在用机器学习解决问题时,往往要先对数据进行预处理。其中,z-score归一化和Min-Max归一化是最常用的两种预处理方式,可以通过sklearn.preprocessing模块导入StandardScaler()和 MinMaxScaler()接口实现,而在调用这两个接口时,有三种方法:fit(), fit_transform() , transform()。
但是,查阅了许多博客以及官方文档,都没有把这几个函数的区别讲清楚。
因此,今天花了半天时间,把这个问题探索清楚。
时间紧张的朋友可以直接跳到第四节去看结论,第一节到第三节是作者结合某个数据集进行验证的过程。
还是先提一下这两个归一化方法。
z-score归一化: x = (x – x的均值)/ x的方差
Min-Max归一化: x = (x – x的最小值) / (x的最大值 – x的最小值)
官方文档:
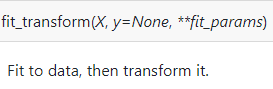
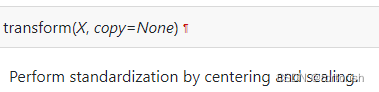
只有两行文字解释,说了等于没说,。。。= =
So, 下面通过实验来验证。为了让文章更简洁,这里只挑选了项目中的部分代码。
一、处理数据
1、通过 fit_transform() 对训练集进行归一化,这里采用Min-Max归一化
minmaxscaler = MinMaxScaler()
data_train_norm = minmaxscaler.fit_transform(data_train)
data_train_norm = pd.DataFrame(data_train_norm, columns=new_column_name)
data_train_norm.head(3)
2、分别通过调用 fit_transform() 和 transform()处理测试集
data_test_norm_transform = minmaxscaler.transform(data_test)
data_test_norm_transform = pd.DataFrame(data_test_norm_transform, columns=new_column_name)
data_test_norm_fit_transform = minmaxscaler.fit_transform(data_test)
data_test_norm_fit_transform = pd.DataFrame(data_test_norm_fit_transform, columns=new_column_name)2.1 fit_transform()的结果:

2.2 transform()的结果:

大家肯定已经发现了,这两个方法产生的结果是不一样的,让我们用密度图画出这三个结果的分布。这边只展示前六列数据的分布图。
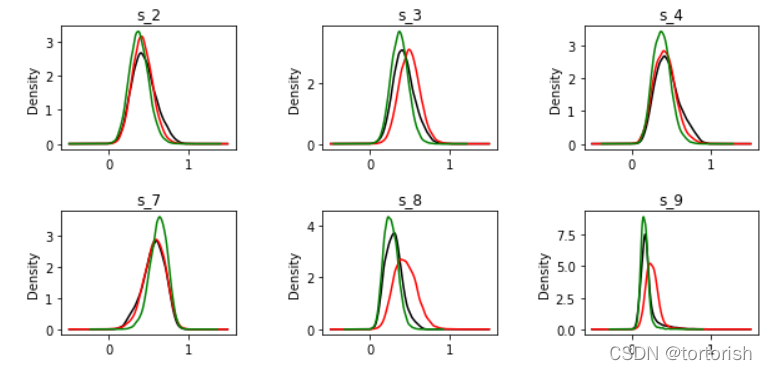 黑线:训练集上fit_transform()后的结果
黑线:训练集上fit_transform()后的结果
红线:测试集上fit_transform()后的结果
绿线:测试集上transform()后的结果
可以发现,绿线波峰的位置和黑线是相同的,而红线波峰的位置却不一定和黑线相同。
二、猜测
猜想一:transform() : 在对测试集上的数据进行归一化时,使用的是训练集的最小值和最大值
猜想二:fit_transform():用自己的最小值和最大值进行归一化
三、验证猜想
3.1 验证猜想二
不用sklearn的方法,手动编程。在归一化测试集时,使用测试集自己的最小值和最大值
((data_test - data_test.min()) / (data_test.max()-data_test.min())).head(3)
对比2.1节的结果,可以看到两者是相同的。
所以猜想二正确。
3.2 验证猜想一
在归一化测试集时,使用训练集的最小值和最大值
((data_test - data_train.min()) / (data_train.max()-data_train.min())).head(3)
对比2.2节的结果,发现手动编程的结果与用sklearn中transform()的结果是相同的。
所以猜想一正确。
四、总结
在用机器学习解决问题时,会将数据集划分成训练集和测试集。我们可以先用fit_transform()方法处理训练集,再用transform()方法处理测试集。这时,在归一化测试集时,使用的是训练集的统计量,这么做是为了让训练集和测试集更相似。使算法在两者上的表现尽可能相同
而若对测试集使用了fit_transform()方法,则会用测试集自己的统计量来归一化数据。
在测试集上千万不要混用这两个方法,笔者就因为在测试集上使用了fit_transform()方法,导致测试集上的损失一直比验证集上的大很多!
还有一个fit()方法没说,这个是最简单的,它和fit_transform()是相同的,只不过后者会返回转换后的结果,而前者是不会返回的,只会训练转换器。
文章出处登录后可见!