最近在看ATOM,作者在线训练了一个分类器,用的方法是高斯牛顿法和共轭梯度法。看不懂,于是恶补了一波。学习这些东西并不难,只是难找到学习资料。简单地搜索了一下,许多文章都是一堆公式,这谁看得懂啊。
后来找到一篇《An Introduction to the Conjugate Gradient Method Without the Agonizing Pain》,解惑了。
为什么中文没有这么良心的资料呢?英文看着费劲,于是翻译过来搬到自己的博客,以便回顾。
由于原文比较长,一共 页的PDF,所以这里分成几个部分来写。
目录
共轭梯度法(Conjugate Gradients)(1)
共轭梯度法(Conjugate Gradients)(2)
共轭梯度法(Conjugate Gradients)(3)
共轭梯度法(Conjugate Gradients)(4)
共轭梯度法(Conjugate Gradients)(5)
Abstract (摘要)
共轭梯度法(Conjugate Gradient Method)是求解稀疏线性方程组最棒的迭代方法。然鹅,许多教科书上面既没有插图,也没有解说,学生无法得到直观的理解。时至今日(今日指1993年,因为这份教材是1993年发表的),仍然能看到这些教材的受害者们在图书馆的角落里毫无意义地琢磨。只有少数的大佬破译了这些正常人看不懂的教材,有深刻地几何上的理解。然而,共轭梯度法只是一些简单的、优雅的思路的组合,像你一样的读者都可以毫不费力气学会。
本文介绍了二次型(quadratic forms),用于推导最速下降(Steepest Descent),共轭方向(Conjugate Directions)和共轭梯度(Conjugate Gradients)。
解释了特征向量(Eigenvectors),用于检验雅可比方法(Jacobi Method)、最速下降、共轭梯度的收敛性。
还有其它的主题,包括预处理(preconditioning)和非线性共轭梯度法(nonlinear Conjugate Gradient Method)
本文的结构:
1. Introduction(简介)
当我决定准备学共轭梯度法(Conjugate Gradient Method, 简称 CG)的时候,读了 种不同的版本,恕我直言,一个都看不懂。很多都是简单地给出公式,证明了一下它的性质。没有任何直观解释,没有告诉你 CG 是怎么来的,怎么发明的。我感到沮丧,于是写下了这篇文章,希望你能从中学到丰富和优雅的算法,而不是被大量的公式困惑。
CG 是一种最常用的迭代方法,用于求解大型线性方程组,对于这种形式的问题非常有效: 其中:
是未知向量,
是已知向量。
是已知的 方形的(square)、对称的(symmetric)、正定的(positive-definite)矩阵。
(如果你忘了什么是“正定”,不用担心,我会先给你回顾一下。)
这样的系统会出现在许多重要场景中,如求解偏微分方程(partial differential equations)的有限差分(finite difference)和有限元(finite element)法、结构分析、电路分析和你的数学作业。
像 CG 这样的迭代方法适合用稀疏(sparse)矩阵。如果 是稠密(dense)矩阵,最好的方法可能是对
进行因式分解(factor),通过反代入来求解方程。对稠密矩阵
做因式分解的耗时和迭代求解的耗时大致相同。一旦对
进行因式分解后,就可以通过多个
的值快速求解。稠密矩阵和大一点的稀疏矩阵相比,占的内存差不多。稀疏的
的三角因子通常比
本身有更多的非零元素。由于内存限制,因式分解不太行,时间开销也很大,即使是反求解步骤也可能比迭代解法要慢。另外一方面,绝大多数迭代法用稀疏矩阵都不占内存且速度快。
下面开始,我就当作你已经学过线性代数(linear algebra),对矩阵乘法(matrix multiplication)和线性无关(linear independence)等概念都很熟悉,尽管那些特征值特征向量什么的可能已经不太记得了。我会尽量清楚地讲解 CG 的概念。
2. Notation(标记)
除了一些特例,这里一般用大写字母表示矩阵(matrix),小写字母表示向量(vector),希腊字母表示标量(scalar)。
所以 是一个
的矩阵,
和
是向量(同时也是
矩阵)。公式(1) 的完整写法:
两个向量的内积(inner product)写成
,可以用标量的和
来表示。
注意这里 。 如果
和
是正交(orthogonal)的,则
。
一般来说,这些运算会得到 的矩阵。像
和
这种,运算结果是一个标量值。
对于任意非零向量
,如果下面的 公式(2) 成立,则矩阵
是正定(positive-definite)的:
这可能对你来说没什么意义,但是不要感到难过。
因为它不是一种很直观的概念,很难去想像一个正定和非正定的矩阵看起来有什么不同。
当我们看到它怎么对二次型的造成影响时,你就会对“正定”产生感觉了。
最后,还有一些基本的定义:
3. The Quadratic Form(二次型)
二次型(quadratic form)简单来说是一个标量。
一个向量的二次型方程具有以下形式:
其中 是一个矩阵,
是一个向量,
是一个标量常数。
如果 是对称(symmetric) 且正定(positive-definite),则
的最小化问题等同于求解
。
本文的所有例子都基于下面的值来讲解:
可以把 (4) 代入 (3) 得到:
所以二次型其实是个变量的二次齐次多项式。
再举一个例子,当有个变量时,二次型大概像这样子:
方程组 如图(1)所示。
通常来说,方程的解 处于
维超平面相交的地方,这些相交的位置维度是
。
(直线相交于点,平面相交于线, 维相交于面,
)。
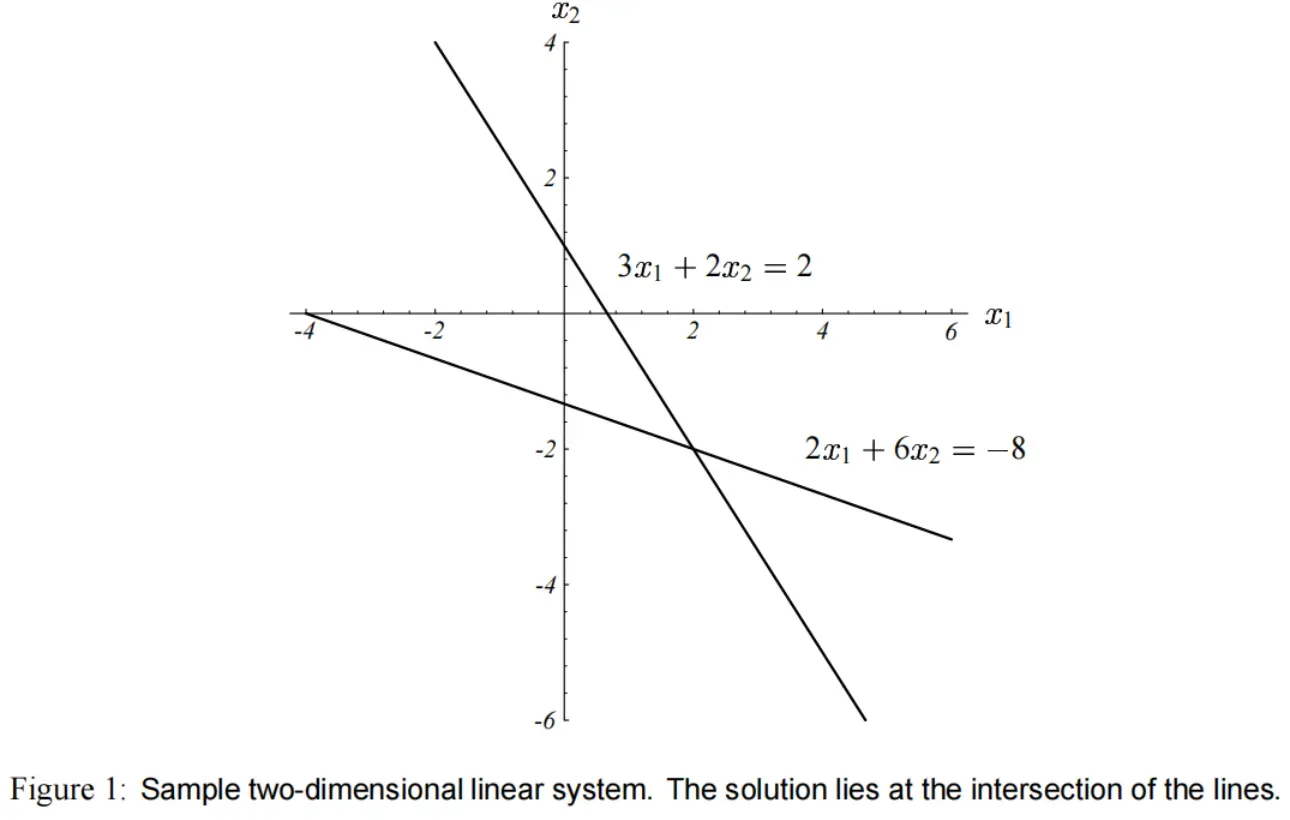
对于 这个问题 ,方程的解
,也就是 图(1) 两条直线的交点。
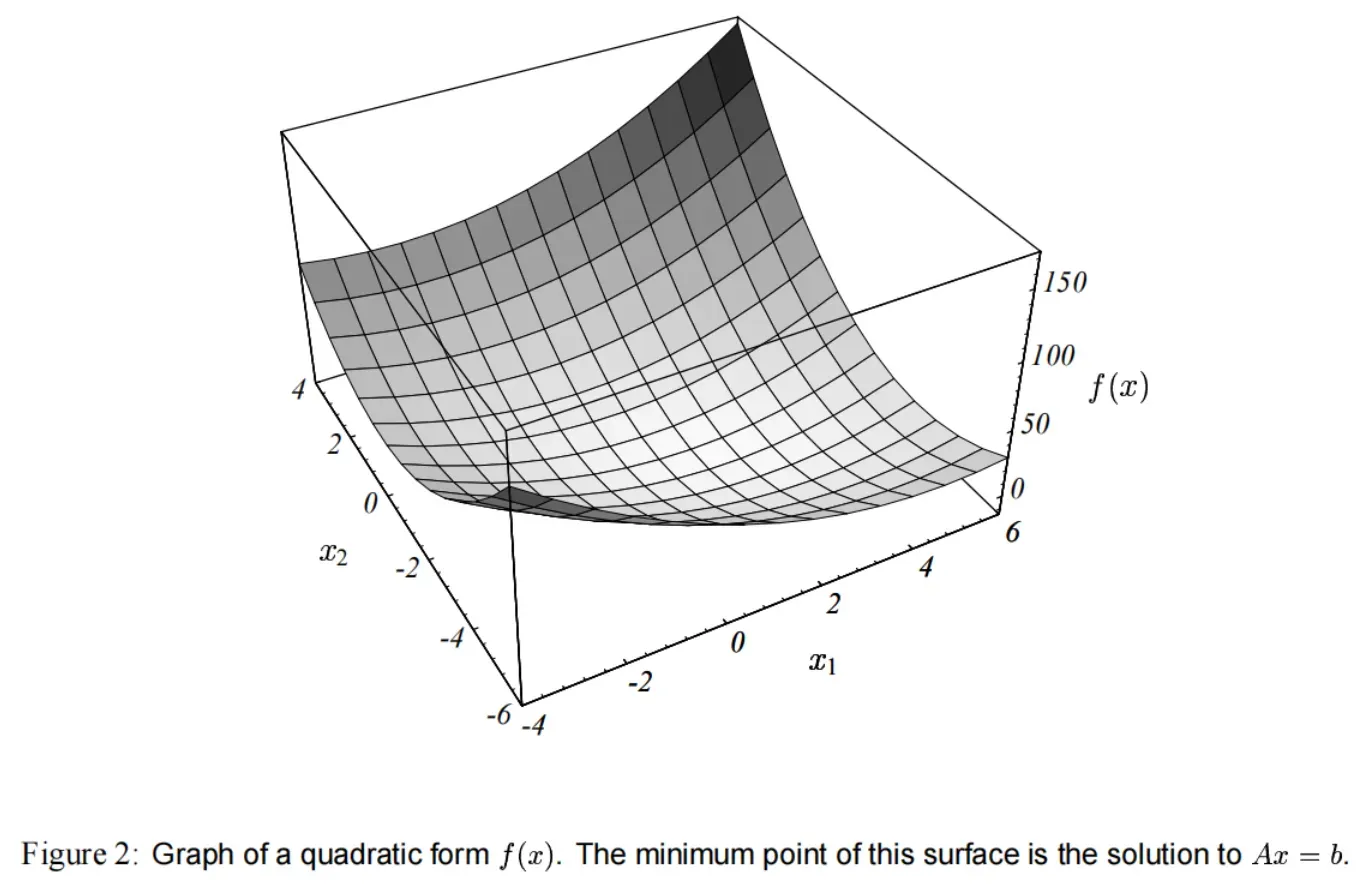
对应的二次型 ,它的曲线如图(2)所示。
的解是
的最小值的点。
的等高线(contour plot)如图(3)所示。
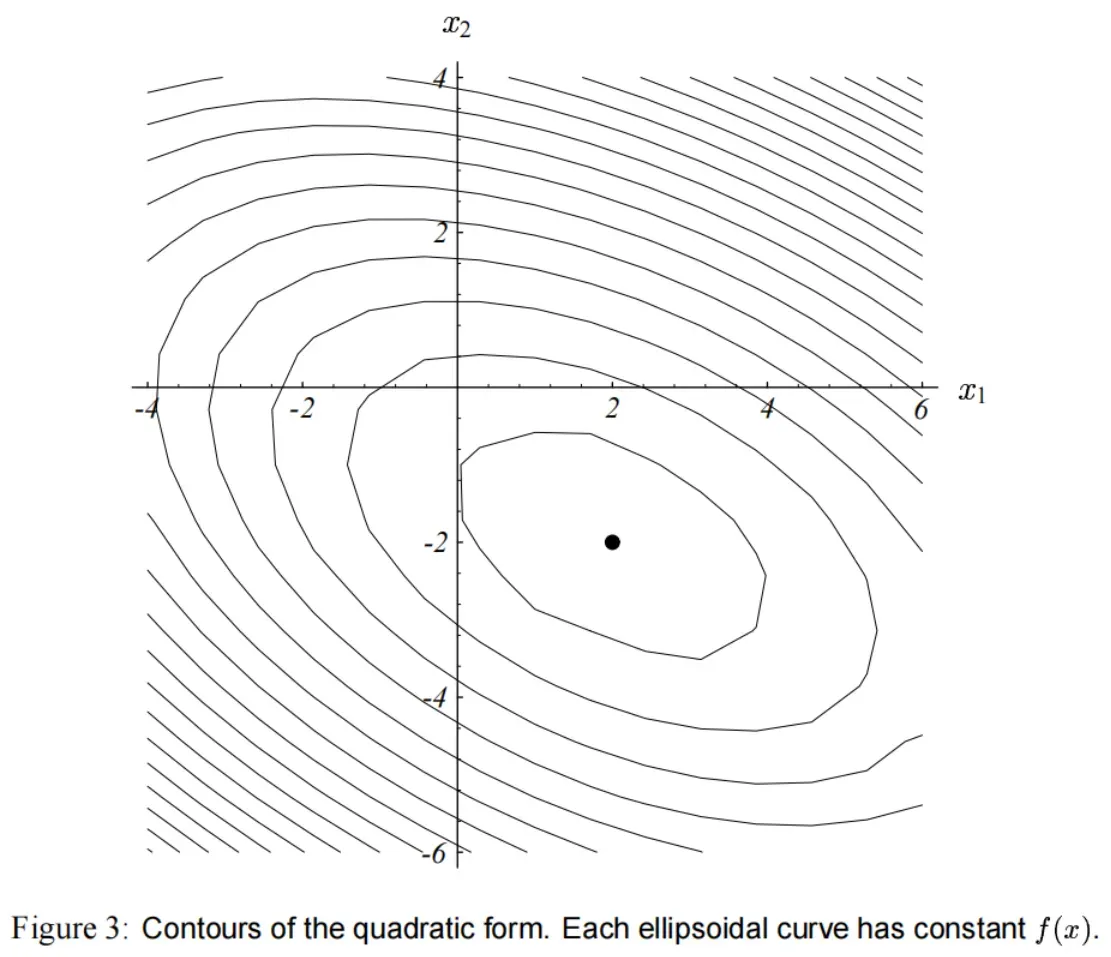
由于 是正定的,所以函数
的形状是一个抛物碗状。
二次型的梯度(gradient)由以下式子而来:
梯度是一个向量场,对于每一个点 ,它指向
增大得最快的方向。
图(4) 展示了 式子(3) 的梯度,其中具体的参数如 式子(4) 所示。
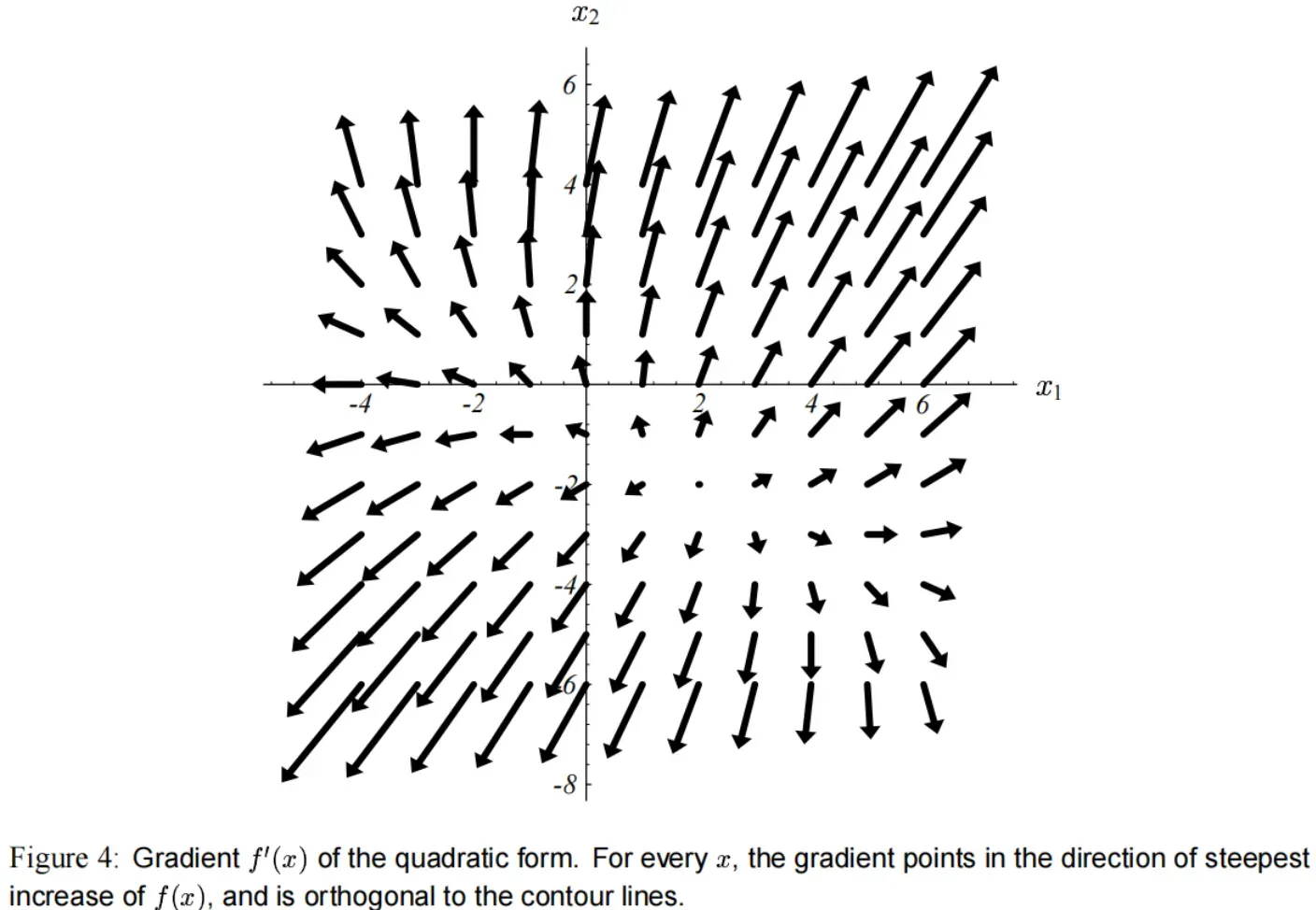
在碗状的底部,梯度为 。因此令
可以最小化
。
应用 式子(5) 来求导,可以得到: 如果
是对称的,式子会被化简为
因为此时
。
梯度设为 ,就能得到 式子(1),也就是我们要求解的线性方程组。
的解就是
的关键点。如果
是正定且对称的,则这个解能使
最小化。
所以, 的解
能使
最小。
如果 不是 正定 的,从 式子(6) 可知用 CG 可以求解方程组
。
因为
是对称的
【附录C1】
假设是对称的。
令满足
,并且能使二次型(式子(3)) 最小;
令为误差项;
则:
如果有
,因此
。
为什么 对称 且 正定 的矩阵有这样的性质? 可以考虑函数 上任意一点
,和它的解
之间的关系。
如果 A 是对称的(无论正定与否),由 式子(3) 和 附录C1,令 可得:
如果此时 又能正定的话,由 式子(2) 得知对于任意
有
,所以一定有
,所以
是全局最小。
正定(positive-definite) 矩阵到底意味着什么?最直观的感受就是, 的图形是一个碗状。
如果 是 非正定 的,那么有以下几种可能:
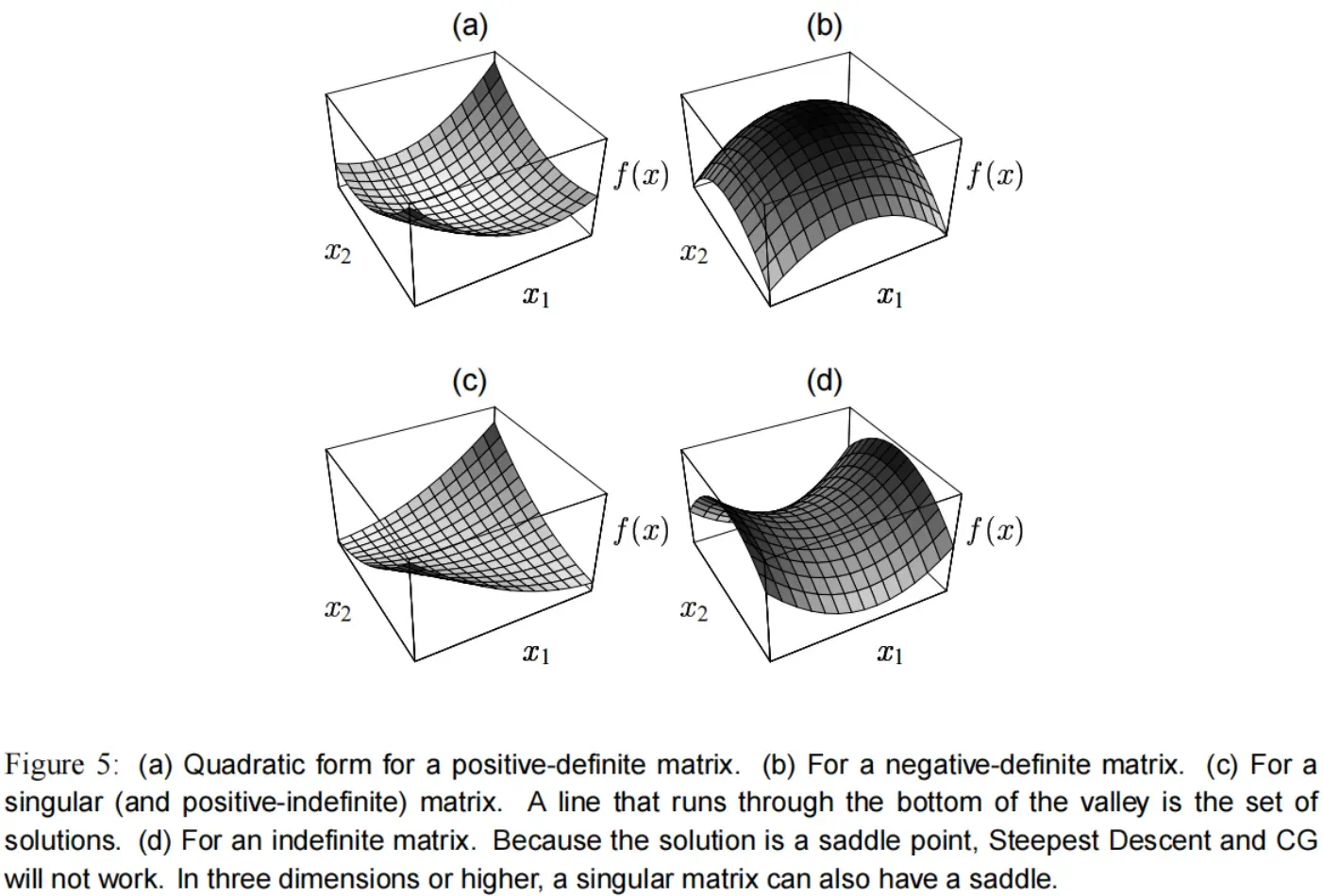
负定(negative-definite)矩阵。相当于对正定取反,如 图(5)b。
奇异(singular)矩阵。这种情况下解不是唯一的,如 图(5)c。解集是一条直线或者超平面,在那里
具有相同的值。
如果矩阵
不属于以上情况,那么
是一个鞍点(saddle point),最速下降法 和 共轭梯度法 都将失效。
式(3) 中的 和
决定碗状的极小值在哪里,但不影响抛物面的形状。
为什么要把线性方程组弄得这么麻烦?
因为下面要讲的 最速下降法 和 共轭梯度法 ,需要基于 图(2) 这种最小化问题,才能进行直观的理解。
而不是研究 图(1) 这种超平面的相交的问题。
(即,把问题转成求 极小值,而不是 找交点)
4. The Method of Steepest Descent(最速下降法)
或者叫最陡下降。
我们会从任意点 开始,滑到碗状面的底部。我们会走到
,直到足够接近方程的解
。
每走一步的时候,我们要选择 下降最快的方向,也就是
的反方向。
根据 式子(7),这个方向就是 。
这里再引入一些定义:
误差(error)
。
表示与 解 有多远。(这个解叫做 精确解(exact solution))
残差(residual)
。
表示与正确值 有多远。
容易发现,残差 可以由 误差 变换得来:
。
误差反映的是变量的层面,残差描述的是函数值的层面,所以通过 从变量空间转换到函数值的空间。
更重要的是: 你可以认为 残差
是 最陡下降的方向 (原函数的导数的反方向)。
(这里也很容易理解,因为向量是有方向的,它反映了函数值和真实值之间的距离,同时方向也指向真实值)
对于非线性问题,我们用的就是这一种定义。
所以每当你看到残差 ,请记住它是最速下降的方向。
假设我们从 开始,
。
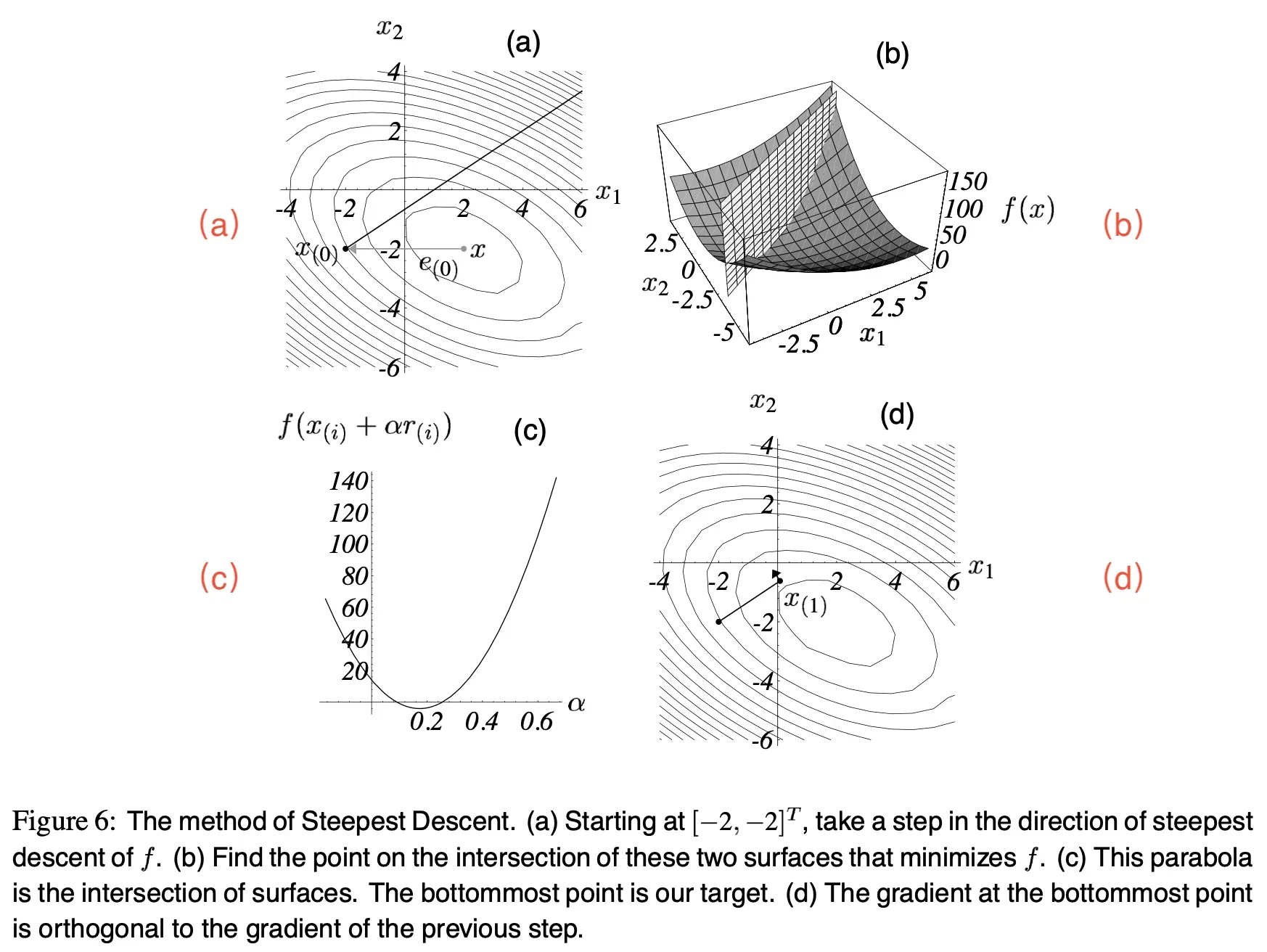
第 步,我们沿着最陡方向走
步,落在 图(6)a 中的实线的某处。
换句话来讲,我们会选择这样一个点:问题是,这一步要迈多大呢?(可以把
看做学习率)
线搜索(line search)是这样一种过程:沿着一条线选择一个 ,使得
最小化。
图(6)b :竖直平面和碗状曲面相交于一条横切线,我们要的点在这条线上。
图(6)c :是这条横切线(从这个视角来看是抛物线)。那么在抛物线的底部, 的值是多少呢?
由基本推导有,当方向导数(directional derivative) 时,
能使
最小。
根据链式求导法则:。
令这条式子为 ,我们会发现这个
应该使
和
正交。见 图(6)d。
所以,为什么我们期望这些向量正交,这就是最直观的原因 。☝↑☝
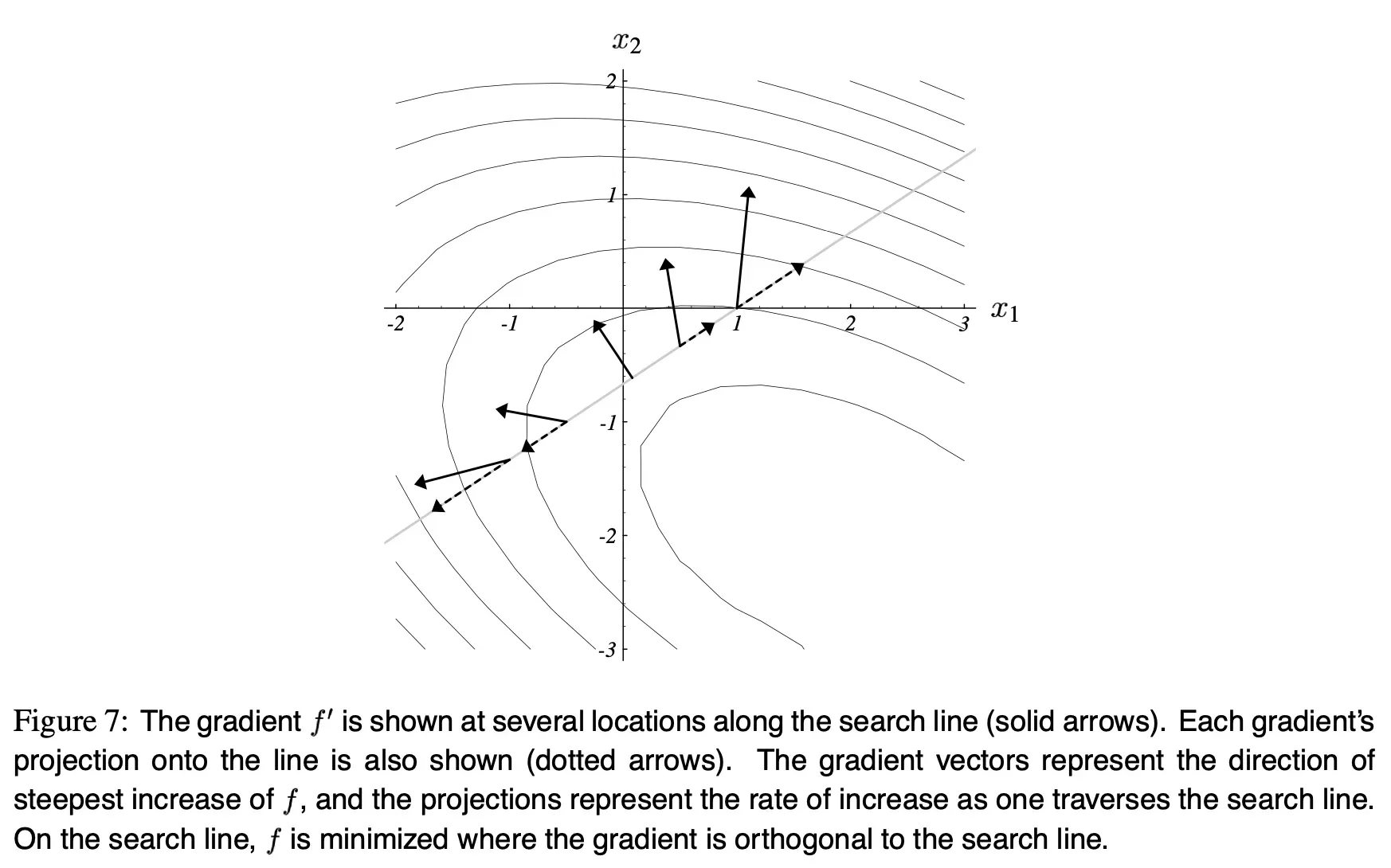
图(7) 展示了搜索线上不同点的梯度向量。虚线是这些梯度向量在搜索线上的投影。这些虚线的大小等同于 图(6)c 中抛物线上每个点的斜率。这些投影表示当你在这条搜索线上移动时, 的增长率。当投影为
时,
最小,此时的 梯度 和 搜索线 正交。
为了确定 ,由于又有
,于是有:
结合起来,最陡下降法(Steepest Descent)就是:
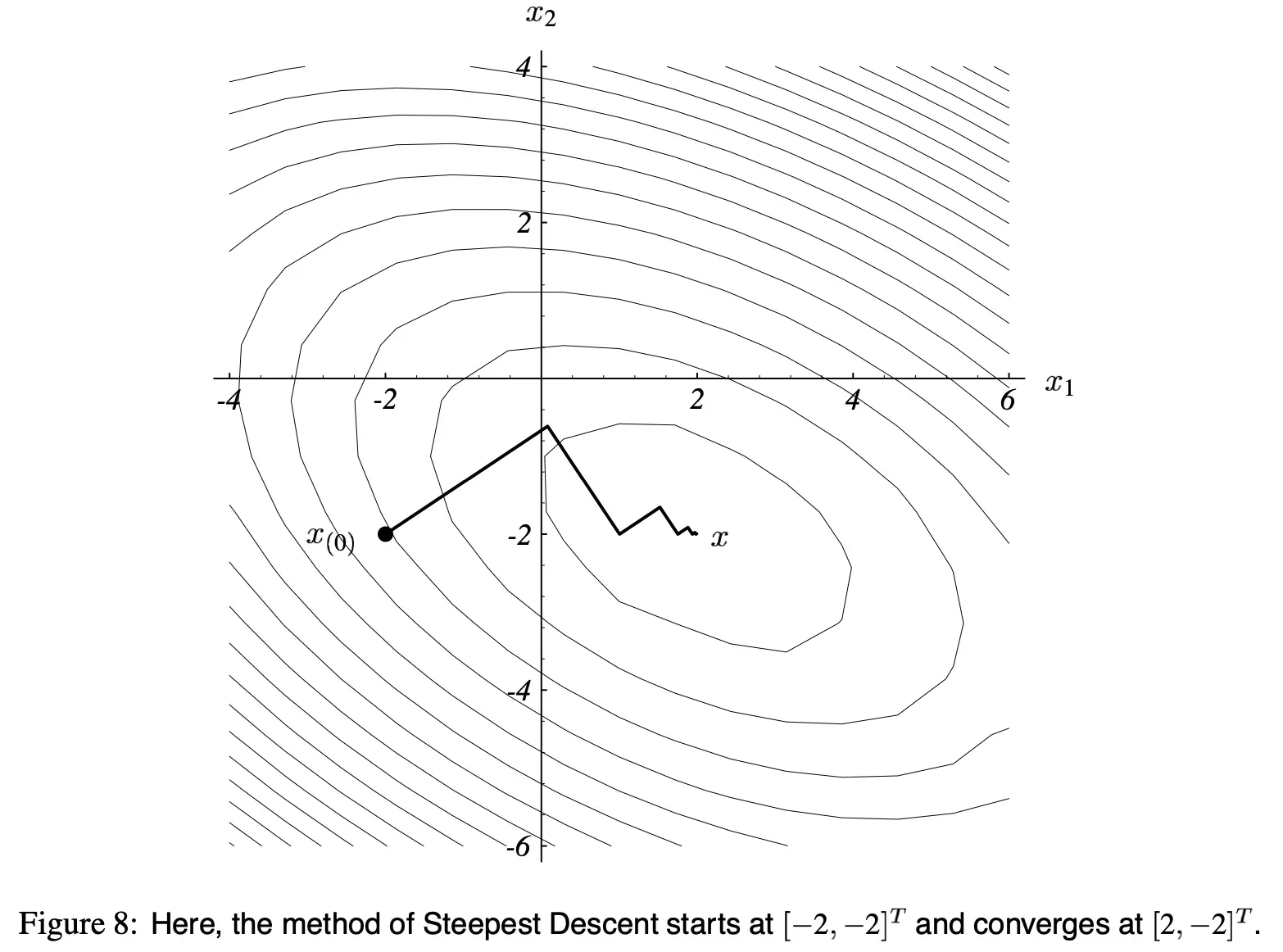
如 图(8) 所示,一直迭代,直到收敛。
由于每一次的梯度都和上一次的正交,所以这个路径呈“之”字型。
上面的算法,要在每轮迭代中做两次矩阵-向量的乘法,不过好在有一个可以被消掉。
在 式子(12) 两边同时左乘 ,再加
,得:
尽管 式子(10) 仍然要算一次 ,不过之后每轮迭代都可以用 式子(13) 了。
式子(11) 和 式子(13) 中的乘法 只需要被计算一次。
这个迭代的缺点是, 公式(13) 生成的序列没有从 的值里得到任何回馈。因此对浮点舍入造成的累积误差会使
收敛至
附近的点,而无法真正地收敛到
。这种影响可以通过周期性地使用 式子(10) 来重新计算正确的残差来避免。
在分析最陡下降的收敛性之前,还要先讲一下特征向量(eigenvectors)的知识,确保你对特征向量有深刻的理解。
5. Thinking with Eigenvectors and Eigenvalues(特征向量和特征值的思考)
上完线性代数课程后,我对特征向量和特征值了如指掌。如果你的老师和我一样,你会记得自己解决了一些关于特征值的问题,但你从来没有真正理解过它们。不幸的是,如果没有对它们的直观理解,CG 也没有意义。如果你已经很有天赋,可以跳过这一节。
特征向量(eigenvectors)主要用来当做分析工具,最陡下降法和共轭梯度法不用计算特征向量的特征值。
5.1 Eigen do it if I try
矩阵 的特征向量
是一个非零的向量,用
乘以它的时候,不会发生旋转(只可能掉头)。
特征向量 的长度可能会变,或者反方向,但不会转。
也就是说,存在一些标量常数 使得
。
就是
的特征值(eigenvalue)。
为什么要讲这个,因为迭代法通常会用 一次又一次地乘上特征向量,而这时只会发生两种情况:
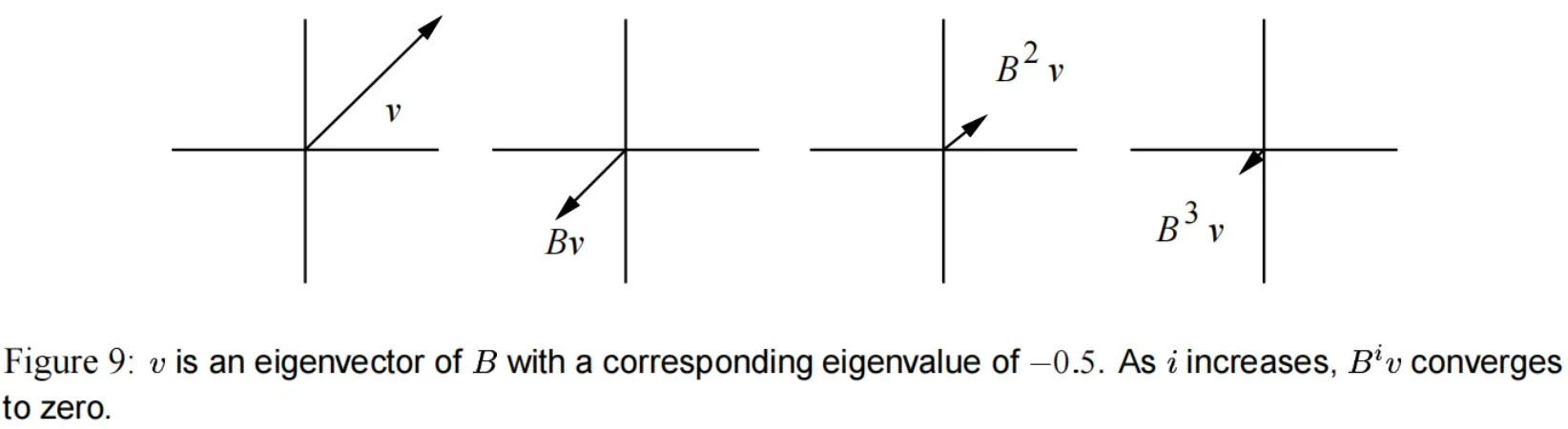
(1) 如果特征值 ,随着
的迭代,
会消失。(如 图(9))
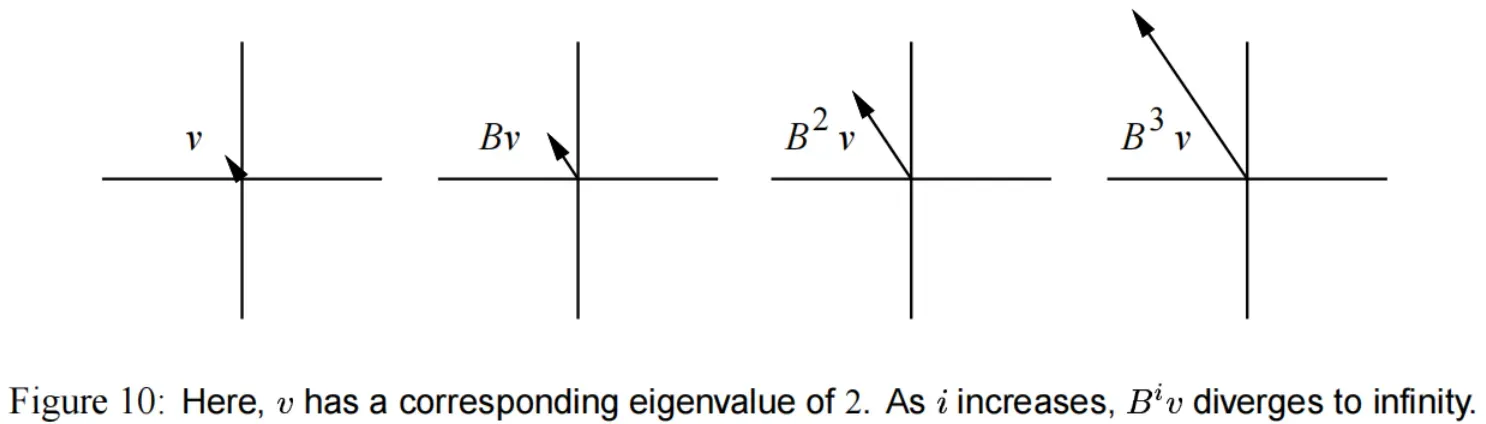
(2) 如果特征值 ,随着
的迭代,
会增大到无穷。(如 图(10))
如果 是对称的(然而一般都不是),一般会存在一组
个线性无关的特征向量:
。
这组向量不是唯一的,因为可以用任意的非零常数对它们缩放。
每个特征向量都有对应的特征值:。
对于确定的矩阵,特征值是唯一的。
特征值可能彼此相等,也可能不相等,例如单位矩阵 的特征值都是
,所有非零向量都是
的特征向量。
如果 乘以一个向量,而该向量不是特征向量呢?
在理解线性代数时有一个非常重要的技巧:把该向量拆成 多个向量的和 ,这些多个向量特性是已知的。
考虑一组特征向量 ,构成
维空间
的基(因为对称矩阵
有
个线性无关的特征向量)。
在该空间中其它任意的 维向量都可以用
的线性组合来表示。
由于矩阵-向量的乘法满足 分配律,所以可以分别检查 对每个特征向量的影响。
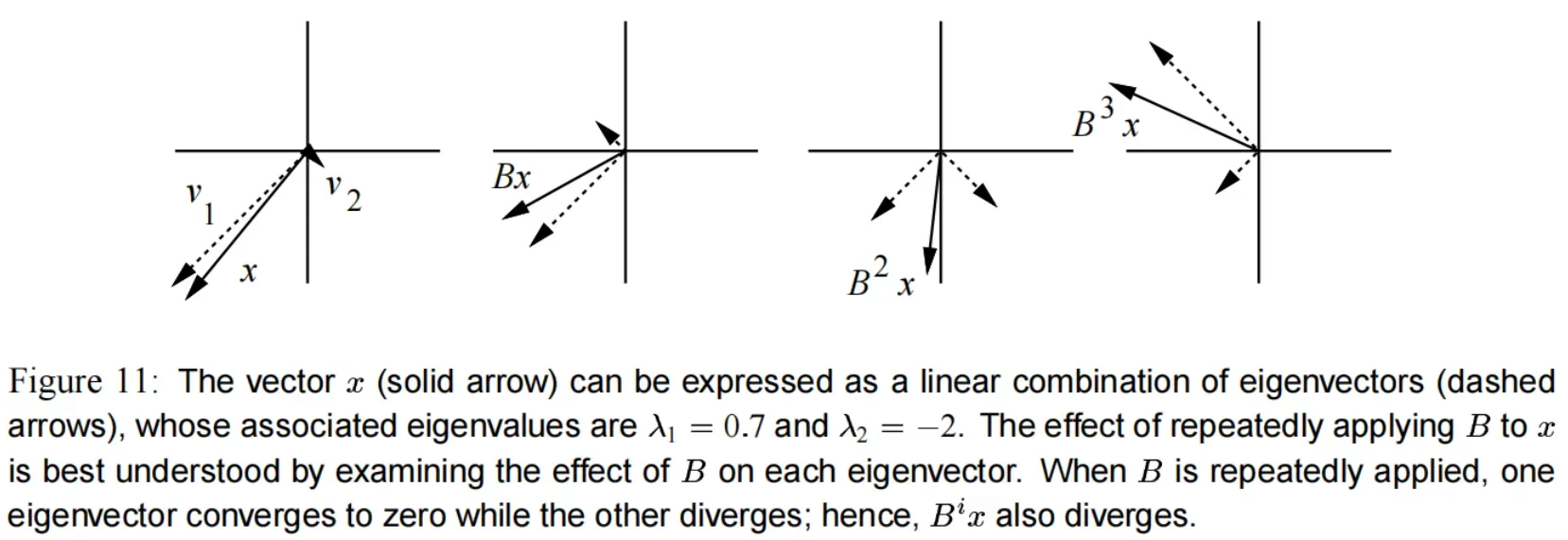
在 图(11) 中,向量 被表示为特征向量
和
的和。
用 乘以
,等价于分别乘以
和
再加起来。
在迭代过程中有 。
如果特征值都小于 ,
会收敛至
,因为迭代地乘
后,组成
的特征向量都趋于
了。
如果其中一个特征值大于 ,
将发散至无穷。
这也是为什么做数值分析的很重视一个矩阵的光谱半径(spectral radius):
如果我们希望 快速收敛到
,
应当小于
,越小越好。
值得一提的是,存在一类非对称矩阵,不具备完整的 个线性无关特征向量。
这类矩阵被称为缺陷矩阵(defective)。关于它的细节很难在本文讲清楚,不过可以通过广义特征向量(generalized eigenvectors)和 广义特征值(generalized eigenvalues)来分析缺陷矩阵的性质。 趋于
的条件是:当且仅当所有广义特征值都于
。但这个证明起来很难。
下面是一个有用的事实:正定矩阵的特征值都是正数。
可以用特征值的定义来证明:
根据正定矩阵的定义,对于非零向量 ,有
是正数,而
,所以
必须大于为正。
5.2 Jacobi iterations(雅克比迭代)
当然,总是收敛到 的过程不会帮助你吸引到朋友。
考虑一个更有用的过程:用雅克比(Jacobi Method)方法求解 。
矩阵 被拆成两部分:
(1) ,对角线上的元素与
的对角线相同,其余部分为
。
(2) ,对角线上的元素为
,其余部分与
相同。
于是 。
我们推导出雅克比法:
由于 是对角矩阵,很容易求逆。
可以通过下面的递归式,把 式子(14) 的恒等式转为迭代法:
给定起始向量 ,这条公式生成了一序列的向量。我们希望每个连续的向量都比最后一个更接近解
。
称为 式子(15) 的驻点(stationary point)。因为,如果
,则
总是等于
。(也就是到达
之后,再迭代也不动了)
是的,这个推导可能对你来说过于直接。
除了 式子(14) 以外,我们其实可以为 形成任意数量的恒等式。
事实上,简单地把 分成不同的东西,即选择不同的
和
,我们可以推导出高斯-赛德尔( Gauss-Seidel method)方法,或者其变种:SOR( Successive Over-Relaxation)。我们希望的是,所选择的矩阵使
具有小的光谱半径。所以为了简单起见,这里直接选择了雅克比切法。
假设我们从任意的 出发。对于每次迭代,用
乘以这个向量,然后加上
。到底每次迭代在做什么呢?
同样地,我们可以把一个向量看成是多个已知向量的和。
把每次迭代 当做是精确解
和误差项
的和。于是 式子(15) 就变成了:
每次迭代都不影响 的 “正确部分”(因为
是一个驻点);但每次迭代影响误差项。
显然,由 式子(16) 得知,如果 ,则随着
的增大,
将趋于
。
因此,初始向量 不会影响必将出现的结果!
当然, 的选择会影响迭代次数。然而,这种影响远远小于光谱半径
的影响,是它决定了收敛的速度。
假设 是
的特征向量,对应的特征值是最大的(即
)。
如果初始误差 用特征向量的线性组合来表示,它的成分中包含
的方向,这部分将会是收敛得最慢的。(因为
对应的特征值是
,
是所有特征值里面最大的,所以
缩小的最慢,所以这个方向收敛得很慢)
通常都不是对称的(就算
是对称的),还可能是缺陷矩阵。然而,雅克比方法的收敛速度很大程度上取决于
,而
又是由
决定的。雅克比方法不能对所有的
收敛,即使是正定的
。
5.3 A Concrete Example(一个具体例子)
为了证明这些想法,我来求解由 式子(4) 指定的实例。
首先,我们需要求解特征向量和特征值。
根据定义,对于具有特征值 的特征向量
,有:
由于特征向量非零,则 一定是奇异矩阵,所以:
的行列式称为特征多项式(characteristic polynomial),是
的
次多项式,其平方项都是特征值。
代入 式子(4) 的值,则 的特征多项式为:
因此特征值为 ,
。(有两个特征向量)
第 个特征向量:
为了找到到关于 的特征向量:
的解就是一个特征向量:
。
即 的特征向量为
第 个特征向量:
同样地,可以找到 的特征向量为
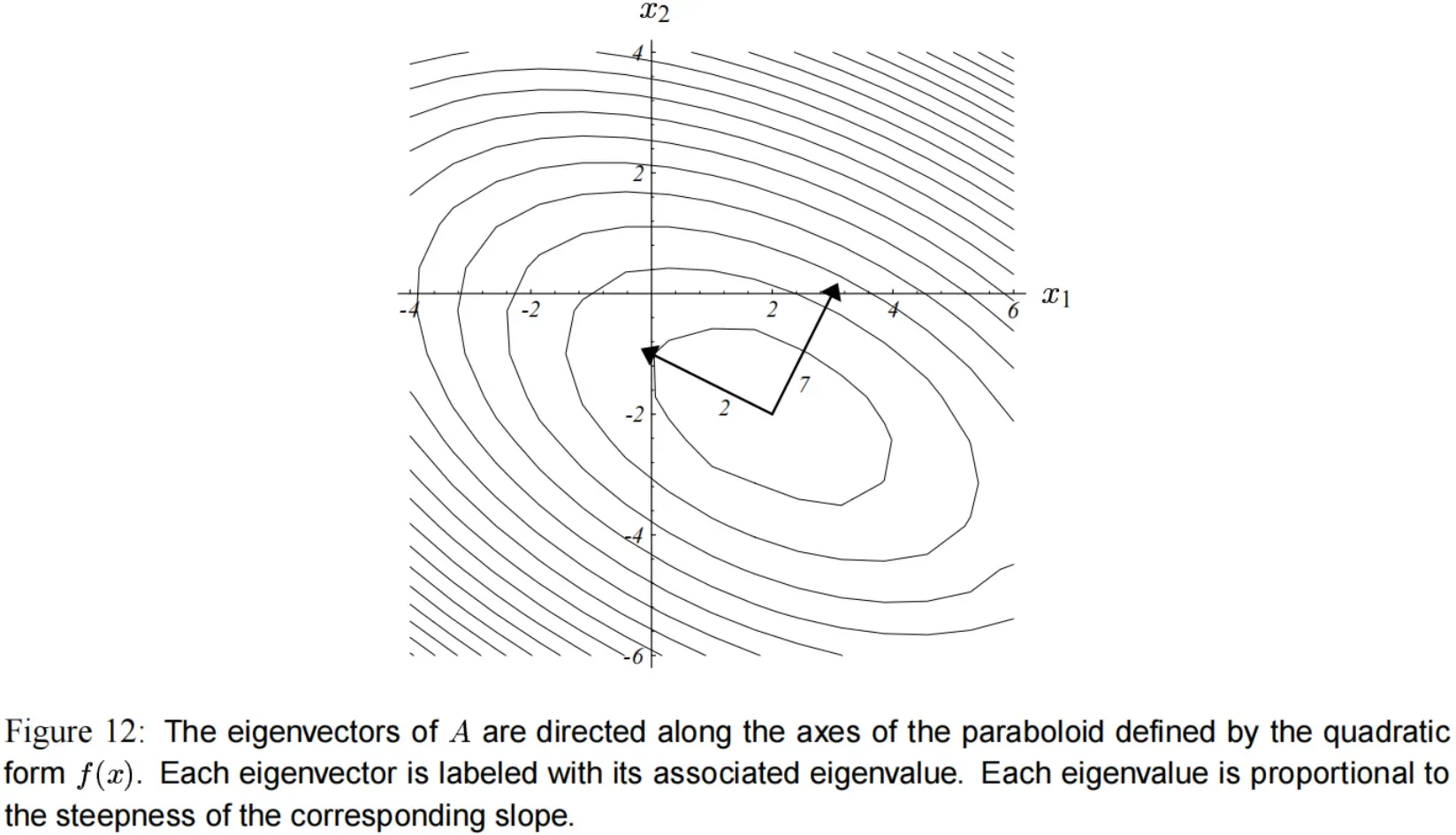
在 图(12) 中,我们可以看到特征向量和椭圆的轴一致,特征值较大的那个特征向量对应更陡的斜坡(slope)。
(负的特征值表示 沿着该轴减小,如 图(5)b 和 图(5)d )
现在再来看实际中的雅克比方法。同样采用 式子(4) 中的数值,我们有:
所以矩阵 ,求解
的特征值特征向量:
有对应于特征值 的特征向量
,对应于特征值
的特征向量
。
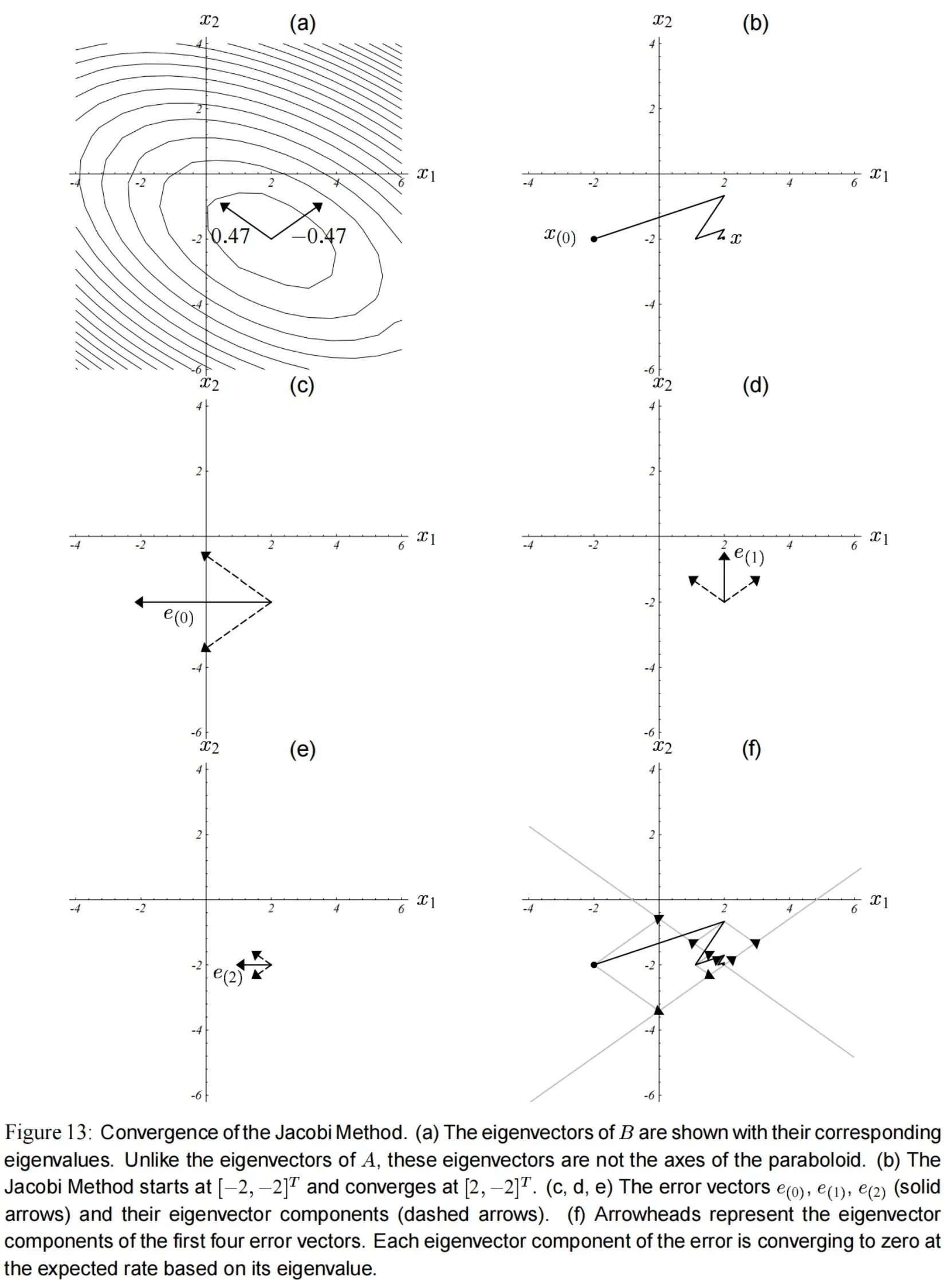
这两个特征向量如 图(13)a 所示。
注意, 的特征向量与
的特征向量不重合,与碗状面的轴也无关。
误差项 表示为
的特征向量的线性组合。而两个特征向量都小于
,并且有一个是负的,所以迭代
会使特征向量收敛到
,同时其中一个特征向量的方向不断地反转,如 图(13)的c,d,e 所示。
误差项 越来越小,则
收敛于
。
图(13)b 展示了雅克比方法的收敛情况。
文章出处登录后可见!