【Diffusion Models】新加坡国立大学、腾讯强强联手Tune-A-Video:One-Shot微调图像扩散模型用于文本到图像的生成!_哔哩哔哩_bilibili【Diffusion Models】新加坡国立大学、腾讯强强联手Tune-A-Video:One-Shot微调图像扩散模型用于文本到图像的生成!共计2条视频,包括:[论文代码阅读]Tune-A-Video_ One-Shot微调图像扩散模型用于文本到图像的生成新加坡国立大学、腾讯、3连等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1q24y1V79k/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22视频生成和图像生成最大的不同在于要保证视频的连续性,运动主体不能变且运动主体的状态背景等不能产生突变,因此视频生成是一定要添加约束信息的,本文是在图像生成的基础上(T2I)通过特定设计的finetune来完成视频生成(T2V),作者说人类可以通过一个视频就能学习到新的试卷概念,因此设计了one shot video generation。怎么做呢?首先作者升级了stable diffusion的架构将2d卷积换成了3d卷积,并且将self-attention扩展到时空域,但转换之后的计算量会飙升,作者提出了sparse-causal attention,每一帧只和第一帧以及前一阵计算attention,可以极大减少计算量,在训练时,通过一段视频和相应的text进行微调,在推理时,要保证动词的一致性,可以更换背景和主题,依然能产生很好的连续性,one shot的视频实际上就是让T2I模型去学动作的。
https://www.bilibili.com/video/BV1q24y1V79k/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22视频生成和图像生成最大的不同在于要保证视频的连续性,运动主体不能变且运动主体的状态背景等不能产生突变,因此视频生成是一定要添加约束信息的,本文是在图像生成的基础上(T2I)通过特定设计的finetune来完成视频生成(T2V),作者说人类可以通过一个视频就能学习到新的试卷概念,因此设计了one shot video generation。怎么做呢?首先作者升级了stable diffusion的架构将2d卷积换成了3d卷积,并且将self-attention扩展到时空域,但转换之后的计算量会飙升,作者提出了sparse-causal attention,每一帧只和第一帧以及前一阵计算attention,可以极大减少计算量,在训练时,通过一段视频和相应的text进行微调,在推理时,要保证动词的一致性,可以更换背景和主题,依然能产生很好的连续性,one shot的视频实际上就是让T2I模型去学动作的。

如上图所示,第一行为原始的训练视频,训练完成之后,第二、三、四行均为推理视频,可见tune a video产生了主体一致性和动作一致性。
abstract:在现实中没有足够的视频文本对来训练T2V,人类可以从一个样本中学习新的视觉概念,因此本文研究一个新的方向,one shot视频生成,仅使用一个文本-视频对来训练一个T2V,基于已有的T2I的扩散的能力。有两个关键点,1.T2I模型能够生成很好的与动词相对齐的图像,2.扩展T2I模型同时产生多个图像有良好的一致性。为了进一步学习连续运动,采用定制的sparse-causal attention来微调模型。
1.introduction

视频生成的关键是保持一致主体的连续运动,motion and consistent object,如上图所示,第一行,给定text,例如一个男人正在沙滩上跑步,T2I能够很好的对齐动词信息,但是背景不同且不是一致的。但证明T2I可以通过cross-model attention来注意到动词。第二行作者采用了扩展的T2I模型,将T2I模型的中self-attention从一张图扩展到多张图保持跨帧时的内容一致性,并行的生成帧时都和第一帧做attention,可以看到尽管动作还不是连续的,但是主体背景等信息是一致的。可推论self-attention层仅由spatial similarities驱动而不是pixel positions(这块的解释可以从框架角度理解,因为最终推理时是无法改变one shot时学习的动作的,也就是说模型最终学习到的还是一致的空间相似度)。
tune a video对T2I在时间维度的简单膨胀,1.将3×3 conv换成1x3x3(unet中resnet卷积),2.将spatial self-attention 换成spatio-temporal cross-frame attention。提出了一个简单的tune策略,只更新attention block中的投影矩阵,从one-shot视频中捕获连续的运动状态,其余参数均被冻结。但是spatio-temporal cross-frame attention参数量很大,提出了一个新的变体,sparse-causal attention(SC-Attn),它只计算第一帧和前一帧,自回归生成视频。
2.method
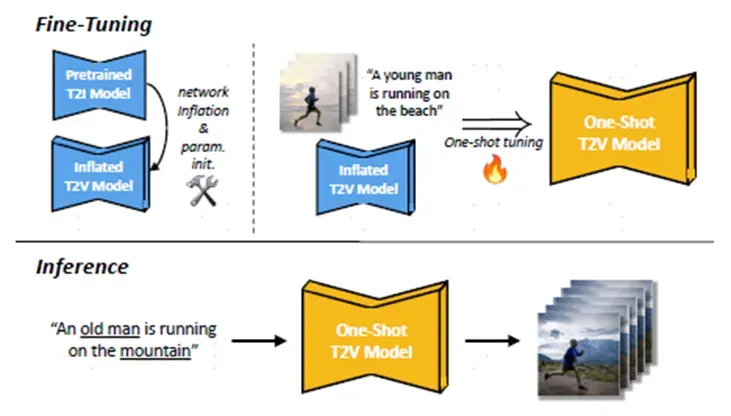
上图是本文的框架, 在fine-tune之前,现将T2I模型膨胀成T2V,其中T2V中的部分参数是从T2I中初始化的,然后采用一个视频去fine-tune,推理时,给定一个text即可生成视频,但是视频中动作是不能变的,one shot的视频就是一个动作。
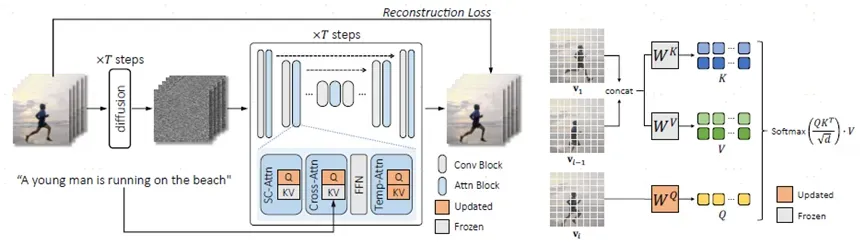
上图是pipeline,首先输入视频和文本,在unet中有三attention,第一个是SC-Attn,第二个是cross-Attn(不同模态之间的attn),第三个是新增的Temp-Attn,黄色表示不断更新的,灰色表示不更新的其中Q,query是不断更新的,KV是不更新。右侧是sparse-causal attention,计算第i帧,要取到第1帧和i-1帧,之后分别投影得到KV,再计算softmax。
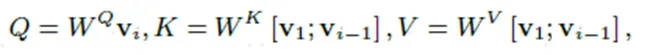
上式可以看到Q是第i帧通过投影矩阵产生,但是K和V就不是了,常规操作,ldm中text conditional都是加在KV上的。这里,第一帧做attention能够保证在生成内容上的全局一致性,与前一帧计算attention能够保持运动的一致性,连续性。
network inflation
普通的unet是由多层2d convolution residual blocks构成,后续是attention,每一个attention是由一个self-attention、一个cross-attention和一个feed-forward network构成,spatial self-attention利用特征图上pixel locations来实现similar correlations,cross-attention则考虑pixel和conditional input(text)之间的相关性。
首先对输入视频使用1x3x3的卷积,可以将frame的1转到batch处理,所以2d还是可以的。
sparse-casual attention
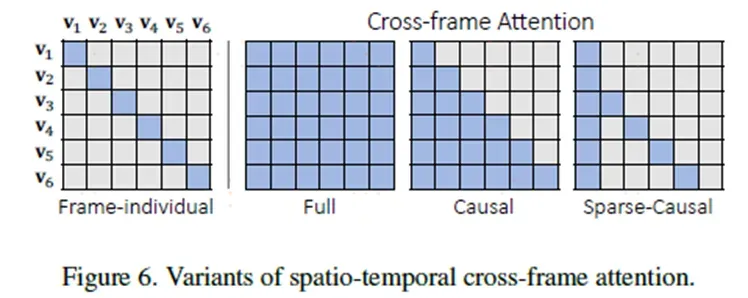
如上图所示,v表示帧,第一个是spatial attention,在单帧之间做attention,第二张图是spatio-temporal attention,每一帧和所有帧之间计算attention,计算量是第一张图的平方,第三张图是causal attention,第i帧只会和所有的i-1帧计算attention,第四张图就是本文使用的sparse-causal attention,第四帧只与第一帧和第三帧计算attention,是前一张图的稀疏版本。
文章出处登录后可见!