图像增强的目的是从现有数据中创建新的训练样本。Albumentations是一个用于图像增强的Python库。图像增强用于深度学习和计算机视觉任务,以提高训练模型的质量。之所以分享这个库的使用,是因为这个库极其强大。Albumentations库支持图像分类、语义分割、实例分割、关键点检测、目标检测,同时还支持这些任务的融合(也就是混合数据,多任务)。比如:支持对目标检测+语义分割的数据进行增强。其支持30多种图像扩充方法,且其响应速度极其快。
安装命令:其要求python版本在3.6及以上
pip install -U albumentationsgithub地址: GitHub – albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries。Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 ![]() https://github.com/albumentations-team/albumentationsapi地址: Albumentations Documentation
https://github.com/albumentations-team/albumentationsapi地址: Albumentations Documentation ![]() https://albumentations.ai/docs/
https://albumentations.ai/docs/
1、性能介绍
1.1 支持的方法
针对于image与不同label所支持的扩充方法如下所示。
| Transform | Image | Masks | BBoxes | Keypoints |
|---|---|---|---|---|
| Affine | ✓ | ✓ | ✓ | ✓ |
| CenterCrop | ✓ | ✓ | ✓ | ✓ |
| CoarseDropout | ✓ | ✓ | ✓ | |
| Crop | ✓ | ✓ | ✓ | ✓ |
| CropAndPad | ✓ | ✓ | ✓ | ✓ |
| CropNonEmptyMaskIfExists | ✓ | ✓ | ✓ | ✓ |
| ElasticTransform | ✓ | ✓ | ||
| Flip | ✓ | ✓ | ✓ | ✓ |
| GridDistortion | ✓ | ✓ | ||
| GridDropout | ✓ | ✓ | ||
| HorizontalFlip | ✓ | ✓ | ✓ | ✓ |
| Lambda | ✓ | ✓ | ✓ | ✓ |
| LongestMaxSize | ✓ | ✓ | ✓ | ✓ |
| MaskDropout | ✓ | ✓ | ||
| NoOp | ✓ | ✓ | ✓ | ✓ |
| OpticalDistortion | ✓ | ✓ | ||
| PadIfNeeded | ✓ | ✓ | ✓ | ✓ |
| Perspective | ✓ | ✓ | ✓ | ✓ |
| PiecewiseAffine | ✓ | ✓ | ✓ | ✓ |
| PixelDropout | ✓ | ✓ | ✓ | ✓ |
| RandomCrop | ✓ | ✓ | ✓ | ✓ |
| RandomCropNearBBox | ✓ | ✓ | ✓ | ✓ |
| RandomGridShuffle | ✓ | ✓ | ✓ | |
| RandomResizedCrop | ✓ | ✓ | ✓ | ✓ |
| RandomRotate90 | ✓ | ✓ | ✓ | ✓ |
| RandomScale | ✓ | ✓ | ✓ | ✓ |
| RandomSizedBBoxSafeCrop | ✓ | ✓ | ✓ | |
| RandomSizedCrop | ✓ | ✓ | ✓ | ✓ |
| Resize | ✓ | ✓ | ✓ | ✓ |
| Rotate | ✓ | ✓ | ✓ | ✓ |
| SafeRotate | ✓ | ✓ | ✓ | ✓ |
| ShiftScaleRotate | ✓ | ✓ | ✓ | ✓ |
| SmallestMaxSize | ✓ | ✓ | ✓ | ✓ |
| Transpose | ✓ | ✓ | ✓ | ✓ |
| VerticalFlip | ✓ | ✓ | ✓ | ✓ |
1.2 性能对比
使用Intel(R)Xeon(R)Gold 6140 CPU在ImageNet验证集中的前2000个图像上运行基准测试的结果。所有输出都用np转换成一个连续的NumPy数组。uint8数据类型。该表显示了每秒可在单个核心上处理多少图像;越高越好。
| albumentations 1.1.0 | imgaug 0.4.0 | torchvision (Pillow-SIMD backend) 0.10.1 | keras 2.6.0 | augmentor 0.2.8 | solt 0.1.9 | |
|---|---|---|---|---|---|---|
| HorizontalFlip | 10220 | 2702 | 2517 | 876 | 2528 | 6798 |
| VerticalFlip | 4438 | 2141 | 2151 | 4381 | 2155 | 3659 |
| Rotate | 389 | 283 | 165 | 28 | 60 | 367 |
| ShiftScaleRotate | 669 | 425 | 146 | 29 | – | – |
| Brightness | 2765 | 1124 | 411 | 229 | 408 | 2335 |
| Contrast | 2767 | 1137 | 349 | – | 346 | 2341 |
| BrightnessContrast | 2746 | 629 | 190 | – | 189 | 1196 |
| ShiftRGB | 2758 | 1093 | – | 360 | – | – |
| ShiftHSV | 598 | 259 | 59 | – | – | 144 |
| Gamma | 2849 | – | 388 | – | – | 933 |
| Grayscale | 5219 | 393 | 723 | – | 1082 | 1309 |
| RandomCrop64 | 163550 | 2562 | 50159 | – | 42842 | 22260 |
| PadToSize512 | 3609 | – | 602 | – | – | 3097 |
| Resize512 | 1049 | 611 | 1066 | – | 1041 | 1017 |
| RandomSizedCrop_64_512 | 3224 | 858 | 1660 | – | 1598 | 2675 |
| Posterize | 2789 | – | – | – | – | – |
| Solarize | 2761 | – | – | – | – | – |
| Equalize | 647 | 385 | – | – | 765 | – |
| Multiply | 2659 | 1129 | – | – | – | – |
| MultiplyElementwise | 111 | 200 | – | – | – | – |
| ColorJitter | 351 | 78 | 57 | – | – | – |
Python and library versions: Python 3.9.5 (default, Jun 23 2021, 15:01:51) [GCC 8.3.0], numpy 1.19.5, pillow-simd 7.0.0.post3, opencv-python 4.5.3.56, scikit-image 0.18.3, scipy 1.7.1.
2、基本使用
基本使用代码如下所示,如果是用于图像分类,则使用 transform(image=img) ;如果是用于语义分割或实例分割,则使用 transformed = transform(image=img,mask=label)
transform的设置
import albumentations as A
from skimage import io
img_path="image.jpg"
label_path="label.png"
img=io.imread(img_path)
label=io.imread(label_path)
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
transformed = transform(image=img,mask=label)
img_new=transformed['image']
label_new=transformed['mask']2.1 多label语义分割
有的时候语义分割任务有多个mask
将多个mask组装为list
import cv2
mask_1 = cv2.imread("/path/to/mask_1.png")
mask_2 = cv2.imread("/path/to/mask_2.png")
mask_3 = cv2.imread("/path/to/mask_3.png")
masks = [mask_1, mask_2, mask_3]应用扩展
transformed = transform(image=image, masks=masks)
transformed_image = transformed['image']
transformed_masks = transformed['masks']2.2 目标检测增强
边界框注释有多种格式,目标检测增强需要考虑数据的格式。每种格式都使用其特定的边界框坐标表示。Albumentations支持四种格式:pascal_voc、Albumentations、coco和yolo。4种格式分别如下所示:
pascal_voc: [x_min, y_min, x_max, y_max]
albumentations: [x_min, y_min, x_max, y_max]
coco: [x_min, y_min, width, height]
yolo: [x_center, y_center, width, height] 图1 四种格式的示例
图1 四种格式的示例
除了上述的4种格式外,Albumentations还支持在box中添加n个类别信息。或者 transformed = transform(image=image, bboxes=bboxes, class_labels=class_labels)
bboxes = [
[23, 74, 295, 388, 'dog', 'animal'],
[377, 294, 252, 161, 'cat', 'animal'],
[333, 421, 49, 49, 'sports ball', 'item'],
]transform的设置
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco', min_area=1024, min_visibility=0.1, label_fields=['class_labels']))应用扩展
transformed = transform(image=image, bboxes=bboxes)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']此外还支持class_labels的设置,详情可以参考以下链接的底部。 Bounding boxes augmentation for object detection – Albumentations Documentation Albumentations: fast and flexible image augmentations ![]() https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/
https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/
2.3 关键点增强
一些经典的计算机视觉算法,如SIFT,可能会使用四个值来描述一个关键点。除了x和y坐标,还有关键点比例和关键点角度,Albumentations 也支持这些格式。
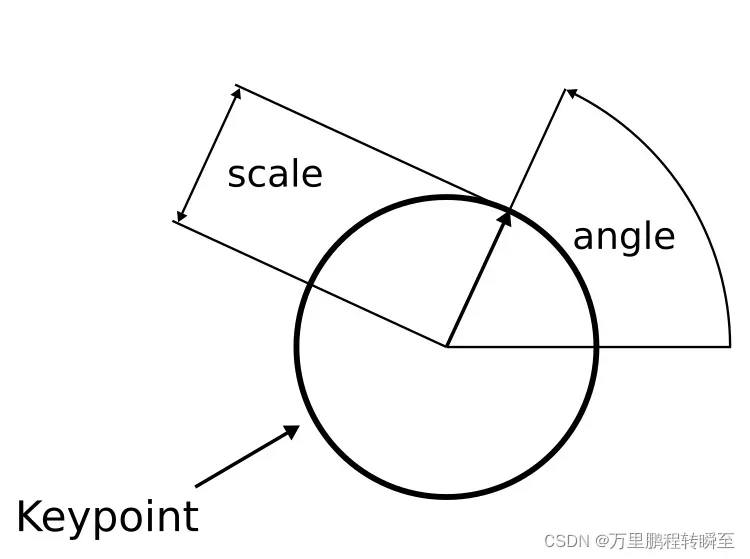 图2 keypoint数据示意
图2 keypoint数据示意
具体支持的格式有以下6种:
xy: 关键点由像素的x和y坐标定义
yx: 关键点由以像素为单位的y和x坐标定义
xya: 关键点由像素的x和y坐标以及角度定义
xys: 关键点由以像素为单位的x和y坐标以及比例定义
xyas: 关键点由像素的x和y坐标、角度和比例定义
xysa: 关键点由像素的x和y坐标、比例和角度定义
transform的设置
transform = A.Compose([
A.RandomCrop(width=330, height=330),
A.RandomBrightnessContrast(p=0.2),
], keypoint_params=A.KeypointParams(format='xy', remove_invisible=True, angle_in_degrees=True))应用扩展
transformed = transform(image=image, keypoints=keypoints)
transformed_image = transformed['image']
transformed_keypoints = transformed['keypoints']2.4 多任务数据
多任务是指图像分类、目标检测、关键点检测等任务的融合。
transform的设置
transform = A.Compose(
[A.RandomCrop(width=330, height=330), A.RandomBrightnessContrast(p=0.2)],
bbox_params=A.BboxParams(format="coco", label_fields=["bbox_classes"]),
keypoint_params=A.KeypointParams(format="xy", label_fields=["keypoints_classes"]),
)应用扩展
transformed = transform(
image=img,
mask=mask,
bboxes=bboxes,
bbox_classes=bbox_classes,
keypoints=keypoints,
keypoints_classes=keypoints_classes,
)
transformed_image = transformed["image"]
transformed_mask = transformed["mask"]
transformed_bboxes = transformed["bboxes"]
transformed_bbox_classes = transformed["bbox_classes"]
transformed_keypoints = transformed["keypoints"]
transformed_keypoints_classes = transformed["keypoints_classes"]3、多图同步扩充
传入transform的数据可以是任意通道的,如WHC,C>1即可,数据格式可以是uint8,int32,float。应而,基于此可以实现对多图数据,保持相同的扩充操作。这里以语义分割为例,可以自行修改为目标检测的
import albumentations as A
class Augmentation:
def __init__(self, image_size):
self.transform = A.Compose([
A.RandomSizedCrop(min_max_height=[384,512], height=image_size[0], width=image_size[1], w2h_ratio=1.0, interpolation=1, always_apply=False, p=1.0),
A.VerticalFlip(p=0.5),
A.HorizontalFlip(p=0.5),
A.Rotate(limit=90, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=0.5),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45, interpolation=1, border_mode=4, value=255, mask_value=0, shift_limit_x=0.2, shift_limit_y=0.2, always_apply=False, p=0.1),
A.RandomGamma(gamma_limit=(80, 120), eps=None, always_apply=False, p=0.8),
A.RandomGridShuffle(grid=(3, 3), always_apply=False, p=0.2),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, always_apply=False, p=0.5),
A.Perspective(scale=(0.05, 0.1), keep_size=True, pad_mode=0, pad_val=0, mask_pad_val=0, fit_output=False, interpolation=1, always_apply=False, p=0.1),
A.PiecewiseAffine(scale=(0.05, 0.05), nb_rows=4, nb_cols=4, interpolation=1, mask_interpolation=0, cval=0, cval_mask=0, mode='constant', absolute_scale=False, always_apply=False, keypoints_threshold=0.01, p=0.1),
A.OpticalDistortion(distort_limit=0.5, shift_limit=0.5, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=0.1),
A.ElasticTransform(alpha=2, sigma=80, alpha_affine=60, interpolation=1, border_mode=4, value=0, mask_value=0, always_apply=False, approximate=False, same_dxdy=False, p=0.1),
A.GridDistortion(num_steps=5, distort_limit=0.5, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=0.1),
A.CoarseDropout(max_holes=8, max_height=128, max_width=128, min_holes=None, min_height=64, min_width=64, fill_value=0, mask_fill_value=0, always_apply=False, p=0.1),
])
def aug(self, img, mask=None):
transformed = self.transform(image=img, mask=mask)
if mask is None:
return transformed['image']
else:
return transformed['image'],transformed['mask']
#可以对list中的数据进行相同的aug操作
def aug_list(self, imglist, maskList=None):
lens=len(imglist)
imglist=list2np(imglist)
maskList=list2np(maskList)
transformed = self.transform(image=imglist, mask=maskList)
if maskList is None:
return np2list(transformed['image'],lens)
else:
return np2list(transformed['image'],lens),np2list(transformed['mask'],lens)
def list2np(self,list):
if list is None:
return None
#单通道数据
if len(list[0].shape)==2:
result=np.stack(list,axis=-1)
else:
result=np.concatenate(imglist,axis=-1)
return result
def np2list(self,np_arr,lens,dims=-1):
result=[]
#单通道数据
if lens==np_arr.shape[dims]:
for i in range(lens):
result.append(np_arr[:,:,i])
else:
for i in range(0,lens*3,3):
result.append(np_arr[:,:,i:i+3])
return result
文章出处登录后可见!