Vit:
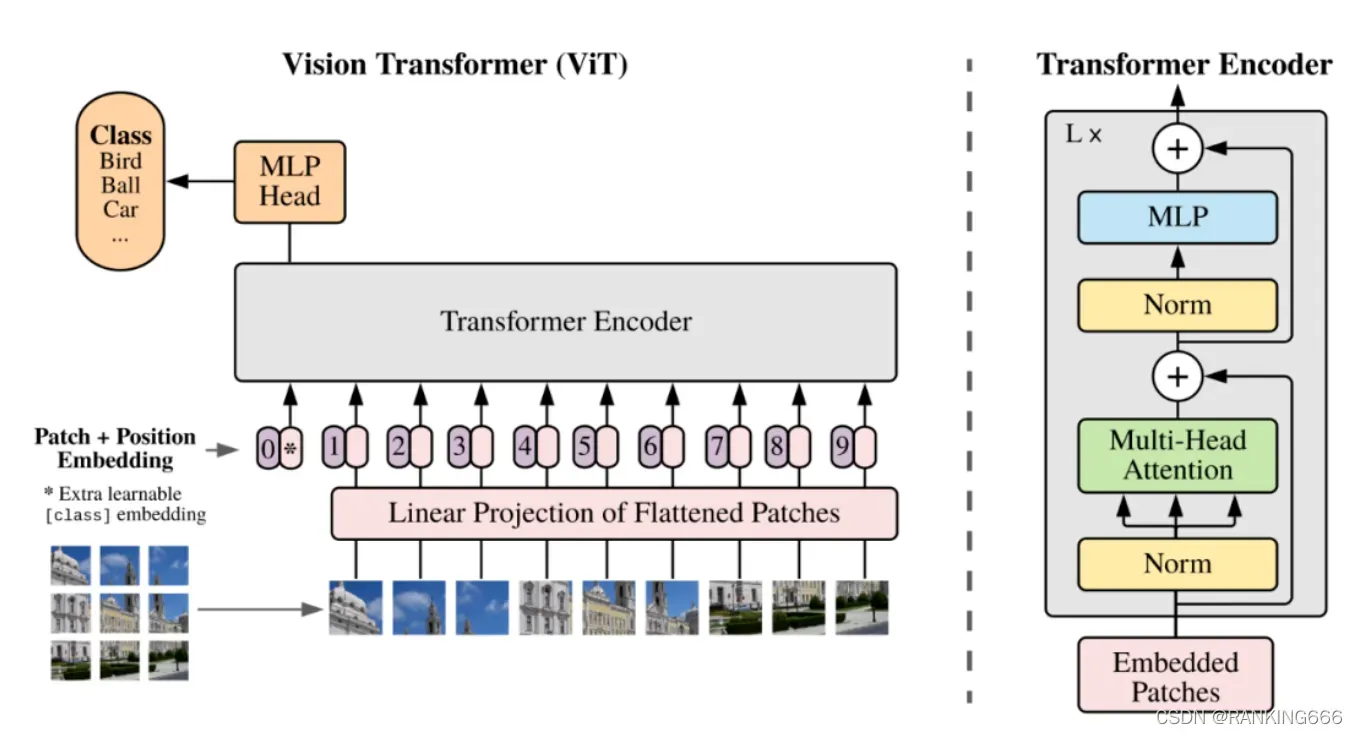
最基础的,就是将transformer的encoder取出来。
输入图像大小维度(B,C,H,W),将图片不重叠地划分为H/patch_height * w/patch_weight个patch,每个patch为patch_height * patch_weight * c。
之后,concat用于分类的cls token,维度+1,同时加入可学习的绝对位置编码,送入transformer的主体。
之后就与tansformer的计算相同,这里不多做赘述。
如果要加入mask屏蔽,应该在未softmax前的attention weights进行屏蔽。
最终送入分类头时,可以选择对所有patch求均值或只送入cls token。
Deit:
DeiT 是在 ViT 的基础上,多加入了一个 distill token 用于蒸馏学习。
本文提出了两种蒸馏方法:
软蒸馏:
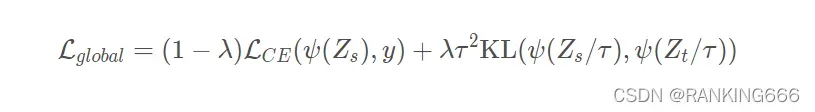
λ,τ是超参数,y 是ground truth,ψ是softmax函数,Zs和Zt分别是学生模型、教师模型的输出, LCE是交叉熵损失,K L是KL散度。
KL散度也就是相对熵,也是用来计算两个概率分布的一种差异
硬蒸馏:
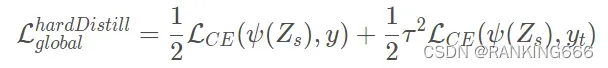
也就是计算学生的输出分别于与真实标签,yt教师输出做损失。
DeepViT:
主要在于VIT深层,自我注意机制无法学习到有效的表征学习概念,阻碍了模型获得预期的性能增益。也就是出现了注意力坍塌的问题。
基于这一观察,为了解决注意力崩溃的问题,并有效地将视觉转换扩展到更深的层面,提出了一种简单而有效的自我注意机制–再注意( re-attention )用于 ViTs 中。
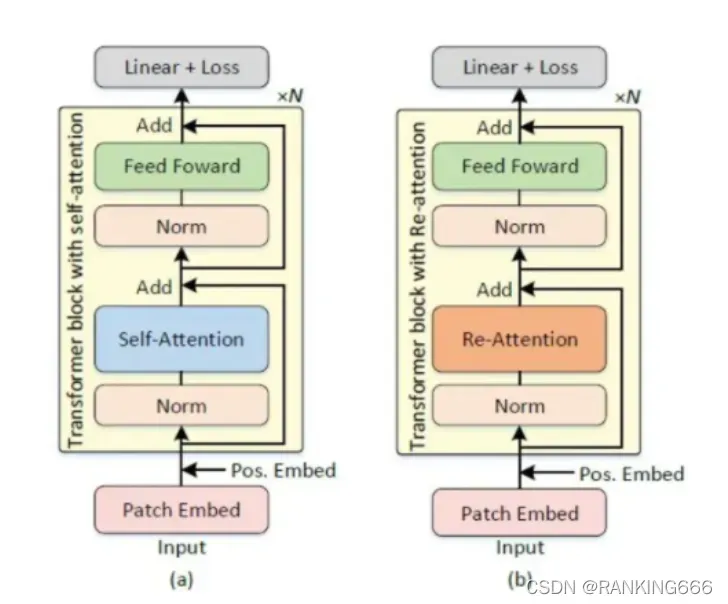
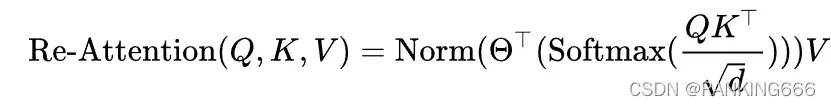
定义了一个端到端可学习的变换矩阵,变换矩阵沿着头部维度乘以自注意力映射图,将多头注意力映射图混合到重新生成的新的注意力映射图中,并且Norm取得是BatchNorm而不是传统的LayerNorm,然后与Value相乘。实现时,变换矩阵是一个(heads,head,1,1)的二维卷积。
Cait:
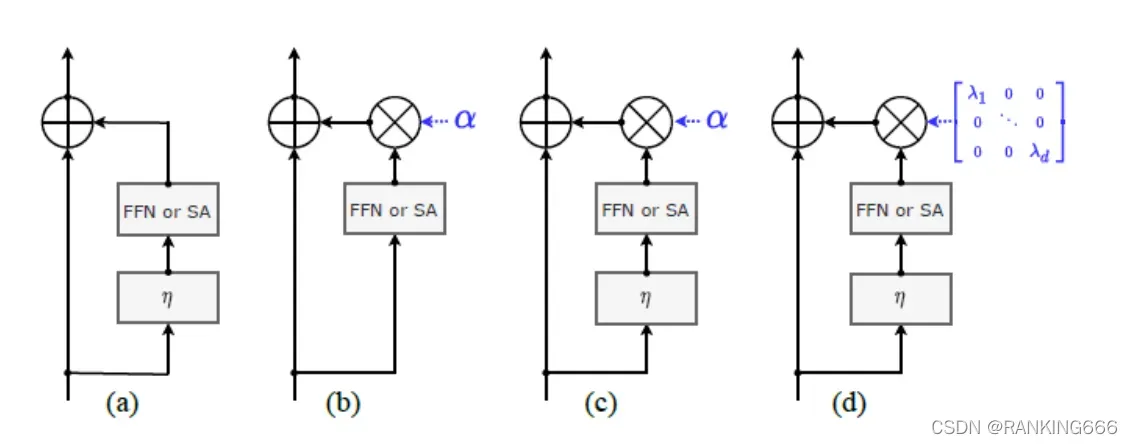
( b )( c )中的α是一个实数,即, FFN 或 SA 的输出特征都统一乘以α;而图( d )中, FFN 或 SA 输出特征的不同 channel 乘上不同的数值,在一定程度上会使得特征更细化,更精准。
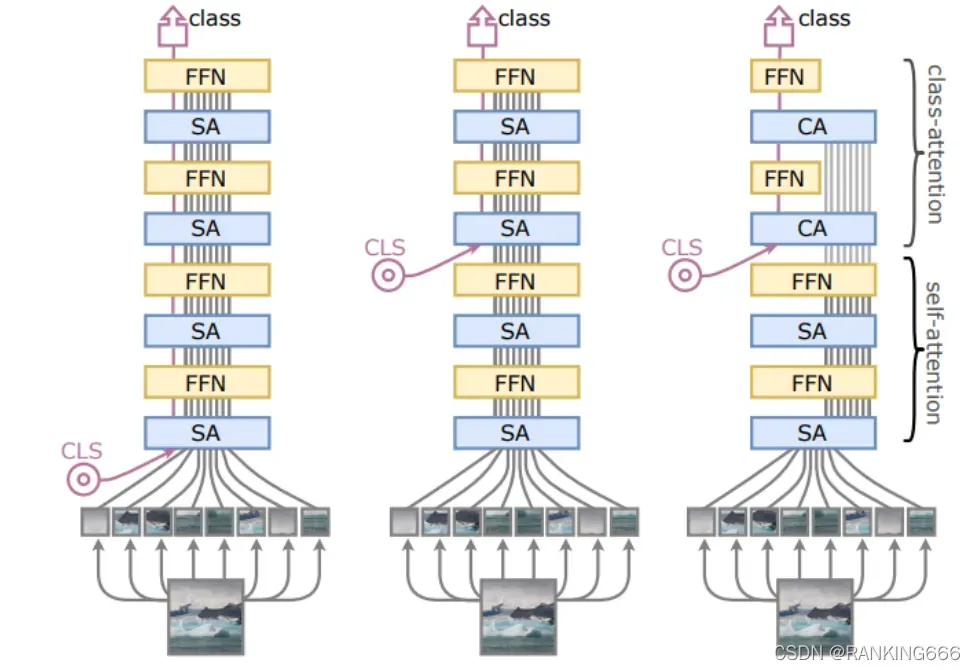
该作者认为,既然用于分类的 cls token 只是为了获得图片的全部信息,那么完全不必在一开始就送入网络进行信息交互,只在最后两层 transformer 加入进行信息交互。
CPVT:
这篇论文主要的侧重点在于,位置的编码。常见的 position encoding 方式包括绝对位置编码和相对位置编码等。
目前常用的一般是绝对位置编码,包括在 Transformer 中提出的 sinusoidal 编码方式,以及在 GPT , ViT 等中所使用的可训练的位置编码等。但是一般的绝对位置编码针对特定分辨率的任务,在训练时就会生成固定尺寸的编码,无法处理不同分辨率大小的图片,这极大地妨碍了 Transformer 地灵活性和更大的应用空间。常见的处理方式是在处理不同分辨率的图像时,对训练好的 position encoding 进行插值适用,但需要 fine-tune 来恢复,不然会造成较大的精度下降。
所以,该文提出了提出一种能够根据不同尺寸输入改变长度的 position encoding 方式
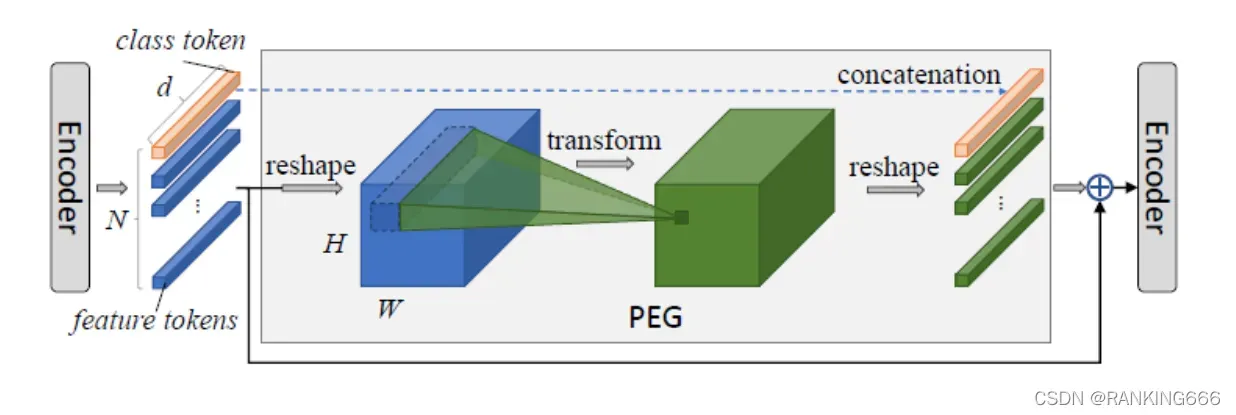
首先对上一个transformer encoder的输出进行reshape,回退为2D的图像形式;
然后对该2D信息进行一个2D可分离卷积等来进行局部信息的提取;
最后对新生成的tensor重新reshape到序列化信息格式作为输出。
由于class token中不包含位置相关信息,因此将其隔离不参与PEG的操作。
CVT:
将卷积与 transformer 两种设计相互结合,寻求最佳组合方式,从而提高了视觉 Transformer ( ViT )的性能和效率。
CvT的整体流程如图所示。在 ViT 架构中引入了 2 种基于卷积的操作,即卷积 Token 嵌入和卷积映射。
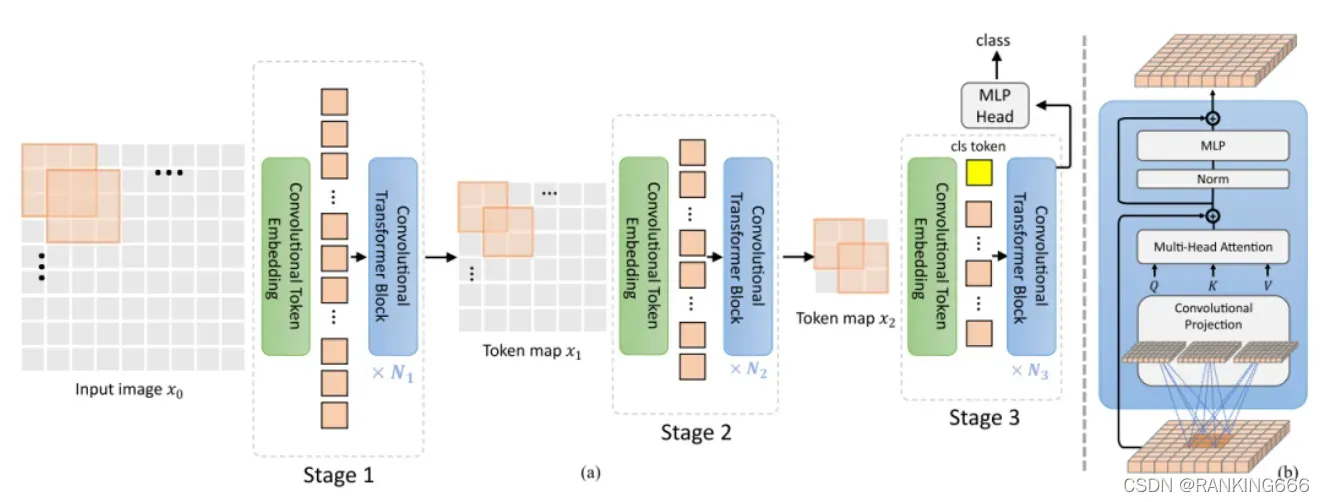
卷积 Token 也就是,在 VIT 中使用 linear 实现 patch_embedding 和 pos_embedding ,而在这里使用卷积替代。并且每一个 stage ,都会进行卷积 +LN 的 token embedding 。这允许每个阶段逐步减少 Token 的数量 ( 即特征分辨率 ) ,同时增加 Token 的宽度 ( 即特征维度 ) ,从而实现空间下采样和增加丰富度。
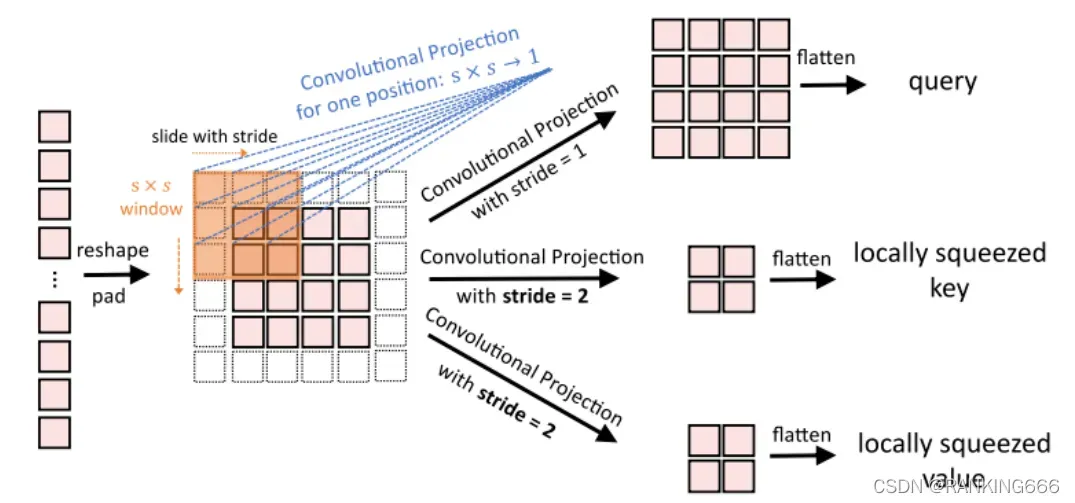
在 Q , K , V 的计算上使用深度可分离的卷积运算,称为卷积映射,分别用于查询、键和值的嵌入,而不是 ViT 中标准的位置线性映射。此外,分类 Token 只在最后阶段添加。
CeiT:
该论文同样,也是希望将 CNN 与 transformer 相结合。
主要有以下三项创新:
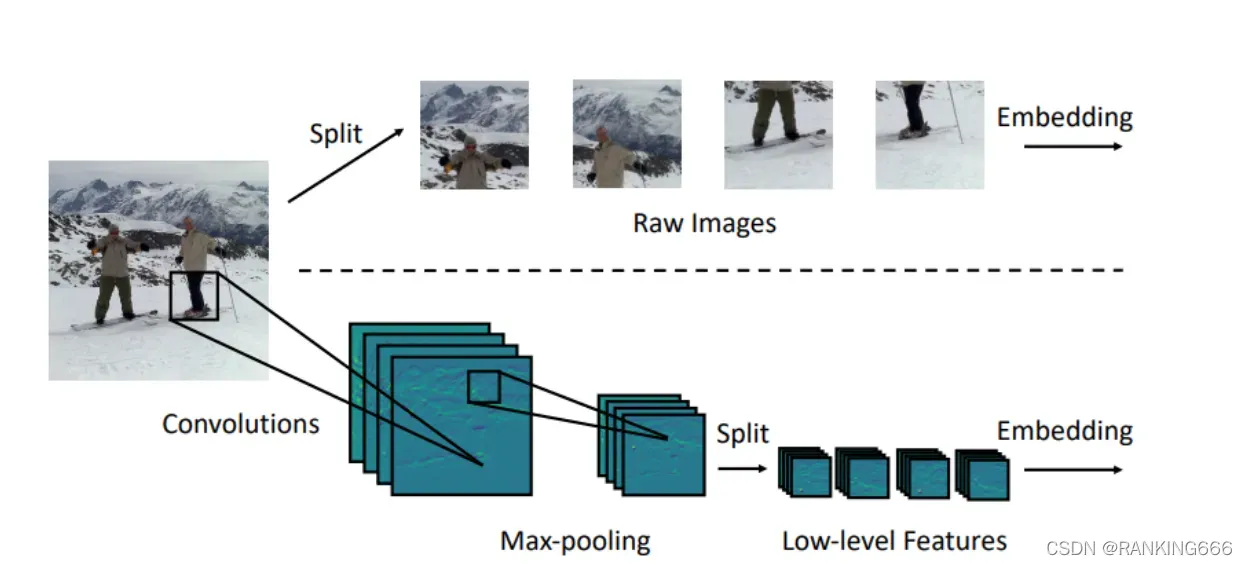
首先设计 Image-to-Tokens 模块来从 low-level 特征中得到 embedding 。
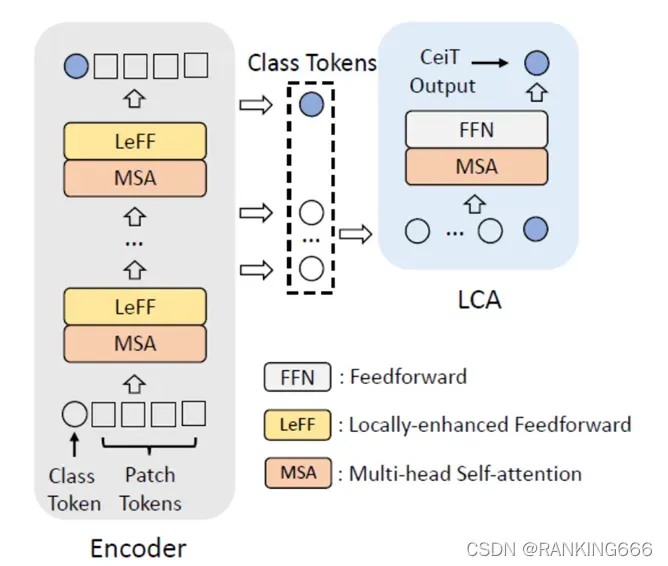
其次是将 Transformer 中的 Feed Forward 模块替换为 Locally-enhanced Feed-Forward(LeFF) 模块,增加了相邻 token 之间的相关性。
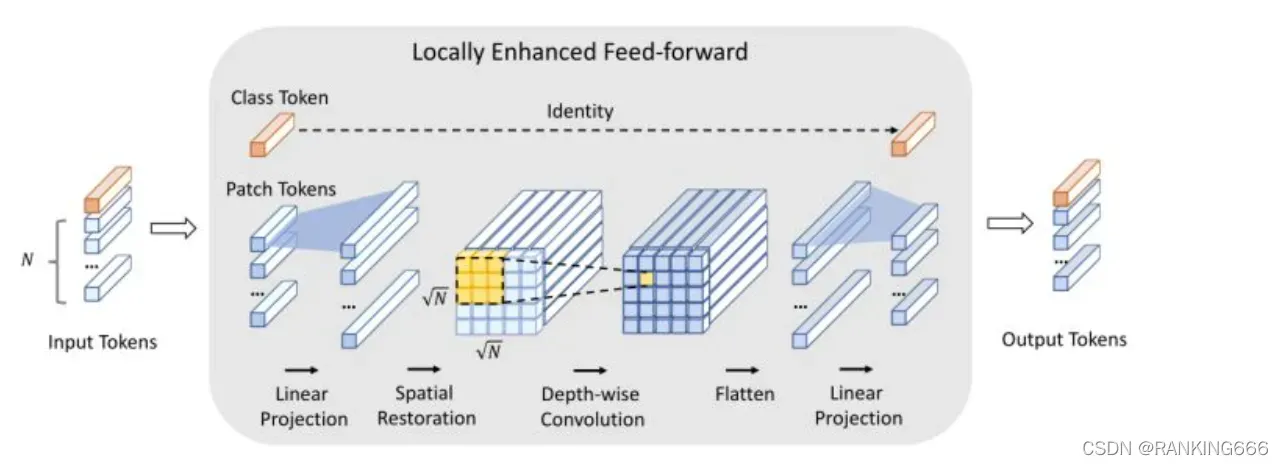
也就是在 mlp 中加了卷积来融合不同通道的特征。
最后是本文最为突出的一个特点使用 Layer-wise Class Token Attention ( LCA )捕获多层的特征表示。也就是将前面所有 stage 的 class token 取出来,将所有的 class token 作相关与前馈,相互进行信息交互。
如有错误,请批评指正!
文章出处登录后可见!