目 录
1 ResNet网络介绍
1.1 ResNet网络的亮点
1.2 梯度消失、梯度爆炸和退化问题
1.3 残差(residual)模块
1.3.1 残差模块介绍
1.3.2 特殊的残差模块
1.4 Batch Normalization
1.4.1 BN处理原理
1.4.2 BN处理使用时需要注意的问题
1.5 迁移学习
1.5.1 使用迁移学习的优势
1.5.2 迁移学习原理简介
1.5.3 迁移学习方式
2 网络结构
3 利用Pytorch实现ResNet网络
3.1 模型定义
3.1.1 ResNet-18、34所用残差结构
3.1.2 ResNet-50、101、152所用残差结构
3.1.3 定义网络结构
3.2 训练过程
3.3 预测过程
3.3.1 单图片预测
3.3.2 多图片预测
1 ResNet网络介绍
1.1 ResNet网络的亮点
①突破1000层的超深的网络结构;
②提出残差(residual)模块;
③使用Batch Normalization加速训练,不需要使用dropout方法了。
1.2 梯度消失、梯度爆炸和退化问题
网络结构并不是越深越好,原因如下:
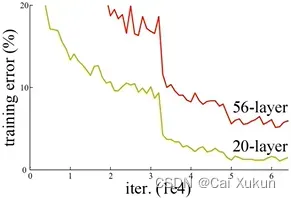
①首先是梯度消失和梯度爆炸问题:假设每一层的误差梯度是小于1的数,那在反向传播中,每向前传播一次都要乘以一个小于1的误差梯度,当网络越来越深乘以小于1的数就越多就越接近于0,这样梯度就会越来越小,这就是梯度消失现象,梯度爆炸现象同理;解决该问题通常是对数据进行标准化、权重初始化等处理。
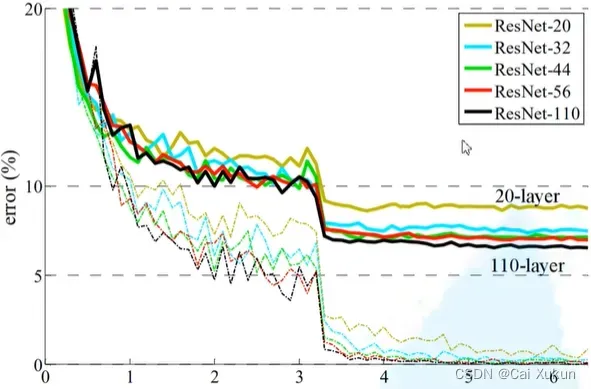
②其次是退化问题:提出了残差结构,如上图所示,ResNet网络能够实现层数越深,效果越好。
1.3 残差(residual)模块
1.3.1 残差模块介绍
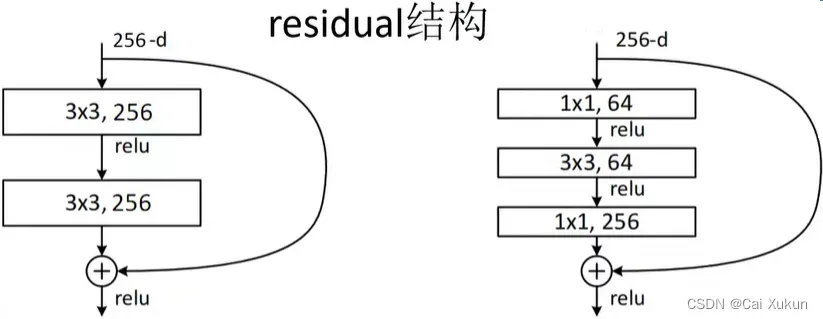
左图是针对网络层数较少的网络结构所使用的残差结构(原论文中用在了ResNet-18、32),右图是针对网络网络层数较多的网络结构所使用的残差结构(原论文中用在了ResNet-50、101、152)。
左图是将输入矩阵经过两个3×3的卷积层得到的输出与原输入矩阵相加(注意是对应维度相加,而不是在深度方向进行拼接),因此需要保证输出与原输入矩阵的shape(H、W、channel)相同,再经过ReLU激活函数得到输出矩阵;右面不同点是加入了两个1×1的卷积层进行降维和升维,这样的好处在:
左面所需参数:3×3×256×256+3×3×256×256=1179648
右面所需参数:1×1×256×64+3×3×64×64+1×1×64×256=69632
会大大减少参数数量。
1.3.2 特殊的残差模块
虚线残差结构出现在以下几个位置:
①所有层数ResNet网络的conv3_x、conv4_x和conv5_x的第一层中(比如ResNet-50的conv3_x需要4个残差结构,只有第一个残差结构需要用虚线结构),主要是为了改变输入的H、W、channel;
②ResNet-50、101、152深层网络的conv2_x的第一层中,只是为了改变输入的channel。
下图为用在ResNet-18、34的虚线残差结构:
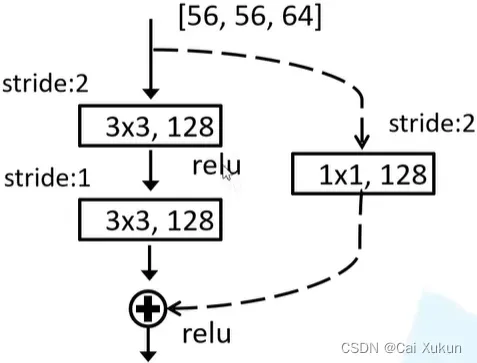
该结构的输出为[28, 28, 128],因此第一层的步长为2,计算如下(主分支padding=1):
(56-3+2)/2+1=28(当计算不被整除时,卷积向下取整,池化向上取整)
将长和宽变为28,再经过一层步长为1的卷积层:
(28-3+2)/1+1=28
得到的输出为[28, 28, 128],输入经过侧分支(padding=0):
(56-1)/2+1=28(当计算不被整除时,卷积向下取整,池化向上取整)
下图为用在ResNet-50、101、152的虚线残差结构(conv2_x的主副分支步长为1,因为前面有最大池化下采样层做了H和W减半的工作):
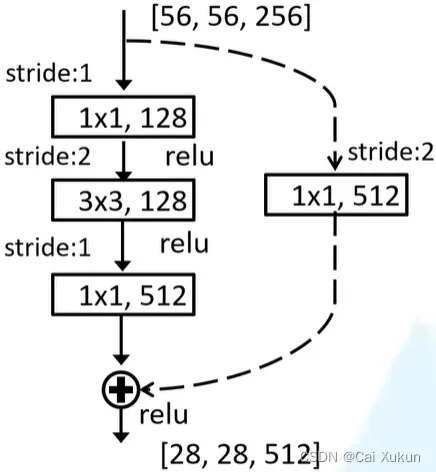
作者一共比较了A、B、C三个结构,最终上图B结构的效果最好。在原论文中残差结构的主分支上第一个1×1卷积层的步长是2,第二个3×3卷积层步长是1;但在pytorch官方实现过程中是第一个1×1卷积层的步长是1,第二个3×3卷积层步长是2,这样能够在ImageNet的top1上提升大概0.5%的准确率。
1.4 Batch Normalization
1.4.1 BN处理原理
该标准化处理的目的是使我们一个batch的每一个channel对应的维度满足均值为0、方差为1的分布规律,具体原理如下例子所示:
假设batch size为2(即输入两张图片),每张图片H和W为2,channel为2:
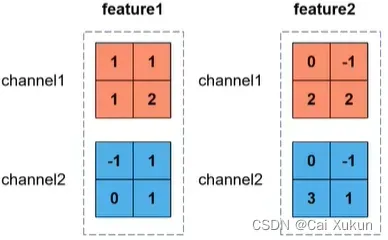
 ,
,
channel1的均值:

同理channel2的均值为0.5;channel1的方差为:

同理channel2的方差为1.5,因此可以得出:
![mu =left [ 1; ; 0.5 right ]^{T}](https://aitechtogether.com/wp-content/uploads/2023/04/gif-556.gif) ,
,![sigma ^{2}=left [ 1; ; 1.5 right ]^{T}](https://aitechtogether.com/wp-content/uploads/2023/04/gif-557.gif)
 和
和 都是在正向传播过程中得到的,再根据公式(
都是在正向传播过程中得到的,再根据公式( 是一个很小的数,作用是为了防止分母为0):
是一个很小的数,作用是为了防止分母为0):

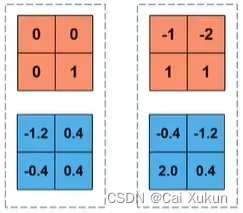
最后一步还需要进行: ,其中
,其中 初始值为1、
初始值为1、 初始值为0,并且这两个参数是在反向传播过程中训练得到的,因此此处就取1和0,因此值不变,最后结果为:
初始值为0,并且这两个参数是在反向传播过程中训练得到的,因此此处就取1和0,因此值不变,最后结果为:
1.4.2 BN处理使用时需要注意的问题
①训练时要将training参数设置为True,验证时要将training参数设置为False(在pytorch中可以通过创建模型的model.train()和model.eval()控制),因为在训练过程中是要不断地统计均值和方差,但是在验证或者预测过程中,是使用我们历史统计的均值和方差,而不是使用当前计算的均值和方差;
②batch size设置的尽可能大,这样计算的均值和方差能够尽可能的接近整个训练集的均值和方差,效果越好,设置的太小效果会很差;
③将BN层放在卷积层(Conv)和激活层(如ReLU)之间,并且卷积层不使用bias,因为即使使用了偏置bias求出来的结果 和不使用bias的结果也是相同的。
和不使用bias的结果也是相同的。
1.5 迁移学习
1.5.1 使用迁移学习的优势
①能够快速的训练出理想的结果(只迭代几个epoch就可达到),减少训练时间;
②当数据集较小时也能训练出理想的结果。如果网络参数过多而数据集有太少,这些数据集是不足以训练整个网络的,这样便会出现过拟合的情况导致结果很差,但是使用迁移学习的方法可以使用别人预训练好的模型参数来训练我们较小的数据集,也能训练出一个比较好的效果。但是在使用别人的预训练模型参数时,要注意该模型预处理的方式。
1.5.2 迁移学习原理简介
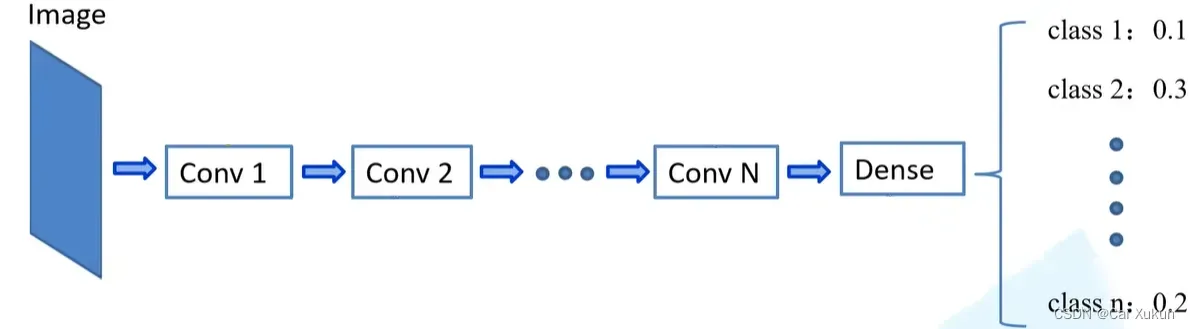
以上图网络模型为例,假设一张图像经过网络训练完之后,第一个卷积层学到了角点信息,第二层学到了稍微复杂的纹理信息,到第n层可能学到了识别眼睛、鼻子等等,最后通过全连接层将一系列的特征整合,最终能够输出对应每一个类别的概率。
对于浅层的网络,所学到的信息是较为通用的信息,不但能在本网络中使用,对于其他网路也是适用的,所以有“迁移”这个概念。将学习好的浅层网络的一些参数,迁移到新的网络中去,这样新网络也具有识别底层通用特征的能力,就能够更加快速的学习新数据集的高维特征了。
1.5.3 迁移学习方式
①载入权重后训练所有参数(效果最佳):
载入别人预训练好的模型参数之后,针对我们使用的数据集,再去训练所有层的网络参数,但要注意最后一层全连接层是无法载入预训练模型参数的,节点个数要根据我们数据集的类别更改。
②载入权重后只训练最后几层参数;
③载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层。
2 网络结构
原论文中不同层数网络的参数列表如下:
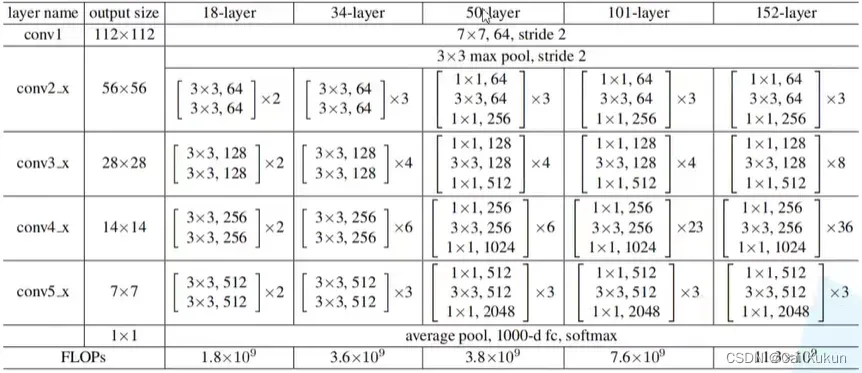
以34层的网络结构为例:
①第一层用了64个7×7的卷积核;
②第二层是3×3的最大池化下采样操作;
③经过Conv_2残差结构(共3个),如下图所示:
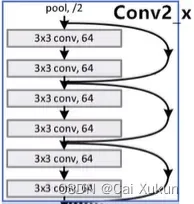
后面的残差结构同理,再经过平均池化下采样层和全连接层,最后softmax处理将输出转化为概率分布。
3 利用Pytorch实现ResNet网络
3.1 模型定义
3.1.1 ResNet-18、34所用残差结构
# 定义18层和34层网络所用的残差结构
class BasicBlock(nn.Module):
# 对应残差分支中主分支采用的卷积核个数有无发生变化,无变化设为1(即每一个残差结构主分支的第二层卷积层卷积核个数是第一层卷积层卷积核个数的1倍)
expansion = 1
# 输入特征矩阵深度、输出特征矩阵深度(主分支卷积核个数)、步长默认取1、下采样参数默认为None(对应虚线残差结构)
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
# 每一个残差结构中主分支第一个卷积层,注意步长是要根据是否需要改变channel而取1或取2的,不使用偏置(BN处理)
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
# BN标准化处理,输入特征矩阵为conv1的out_channel
self.bn1 = nn.BatchNorm2d(out_channel)
# 激活函数
self.relu = nn.ReLU()
# 每一个残差结构中主分支第二个卷积层,输入特征矩阵为bn1的out_channel,该卷积层步长均为1,不使用偏置
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
# BN标准化处理,输入特征矩阵为conv2的out_channel
self.bn2 = nn.BatchNorm2d(out_channel)
# 下采样方法,即侧分支为虚线
self.downsample = downsample
# 正向传播过程
def forward(self, x):
# 将输入特征矩阵赋值给identity(副分支的输出值)
identity = x
# 如果需要下采样方法,将输入特征矩阵经过下采样函数再赋值给identity
if self.downsample is not None:
identity = self.downsample(x)
# 主分支的传播过程
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 将主分支和副分支的输出相加再经过激活函数
out += identity
out = self.relu(out)
return out3.1.2 ResNet-50、101、152所用残差结构
# 定义50层、101层和152层网络所用的残差结构
class Bottleneck(nn.Module):
# 每一个残差结构主分支的第三层卷积层卷积核个数是第一层或第二层卷积层卷积核个数的4倍)
expansion = 4
# 输入特征矩阵深度、输出特征矩阵深度(和18层和34层网络残差结构的主分支卷积核个数相同)、步长默认取1、下采样参数默认为None(对应虚线残差结构)、最后两个参数和ResNeXt网络的搭建有关
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# ResNeXt网络的搭建
width = int(out_channel * (width_per_group / 64.)) * groups
# 每一个残差结构中主分支第一个卷积层,卷积核为1*1,不使用偏置
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
# BN标准化处理,输入特征矩阵为conv1的width
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# 每一个残差结构中主分支第二个卷积层,卷积核为3*3
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
# BN标准化处理,输入特征矩阵为conv2的width
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
# 每一个残差结构中主分支第二个卷积层,卷积核为1*1,输出特征矩阵为4倍的第一层或第二层卷积的卷积核个数
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
# BN标准化处理,输入特征矩阵为conv3的out_channel*self.expansion
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
# 激活函数
self.relu = nn.ReLU(inplace=True)
# 下采样方法,即侧分支为虚线
self.downsample = downsample
# 正向传播过程
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out3.1.3 定义网络结构
# 定义ResNet网络结构
class ResNet(nn.Module):
# 对应哪一种残差结构、残差结构数目(是一个列表值,如ResNet-34为[3, 4, 6, 3])、分类个数、方便在ResNet网络基础上搭建更加复杂的网络
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
# 输入矩阵深度,对应3*3maxpool后所得到的特征矩阵深度,不论多少层的ResNet网络均为64
self.in_channel = 64
# ResNeXt网络的搭建
self.groups = groups
self.width_per_group = width_per_group
# 第一层卷积层,输入RGB图像深度为3,64个7*7的卷积核,为了让输出特征矩阵的H和W变为原来一半padding设置为3
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
# BN层
self.bn1 = nn.BatchNorm2d(self.in_channel)
# 激活函数
self.relu = nn.ReLU(inplace=True)
# 最大池化下采样层,为了让输出特征矩阵的H和W变为原来一半padding设置为1
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x,通过_make_layer函数生成,注意该层输入的是maxpool输出的56*56的矩阵,因此不需要步长为2来减半,故步长默认为1
self.layer1 = self._make_layer(block, 64, blocks_num[0])
# conv3_x
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
# conv4_x
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
# conv5_x
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
# 平均池化下采样层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
# 全连接层,节点个数可能为512也可能为512*4
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 对卷积层进行初始化操作
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# 生成conv2_x、conv3_x、conv4_x、conv5_x的函数
# 选择哪种残差结构、主分支第一层卷积核个数、该层一共包含了多少个残差结构、步长默认为1
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
# 步长不为1或者conv2、3、4、5_x的第一个卷积层卷积核个数不等于最后一层卷积核个数(即expansion是否为4)
# 若为ResNet-18、34的虚线残差结构,前一项为True;若为ResNet-50、101、152的虚线残差结构,前后均为为True
# 故前一项是为了保证ResNet-18、34的conv3、4、5_x的判断能够通过
if stride != 1 or self.in_channel != channel * block.expansion:
# 生成副分支,输入为输入convx_x的特征矩阵,输出为1倍或4倍,步长为1或2
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
# 定义一个空列表,用来装convx_x的网络结构
layers = []
# 首先要把第一个残差结构加进去,因为第一个残差结构涉及到虚线残差结构
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
# 经过convx_x后输入conv(x+1)_x的channel变为1倍或4倍
self.in_channel = channel * block.expansion
# 把后面的残差结构加上,不涉及虚线残差结构
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
# 将层结构组合在一起并且返回
return nn.Sequential(*layers)
# 整个网络的正向传播过程
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
# 展平
x = torch.flatten(x, 1)
x = self.fc(x)
return x
3.2 训练过程
需要下载预训练模型,并且使用迁移训练,迁移训练代码如下:
# 迁移学习resnet34()中不能直接传入类别个数,若不使用迁移学习可以直接传入5就行
net = resnet34()
# 模型权重的位置
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
# 载入模型权重
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# in_features获取全连接层的输入
in_channel = net.fc.in_features
# Linear定义一个神经网络新的全连接层,输入为in_channel,输出为5
net.fc = nn.Linear(in_channel, 5)
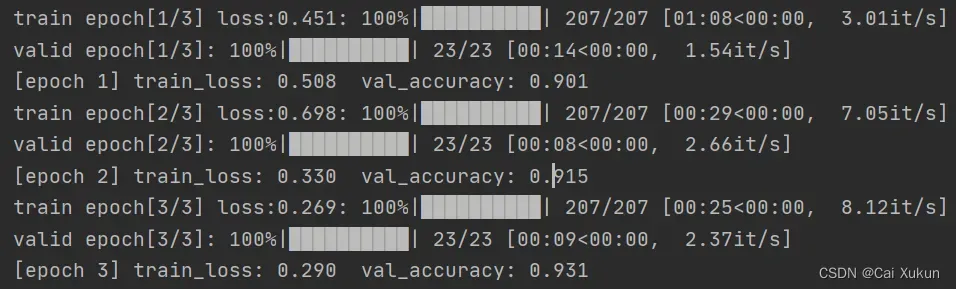
net.to(device)只经过三个epoch就能达到93%的正确率:
3.3 预测过程
3.3.1 单图片预测
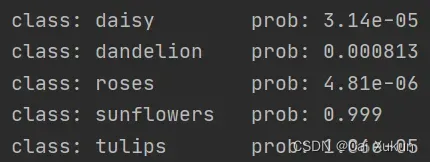
预测下面这张图片:

预测结果为向日葵的概率为99.9%:
3.3.2 多图片预测
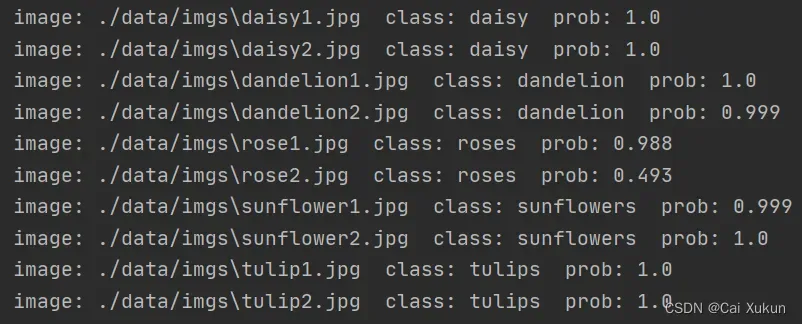
文件夹里存放了下列图片:

预测结果为:
文章出处登录后可见!