回顾一下之前reward的过程。首先是initial_model对某个prompt数据做generate的动作,比如生成了5个结果,然后再针对这5个结果,做打分的动作。
2.1 基于某一个prompt做结果生成
首先准备数据,这个数据则是raw_input + prompt
input_test_for_generate = raw_input + prompt
# 注意,这里一定要加return_tensors='pt'的动作,因为tokenizer会自动的将结果做成二维的tensor用于模型的推理
token_info = initial_tokenizer.encode_plus(
input_test_for_generate,
return_tensors='pt'
)
# 当前的token_info中已经记录下来最重要的input_ids, 在model.generate中只需要input_ids即可
input_ids = token_info['input_ids']
# 使用model.generate自动帮做beamsearch的动作
generated_result = initial_model.generate(
input_ids=input_ids,
max_length=256,
do_sample=True, # 增加随机性,而非greedysearch
num_beams=5,
num_return_sequences=5, # 每个样本生成5个结果
no_repeat_ngram_size=3, # 防止重复的token
early_stopping=True # 提前停止
)
# 使用batch_decode的方式对5个结果整体做decode的动作
generated_tokens = initial_tokenizer.batch_decode(
generated_result,
skip_special_tokens=True # decode之后自动去掉[CLS][SEP]那些token
)
# 生成之后token和token之间有空格,对5个结果的每个结果都去抹掉空格
generated_tokens = [i.replace(' ', '') for i in generated_tokens]关于Transformer的生成模型的generate的方法,感兴趣的同学可以去查看https://huggingface.co/blog/how-to-generate
以下生成的结果
《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。看完这部电影后,我感觉到了一种奇妙的力量。这是一部非常好看的电影,也是我看过的最棒的一部动画电影。我觉得这不仅仅是电影本身的魅力,更是一种对于人性的深刻理解和对于生活的思考。一部优秀的动画片,能够让我们感受到人与人之间的关系,这种关系是多么的纯粹。我想,这是我最喜欢的动漫电影之一。
《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。看完这部电影后,我突然意识到,这是一部值得一看的电影,因为它给我们带来了新的思考,让我们看到一个真实的苏里。···影片讲述的是一个名叫苏里的女孩,在一次意外事故中,她遭遇了一场灾难,她的母亲不幸身亡,而她的父亲也因此受到了重大的伤害。
《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。看完这部电影后,我觉得这是一部值得一看的电影,因为它让我们看到了一个真实的苏里,一个关于爱情的真实故事。话说回来,电影中的人物很多,但是都有一个共同的特点,那就是他们都是一个人,他们有自己的生活,也有他们的家庭。
《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。看完这部电影后,我的脑海里浮现出一个画面:一个年轻的女孩子站在一个不起眼的地方,面对一个陌生的男人,她的内心是崩溃的,她不知道自己要做什么,但是她却一直在寻找答案。这个女孩是一个孤独的人,因为她没有人能够帮助她,所以她只能靠自己的力量来维持这个世界的秩序。在这个过程中,她遇到了一些困难,她想要找到解决问题的办法,这个男人帮助了她,让她找到了自己想要的东西。
《阿凡达》的背景设定在前一集的十年多以后,讲述苏里一家的故事、他们面临的麻烦、他们为了保护彼此而做的努力、他们为了存活而打的仗,以及他们所承受的悲剧。看完这部电影后,我觉得这个故事还是很有意思的,尤其是第一集,我们看到的是一个小男孩,他的爸爸是一名医生,妈妈是一位老师,还有一个孩子,他们的父亲是一对夫妻。他们在一起生活了一段时间,后来他们结婚了,结婚之后,孩子也跟着他们长大。在他们生活的这个过程中,父母的关系发生了很大的变化,这也是为什么他们之间的感情非常好的原因。因为他们是彼此的父母,而不是父母。为了方便后期的训练,笔者通过手动的方式为这5个生成的结果做打分。这个时候,注意打分的方式有多种,这里暂时了解到的是两种打分方式,一种是assessment scores, 另外一种是preference scores。这两个名字是笔者自己取的。
2.2 打分方式
2.2.1 asessment scores
这种打分的代表数据是HFsummary,这个数据可以通过datasets的包去自动的load,有兴趣的读者可以自己去尝试。这种打分方式是针对单个样本做多维度的打分,比如对生成的每句话来说,这句话是否 [流畅,真实,和raw有关联]。以下是笔者对5句话的assessment打分,注意这里的打分不是特别的准确,只是举例子描述核心的训练过程而已。
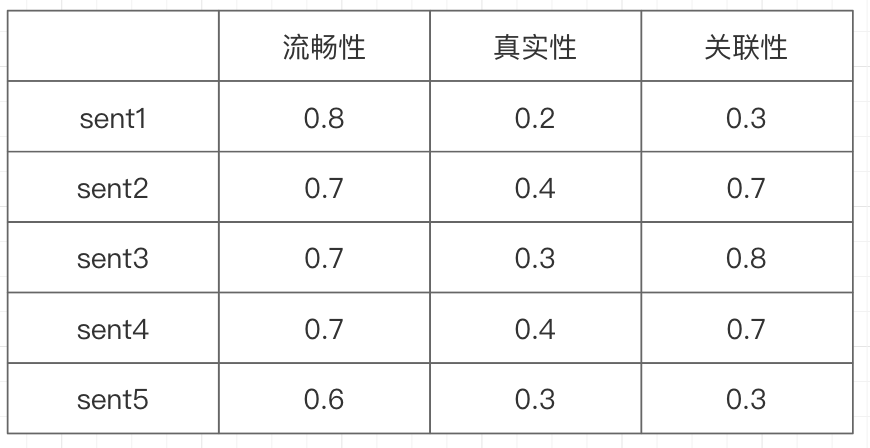
这种数据适合的训练方式,可以是在Bert模型上方加个Linear层,从而用MAE或者MSE的方式来做损失的计算。
2.2.2 preference scores
这种打分的代表数据是WebGPT,这个数据也可以通过datasets的包去自动的load,有兴趣的读者可以自己去尝试。这种打分方式是单维度,是对生成的成对的样本来打分,判断在两个生成的样本中,到底哪个样本更加好一些。以下是笔者对5句话的preference打分,注意这里的打分是很原始的打分,后期会做成pairwise的形式从而来完成paper中所描述的损失的计算。
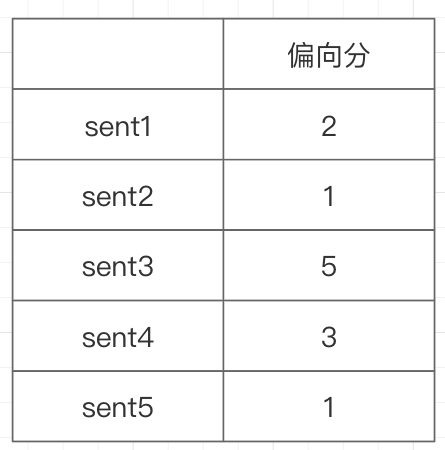
这种label可以使用两种方式的训练方式,这两种方式核心的思想差不多,但是损失函数的实现方式不一样
paper中pairwise的训练方式
苏神所创建的cosent的训练方式
每一种训练的方式,都要对数据做不一样的准备,后面做详细的展示
2.3 Assessment打分下模型训练
2.3.1 数据集的准备
这种状态下的数据准备很简单的,因为不需要使用pairwise的方式,则简单的对数据做tokenizering的动作,后期放入模型即可
首先回顾下标签数据
scores_assessment = [
[0.8, 0.2, 0.3],
[0.7, 0.4, 0.7],
[0.7, 0.3, 0.8],
[0.75,0.4, 0.75],
[0.6, 0.3, 0.3]
]reward_tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
# generate_tokens上面生成的token,这里统一改名字为reward_data
# 一定要注意的是,当前的reward_data里的5个样本,每个样本都是包含之前的raw_input和prompt的
# 这是因为希望模型不仅仅只关于generate的质量,也希望模型可以考虑generate的结果是否和raw_input相关
reward_data = generated_tokens
reward_token_info = reward_tokenizer.batch_encode_plus(
reward_data,
max_length=256,
padding='max_length',
truncation=True,
return_tensors='pt'
)2.3.2 模型的训练
模型可以是SequenceForClassification的模型,也就是在Bert的pooler的output上增加nn.Linear(hidden_size, 3)层。这种训练方式可以尝试使用图的方式做展示
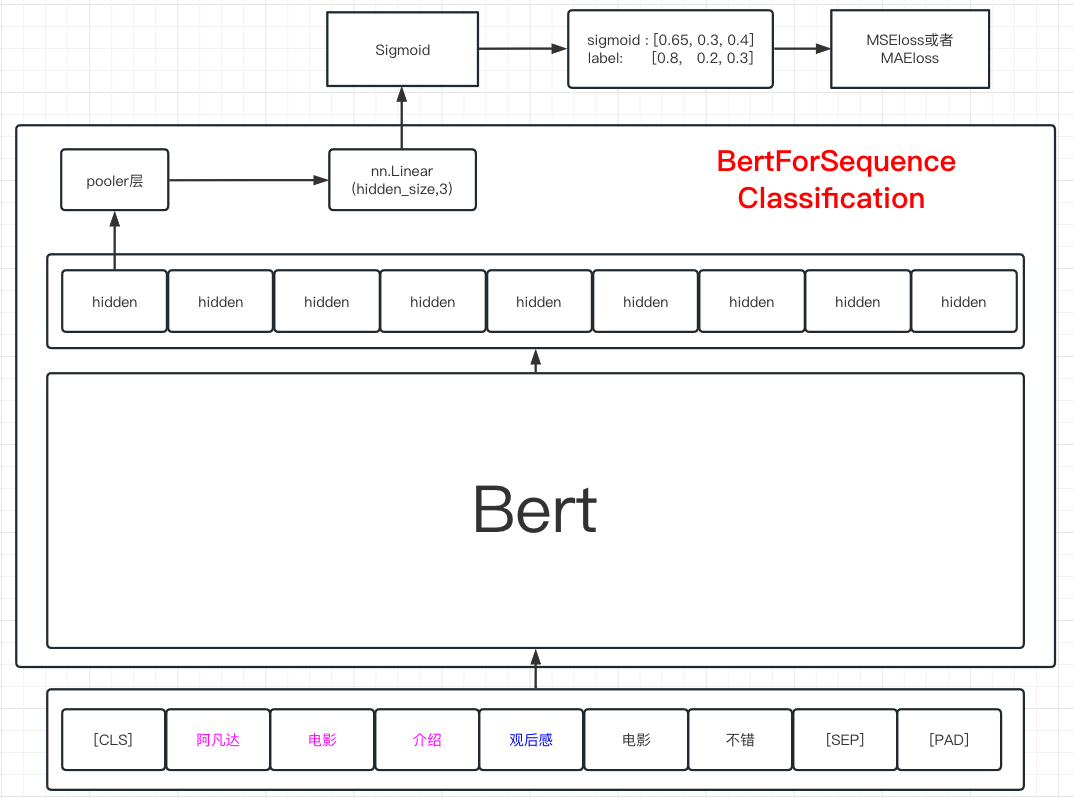
从图中可以看到,BertForSequenceClassification模型是在Bert的上方加了一个Linear层的模型。当句子入模之后,在每个token上都会得到hidden向量,而[CLS]所对应的向量一般被认为是保存了句子中所有信息的向量。将这个向量拿出来,经过Bert的pooler层之后,再通过Linear层映射到3个维度上。此时的结果还需要经过Sigmoid,将值映射到0,1空间中,最终和标签参与损失的计算。以下是基于上图的代码实现。
# 使用SequenceClassification模型,这个模型是在base的模型的pool的结果上,多家了个linear层
from transformers import AutoModelForSequenceClassification
# nn.Linear(hidden_size, 3)的这个最后映射到多少个维度的值在num_labels上设置
reward_model = AutoModelForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=3
)
reward_outputs = reward_model(**reward_token_info)2.3.3 损失的计算
import torch
to_sigmoid = torch.nn.Sigmoid()
# reward_outputs中的logits需要先做一个sigmoid映射到0,1的空间中,才能计算损失
reward_logits = to_sigmoid(reward_outputs.logits)
# 将labels从list转化成tensor
labels = torch.tensor(scores_assessment, dtype = torch.float)
# 使用MSELoss
loss_fn = torch.nn.MSELoss() # 有的框架中使用L1Loss也就是mae的方式做的loss计算
# 或者使用MAEloss,以下注释
# loss_fn = torch.nn.L1Loss()
reward_loss = loss_fn(reward_logits, labels)
reward_loss.backward()2.4 Preference打分下模型训练(paper的方式)
2.4.1 数据集的准备
首先需要尝试将数据做成pairwise的形式,从而的成对的来进行进行计算。回顾下标签的数据
scores_preference = [2, 1, 5, 3, 1]
#reward_data = [sent1, sent2, sent3, sent4, sent5]对于这种标签其实一种最简单的方法还是像上面的介绍的,使用BertForSequenceClassification的方式来做,但是由于当前每个样本只有一个分数,num_labels需要设置成1,最终通过mse的损失来做模型的更新。
其实有更加不错的方法,也就是使用pairwise的方法,这种方法的思想来自simCSE。在将每个句子压缩一个维度(一个logits值)后,这个logits的值可以简单的理解成当前raw_input + prompt + generated整个句子的质量,这个值越大整个句子总体的质量越好。那么模型训练的过程中,可以尝试在5个句子中做两两句子的对比,在每个句子对中,期望质量高的句子的logits和质量低的句子的logits中间的差值被拉的越大越好。以下从图的角度来描述这一过程。
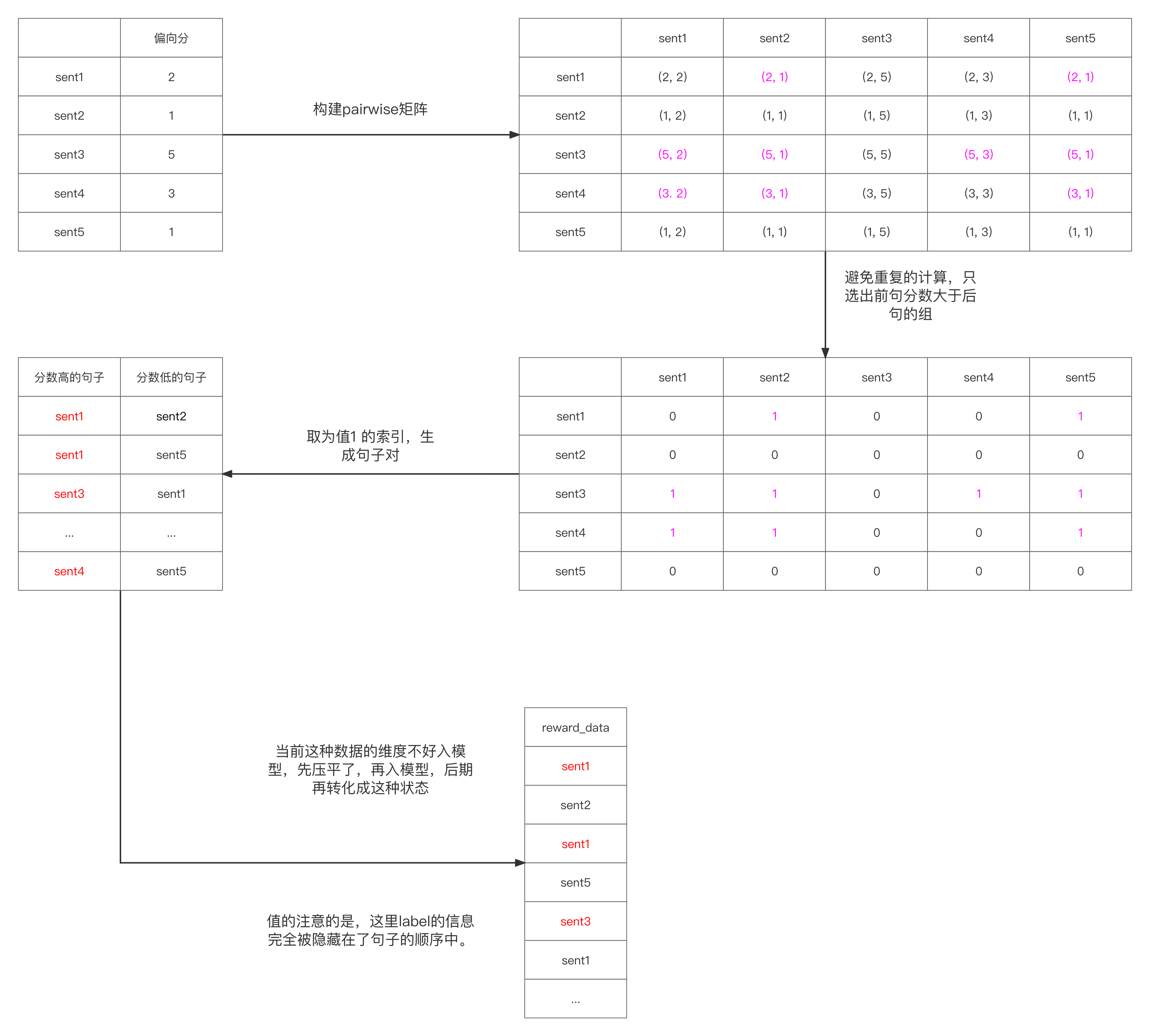
以下是详细的代码
# 将原数据做成以上的形态
batch_size = len(scores_preference)
ordered_reward_data = []
for i in range(batch_size):
for j in range(batch_size):
if scores_preference[i] > scores_preference[j]:
ordered_reward_data += [generated_tokens[i], generated_tokens[j]]
# 假设当前的ordered_reward_data的个数有18个,那也就暗示着有9对数据
# 注意这个时候是没有label的,label的信息是隐藏在了ordered_reward_data的顺序中,也就是双数索引(从0开始)上的句子成对的要比单数索引上的分数高。
# 做分词的处理
reward_token_info = reward_tokenizer.batch_encode_plus(
ordered_reward_data,
max_length=256,
padding='max_length',
truncation=True,
return_tensors='pt'
)2.4.2 模型的训练
# 实例化模型, 注意这里num_labels为1,也就是我们只有一个维度的评价评分,将每个句子映射到一个维度上去
reward_model = AutoModelForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=1
)
# 生成logits
reward_outputs = reward_model(**reward_token_info)
# outputs中的logits的维度18 * 1。因为18个句子每个句子被最后的Linear映射到了1个维度上。2.4.3 损失的计算
拿到outputs之后,由于准备数据的时候是,成对的数据是按顺序穿插起来的,为了方便计算损失,可以的展开。以下是损失计算的方式
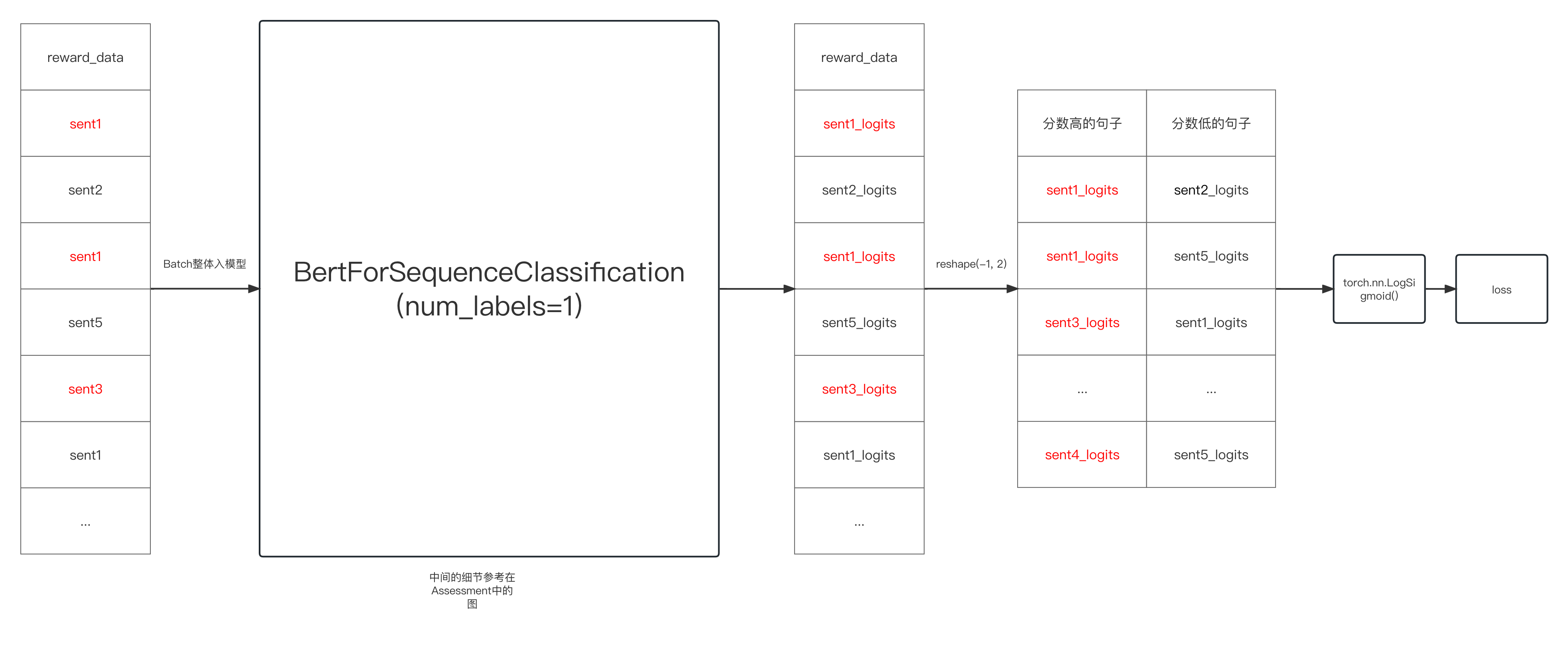
# 整理成句子对
reward_logits = reward_outputs.logits.reshape(-1, 2)
# 这个时候reward_logits的维度为18 * 1, reshape后为9 * 2
# 通过reshape的动作之后,将双单的向量矩阵分开,放在了第一列和第二列,成对的来看,第一列的句子的分数要比第二列的高
# 设计论文中所提到的RankLoss
class RankLoss(torch.nn.Module):
def __init__(self, eps=1e-8) -> None:
super().__init__()
self.eps = eps
self.log_sigmoid = torch.nn.LogSigmoid()
def forward(self, pos, neg):
# 注意这里传进来的pos,neg的向量的维度都是batch, 1
# pos,neg是成对的向量,在每一个pair中,前面的句子比后面的句子分数要高
# 下面的log_sigmoid的目标就是尝试拉长这个每一对中前者何后者之前的差距
# 从而让模型学习到前者的结果要优于后者
# 这个时候为什么没有labels呢?这是因为labels的信息已经被隐藏在pos,neg之前穿插的数据顺序中
return -self.log_sigmoid(pos - neg + self.eps).mean()
loss_fn = RankLoss()
reward_loss = loss_fn(reward_logits[:, 0], reward_logits[:, 1])
reward_loss.backward()2.5 Preference打分下模型训练(consent的方式)
在2.4中,是将raw_input + prompt + generated 三部分全部添加在一起做成了一个整体的句子,再通过句子对的方式来比较。是否可以有更加灵活一点的方法呢,比如将raw,prompt和generated也做成句子对,从而通过拉大“句子对”的对之间的差距从而更新模型呢?
笔者的这种不同于paper里的思路,是从苏神的cosent训练词向量的方法来的,关于cosent的损失的细节可参考https://spaces.ac.cn/archives/8847。笔者认为,生成generated质量越高,则其和raw + prompt的相似度就应该越高(或者使用新的Linear层u, v处理下也可以),从而将其做成句子对来对"句子对"对训练更加合理。另外一点好处的是在苏神的文章中提到,cosent的优势就是更加适合有排序性的标签,也就是当前的这种Preference的分数。以下给出一个大致的处理图
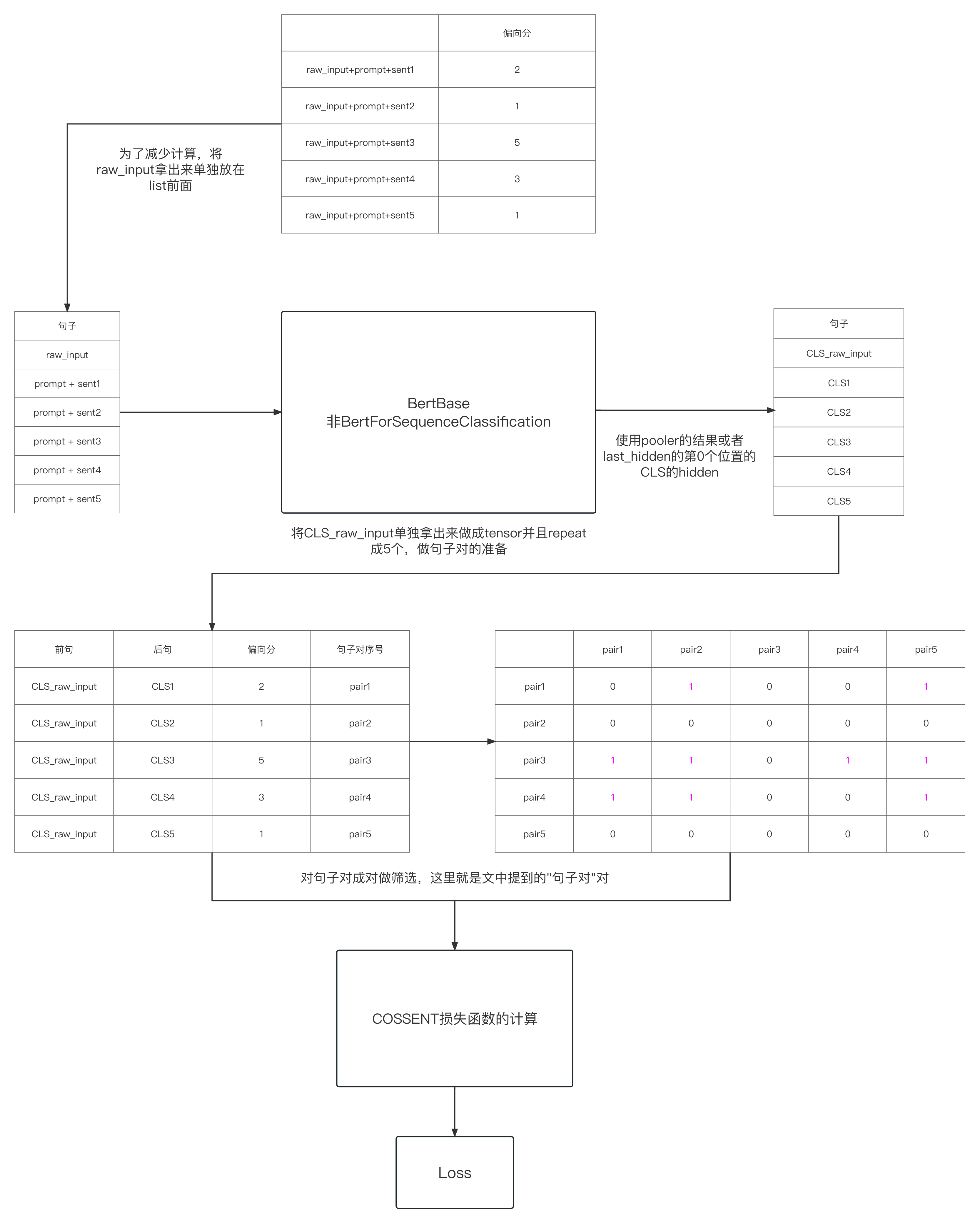
2.5.1 数据的准备
期望做成以下的结果
raw, prompt + sent1
raw, prompt + sent2
raw, prompt + sent3
raw, prompt + sent4
raw, prompt + sent5这里可以减少计算,先做成
raw
prompt + sent1
prompt + sent2
prompt + sent3
prompt + sent4
prompt + sent5得到各个句子的CLS向量后,再将raw_prompt给提取出来,复制5份做成以上期望的样本
# 将原generated_tokens里面的raw去掉
generated_tokens_only_generated = [i[len(raw_input):] for i in generated_tokens]
# 然后list的元素的第一个位置增加raw
generated_tokens_only_generated = [raw_input] + generated_tokens_only_generated
# 做分词的动作
reward_token_info = reward_tokenizer.batch_encode_plus(
generated_tokens_only_generated,
max_length=256,
padding='max_length',
truncation=True,
return_tensors='pt'
)2.5.2 模型的训练
# 其实可以直接复用上面的reward_model, 这里为了完整性,重新实例化一遍
reward_model = AutoModelForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=1
)
# 我们不需要reward_model的linear的输出了,想要其base模型
raw_model_base = reward_model.base_model
# 在ouputs中,我们关注的是last_hidden_state的CLS的部分
outputs = raw_model_base(**reward_token_info)2.5.3 损失的计算
# 首先拿出last_hidden出来,维度为6 * seq_length * 768, 取CLS的部分
cls_hiddens = outputs.last_hidden_state[:, 0, :]
# 6个是因为第一个是raw_input的CLS,而后面的5个是prompt+5个generate的CLS
raw_input_hidden_states = cls_hiddens[0]
# 取出raw_input的CLS,维度为768, 将复制5份,做成5 * 768的维度
raw_input_hidden_states = raw_input_hidden_states.repeat(5, 1)
# 起初generated的部分,维度也为5 * 768, 因为有5个句子
generated_token_hidden_states = cls_hiddens[1:]
# 在cosent计算的时候labels的信息需要有,是用来看到底哪个句子对分数高,哪个句子对分数低用的
labels = torch.tensor(scores_preference)
# 这样维度一样,可以做后面句子对的cosent的损失计算
# 设计关于cosent的损失函数
def cosent_task_function(cls1, cls2, labels):
cossim_for_each_pair = (cls1 * cls2).sum(axis=1)
cossim_ij_diff_matrix = cossim_for_each_pair[:, None] - cossim_for_each_pair[None, :]
labels_ij_diff_matrix = labels[:, None] - labels[None, :]
labels_ij_diff_matrix = (labels_ij_diff_matrix < 0).to(cossim_for_each_pair.device, dtype=torch.float)
cossim_ij_diff_matrix = cossim_ij_diff_matrix - (1 - labels_ij_diff_matrix) * 1e12
cossim_ij_diff_matrix = cossim_ij_diff_matrix.reshape(-1)
cossim_ij_diff_matrix = torch.cat(
[
torch.tensor([0]).to(cossim_ij_diff_matrix.device, dtype=torch.float),
cossim_ij_diff_matrix
], dim=0
)
loss = torch.logsumexp(cossim_ij_diff_matrix, dim=0)
loss = loss / cls2.shape[0]
return loss
loss = cosent_task_function(
raw_input_hidden_states,
generated_token_hidden_states,
labels
)
loss.backward()2.6 Assessment打分下的Cosent
Cosent的方法如何用刀Assessment的打分呢?其实很简单,Preference打分可以看成是用户在一个维度上的打分,Assessment有n个维度,那么可以尝试设计n个维度上的Cosent损失函数,TotalLoss = a1 * CosentLoss1(真实度) + a2 * CosentLoss2(准确度) + a3 * CosentLoss3(相关度) + a4 * (无敏感词度)从而完成Loss的计算,注意a1 + a2 + a3 + a4 = 1, 如果想让模型更加的关注无敏感词这个维度,可以手动的增加a4的值,从而让模型更加关注这个维度上的信息。
文章出处登录后可见!