前言(不是论文前言)
和用言语讲出来相比,用文字解读论文挺有难度,因为作为听/观众来说,耳朵对信息的过滤效果要好于眼睛。论文看完,用代码把模型跑通、跑出较好的效果也很有难度,因为作者为了涨精度,常常加入一些tricks,但又不写在论文里。
AlexNet模型结构比较简单,所以实现起来不算难,但如果要在自己的数据集上训练,那还是有一定难度的,因为这涉及到数据处理、搭模型、推理预测等阶段,期间会出现很多bug,得一个一个解决。
出于篇幅和工作量的问题,本文的解读方式并不是像网上那样翻译一波+长篇大论(或复制别人的讲解),而是把我觉得有价值的地方捋一遍,适当补充一些知识点,然后把我自己跑通的代码讲一讲(又一次不忍吐槽:网上大部分代码都是bug满天飞的,作者到底有没有自己运行过…)。另外,本文采用的数据集是去年华为组织的一个竞赛的数据,由于数据量较大,因此每个标签只选取1-3张图片,旨在把模型跑通。(数据集可私聊我获取)
正文:论文的解释
论文地址:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf

ImageNet LSVRC是计算机视觉领域里一个十分重要的比赛,而作为深度学习在计算机视觉领域的开山之作AlexNet,在这个比赛中勇夺桂冠,而且大幅超过之前性能最好的方法,后面出现的大多数SOTA(表现最好)视觉模型都是以AlexNet为出发点进行改进的,因此这篇论文成为经典之作。
先看摘要,它实际上说了三件事:
- 使用多个卷积层+池化层
- 使用了ReLU激活函数
- 使用了Drop-out
注意:这三件事不容小觑。到目前为止,大多数视觉模型都有这三个的影子。
1.卷积层+池化层。
什么是卷积?通俗的讲,卷积是一种获取图片局部信息的计算方法。通常,使用多个卷积核来提取不同类型的特征。可以使用多少个卷积核来提取尽可能多的“模式”。例如,有的卷积核提取与“边缘”相关的信息,如线条、轮廓等,有的卷积核提取色块信息,如绿色色块、红色色块等,如下图:

什么是池化?通俗地说,池化的主要作用是降低图像的分辨率,但尽可能多地保留有用信息。例如,max pooling 用小块中响应最大的像素替换整个区域;另一个例子是average pooling,它使用一个小块中所有像素的平均值作为响应值,起到平滑的作用。
相比于全连接层,卷积层的优势就是可以大幅减少参数量和计算量,但又不会使得效果变差。全连接层是通过寻找整幅图片的特征来确定图片内容,输出层的每个节点需要和输入层的所有节点连接;而卷积计算利用了图像的局部相关性,只需要对限定的那么一片区域进行关联即可。卷积之所以能够work,是因为:图片的局部相关性是很突出的,比如文字中每一笔画附近的像素往往是相同的,一块背景区域的像素之间的颜色差异不大,等等。通常,一个像素和距离很远的像素关系不大,因此卷积计算在关注附近像素的同时,忽略了远处的像素,这也和实际图像表现出来的性质类似。
而池化呢?池化的英文叫“pooling”,实际上是“汇聚、聚集”的意思,目的在于从附近的卷积结果中再采样选择一些高价值的信息,丢弃一些重复的低质量信息,从而对特征信息做进一步的过滤,使特征变得少而精。作者在论文中提到,他采用重叠池化(Overlapping Pooling)的方法,如下图:
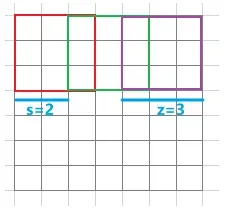
绿色框框以步长2进行滑动,从而和红框产生重叠,这样做有利于缓解过拟合。
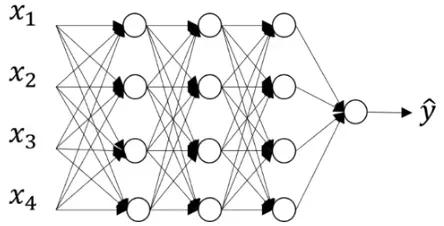
网络架构如下图所示:
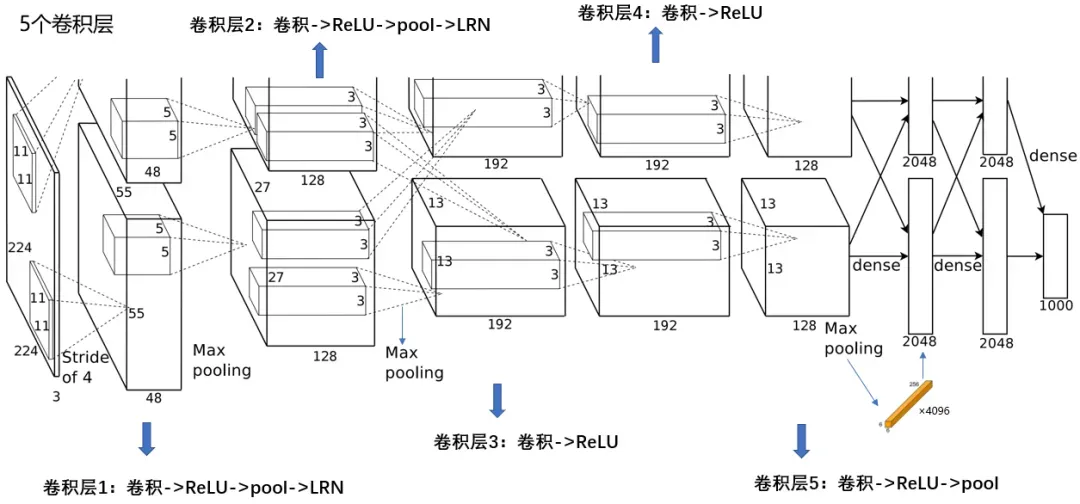
网络架构比较简单,使用了5个卷积层+3个最大池化层+3个全连接层,由于当时GPU显存较少(GTX 580只有3G显存),因此作者利用2块GPU并行计算,从上图可看出上下两部分对应于两块GPU。
二、ReLU激活函数
作者把修正线性单元(ReLU)用在了模型里,发现训练速度显著提高,原因在于传统用的是饱和非线性激活函数,例如tanh(·),训练时如果进入到饱和区域,那么会因为梯度变化过小而难以训练;而ReLU(·)是一种非饱和非线性激活函数,接受阈是0~∞,不存在tanh的问题。
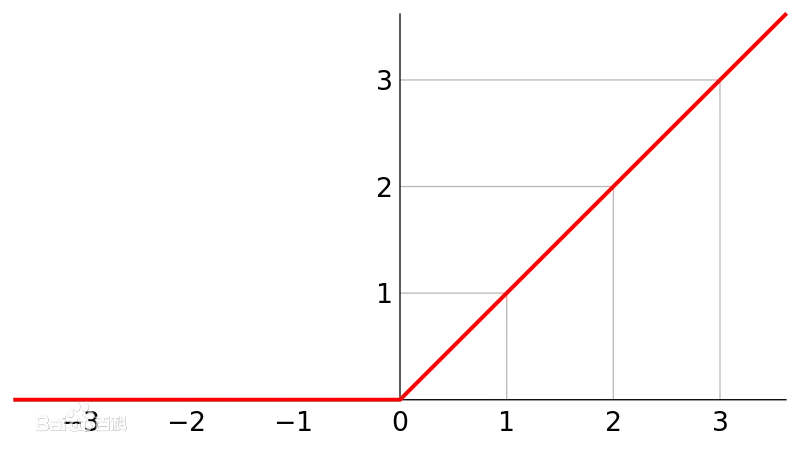
ReLU
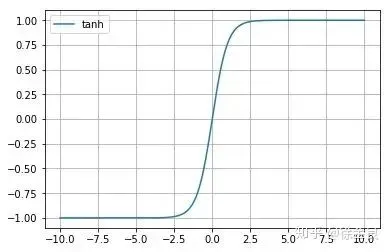
tanh
ReLU的好处是可以有效缓解梯度消失的问题,同时它可以被看做一种线性操作,从而更有利于模型分析(注意,这里只能说是“被看做线性”,由于大于0的部分和小于0的部分不同,因此整体是非线性的)。但缺点是无法限制数据的上界,因为可以趋于∞,因此会造成数值上的不稳定,另一个缺点是小于0的部分会被直接置为0,并且一直不会改变,导致这个数据“失效”。虽有缺点,但后面也有了应对的方法,例如在ReLU前采用批量归一化(BN)压缩到0-1之间来解决数值问题,采用Leaky ReLU来解决数据失效问题。
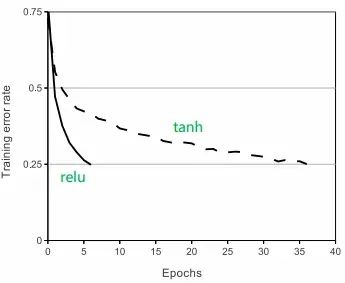
下图为作者使用tanh和ReLU训练模型的结果,可以看出在达到相同性能的情况下,ReLU只需5个epoch就能实现,而tanh需要36个epoch。
三、Drop-out
随机失活(Drop-out)技术是很常用的,其思想很简单(事后诸葛亮):全连接层由于参数过于庞大,因此很容易出现过拟合,那么每次迭代的时候把一些神经元以概率p失活,这样每次迭代时都是一个新的模型,显著提高了健壮性(Robust),某种意义可以看做通过集成不同的模型来提高泛化能力。举个例子如下图:
无Drop-out
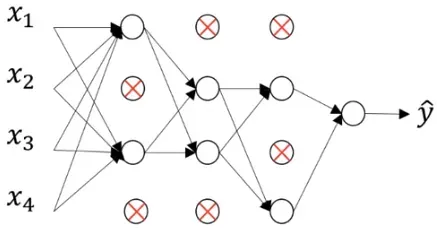
有Drop-out
说完三个主要创新,我们再来谈谈论文的另一个有趣的部分:使用数据增强来减少过拟合。
数据增强方法已经成为现阶段图像预处理的标准,这并不奇怪,但在当时还是相当创新的。
训练阶段,作者把一张长宽都为256的图片以步长1进行裁切,同时把裁切后的图片再水平翻转,这样就把一张图片扩充为2048张((256-224)^2×2),尽管每张图片相关性较高,但能够缓解过拟合的情况。(对此我的理解是:尽管大部分图片是高度相关的,但由于扩充倍数实在太大,那么也能够学习到其中的微小差异,并利用这些差异来提高模型的泛化能力。如有其它想法,期待交流探讨。)
测试阶段,作者通过在图片的四角和中心进行裁剪+翻转,把每张图片扩充为10张图片,分别预测,然后计算均值,如下图:

作者经过实验后发现,这个数据增强方法在ImageNet数据集上有较好的表现。(这里说一点题外话,用哪种数据增强方法,需要看自己手里的数据集是什么情况,在ImageNet上好用的方法,在其它数据集上不一定好用,比较好的办法就是多尝试,然后获取经验)
正文:代码实现
主要包括数据集引入、模型构建、数据预处理、模型训练和推理五个模块。
任务:利用AlexNet对华为金相图片进行分类。
框架:pytorch。
下面给出部分代码。完整代码可以在我的微信公众号文章中查看~(见文末链接^_^)
一、数据集简介
样本是显微镜下的金相图,分为6.5-13.0共14个类别,如下图所示:
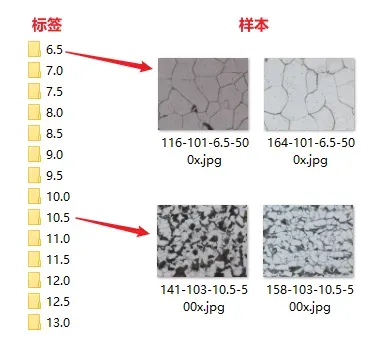
可以看出,标签值越小,小块越大。每个标签下有1-3张图片,总共有31张图片(为了快速实验模型是否能跑通,如果用所有数据集,那么跑一个epoch会很慢)。
注:在训练之前,需要把数据集划分为训练集和验证集,并放在dataset文件夹下(也可以放其它地方,那么后面的代码需要一下路径):
2. 模型构建
下面的代码定义了一个类,叫做AlexNet,然后根据论文里的模型架构一层层搭建即可。需要注意的是,前面提到过,论文里作者把每一个卷积层输出的通道数拆分为二,送到两块GPU上训练,那么这里就只弄一半的通道数即可,例如第一个卷积层,原文是48×2,那么这里就定义为48。
这段代码保存为一个 .py文件,名为my_net.py。
import torch
import torch.nn as nn
class AlexNet(nn.Module): # AlexNet继承nn.Module的初始化方法
# def __init__的参数写多少无所谓,后面创建实例的时候写上即可
def __init__(self, num_class = 14, init_weights = False):
super(AlexNet, self).__init__()
# 下面定义特征提取层:CNN+pooling
self.feature_extract = nn.Sequential(
# 第一个模块:卷积->ReLU->maxpool
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # padding有两种表述方式:int和tuple
nn.ReLU(inplace=True), # 参数含义:对传过来的tensor直接修改,节省内存空间
nn.MaxPool2d(kernel_size=3, stride=2),
# 第二个模块:卷积->ReLU->maxpool
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# 第三个模块:卷积->ReLU
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第四个模块:卷积->ReLU
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第五个模块:卷积->ReLU->maxpool
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 下面定义分类层:FC
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=128*6*6, out_features=2048),
···(省略)
# 最终输出模型
model = AlexNet(num_class=14, init_weights=False)
print(model)
3.数据预处理
下面的代码主要对图片进行标准化、数据增强,然后把图片转为可以输入模型的张量(tensor),最后送到模型里。
ImageFolder是pytorch自带的加载数据工具,可以对原始图片进行各种处理,然后封装起来。DataLoader是pytorch自带的数据装载工具,比较重要的功能是把数据拆分为多个批量(batch)送到模型中训练。
这段代码保存为一个 .py文件,名为my_data_preprocess.py。
import torch
import torch.nn as nn
from torchvision import datasets, transforms, utils
import os
import json
import matplotlib.pyplot as plt
import numpy as np
#### 定义一些全局的参数 ####
batch_size = 2
#### 定义一些数据预处理方法 ####
# 这两组数据是ImageNet数据集所有样本的RGB均值和标准差,用这个一般没错
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
#### 定义文件路径 ####
os.chdir('...自己定义') # 修改当前工作目录,后面便于操作
data_root = os.path.join(os.getcwd(), r'dataset') # 这是获取数据集路径的代码,
# 一般需要自行设置
#### 利用transforms.Compose()对图片预处理,同时转为可训练的tensor ####
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]),
"val": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.ToTensor(),
normalize,
])
}
···(省略)4.模型训练
下面的代码主要是定义训练过程,比如定义epoch、学习率、损失函数、优化算法等等,这部分的基础写法是比较固定的,但如果要采用其它策略进行训练,那就需要定义很多东西了,比如学习率衰减、冻结部分层进行微调、不同层用不同学习率、加载其它预训练模型等等,这些内容后面再补充。
这段代码保存为一个 .py文件,名为my_train.py。
import os
import torch
import torch.nn as nn
import torch.optim as optim
import time
from tqdm import tqdm # 显示进度条的库
from AlexNet.my_net import AlexNet # pycharm中,同级导入需要加上文件所在目录名称
from AlexNet.my_data_preprocess import *
#### 定义一些参数 ####
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择用CPU还是GPU训练
num_epoch = 2
learning_rate = 0.1
save_path = os.getcwd() # 保持模型的路径
#### 创建网络实例 ####
model = AlexNet(num_class=14, init_weights=False)
# 模型放到设备上, 这里先把model的参数放到设备上,后面训练每一个epoch时,要把图片和标签也放到设备上
model.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-4)
#### 开始训练 ####
best_acc = 0.0
running_time = []
print('开始训练------------>')
for epoch in range(num_epoch):
# 训练阶段
model.train() # 训练时用 .train(),后面验证时用 .eval()。因为像dropout、BN层,训练时和验证时是不一样的!
running_train_loss = 0.0 # 统计训练集的平均损失
start_time = time.perf_counter() # 统计训练一个epoch需要多久, 需要两个time.perf_counter()计算区间
train_loader = tqdm(train_loader, file=sys.stdout)
for step, (image, target) in enumerate(train_loader):
image, target = image.to(device), target.to(device)
# 计算输出、损失
output = model(image) # 前向传播
loss = loss_func(output, target) # 计算损失
# 反向传播
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播求解梯度
optimizer.step() # 更新权重参数
···(省略)
print('训练结束<------------')
5. 推理
以下代码主要用于预测新传入的图像。实际上,它类似于在训练阶段对验证集的操作。不同之处在于预训练的权重在推理阶段再导入一步。
这段代码保存为一个 .py文件,名为my_inference.py。
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from AlexNet.my_net import AlexNet
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
data_transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize])
# 加载图片
img_path = "./dataset/val/6.5/164-101-6.5-500x.jpg"
img = Image.open(img_path)
plt.imshow(img) # 先把图画出来
img = data_transform(img)
print(img.shape)
img = torch.unsqueeze(img, dim=0) # 在tensor的第0个位置加上batch信息
# 读取标签的json文件
json_path = './class_indices.json'
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# print(class_indict)
# 创建模型
model = AlexNet(num_class=14).to(device)
# 加载预训练权重
weights_path = "./model.pth"
···(省略)
plt.title(title)
plt.show()最后看一下推理结果(当然是很不准确的):

后记1:文中涉及到很多基础知识,每次写到那个知识点的时候就想多扩展一些,但是这样做的话不知道得写多少字了,遂尽量精简,其实那些知识点在书本上、网上都有更详细的讲解,推荐使用“哪里不会查哪里”的方法。
后记2:后期准备持续用这样的方式解读论文,方向主要是目标检测,并且主要在微信公众号进行更新,喜欢的朋友可以关注一波哦~
关注我的微信公众号“风的思维笔记”,期待与大家共同进步!

有新想法,期待交流讨论~

文章出处登录后可见!