Transformer是最近比较火的深度学习模型,它抛弃了传统的CNN和RNN,提出了一种全新的模型架构。借助于新的模型和大规模数据训练,transformer刷新了NLP和CV许多领域的指标,成为这些领域新的SOTA,大有要统一NLP和CV模型的趋势。当然,transformer本身也有许多解释性问题和缺点在被广泛研究改进,但不得不承认这是目前受到关注最多的模型之一了。基于最近看到的一些论文,本文对Transformer的主要观点和在视觉领域,特别是low-level视觉领域的发展做一个简单的总结。
Transfomer的发展简述
Attention is All Your Need
17年这篇发表在NeurlPS上的文章,正式提出了transformer。Transformer的结构如下图所示,其包含了编码器和解码器部分,编码器和解码器都是由多个transformer block堆叠组成。而每个block由一个self-Attention模块和一个Feed Forward Neural Network组成。关于transformer的详细介绍可以参考李沐老师的讲解。Transformer被提出主要用于机器翻译,它使用self-attention代替了RNN(以及LSTM等)的时序结构,使得模型能在捕捉全局上下文信息的同时更好地被并行训练。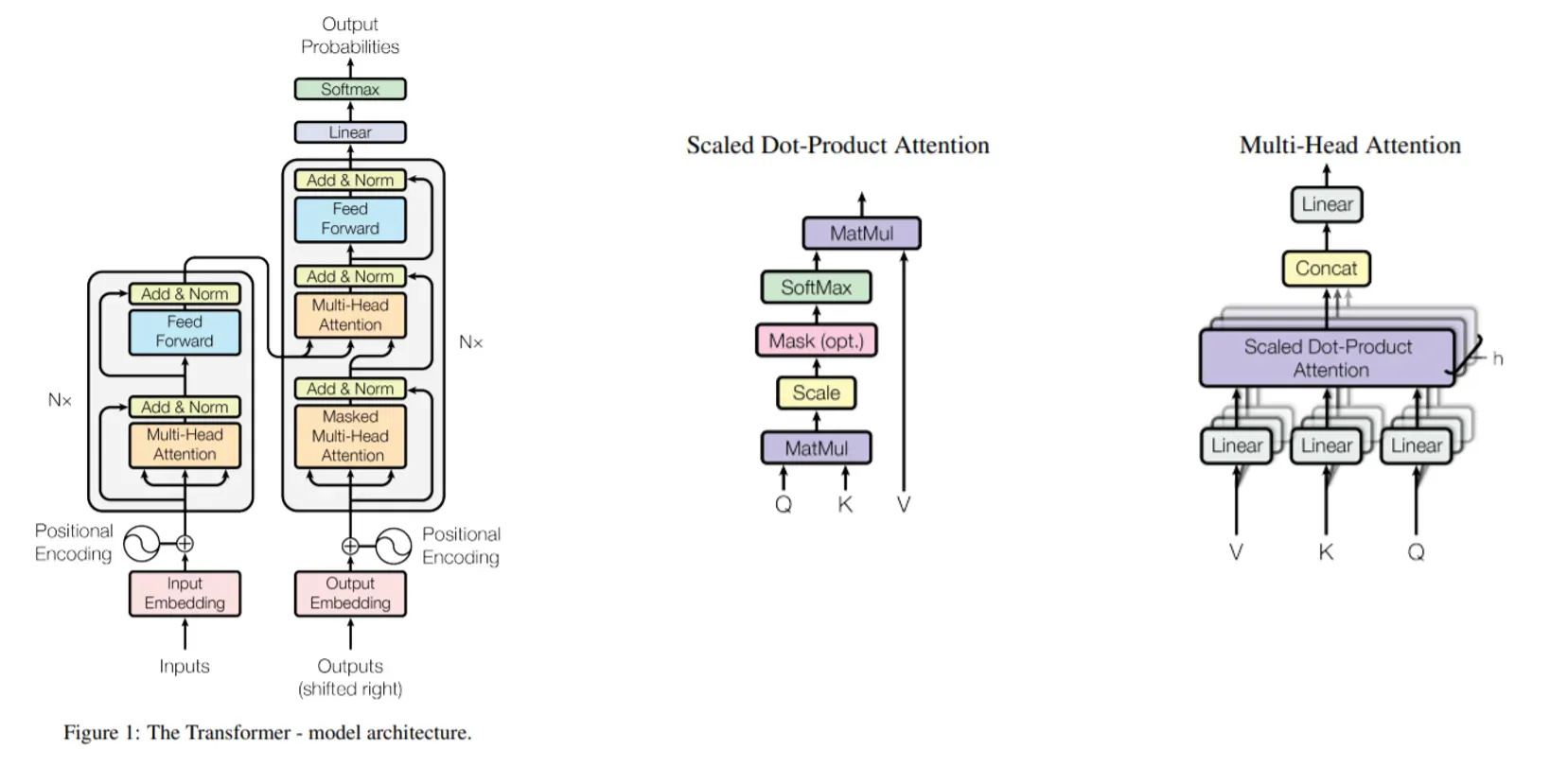
Vision Transformer
2021的ViT(Vision Transformer)第一次将Transformer引入到视觉领域。为了说明transfomer的有效性,其几乎完整地照搬了transformer的结构和训练方法等。文章说明了仅仅是照搬transformer模型,便可以达到与当前SOTA的CNN模型(如ResNet)相媲美的效果(主要是在图像分类任务上做的对比)。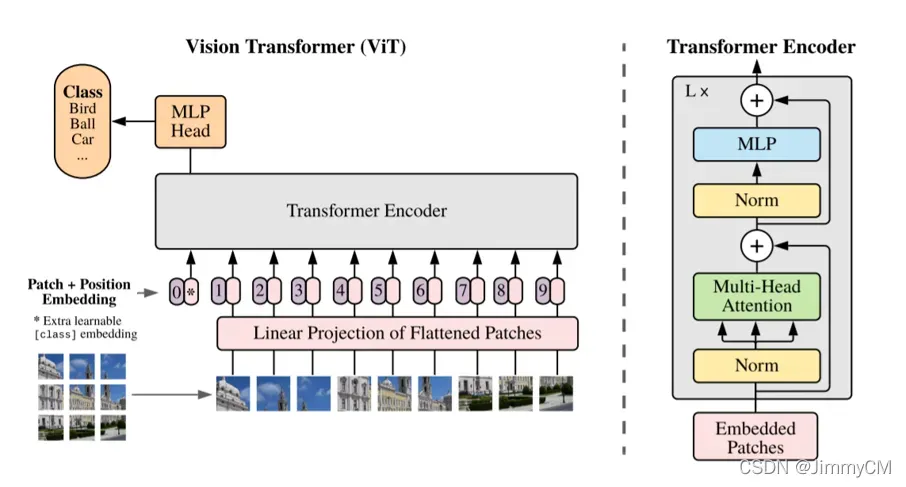
而且文章做了充分的对比实验,得到了许多有意义的结论。如下图所示,实验结果表示transformer和ResNet同在较小的训练集上预训练,transformer的结果不如ResNet好,而当预训练数据集变大时,transformer的优势开始体现。对于此,文章的解释是,CNN本身是有归纳偏置的,比如CNN的平移不变、权重共享、局部感受野等结构都是基于对图像的一些自然先验知识设计的,而transformer本身是缺乏这些先验知识的,因而在小数据集上,借助于这些先验设计的CNN会更有优势,而随着数据量增多,transformer的结构优势才体现出来。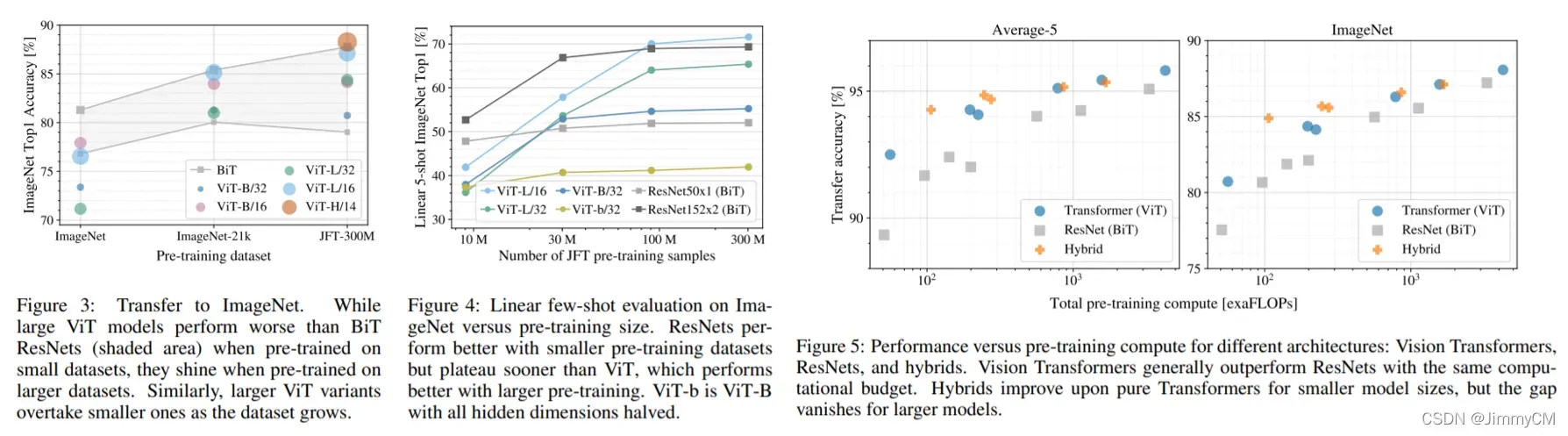
另一个实验结果可以看出,CNN的感受野是随着网络深度逐步增加的,而transformer借助于attention结构在浅层网络便可以获取全局的感受野,这也有助于模型更好地对高层语义信息进行提取。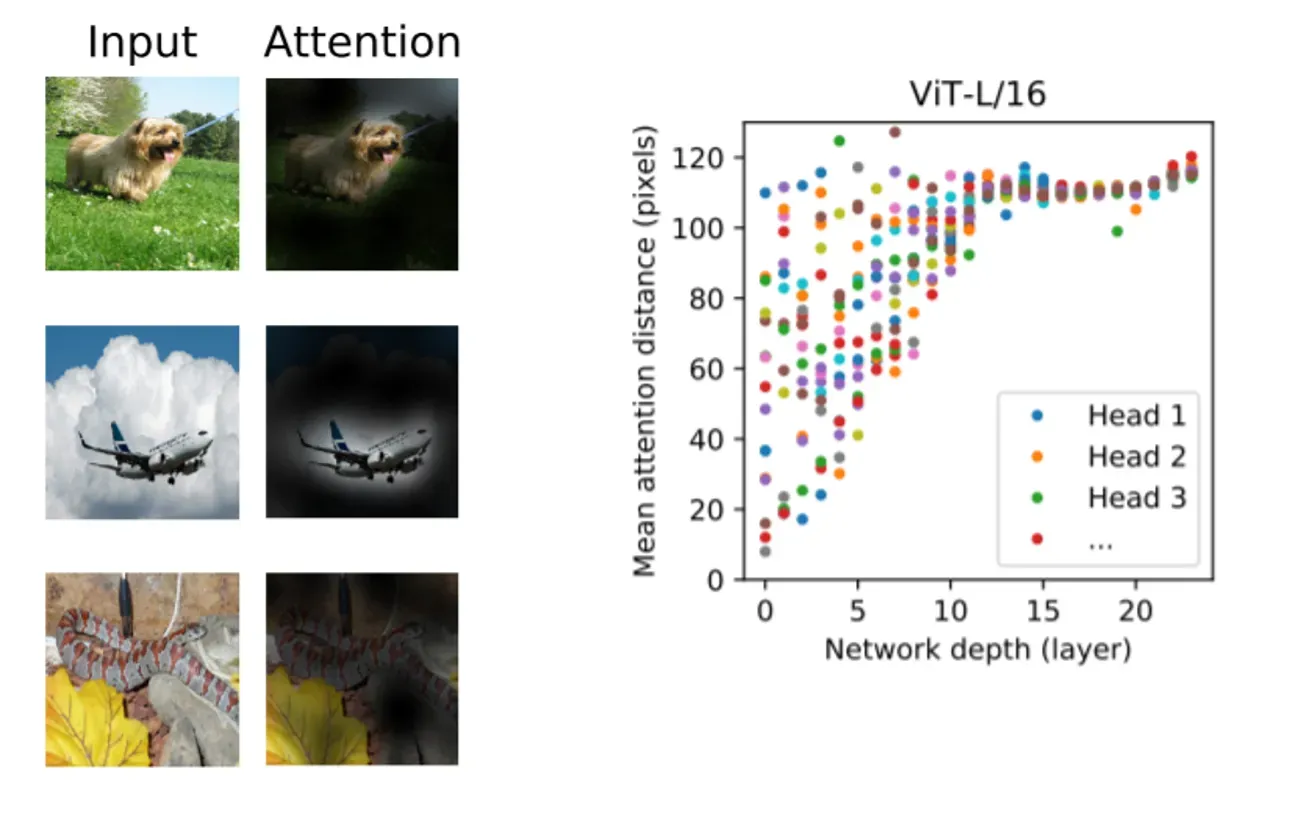
ViT是transformer在视觉领域的开山之作,但其并没有根据图像和视觉任务本身的特性对模型结构做优化,而且Self-attention的计算量和内存消耗确实比较大。另外,transformer能在NLP中大放异彩的另一个原因是大规模的自监督训练。简单理解就是通过完形填空的方式使得模型可以利用无标注数据进行预训练。而ViT在文章中提到虽然其也利用图像数据做了自监督训练,但效果远不如监督预训练来的效果好。
对此,有两篇文章对这些问题做了进一步探索。一篇是ICCV2021的best paper Swin Transformer,其通过层级结构改善了self-attetion计算量大的问题。一篇是最近比较火热的MAE,其探索了ViT自监督训练不佳的问题,提出了一种视觉领域的自监督训练方法。
Swin Transformer
Swin Transformer中的主要改进如下图所示。其设计了类似金字塔的层级结构,在低层级上获取局部感受野,然后随着层级堆叠而逐步扩大感受野。通过这种方式将self-attention的计算从全图减小到固定大小的块内,大大减小了计算复杂度。另一方面,为了保证块与块之间的信息交流,设计了滑动窗口的方法。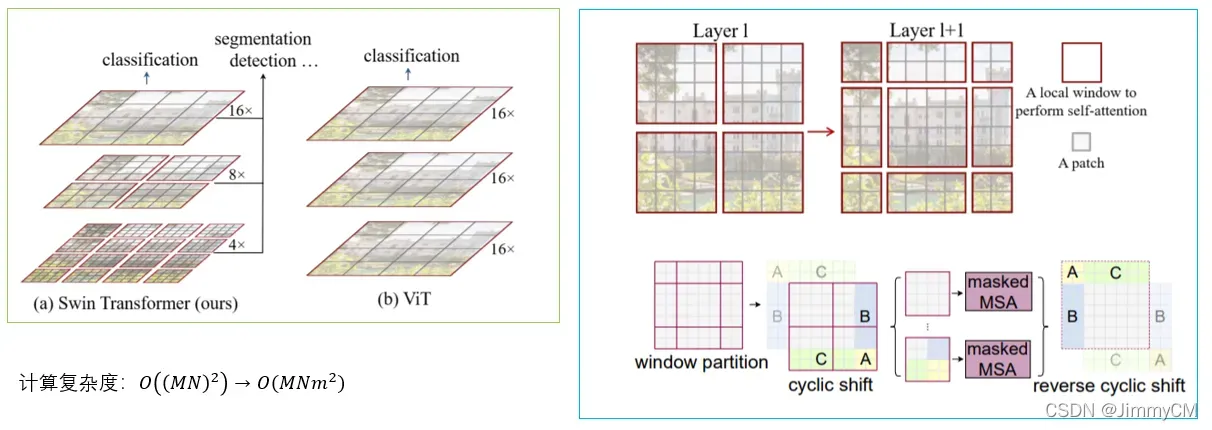
Swin transformer的整体结构如下图所示。可以看到其与CNN的结构相似,在每个stage中获取计算局部块的attention以及块与块之间的attention,然后通过层级堆叠方式扩大感受野范围。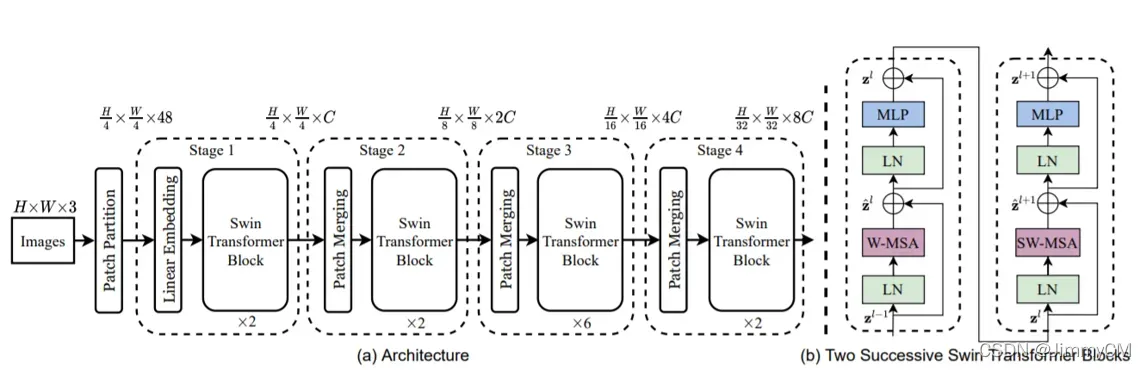
MAE
MAE(masked autoencoders)是kaiming大神最近才放出来的文章,用于解决视觉任务的自监督训练问题。其主要思想很简单:相比自然语言,图像有更多的冗余信息,需要去掉更大比例的内容才能使得模型学习到全局信息。而也因为去掉了很大比例的内容,所以只有通过transoformer这种包含attention结构能提出全局信息的模型才能有效地学习(CNN则很难)。
MAE的结构和效果如下图所示。结构包含了一个编码器和解码器。编码器只输入保留的内容,而解码器则将去掉的内容用mask填充一起作为输入。这种非对称结构使得网络可以用更少的数据量和更小的解码器结构实现更快的训练。而其结果当然也是惊艳到令人惊异。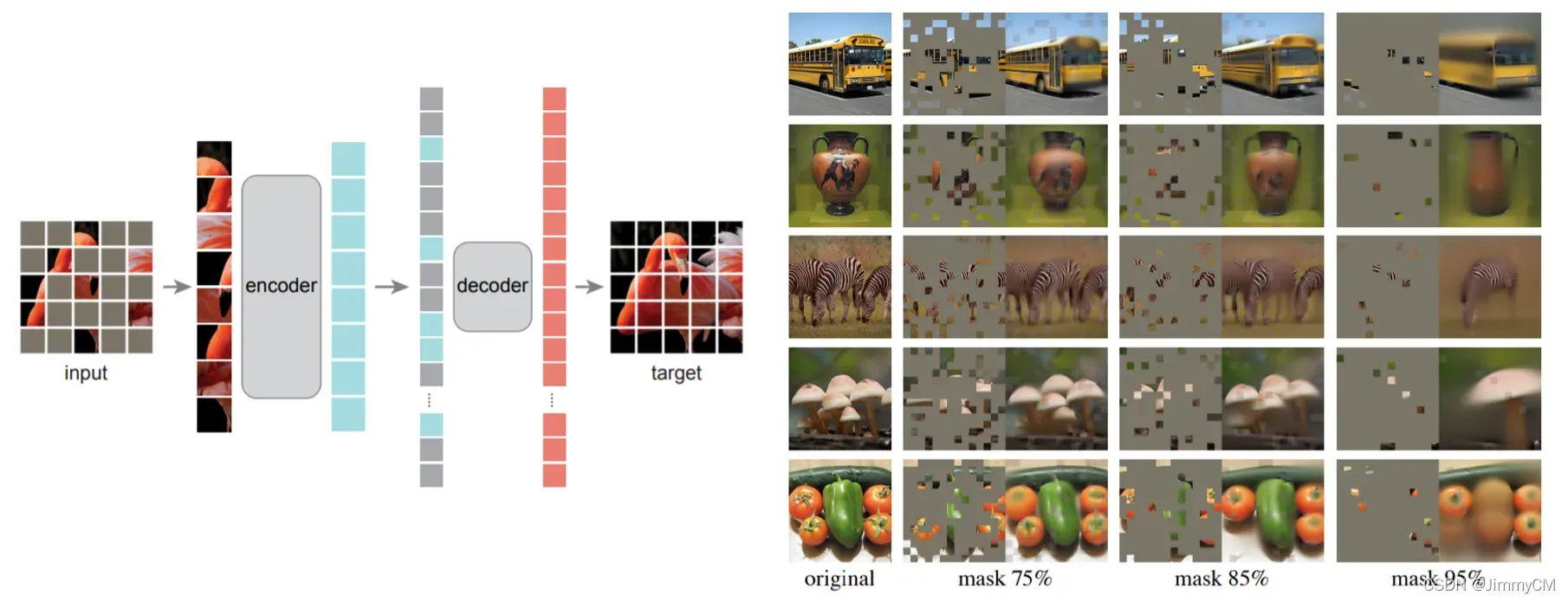
当然,文章也做了充分的对比和消融实验。文章说明了在masking图像内容比例达到75%时能达到好的结果,以及使用预训练之后,使用全部参数finetune比只fintune最后的分类层效果要好得多。另外比较有意思的一点是,仅仅通过对ViT训练调参,作者就能取得比ViT原文更好的结果。不得不说,其实很多时候训练技巧和数据才是影响模型效果的最大因素。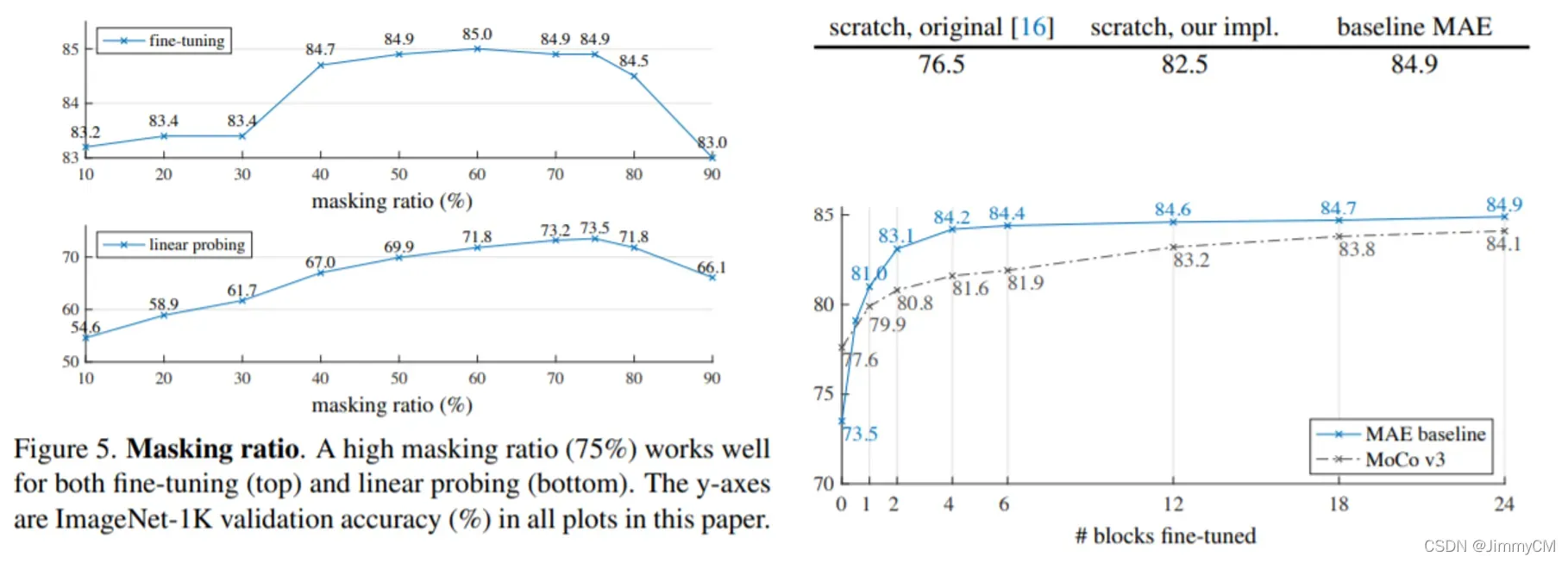
MetaFormer
还有一篇有意思的文章值得说一下。在MetaFormer中,作者提出相比较于self-attention,transformer的整体结构才是更重要的。其通过将替换transformer中的self-attention替换为其他更简单的操作,甚至变为直接连接的方式,发现性能并没有出现很大的变化。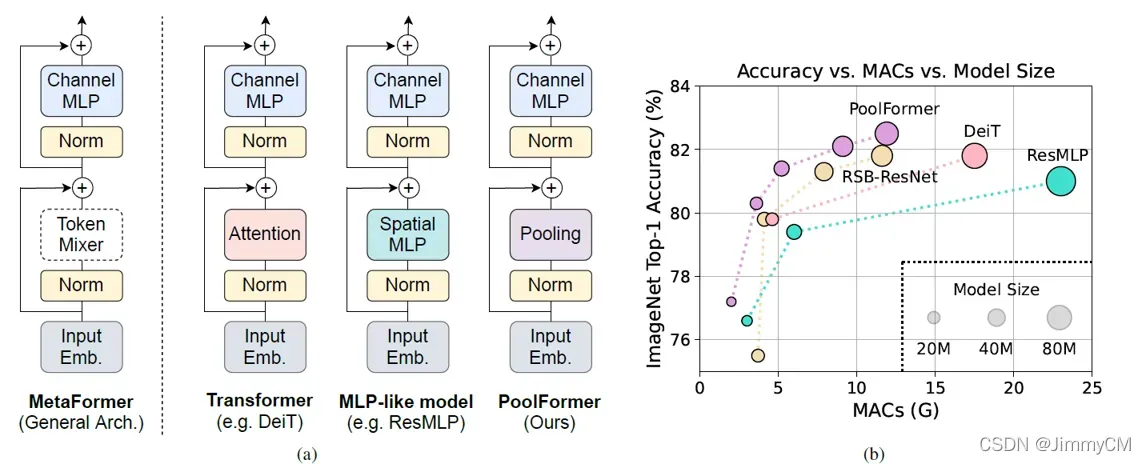
所以transfomer中还有许多设计和可解释问题等待着探索。
Transformer在low-level vision中的应用
既然transformer在高层视觉中已经得到广泛应用,那么自然会被引入到图像处理任务中。目前可以看到有几篇文章:
- IPT(2020.12)
- Uformer(2021.06)
- SwinIR(2021.08)
- Restormer(2021.11)
这些文章使用相同的模型结构来比较多个图像处理任务。
IPT
IPT是CVPR2021的文章,是transformer在图像处理任务中的首次应用。其通过在imageNet上预训练模型,然后再根据不同的图像处理任务,更换不同的头部和尾部(CNN组成),再在相应的任务数据集上做finetune。IPT刷新了多项图像处理任务的SOTA指标。
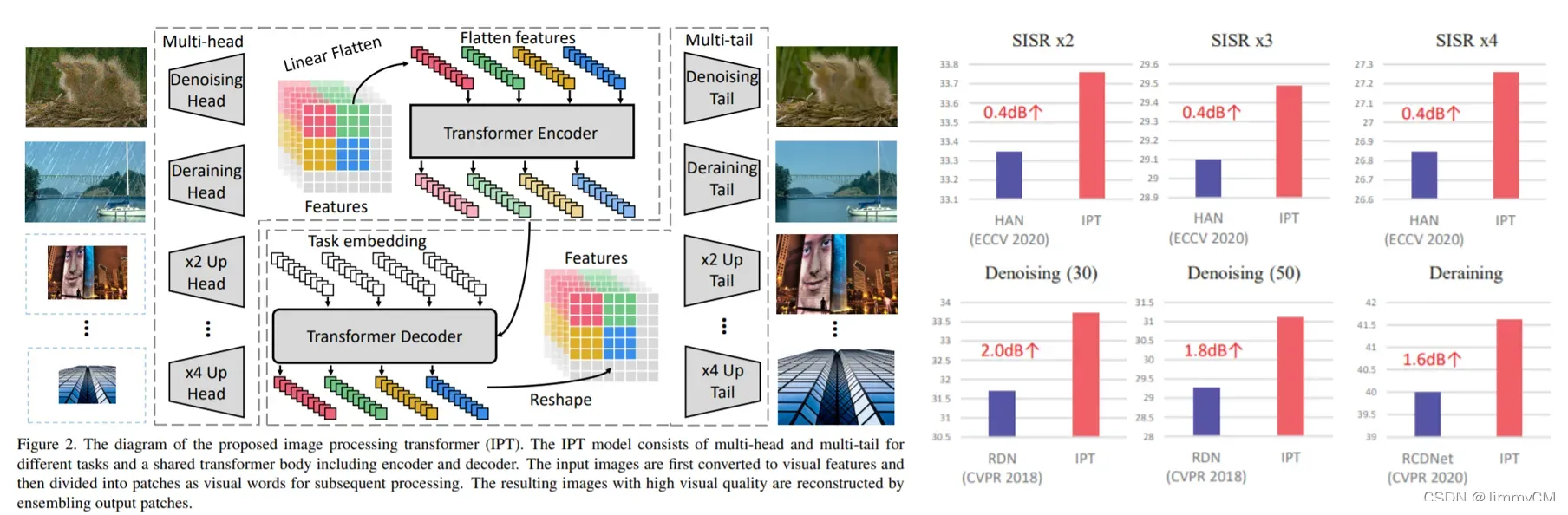
Uformer
Uformer则是将transfomer block与UNET结构结合起来。同时将transfomer block中的机构做了优化。一方面,将原来的feed forword network由简单的MLP改为了深度可分离卷积以更好的提取上下文信息。另一方面,self-attention也由全局改为局部窗口,节省计算开销,通过UNET多尺度结构获取更大的感受野。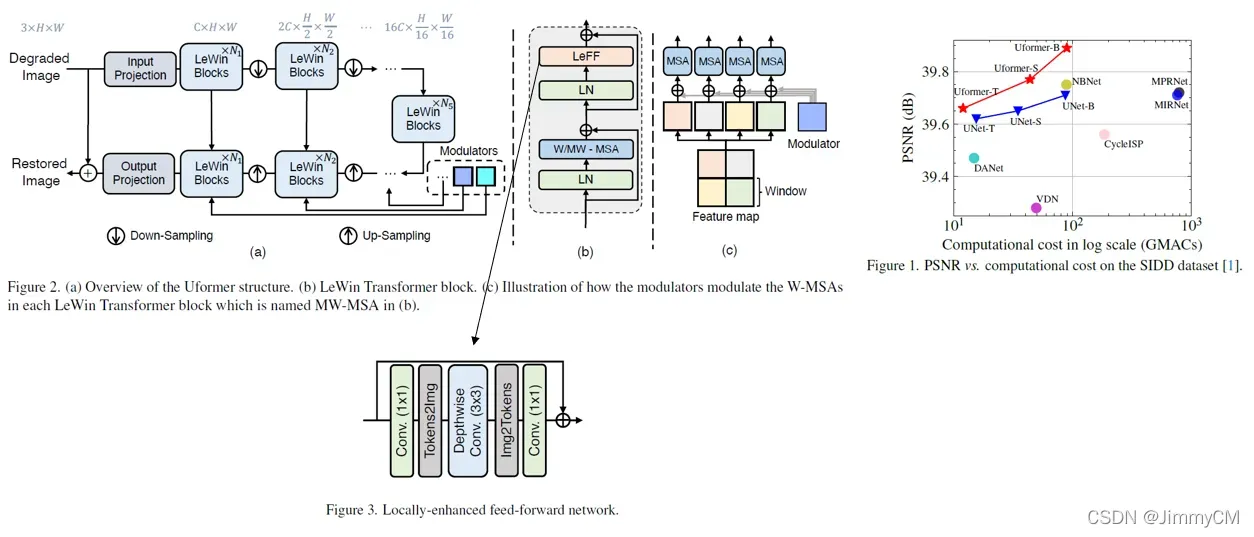
SwinIR
SwinIR则是将swin transfomer应用于图像处理任务。在多项任务,特别是图像超分辨任务上取得了当前SOTA的水平。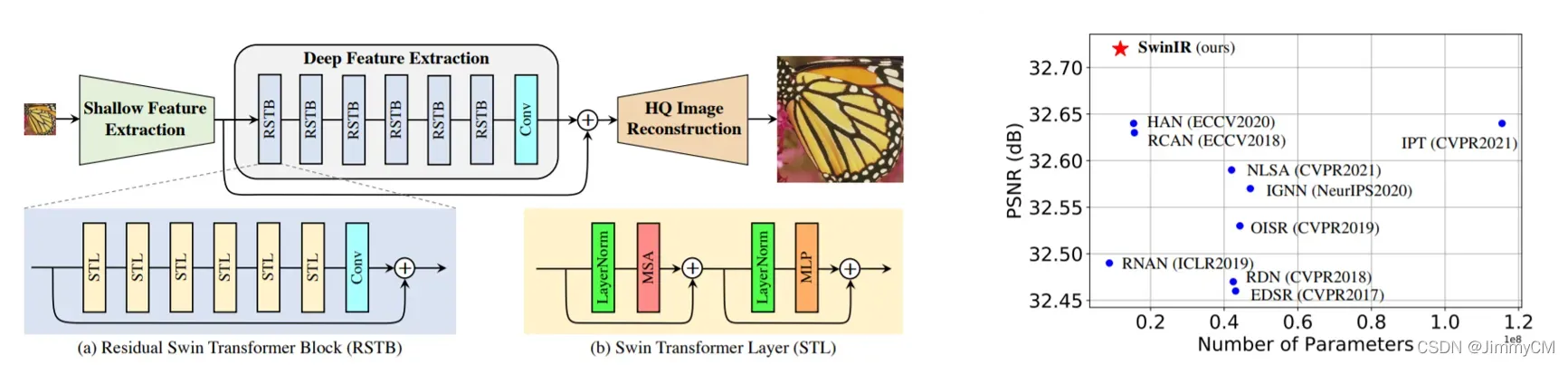
Restormer
Restormer也是将transfomer block与UNET结构相结合。不过其对于transfomer block的优化与Uformer不同。一方面,Restormer也将feed forword network替换为深度可分离卷积,并加入了通道注意力机制(文章称为Gated-Dconv feed-forward network, GDFN);另一方面,Restormer将原来的空间self-attention改为了通道self-attention,减少了计算复杂度。同时,文章还提出了一种渐进式学习的训练方法,即开始时使用小patch size、大batch size的数据训练,随着训练进行,逐渐增大patch size、并减小batch size,在不增加训练数据量的同时优化训练效果。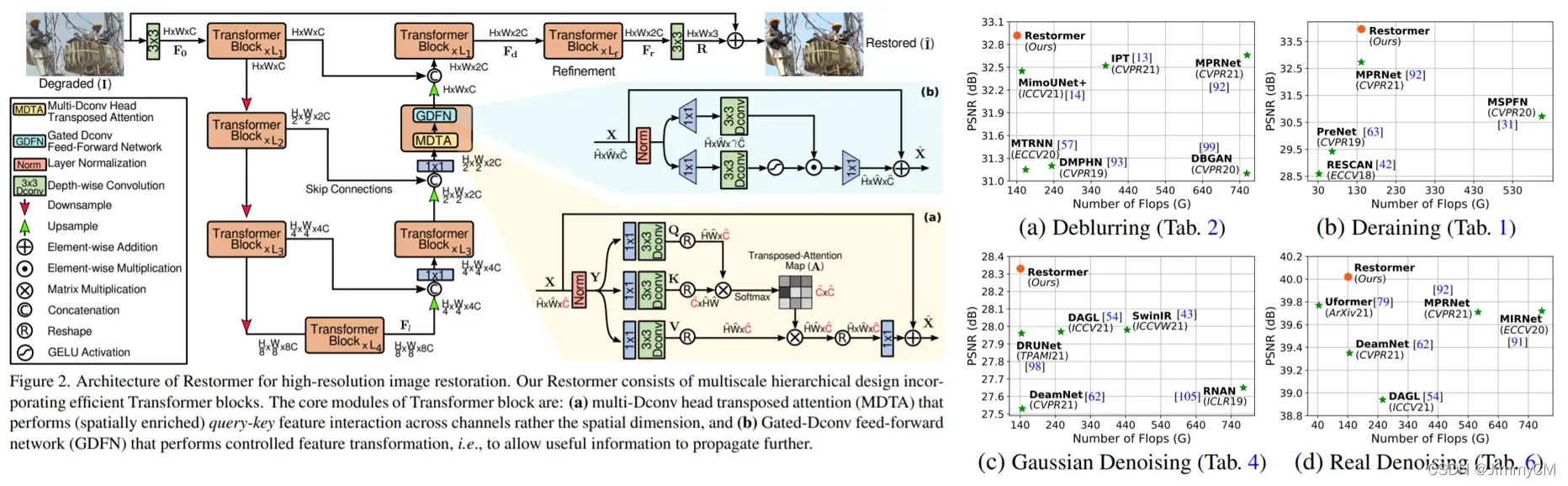
总结
通过简单地梳理现有low-level vision的transfomer相关的文章可以看到有以下的趋势:
- Transfomer与CNN相结合,增加模型的归纳偏置
- 降低self-attention的计算开销
- 增加局部上下文信息的获取
未来可能不论transfomer还是CNN都是相互借鉴,向着统一的模型发展。
参考
- Transformer: Attention is All Your Need. Ashish Vaswani et al. Google Brain. [paper]
- ViT: An Image is Worth 16X16 Words:
Transformers for Image Recognition at Scale. Alexey Dosovitskiy et al. Google Brain. [github] - Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows. Ze Liu et al. MSRA. [github]
- MAE: Masked Autoencoders Are Scalable Vision Learners. kaiming He et al. FAIR. [paper]
- MetaFomer: MetaFormer is Actually What You Need for Vision. Weihao Yu. Sea Ai Lab. [paper]
- IPT: Pre-Trained Image Processing Transformer. Hanting Chen et al. Peking University. [github]
- Uformer: A General U-Shaped Transformer for Image Restoration. Zhendong Wang et al. University of Science and Technology of China. [github]
- SwinIR: Image Restoration Using Swin Transformer. Jingyun Liang et al. ETH. [github]
- Restormer: Efficient Transformer for High-Resolution Image Restoration. Syed Waqas Zamir et al. Inception Institute of AI. [github]
文章出处登录后可见!