U-Net网络模型(注意力改进版本)
这一段时间做项目用到了U-Net网络模型,但是原始的U-Net网络还有很大的改良空间,在卷积下采样的过程中加入了通道注意力和空间注意力 。
常规的U-net模型如下图:
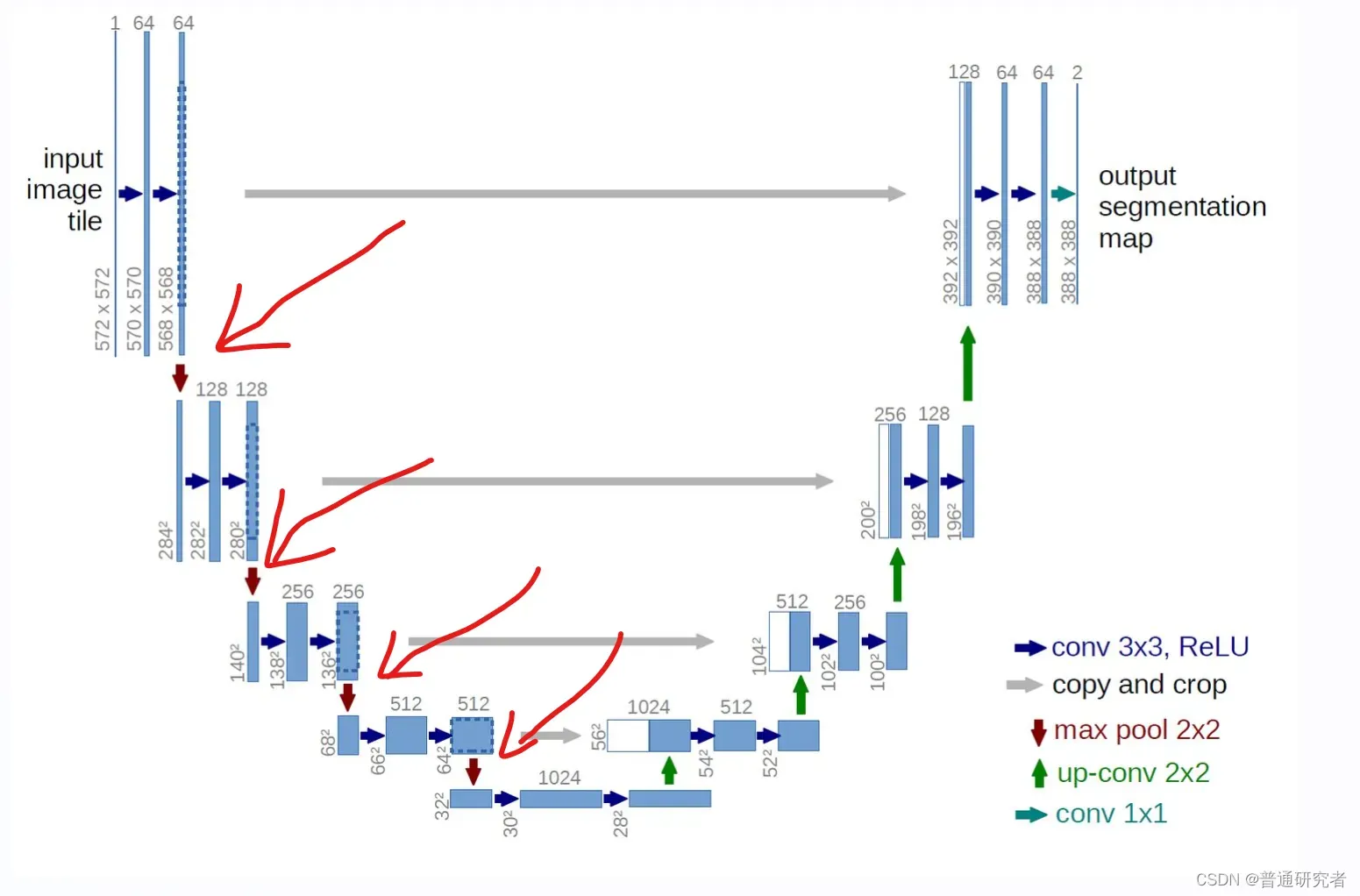
红色箭头为可以添加的地方:即下采样之间。
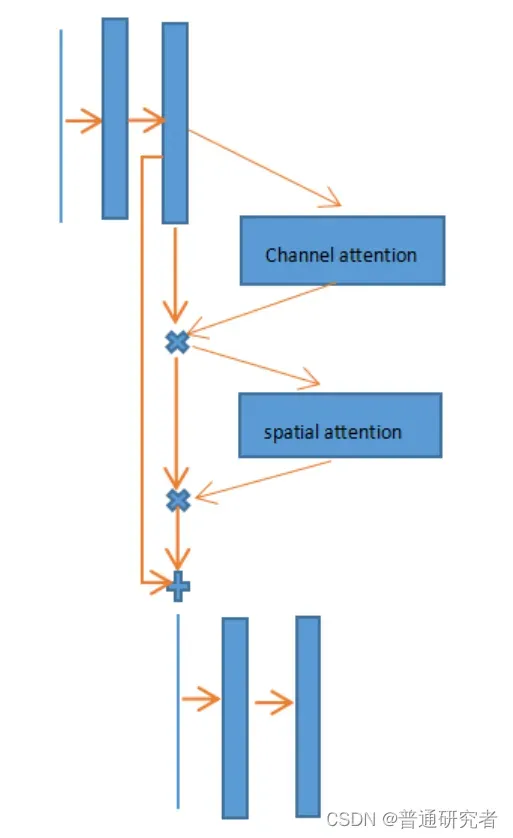
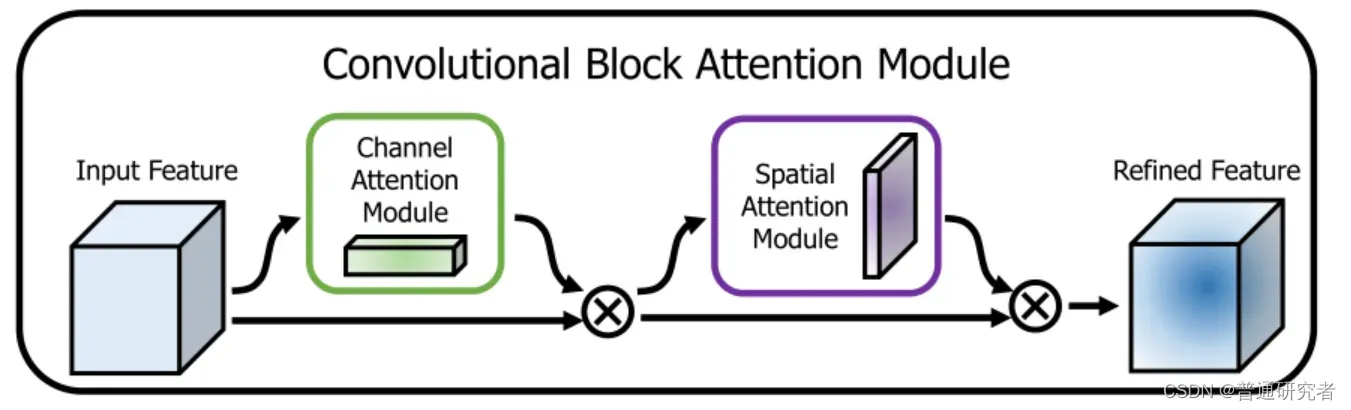
通道空间注意力是一个即插即用的注意力模块(如下图):
代码加入之后对于分割效果是有提升的:(代码如下)
CBAM代码:
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, ratio=16):
super(ChannelAttentionModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // ratio, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x))
maxout = self.shared_MLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
网络模型结合之后代码:
class conv_block(nn.Module):
def __init__(self,ch_in,ch_out):
super(conv_block,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True),
nn.Conv2d(ch_out, ch_out, kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.conv(x)
return x
class up_conv(nn.Module):
def __init__(self,ch_in,ch_out):
super(up_conv,self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.up(x)
return x
class U_Net_v1(nn.Module): #添加了空间注意力和通道注意力
def __init__(self,img_ch=3,output_ch=2):
super(U_Net_v1,self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)
self.Conv1 = conv_block(ch_in=img_ch,ch_out=64) #64
self.Conv2 = conv_block(ch_in=64,ch_out=128) #64 128
self.Conv3 = conv_block(ch_in=128,ch_out=256) #128 256
self.Conv4 = conv_block(ch_in=256,ch_out=512) #256 512
self.Conv5 = conv_block(ch_in=512,ch_out=1024) #512 1024
self.cbam1 = CBAM(channel=64)
self.cbam2 = CBAM(channel=128)
self.cbam3 = CBAM(channel=256)
self.cbam4 = CBAM(channel=512)
self.Up5 = up_conv(ch_in=1024,ch_out=512) #1024 512
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512,ch_out=256) #512 256
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256,ch_out=128) #256 128
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128,ch_out=64) #128 64
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0) #64
def forward(self,x):
# encoding path
x1 = self.Conv1(x)
x1 = self.cbam1(x1) + x1
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x2 = self.cbam2(x2) + x2
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x3 = self.cbam3(x3) + x3
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x4 = self.cbam4(x4) + x4
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
版权声明:本文为博主作者:普通研究者原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_42367888/article/details/134807074