机器学习分类
机器学习作为人工智能的一个重要分支,主要分为监督学习、无监督学习和强化学习三类。如图所示: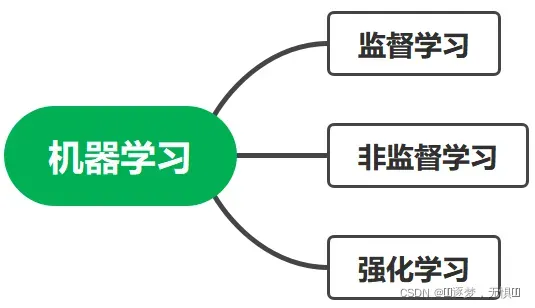
强化学习和监督学习的异同
监督学习需要人为地给定标签,并从有标签的训练样本中学习,以便正确预测训练集外样本的标签。无监督学习不需要给定标签,而是从无标签的训练样本中学习,挖掘训练样本中的潜在结构信息。
强化学习与上述两种学习方法不同:
第一个区别:强化学习的训练样本(在这种情况下,是代理与环境交互产生的数据)没有标签,只有延迟的奖励信号。强化学习从训练数据中学习,希望获得从状态到动作的映射。
第二个区别:监督学习和非监督学习的数据是静止的,不需要与环境进行交互,如分类聚类。而强化学习是一个序贯决策(Sequential Decision Making)的过程,需要不断的与环境进行交互来产生数据,并且产生的数据之间存在高度的相关关系。因此,相对于监督学习与非监督学习,强化学习涉及的对象更多、更复杂,如动作、环境、状态转移概率和回报函数等。
强化学习基础
智能体不断与环境交互,并使用来自环境的反馈来调整其行为以最大化累积奖励。
强化学习包括智能体和环境两大对象,智能体是算法本身,环境是与智能体交互的外部。智能体通过行为a作用于环境,环境反馈给智能体改变前后的状态s和s‘,以及回报r。如图所示: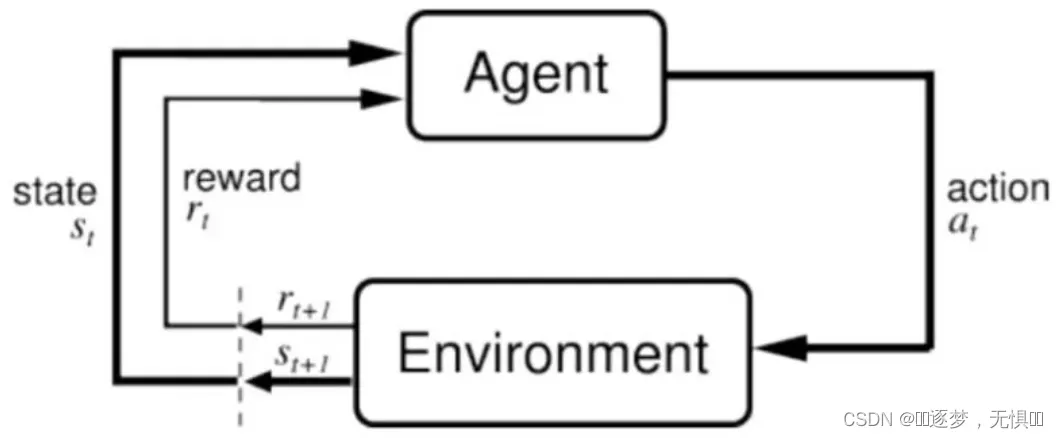
强化学习解决了哪些问题?
强化学习需要解决的是决策问题,即找到当前状态下的最优行为或行为概率。
强化学习分类
(1)有模型方法与无模型方法:根据智能体(agent)在解决强化学习问题时是否建立环境动力学模型划分。其中,在已知模型的环境中学习及求解的方法叫作有模型方法,如动态规划法;使用不依赖环境模型的方法,叫做无模型方法,如蒙特卡罗、时序差分法。
(2)解决强化学习的估计方法分为两种:建立状态值估计、建立策略的估计。可以根据不同的估计方法,将强化学习分为以下三类:
基于值函数(Value Based)的方法:求解时仅估计状态值函数,不去估计策略函数,最优策略在对值函数进行迭代求解时间接得到。如动态规划方法、蒙特卡罗方法、时序差分方法、值函数逼近法。
基于策略(Policy Based)的方法:最优行为或策略直接通过求解策略函数产生,不去求解各状态值的估计函数。所有的策略函数逼近方法都属于基于策略的方法,如蒙特卡罗策略梯度、时序差分策略梯度。
行动者-评论家方法(Actor-Critic,AC):求解方法中既有值函数估计又有策略函数估计。如优势行动者-评论家方法(A2C),异步优势行动者-评论家方法(A3C)
请分别解释随机和确定性策略
确定性策略指的是一个将状态空间映射到动作空间的函数。它本身没有随机性质,所以通常会结合ϵ \epsilonϵ-greey或往动作值中加入高斯噪声的方法来增加策略的随机性。一般都存在于基于值的算法中。
随机性策略是条件为π ( a ∣ s ) \pi(a|s)π(a∣s)情况下,动作a的条件概率分布。它本身带有随机性,获取动作时只需对概率分布进行采样即可。一般存在于基于策略的算法中。
回报、价值函数、行为价值函数这三个指标的定义是什么?
回报Gt为从t时刻开始往后所有的回报的有衰减的总和,也称“收益”或“奖励”。公式如下: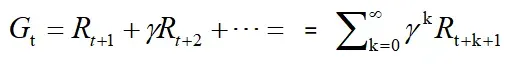
请分别解释以下三对概念:学习与规划、探索与利用、预测与控制
学习和规划:两者是适用于不同情况的强化学习方法的两大类。
学习针对环境模型未知的情况。代理不知道环境是如何工作的,状态如何转变,每一步的奖励是什么,只能通过与环境交互,使用试错法来逐步改进其策略。
计划针对的是代理已经知道或大致知道环境如何工作的情况。此时agent并不直接与环境交互,而是使用拟合的环境模型来获取状态转移概率和回报。在此基础上改进其策略。
探索意味着智能体试图在某个状态下尝试新的行为,以挖掘更多关于环境的信息。 Exploitation 是智能体根据已知信息选择当前最优行为以最大化奖励。代理在做出决策时需要平衡探索和利用。
预测和控制,也称为评估和改进,是解决强化学习问题的两个重要步骤。在解决具体的马尔可夫决策问题时,我们首先需要解决预测问题,即评估当前策略的好坏。具体方法一般是在既定策略下求解状态值函数。然后,在此基础上解决控制问题,即不断优化当前策略,直到找到一个足够好的策略,使未来收益最大化。在实际解决强化学习问题时,一般是先预测后控制,循环迭代直到收敛到最优解。
概括
强化学习是机器学习的一种,它不断地与环境交互,并利用来自环境的反馈来调整其行为以最大化累积回报。强化学习需要解决的是决策问题,即找到当前状态下的最优行为或行为概率。
强化学习包括智能体和环境两大对象,智能体是算法本身,环境是与智能体交互的外部。智能体通过行为a作用于环境,环境反馈给智能体改变前后的状态s和s‘,以及回报r。根据状态转移概率和回报是否已知,强化学习方法可以分为有模型方法和无模型方法。同时,根据在解决强化学习问题时,是对策略函数还是值函数进行逼近,强化学习方法可以分为基于值函数的方法、基于策略函数的方法以及行动者-评论家方法。
参考书:邹伟、葛玲、刘玉杓的《强化学习》
版权声明:本文为博主꧁༺逐梦,无惧༻꧂原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_49897963/article/details/123300447