TS-CAM:由Vision Transformer架构产生CAM类别激活图的一种方法
前言
《TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised
Object Localization》这篇文章解决的是弱监督定位问题(单标签),但其主要内容是由Vision Transformer架构得到一种类别激活图: TS-CAM。本文结合论文内容和Vision transformer, TS-CAM的代码,用画图的形式解释作者的思路。
一、论文链接和代码链接以及重新训练模型得到可视化结果
TS-CAM论文:
论文
TS-CAM代码链接:
TS-CAM代码
Vision Transformer代码链接:
ViT代码
以下内容均来自于对以上文献和代码的理解,在此表示感谢!
在服务器上重新训练模型后,我们重新可视化CUB200种鸟类数据集的结果,确保代码应该无误。
以下是原文中的一张鸟类结果图。最后一张图是该图片对应的TS-CAM。

下面是重新训练模型后得到的该张图片的TS-CAM结果图(取阈值0.4)。

以下是另一张原文中的结果图。最后一张图是该图片对应的TS-CAM。

下面是重新训练模型后得到的该张图片的TS-CAM结果图(取阈值0.4)。

确认代码运行无误后,我们结合代码看作者的思路。
二、TS-CAM论文是如何由Vision Transformer得到类别激活图的?
1.embedding层
我们以一种规模的ViT模型vit_base_patch16_224_in21k为例,16表示每个patch大小是16×16个像素,224表示所有图像要先调整尺寸为224×224后再输入模型,in21k表示该模型已在Imagenet21k上预训练过。对于一个大小为[3, 224,224]的图像,每个patch大小为16×16,则一幅图像中有14*14个patch。
对于transformer模块,要求输入的是token序列(向量序列),得到每一个图像块的token是用卷积操作实现的。例如,要将每个patch编码为一个768长度的向量,则我们需要768个卷积核,每个卷积核大小为16×16,步长是16。如下图所示。
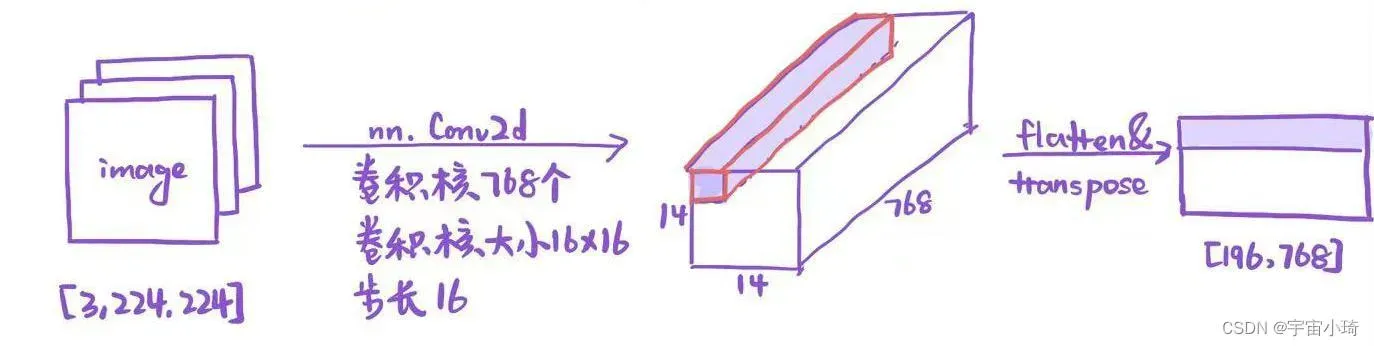
每一行是一个patch的token向量。
在输入到transformer block之前需要加上class token以及position embedding,这两个都是可训练参数。class token是作为一个单独的768维向量加到第一行上,position embedding是作为一个768维向量加进每一个token中,如此,embedding层最终得到的矩阵大小是[197,768], 第一行对应class token,其余行对应每一个patch token。
2.transformer encoder层+Conv2d head层
在得到class token和patch token后,我们就得到了embedded patches。将其送入transformer encoder中,transformer encoder的内部结构如下图所示:
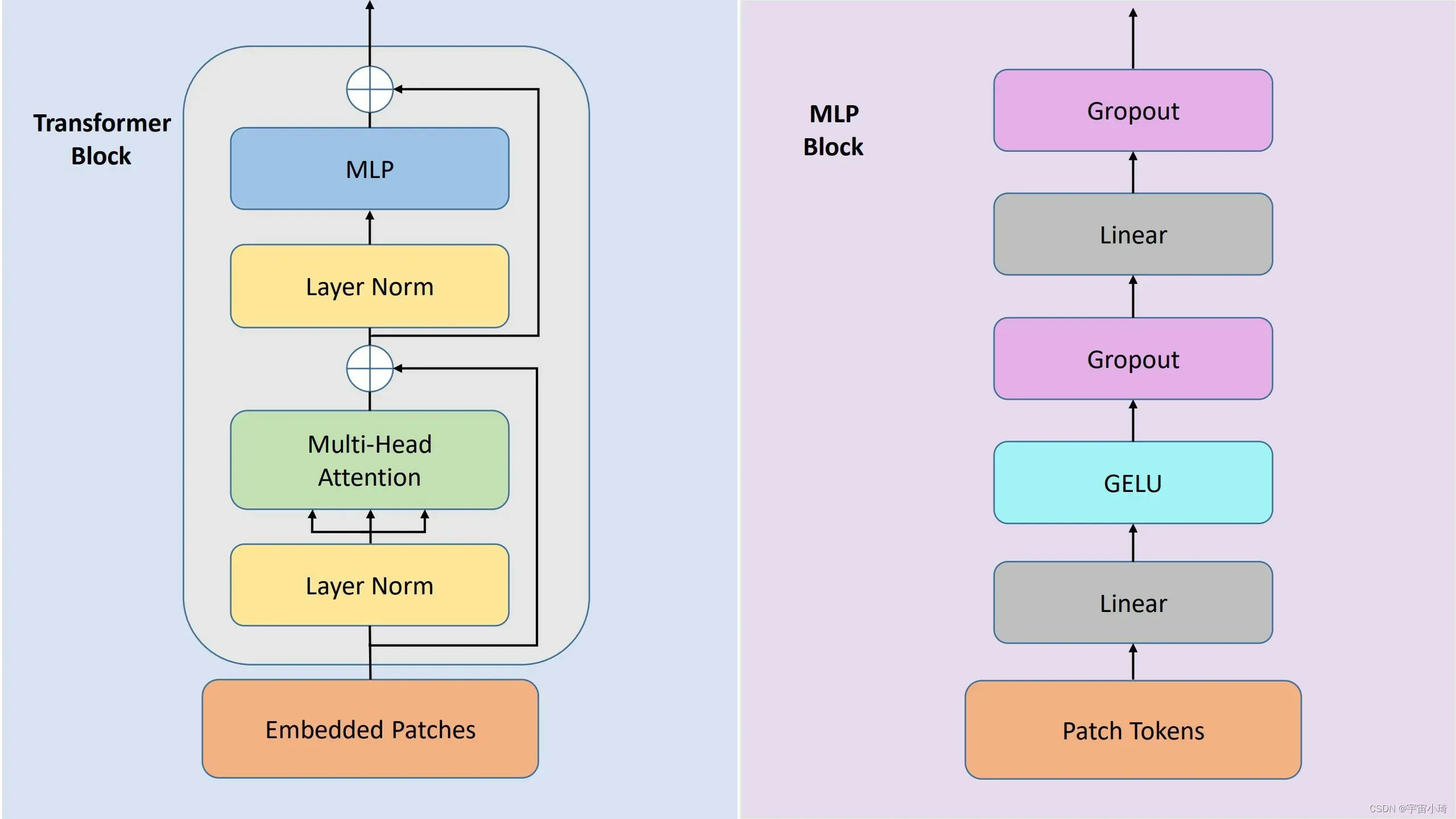
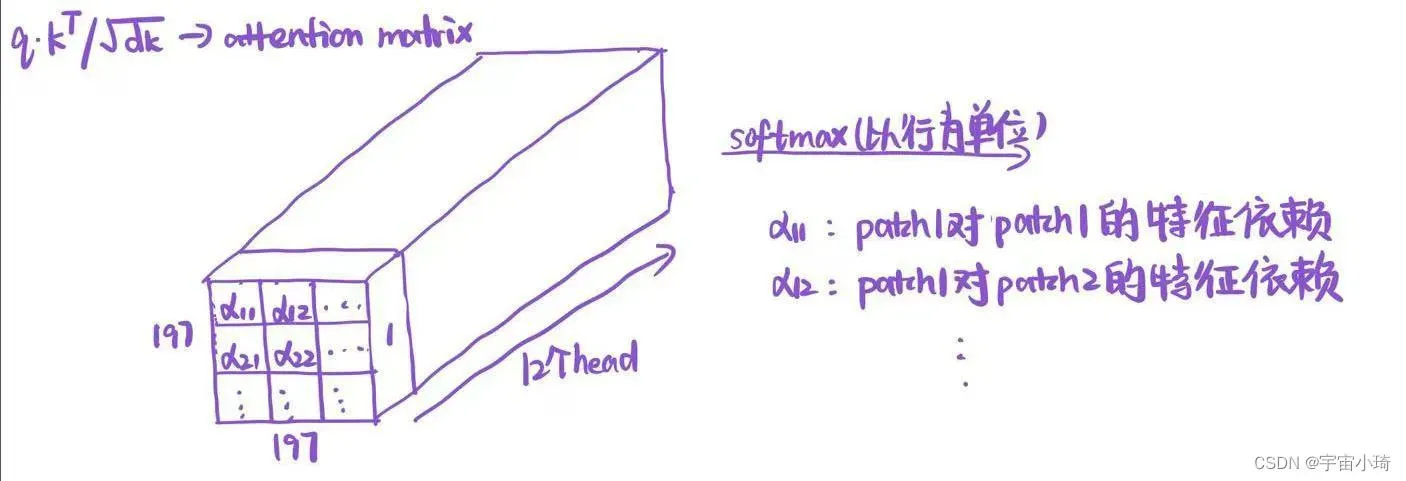
除了Layer Norm和Dropout外,就是Multi-Head Attention和MLP两个模块了。论文中有用到12个transformer block,每个Multi-Head Attention模块里用到12个head。我们只看一个transformer block, 并以3个head为例,multi-head attenttion操作如下:
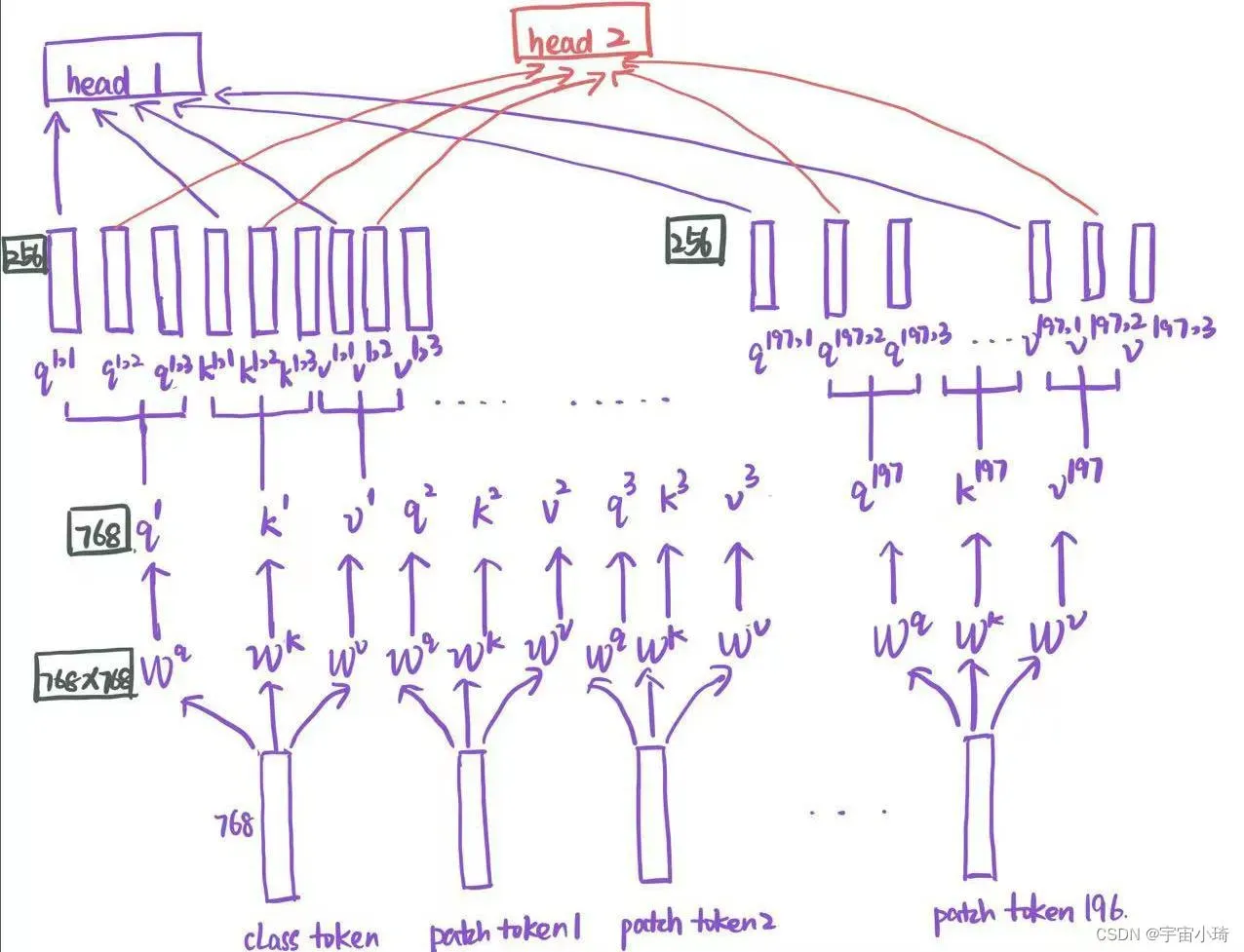
论文中有12个head, 所以对每个head而言,patch token(class token)的特征向量维度是768÷12=64维。对应的矩阵和
矩阵如下图所示:
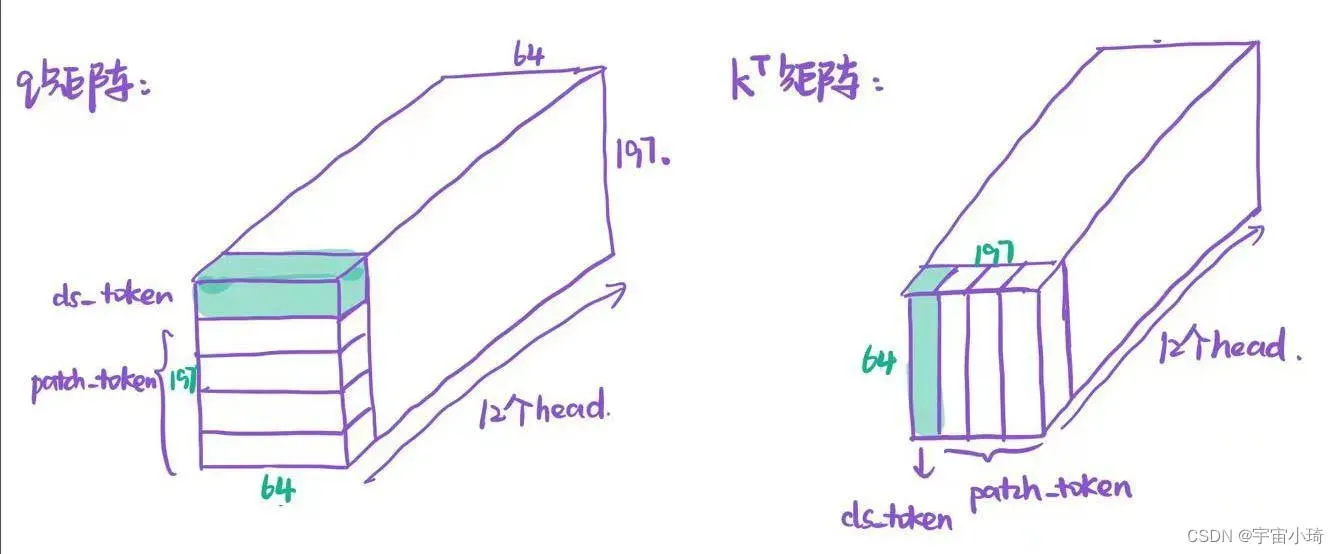
根据公式计算注意力矩阵attention matrix,然后以行为单位进行softmax操作。
3.可视化
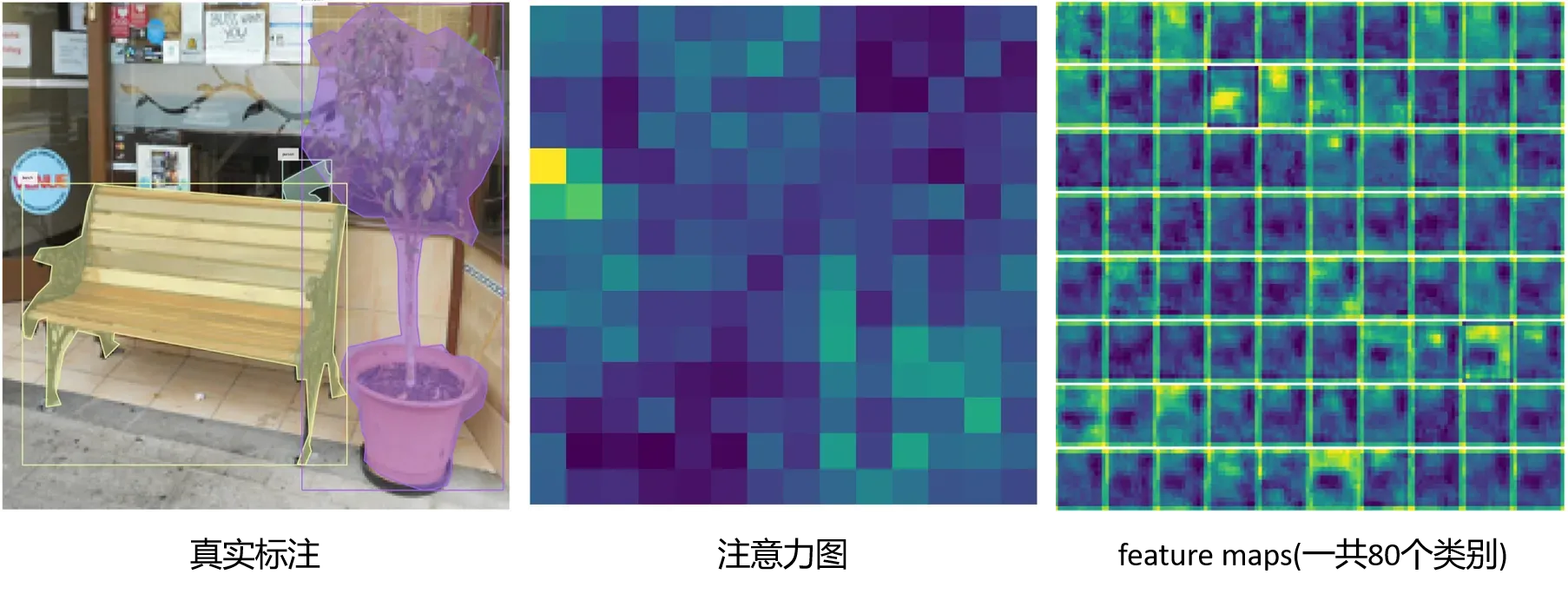
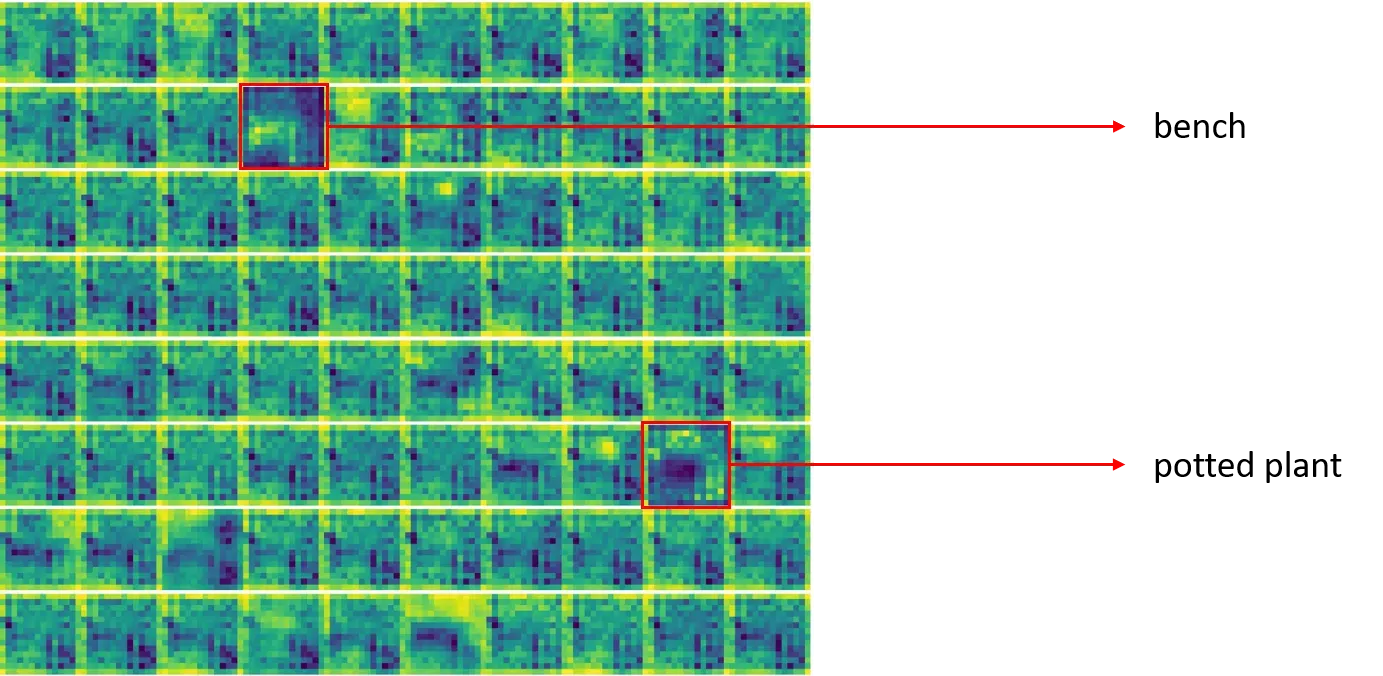
下面我们可视化几张COCO数据集上图片的注意力图cams_re和特征图feature maps,以及将它们两个相乘得到的TS-CAM图,COCO数据集有80个类别,所以feature maps和TS-CAM图都是80个通道,而注意力图是单通道的。
示例1:
将注意力图和特征图相乘即得到下图的TS-CAM类别激活图:

红色框是预测出的类别
示例2:
总结
以上是TS-CAM的具体获取细节。更多的可视化方法可参考github官方文件:
CUB数据集可视化TS-CAM
文章出处登录后可见!