
目录
从例子出发
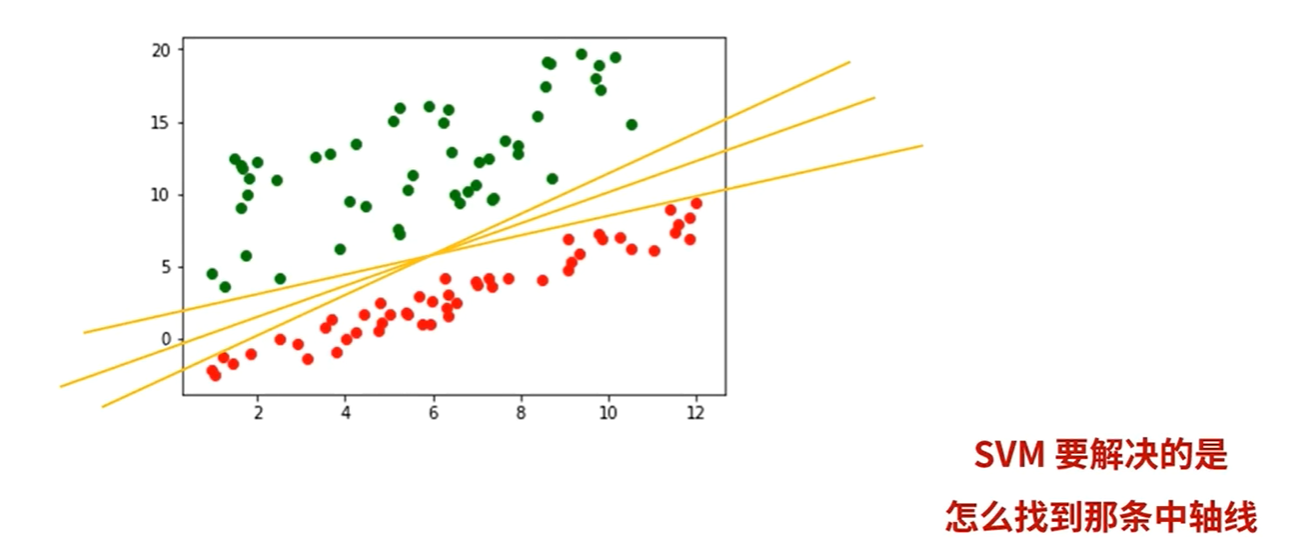
算法原理
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
具体来说就是在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
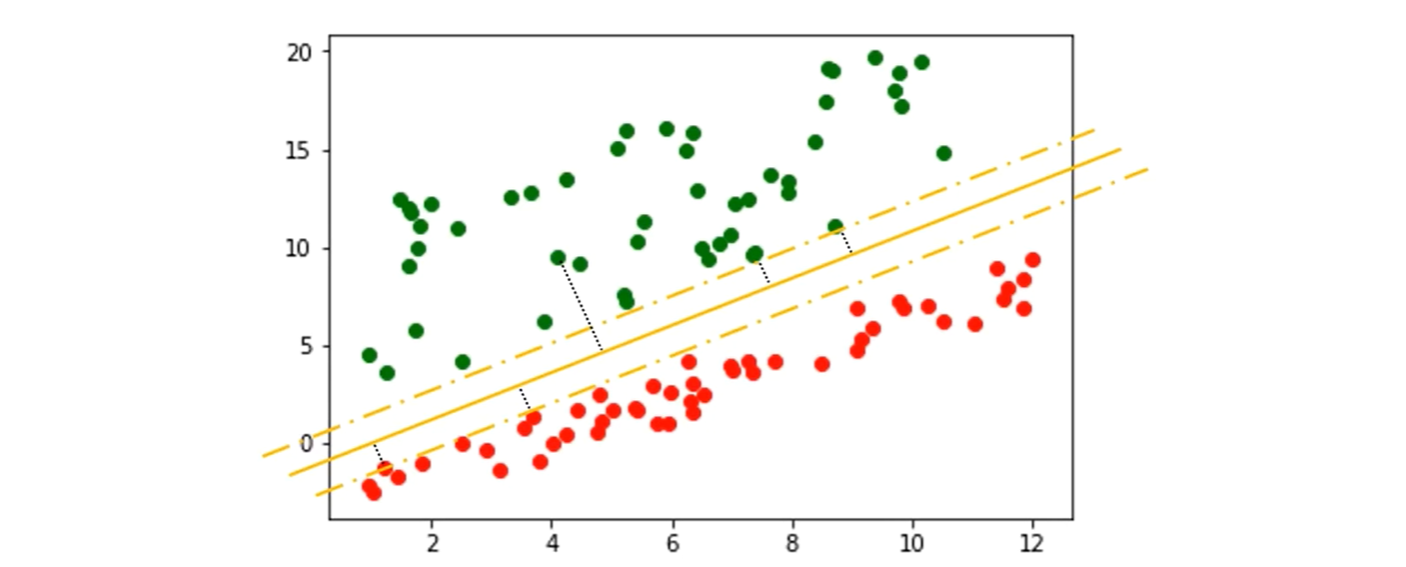
超平面

支持向量
假设找到一条线可以分割红豆和绿豆
红豆和绿豆中距离这条线最近的几个样本点被称为支持向量(Support Vector)
这些点到这条线的距离称为间隔
在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用
如何处理不清晰的边界

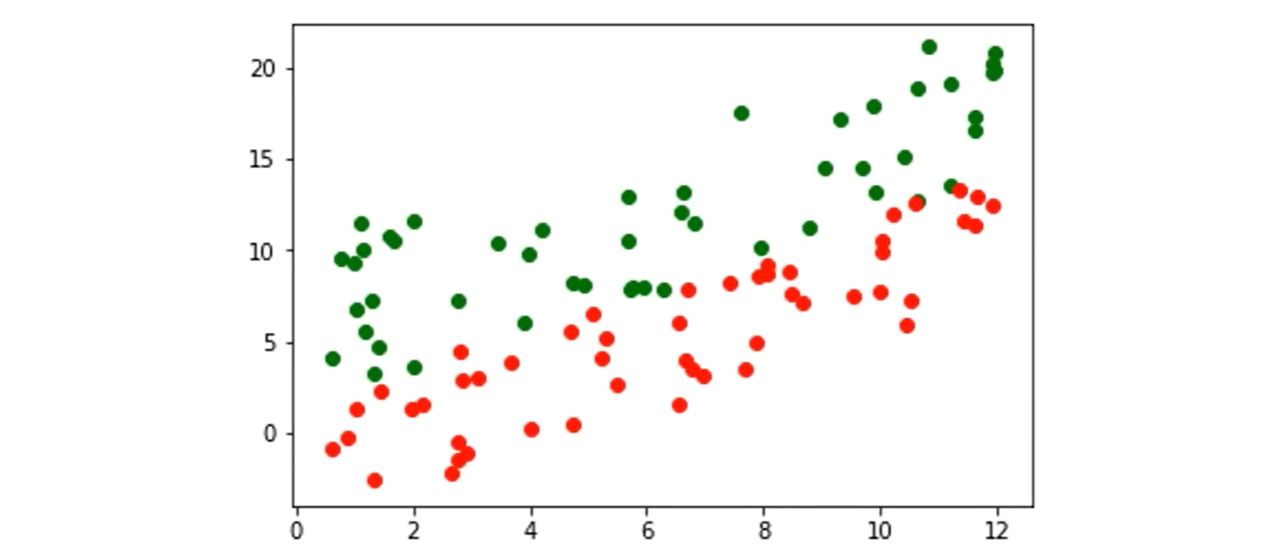
非线性可分的情况
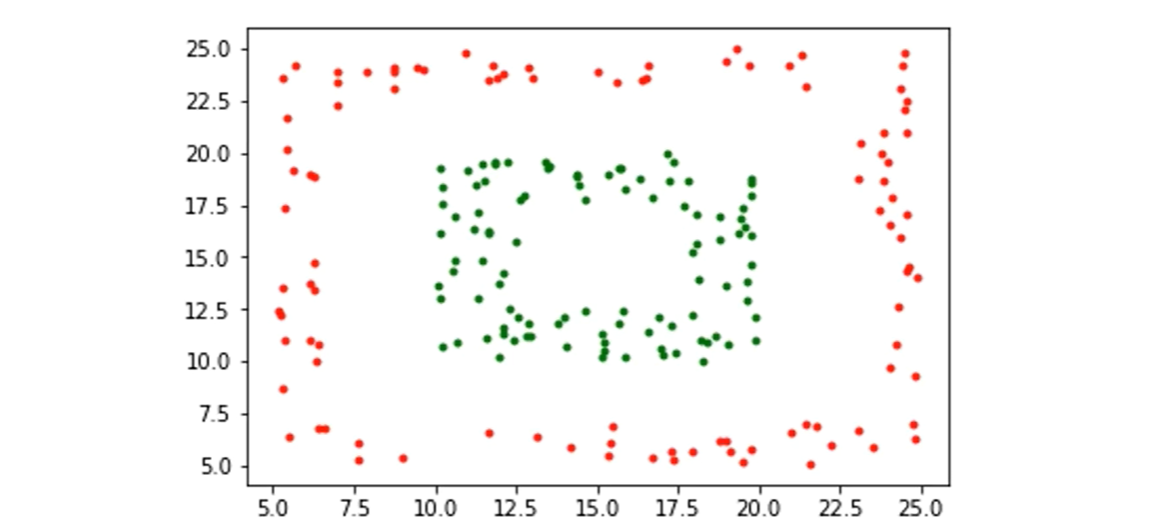
SVM中采取的办法是:
把不可划分的样本映射到高维空间中
在SVM中借助“核函数”,来实现映射到高维的操作
常见的核函数
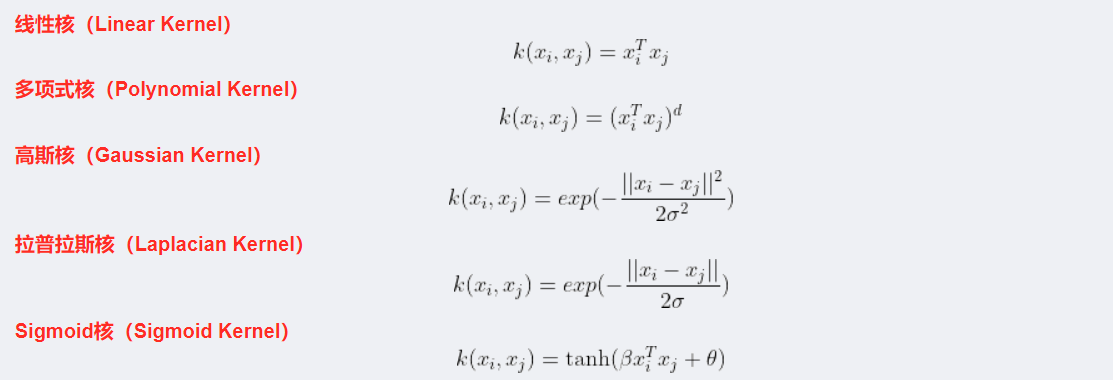
算法的优点
支持向量机算法可以解决小样本情况下的机器学习问题,简化了通常的分类和回归等问题。
由于采用核函数方法克服了维数灾难和非线性可分的问题,所以向高维空间映射时没有增加计算的复杂性。换句话说,由于支持向量计算法的最终决策函数只由少数的支持向量所确定,所以计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
支持向量机算法利用松弛变量可以允许一些点到分类平面的距离不满足原先要求,从而避免这些点对模型学习的影响。
算法的缺点
支持向量机算法对大规模训练样本难以实施。这是因为支持向量机算法借助二次规划求解支持向量,这其中会涉及m阶矩阵的计算,所以矩阵阶数很大时将耗费大量的机器内存和运算时间。
经典的支持向量机算法只给出了二分类的算法,而在数据挖掘的实际应用中,一般要解决多分类问题,但支持向量机对于多分类问题解决效果并不理想。
SVM算法效果与核函数的选择关系很大,往往需要尝试多种核函数,即使选择了效果比较好的高斯核函数,也要调参选择恰当的参数。另一方面就是现在常用的SVM理论都是使用固定惩罚系数C,但正负样本的两种错误造成的损失是不一样的。
代码的实现
from sklearn import datasets
from sklearn import svm
#引入svm包
import numpy as np
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices= np.random.permutation(len(iris_x))
iris_x_train = iris_x[indices[:-10]]
iris_y_train= iris_y[indices[:-10]]
iris_x_test = iris_x[indices[-10:]]
iris_y_test = iris_y[indices[-10:]]
#使用线性核SVC是分类支持向量机的意思,另外还有SVR是回归支持向量机
clf = svm.SVC(kernel = 'linear')
clf.fit(iris_x_train,iris_y_train)#拟合
#调用该对象的测试方法,主要接收一个参数:测试数据集![]()
iris_x__test = iris_x[indices[-10:]]
iris_y_test = iris_y[indices[-10:]]
#使用线性核SVC是分类支持向量机的意思,另外还有SVR是回归支持向量机
clf = svm.SVC(kernel= 'linear')
clf.fit(iris_x_train,iris_y_train) #拟合
#调用该对象的测试方法,主要接收一个参数:测试数据集
iris_y_predict= clf.predict(iris_x_test)
#调用该对象的打分方法,计算出准确率
score=clf.score(iris_x_test,iris_y_test,sample_weight=None)
print('iris_y_predict=')
print(iris_y_predict)
print('iris_y_test= ')
print(iris_y_test)
print('Accuracy:"',score) 
总结
支持向量机算法分类和回归方法的中都支持线性性和非线性类型的数据类型。非线性类型通常是二维平面不可分,为了使数据可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易区分,这样就达到数据分类或回归的目的,而实现这一目标的函数称为核函数。
工作原理:当低维空间内线性不可分时,可以通过高位空间实现线性可分。但如果在高维空间内直接进行分类或回归时,则存在确定非线性映射函数的形式和参数问题,而最大的障碍就是高维空间的运算困难且结果不理想。通过核函数的方法,可以将高维空间内的点积运算,巧妙转化为低维输入空间内核函数的运算,从而有效解决这一问题。
文章出处登录后可见!