本文主要参考博客HRSID舰船检测数据集标签格式转换,json转为xml,在其代码基础上加入大量理解性注释、对其中个别代码进行修改,并在后面附加了json文件中提取信息写成VOC格式数据集中记录训练集与测试集图片名称信息的train.txt与test.txt文件的代码。
一、理解如何从COCO格式转到VOC格式,重点就在于了解COCO标注与VOC标注的区别。
从现在的主流数据集与模型框架来看,COCO格式的数据集使用频率较高,不过COCO转换到VOC格式也比较简单,建议将两者的标注文件结构与标注逻辑搞清楚,这也是目前CV领域的基础知识。
(1)COCO格式简介
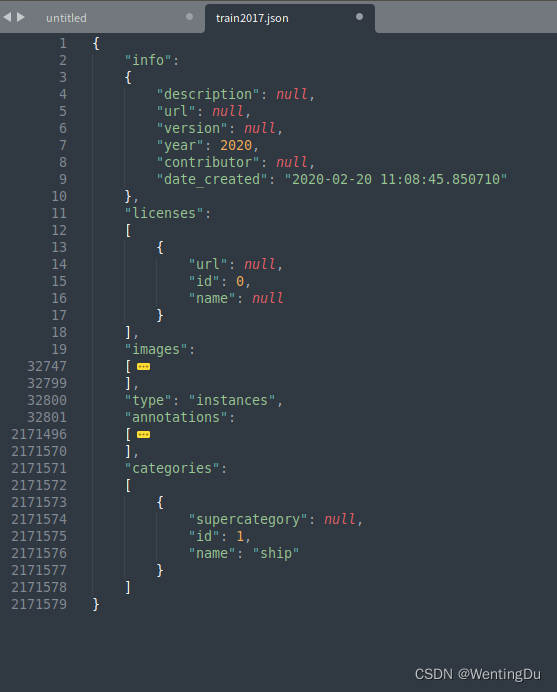
COCO数据集将所有标注信息都集中在一个json格式的文件中,在"images"对应的字典下记录所有图片的信息(包括图片名称、尺寸、标号“id”等)
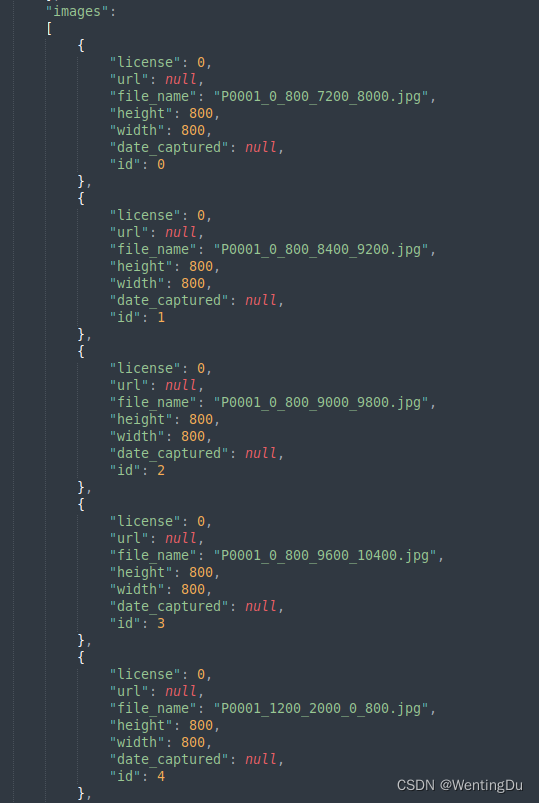
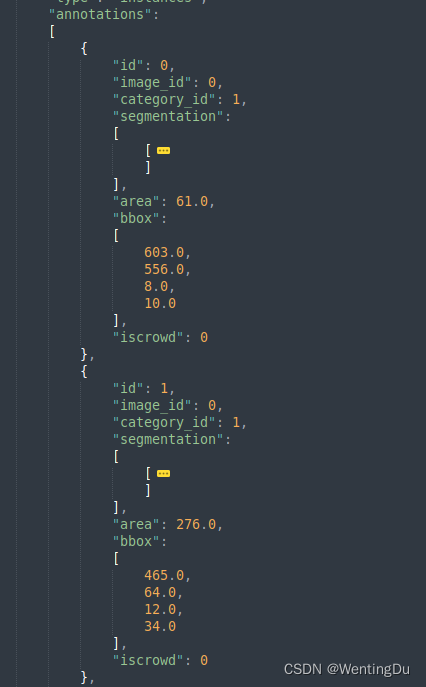
在"annotations"中记录所有的标记目标信息(包括目标的种类标号"category_id"、该目标所在图片的标号“image_id”、该目标的框图坐标信息、该目标的标号“id”)。注意,一张图片中可能有多个目标,所以在“annotations”中,我们经常可以看到许多标记目标它们对应的“image_id”是相同的。
(2)VOC格式简介
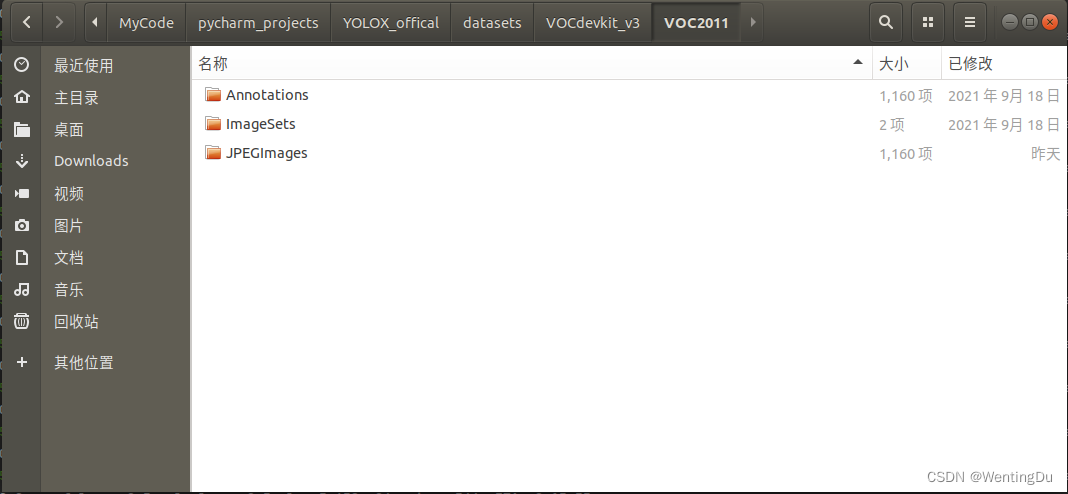
而在VOC格式的数据集中,数据集每个图片都有其对应的xml标注文件,例如SSDD的voc格式的标注中,有1160张图片,同时也有对应的1160个xml标注文件。每个标注文件的名称都与其对应的图片名称相同,两者只是后缀不同,例如000001.jpg对应的标注文件就是000001.xml
xml的标注内容示例如下:

可以发现,xml文件将其所对应的这张图片本身的信息以及该图片所包含的所有目标的信息都记录在一个文件中 ,上面的例子中有多个<object>项,这说明该图片包含有多个目标,每个<object>都对应着一个目标的信息。
我个人比较喜欢VOC的这种标注模式,每个文件都只对应一张图片比较清晰明了,COCO标注虽然在单个json文件中集成大量信息非常简洁,但对初次接触者比较不友好。
另外,需要注意的是coco格式的目标框图坐标格式与voc的目标框图坐标格式的坐标解析方式不同,下面代码中有转换功能,这里不再赘述。
除了图片和其对应的xml文件外,VOC格式的数据集还有专门储存训练集图片名称的train.txt与专门储存测试集图片名称的test.txt这两个txt文件,这里以SSDD数据集的train.txt文件为例,内容展示如下:
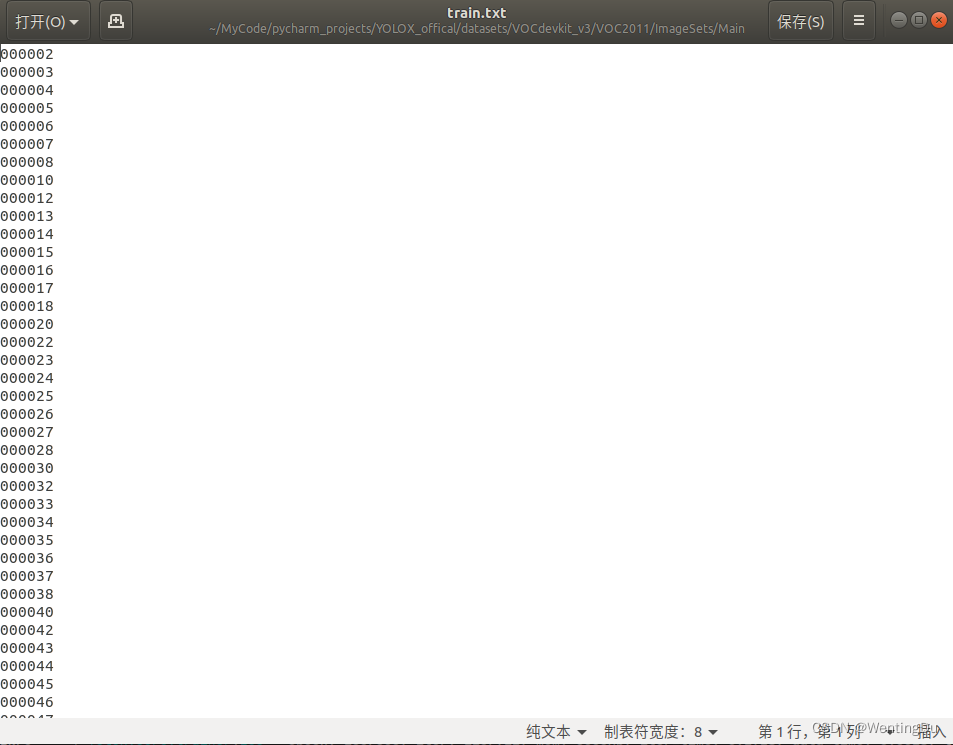
如上图所示,该txt文件每一行的内容就是每张训练集图片的去掉后缀的名称,train.txt与test.txt文件帮助程序区分VOC格式数据集中的数据哪些是训练用、哪些是测试用。相应的,coco格式的数据集也会有train.json与test.json来专门储存训练集和测试集文件信息。
(2)下面是以HRSID数据集为例的COCO格式到VOC格式的转换代码
import xml.dom
import xml.dom.minidom
import os
# from PIL import Image
import cv2
import json
_IMAGE_PATH = r'F:\SAR_Ship\HRSID\JPEGImages'
_INDENT = ' ' * 8
_NEW_LINE = '\n'
_FOLDER_NODE = 'JPEGImages'#_FOLDER_NODE = 'HRSID' #xml格式标注文件中<annotation>项下面的<folder>项记录的内容
_ROOT_NODE = 'annotation'
_DATABASE_NAME = 'Unknown'
_ANNOTATION = 'VOC'
_AUTHOR = 'zc'
_SEGMENTED = '0'
_DIFFICULT = '0'
_TRUNCATED = '0'
_POSE = 'Unspecified'
# _IMAGE_COPY_PATH= 'JPEGImages'
# 封装创建节点的过程
def createElementNode(doc, tag, attr): # 创建一个元素节点
element_node = doc.createElement(tag)
# 创建一个文本节点
text_node = doc.createTextNode(attr)
# 将文本节点作为元素节点的子节点
element_node.appendChild(text_node)
return element_node
def createChildNode(doc, tag, attr, parent_node): #该函数是用来在结点parent_node下面添加内容,tag表示添加内容的键名,attr代表添加内容的值
child_node = createElementNode(doc, tag, attr)
parent_node.appendChild(child_node)
# object节点比较特殊
'''
因为在VOC格式的数据集中,一个图片对应一个xml文件,而一个图片可能包含多个目标,所以每个xml文件中的object项可能有多个,同时coco格式的json文件中又习惯
将图片“images”和目标“annotations”分开记录(在每个目标的标注项目中会有一项“image_id”专门记录该目标所在的图片的编号)。因此在涉及到object项时,需要
将“annotations”中所有对应该图片的目标找出来,并对每个存在于该图片中的目标在根节点<annotation>下写一个object结点
'''
def createObjectNode(doc, attrs):#本函数是专门创建object结点,因为object结点下面有涉及<name>、<pose>、<truncated>、<difficult>、<bndbox>等项,所以本函数专门对object结点及其子结点的添加进行了整合
object_node = doc.createElement('object')
print("创建object中")
midname = "ship" #由于HRSID数据集中所有目标的名字都是“ship”,所以这里统一将object的<name>这一项写入的内容定为"ship"
createChildNode(doc, 'name', midname,
object_node)
createChildNode(doc, 'pose',
_POSE, object_node)
createChildNode(doc, 'truncated',
_TRUNCATED, object_node)
createChildNode(doc, 'difficult',
_DIFFICULT, object_node)
bndbox_node = doc.createElement('bndbox')
# print("midname1[points]:",midname1["points"])
#下面是对取coco标注的bbox格式数据,将其转换成VOC格式再写入xml文件中
createChildNode(doc, 'xmin', str(int(attrs[0])),
bndbox_node)
createChildNode(doc, 'ymin', str(int(attrs[1])),
bndbox_node)
createChildNode(doc, 'xmax', str(int(attrs[2]) + int(attrs[0])),
bndbox_node)
createChildNode(doc, 'ymax', str(int(attrs[3]) + int(attrs[1])),
bndbox_node)
object_node.appendChild(bndbox_node)
return object_node
# 将documentElement写入XML文件
def writeXMLFile(doc, filename):
tmpfile = open('tmp.xml', 'w')
doc.writexml(tmpfile, addindent=' ' * 8, newl='\n', encoding='utf-8')
tmpfile.close()
# # 删除第一行默认添加的标记
fin = open('tmp.xml')
fout = open(filename, 'w')
lines = fin.readlines()
for line in lines[1:]:
if line.split():
fout.writelines(line)
fin.close()
fout.close()
if __name__ == "__main__":
##json文件路径和图片路径,
json_path = r"/home/dwt/DataSets/HRSID/HRSID_JPG/annotations/train_test2017.json"
img_path = r"/home/dwt/DataSets/HRSID/HRSID_JPG/JPEGImages"
Annotations_save_path = r'/home/dwt/DataSets/HRSID/HRSID_JPG_voc格式/Annotations'
fileList = os.listdir(img_path) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
# print(".....::")
# print("fileList:", fileList)
if fileList == 0:
os._exit(-1) #os._exit()会直接将python程序终止,之后的所有代码都不会继续执行。
# 对于每一张图都生成对应的json文件
total_num = len(fileList)
c = 0
for imageName in fileList:
saveName = imageName.strip(".jpg") #Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
print("当前进度:{} / {}".format(c,total_num))
c +=1
print(imageName)
# 得到xml文件的名字
xml_file_name = os.path.join(Annotations_save_path, (saveName + '.xml')) #这里xml_file_name是本次循环操作中的xml文件的保存地址
img = cv2.imread(os.path.join(img_path, imageName))
height, width, channel = img.shape
my_dom = xml.dom.getDOMImplementation() #DomImplementation 对象可执行与文档对象模型的任何实例无关的任何操作。
doc = my_dom.createDocument(None, _ROOT_NODE, None) #createDocument()是上面一行提到的DomImplementation 对象的一个方法,用来创建一个新 Document 对象和指定的根元素。
# 获得根节点
root_node = doc.documentElement #这里的root_node应该是代表xml格式标注文件中<annotation>项 #documentElement 属性可返回文档的根节点。语法:documentObject.documentElement
# folder节点
createChildNode(doc, 'folder', _FOLDER_NODE, root_node)#xml格式标注文件中<annotation>项下面的<folder>项内容
# filename节点
createChildNode(doc, 'filename', saveName + '.jpg', root_node)#xml格式标注文件中<annotation>项下面的<filename>项内容
# path节点--自己仿照VOC格式添加的部分
createChildNode(doc, 'path', 'JPEGImages',root_node) #xml格式标注文件中<annotation>项下面的<path>项内容
#原先SSDD数据集中的VOC格式下的xml标注文件中没有source节点这一项,故我在这里先对添加<source>这一部分代码注释不用
# # source节点
# source_node = doc.createElement('source') #createElement() 方法可创建元素节点。语法:createElement(name) 其中‘name’这个变量代表字符串可为此元素节点规定名称。
# # source的子节点
# createChildNode(doc, 'database', _DATABASE_NAME, source_node)
# # createChildNode(doc, 'annotation', _ANNOTATION, source_node)
# # createChildNode(doc, 'image', 'flickr', source_node)
# root_node.appendChild(source_node)
size_node = doc.createElement('size')
createChildNode(doc, 'width', str(width), size_node)
createChildNode(doc, 'height', str(height), size_node)
createChildNode(doc, 'depth', str(channel), size_node)
root_node.appendChild(size_node) #这里应该是将size这个节点以及这个节点下包含的子结点统统移到<annotation>下面,与<folder>、<filename>、<path>并列
# 创建segmented节点
createChildNode(doc, 'segmented', _SEGMENTED, root_node)
# print("创建object节点")
ann_data = []
# print(json_path1)
with open(json_path, "r") as f:
ann = json.load(f)
# print(ann)
for i in range(5604): # 0 ~ 5603 寻找与jpg_image同名的列表 , 在HRSID的总的coco标注文件train_test2017.json文件中的专门储存图片信息“images”项中有“id”标号从0到5603共5604张图片信息
# 从第一个filename 第一个id开始循环
# i就是图片image_id
filename = ann["images"][i] # 字典 #此时的filename就是一个储存着“images”项中"id"编号为i的字典变量
file_name = filename["file_name"] #将filename中储存其对应图片名称的“键”对应的值(图片名称)提出并付给file_name变量
if imageName == file_name: #找出储存在"images"中的本次循环对应的图片文件的信息进行提取
id = filename["id"]
annotations = ann["annotations"] # len(annotations) = 16951 #"annotations"是HRSID的总的coco标注文件train_test2017.json文件中专门储存所有标注目标信息的部分,每个目标的具体信息都集中储存在一个可以看作是字典的模块中
for j in range(len(annotations)): # 0 - 16951
image_id = annotations[j]["image_id"] #从当前遍历的标注目标信息字典中提取该目标所在图片的id
if image_id == id: # 说明annotations中的该行信息属于该图片
annotations2 = annotations[j] # 将image_id等于id的取出来 #此时变量annotations2相当于储存着当前遍历的标注目标的信息的字典
object_node = createObjectNode(doc, annotations2["bbox"])
root_node.appendChild(object_node)
else:
continue
continue
# 构建XML文件名称
# 写入文件
writeXMLFile(doc, xml_file_name)下面是将json文件中提取信息写成VOC格式数据集中记录训练集与测试集图片名称信息的train.txt与test.txt文件的代码:
import os
import json
json_path = r"/home/dwt/DataSets/HRSID/HRSID_JPG/annotations/train2017.json"
saveBasePath = "/home/dwt/DataSets/HRSID/HRSID_JPG_voc格式/ImageSets/Main"#设定储存记录train或者test的xml名称的txt文件的文件夹路径
f_txt = open(os.path.join(saveBasePath,'train.txt'), 'w')
with open(json_path, "r") as f:
ann = json.load(f)
for i in range(3642): #HRSID数据集测试集对应的coco格式json标注文件共有编号0~1961共1962张图片,训练集对应的coco格式json标注文件共有编号0~3641共3642
filename = ann["images"][i] # 字典 #此时的filename就是一个储存着“images”项中"id"编号为i的字典变量
name = filename["file_name"][:-4]+'\n'
f_txt.write(name)文章出处登录后可见!