1、Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder

超分辨率(SR)和图像生成是计算机视觉中重要的任务,在现实应用中得到广泛采用。然而,大多数现有方法仅在固定放大倍数下生成图像,并且容易出现过平滑和伪影。此外,在输出图像的多样性和不同尺度下的一致性方面也不足。大部分相关工作应用了隐式神经表示(INR)到去噪扩散模型中,以获得连续分辨率的多样化且高质量的SR结果。由于该模型在图像空间中操作,所以产生分辨率越大的图像,需要的内存和推理时间也越多,并且它也不能保持尺度特定的一致性。
本文提出一种新流程,可在任意尺度上对输入图像进行超分辨率处理或从随机噪声生成新图像。方法由一个预训练的自编码器、一个潜在扩散模型和一个隐式神经解码器以及它们的学习策略组成。方法采用潜在空间中的扩散过程,因此高效且与由MLP在任意尺度上解码的输出图像空间保持对齐。更具体说,任意尺度解码器是由预训练自编码器的无上采样对称解码器和局部隐式图像函数(LIIF)串联而成的。通过去噪和对齐损失联合学习潜在扩散过程。输出图像中的误差通过固定解码器进行反向传播,提高输出质量。
通过在包括图像超分辨率和任意尺度上的新图像生成这两个任务上使用多个公共基准测试进行广泛实验,方法在图像质量、多样性和尺度一致性等指标上优于相关方法。在推理速度和内存使用方面,它比相关先前技术明显更好。
2、Diffusion-based Blind Text Image Super-Resolution

恢复退化的低分辨率文本图像是一项具有挑战性的任务,特别是在现实复杂情况下处理带有复杂笔画和严重退化的中文文本图像。保证文本的保真度和真实性风格对于高质量的文本图像超分辨率非常重要。最近,扩散模型在自然图像合成和恢复方面取得成功,因为它们具有强大的数据分布建模能力和数据生成能力。
这项工作提出一种基于图像扩散模型(IDM)的文本图像恢复方法,可以恢复带有真实风格的文本图像。对于扩散模型来说,它们不仅适用于建模真实的图像分布,而且也适用于学习文本的分布。由于文本先验对于根据现有艺术品保证恢复的文本结构的正确性非常重要,还提出了一种文本扩散模型(TDM)用于文本识别,可以指导IDM生成具有正确结构的文本图像。进一步提出一种多模态混合模块(MoM),使这两个扩散模型在所有扩散步骤中相互合作。
对合成和现实世界数据集的广泛实验证明,基于扩散的盲文本图像超分辨率(DiffTSR)可以同时恢复具有更准确的文本结构和更真实的外观的文本图像。
3、Text-guided Explorable Image Super-resolution

本文介绍零样本文本引导的开放域图像超分辨率解决方案的问题。目标是允许用户在不明确训练这些特定退化的情况下,探索各种保持与低分辨率输入一致的、语义准确的重建结果。
提出两种零样本文本引导超分辨率的方法,一种是修改文本到图像(T2I)扩散模型的生成过程,以促进与低分辨率输入的一致性,另一种是将语言引导融入零样本扩散式恢复方法中。展示了这些方法产生的多样化解决方案与文本提示所提供的语义意义相匹配,并且保持与退化输入的数据一致性。评估提出的基线方法在极端超分辨率任务上的任务表现,并展示了在恢复质量、多样性和解决方案的可探索性方面的优势。
4、Boosting Image Restoration via Priors from Pre-trained Models
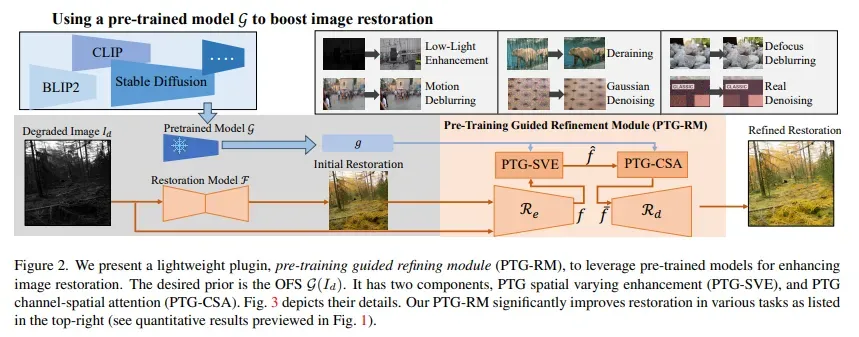
以CLIP和稳定扩散为代表的使用大规模训练数据的预训练模型,在图像理解和从语言描述生成方面展现显著性能。然而,它们在图像恢复等低级任务中的潜力相对未被充分探索。本文探索这些模型来增强图像恢复。
由于预训练模型的现成特征(off-the-shelf features,OSF)并不能直接用于图像恢复,提出一个学习额外的轻量级模块——预训练引导细化模块(Pre-Train-Guided Refinement Module,PTG-RM),用于通过OSF改进目标恢复网络的恢复结果。PTG-RM由两个组成部分组成,预训练引导空间变化增强(Pre-Train-Guided Spatial-Varying Enhancement,PTG-SVE)和预训练引导通道-空间注意力(Pre-TrainGuided Channel-Spatial Attention,PTG-CSA)。PTG-SVE可以实现最佳的短和长距离神经操作,而PTG-CSA增强了与恢复相关的空间-通道注意力。
实验证明,PTG-RM以其紧凑的体积(小于1M参数)有效地增强了不同任务中各种模型的恢复性能,包括低光增强、去雨、去模糊和去噪。
5、Image Restoration by Denoising Diffusion Models with Iteratively Preconditioned Guidance

训练深度神经网络已成为解决图像恢复问题的常用方法。对于每个模型训练一个“任务特定”的网络的替代方法是,使用预训练的深度去噪器仅在迭代算法中强加信号先验,而无需额外训练。最近,这种方法基于采样的变体在扩散/基于分数的生成模型兴起时变得流行起来。
本文提出一种新的引导技术,基于预处理,可以沿着恢复过程从基于BP的引导过渡到基于最小二乘的引导。所提出方法对噪声具有鲁棒性,而且实施起来比替代方法更简单(例如,不需要SVD或大量迭代)。将其应用于优化方案和基于采样的方案,并展示其在图像去模糊和超分辨率方面相比现有方法的优势。
6、Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks

在大规模数据集上训练的扩散模型取得显著进展。然而,由于扩散过程中的随机性,它们经常难以处理需要保留细节的不同低层次任务。为克服这个限制,提出一个新的Diff-Plugin框架,使单个预训练的扩散模型能够在各种低层次任务中生成高保真度的结果。
具体来说,首先提出一个轻量级的Task-Plugin模块,采用双分支设计,提供任务特定的先验知识,引导扩散过程中的图像内容保留。然后,提出一个Plugin-Selector,可以根据文本指令自动选择不同的Task-Plugin,允许用户通过自然语言指示进行多个低层次任务的图像编辑。
在8个低层次视觉任务上进行大量实验结果表明,Diff-Plugin在现实场景中比现有方法表现优越。消融实验证实了Diff-Plugin在不同数据集大小下的稳定性、可调度性和支持鲁棒训练的特点。https://yuhaoliu7456.github.io/Diff-Plugin/
7、Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
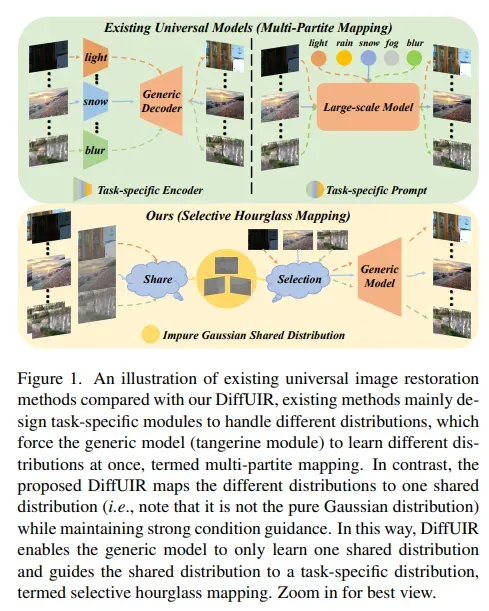
通用图像恢复,一项实际且有潜力的计算机视觉任务,适用于实际应用。这一任务主要挑战是同时处理不同的退化分布。现有方法主要利用任务特定条件(例如提示)来指导模型单独学习不同的分布,称为多部分映射。然而,对于通用模型学习来说,这种方法并不适用,因为它忽视了不同任务之间的共享信息。
这项工作基于扩散模型提出一种先进的选择性沙漏映射策略,称为DiffUIR。DiffUIR具有两个新的考虑因素。首先,为模型提供强大的条件指导,以获得精确的扩散模型生成方向(选择性)。更重要的是,DiffUIR将一种灵活的共享分布项(SDT)巧妙地集成到扩散算法中,逐渐将不同的分布映射到一个共享分布中。在反向过程中,结合SDT和强大的条件指导,DiffUIR迭代地将共享分布引导到具有高图像质量的任务特定分布(沙漏)。
通过只修改映射策略,在五个图像恢复任务、通用设置的22个基准数据集和零样本泛化设置上实现了最先进的性能。令人惊讶的是,仅用轻量级模型(仅为0.89M),就能实现出色的性能。https://github.com/iSEE-Laboratory/DiffUIR
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
ICCV 2023 | 最全AIGC梳理,5w字30个diffusion扩散模型方向,近百篇论文!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!
版权声明:本文为博主作者:机器学习与AI生成创作原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/lgzlgz3102/article/details/137334036